Command Palette
Search for a command to run...
Online Tutorial | NVIDIA Pushes Small Models: The Small and Compact Nemotron-Nano-9B-v2 Is 6 Times Faster Than Qwen3

When large language models were first introduced, did you ever imagine: one day, they would be small enough to fit inside a smartwatch? Today, this fantasy is gradually becoming a reality—devices like smartwatches access models from the cloud, enabling voice conversations and intelligent assistants. However, the challenge ahead lies not only in deploying them on small devices, but also in maintaining the model's reasoning capabilities and efficiency while maintaining its lightweight nature.
To address this, the NVIDIA team launched the lightweight large language model NVIDIA-Nemotron-Nano-9B-v2 on August 19, 2025. As a hybrid architecture optimized version of the Nemotron series,This model innovatively combines Mamba's efficient long sequence processing with Transformer's strong semantic modeling capabilities, replacing most of the self-attention layers with Mamba-2 state space layers, making the model faster when processing long inference trajectories.With only 9 billion parameters, it achieves support for 128K ultra-long context. In complex reasoning benchmarks, it achieves accuracy comparable to or even better than the leading open source model of the same scale, Qwen3-8B, and its throughput is increased by up to 6 times compared to the latter, marking a major breakthrough in the field of lightweight deployment and long text understanding of large language models.
In other words, Nemotron-Nano-9B-v2 represents more than just a "model in a small device."Instead, it aims to make powerful reasoning capabilities truly lightweight and accessible to the public.Perhaps in the future, large language models will be able to provide people with intelligent services anytime and anywhere in a "small and precise" form.
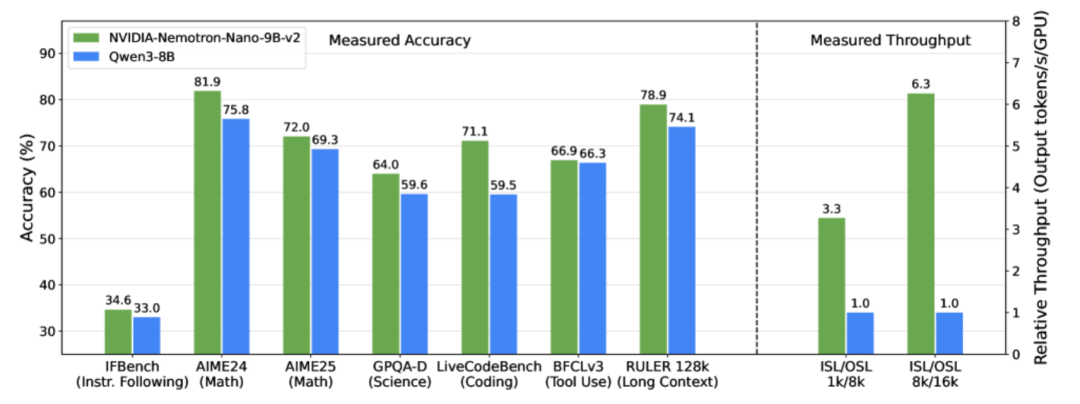
Release multilingual post-training datasets to comprehensively enhance model capabilities
Rather than simply building a small model, the research team started with a 12B-parameter baseline model, Nemotron-Nano-12B-v2-Base, and pre-trained it on a large amount of curated and synthetic data. They also added SFT-style data covering multiple domains to enhance reasoning.
Subsequently, the team conducted multi-stage post-training, including SFT (supervised fine-tuning), IFeval RL (instruction following evaluation), DPO (direct preference optimization), and RLHF (human feedback reinforcement learning), to make the model more accurate and robust in terms of mathematics, code, tool calls, and long-context dialogues.The related post-training dataset was updated and released as "Nemotron-Post-Training-Dataset-v2".Expand SFT and RL data to five target languages (Spanish, French, German, Italian, and Japanese), covering scenarios such as mathematics, coding, STEM (science, technology, engineering, and mathematics), and dialogue, to improve the model's reasoning and command-following capabilities.
Dataset address:
Based on the Minitron compression and distillation strategy, the research team employed a lightweight neural architecture search method to evaluate the importance of model components (such as each layer and feedforward neural network) and then prune them. Through distillation and retraining, the team refined the capabilities of the original model into the pruned model. Ultimately, they compressed the 12-byte model into the 9-byte Nemotron-Nano-9B-v2, significantly reducing resource usage while maintaining inference accuracy.
"Deploying NVIDIA-Nemotron-Nano-9B-v2 with vLLM + Open WebUI" is now available in the "Tutorials" section of the HyperAI Hyperneuron website (hyper.ai). Come and experience communicating with this "small but precise" large language model!
Tutorial Link:
Demo Run
1. Enter the hyper.ai URL in your browser. After entering the homepage, click the Tutorials page, select vLLM + Open WebUI to deploy NVIDIA-Nemotron-Nano-9B-v2, and click Run this tutorial online.
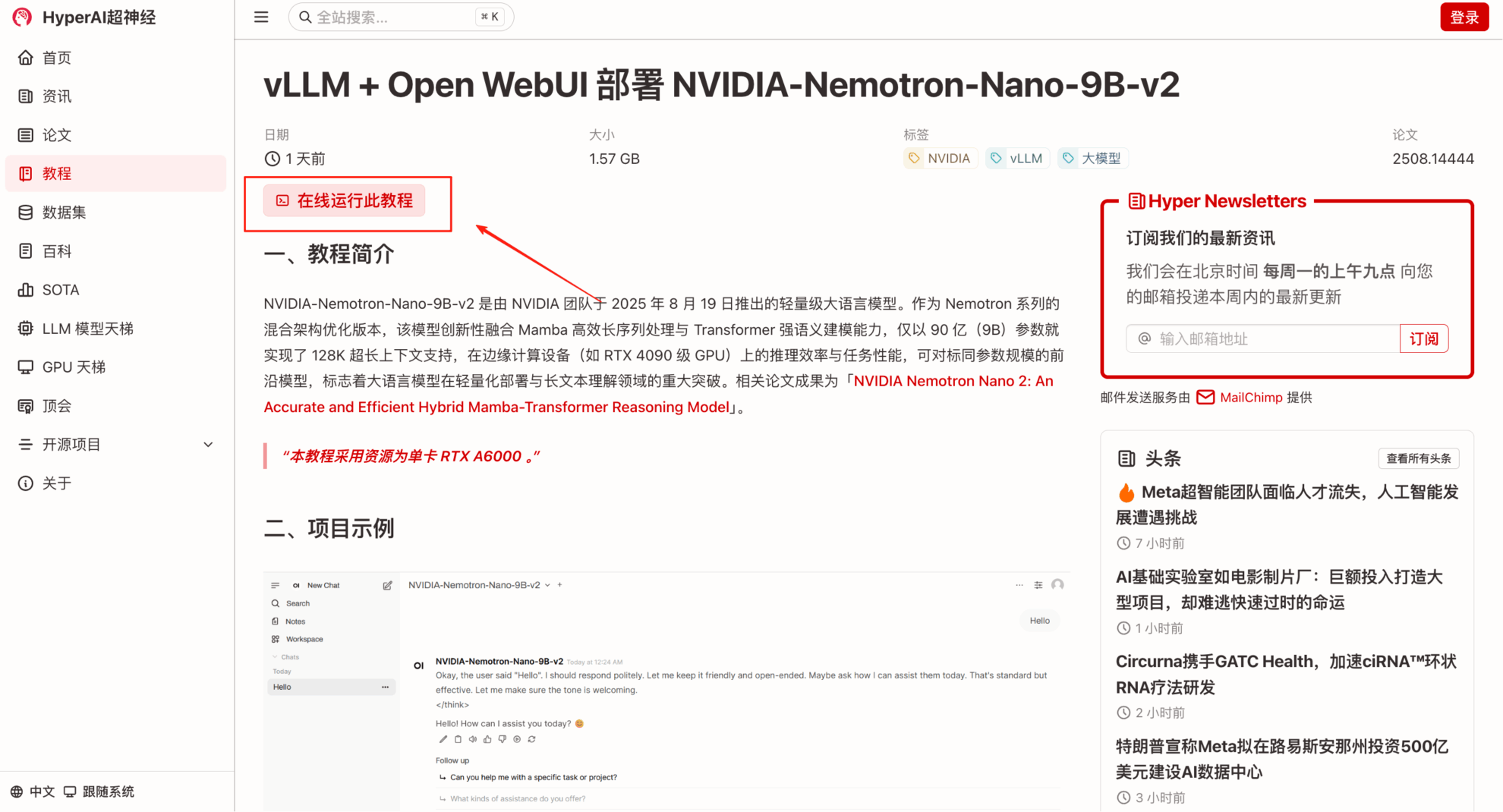
2. After the page jumps, click "Clone" in the upper right corner to clone the tutorial into your own container.
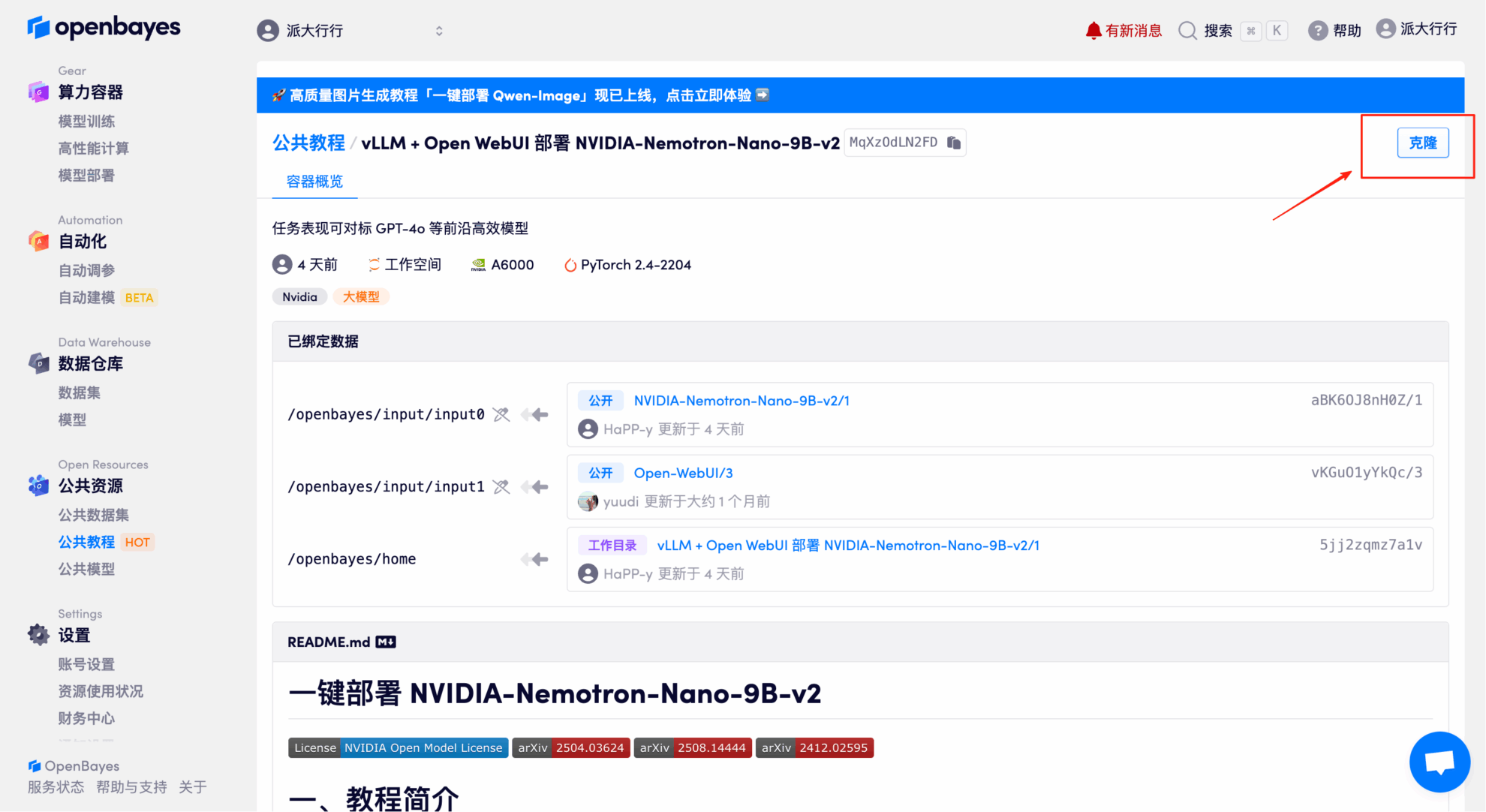
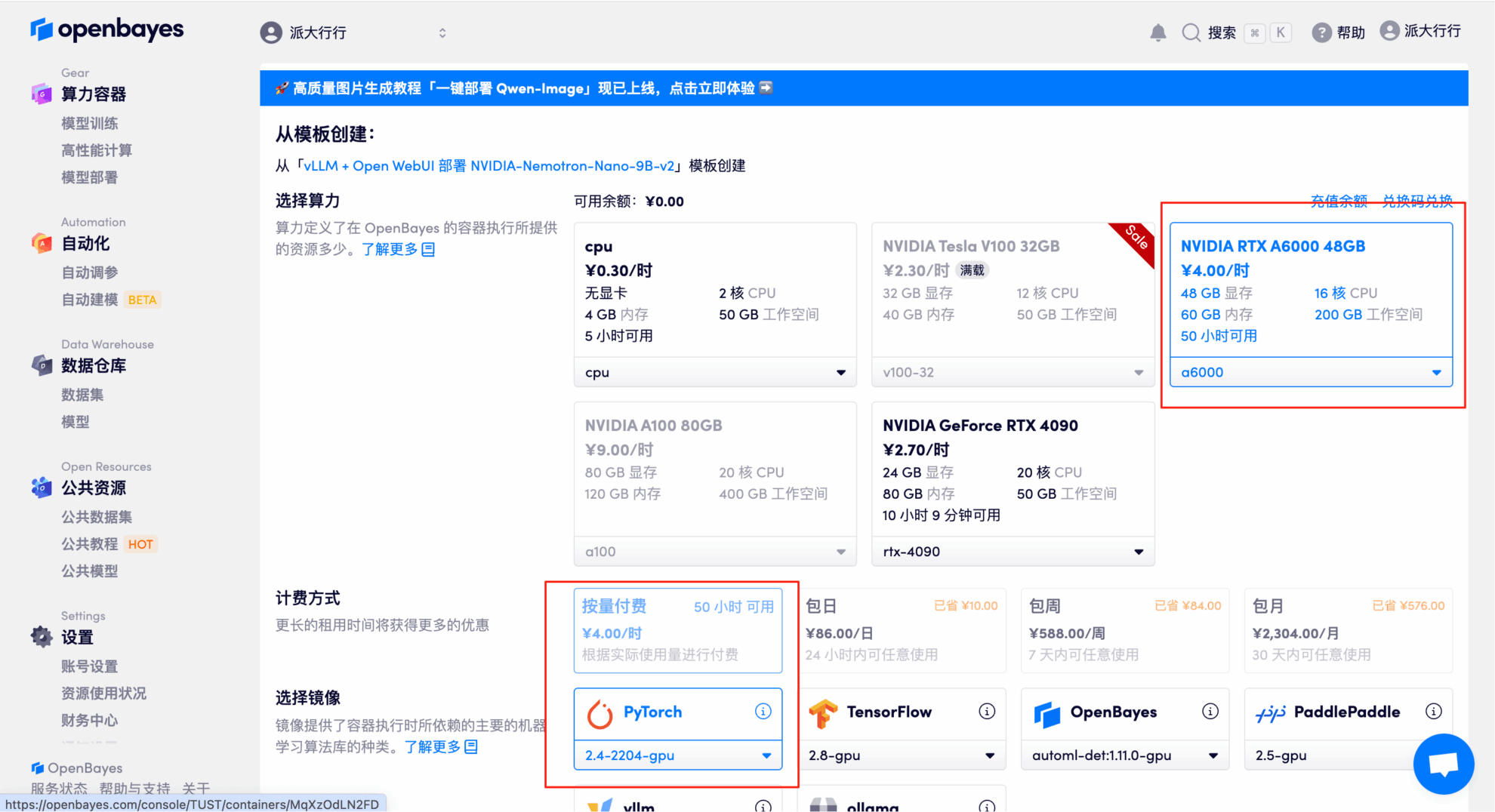
3. Select the NVIDIA RTX A6000 48GB and PyTorch images and click Continue. The OpenBayes platform offers four billing options: pay-as-you-go or daily/weekly/monthly plans. New users can register using the invitation link below to receive 4 hours of free RTX 4090 and 5 hours of free CPU time!
HyperAI exclusive invitation link (copy and open in browser):
https://openbayes.com/console/signup?r=Ada0322_NR0n
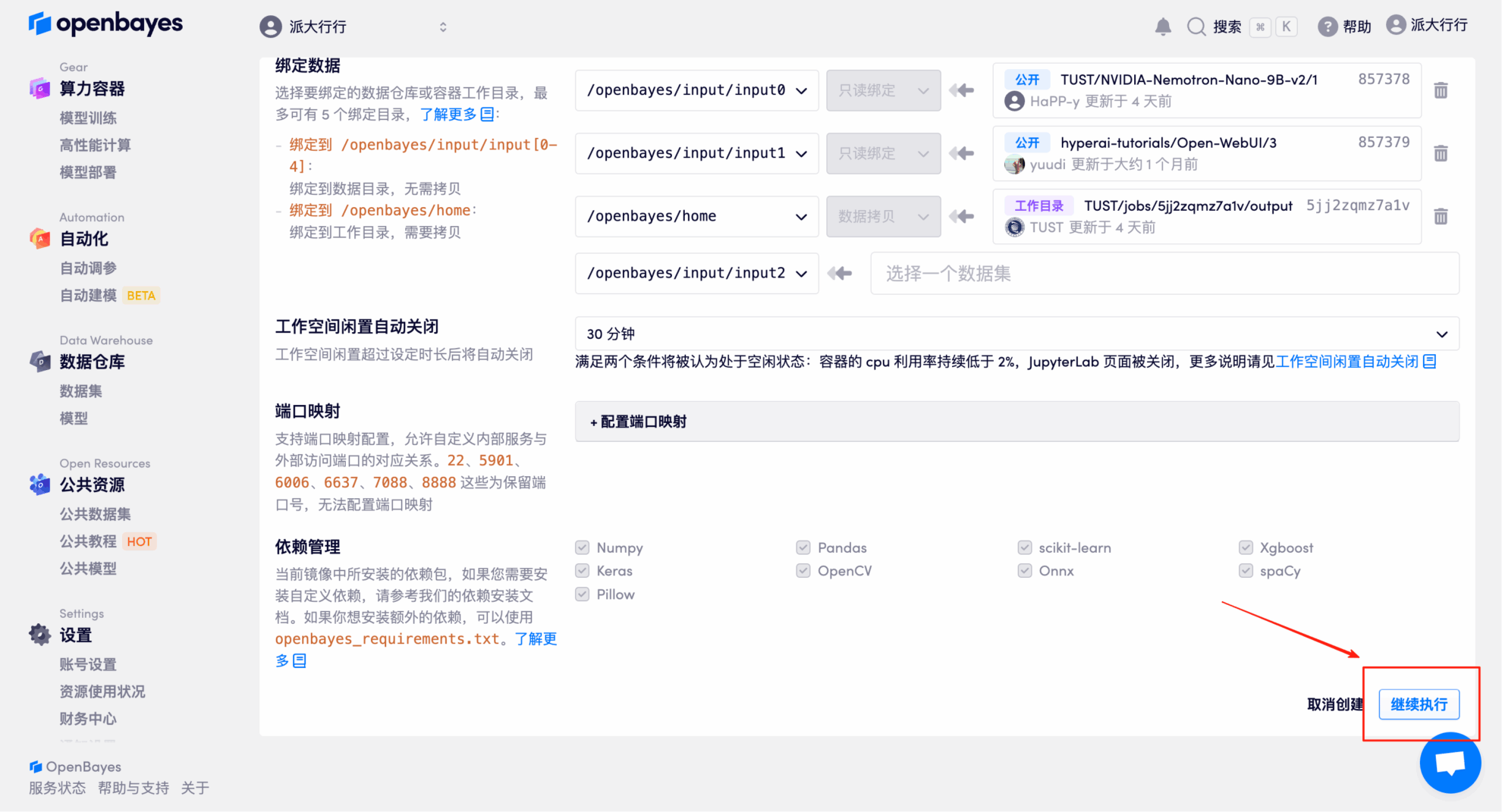
4. Wait for resources to be allocated. The first cloning process will take approximately 3 minutes. When the status changes to "Running," click the arrow next to "API Address" to jump to the Demo page. Please note that users must complete real-name authentication before using the API address.
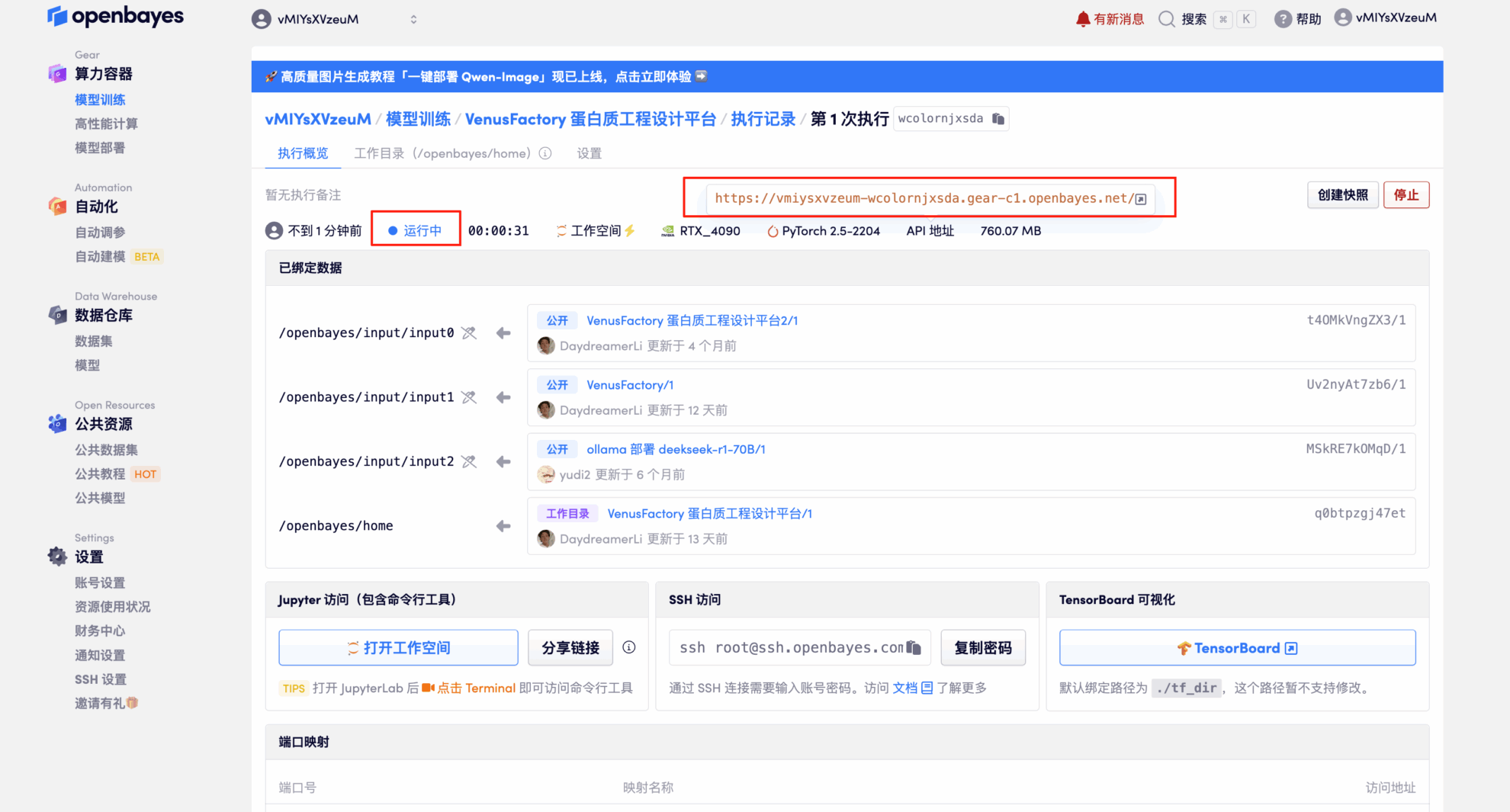
Effect Demonstration
After entering the Demo run page, enter Prompt in the dialog box and click Run.
The weather gradually turns cooler after the beginning of autumn. Let Nemotron-Nano-9B-v2 provide us with some tips on keeping warm in early autumn.



The above is the tutorial recommended by HyperAI this time. Everyone is welcome to come and experience it!
Tutorial Link:
Get high-quality papers and in-depth interpretation articles in the field of AI4S from 2023 to 2024 with one click⬇️









