Command Palette
Search for a command to run...
To Improve the Availability of Scientific Data, Zhang Zhengde's Team at the Chinese Academy of Sciences Proposed an AI-Ready Data Processing and Supply Solution Based on Intelligent agents.

In today's high-energy physics research, cutting-edge large-scale scientific facilities are constantly generating massive amounts of data. As this unprecedented data deluge far exceeds the processing limits of traditional analytical methods, artificial intelligence (AI) technologies, particularly machine learning and deep neural networks, are rapidly becoming core tools throughout the high-energy physics research pipeline. AI algorithms not only efficiently process vast amounts of raw data and uncover implicit, nonlinear, and complex patterns and correlations within them, but also demonstrate application advantages in accelerator operation optimization, detector performance simulation, experimental trigger system design, and theoretical model exploration. The continuous innovation and deep integration of AI methods have become a potential driving force for the future development of high-energy physics.
At the 2025 CCF National High Performance Computing Academic Conference, Zhang Zhengde, Researcher and Head of AI4S at the Computing Center of the Institute of High Energy Physics, spoke at the "AI-Ready Scientific Data Technology" forum on the topic of "Advances and Practices of Data Processing Intelligent Agents Based on Large Models."Starting from the current status of scientific data from large-scale facilities, this paper systematically explains the efficient and high-quality AI-Ready construction plan for data, as well as the application of intelligent agents and multi-agent frameworks in data annotation and supply.

HyperAI has compiled and summarized Professor Zhang Zhengde's speech without violating the original intention. The following is the transcript of the speech.
The State of AI-Ready Data and Scientific Data
In the context of open source AI4S algorithms, data has become the most critical core issue. AI4S requires data to have unified standards for efficient analysis. Although data from large scientific facilities generally have a unified format and storage architecture, in reality, most scientific data is not AI-Ready.
The massive amount of data generated in high-energy physics not only places high demands on data acquisition, processing, and fusion technologies, but also provides a vital resource for developing AI methods. The data types mentioned in today's report include not only experimental data but also simulation data, device operation data, and corpus data.
The general definition of an AI-Ready dataset is a collection of data that can be used efficiently, securely, and reproducibly for training, evaluating, and deploying machine learning and artificial intelligence.High-quality AI-Ready data has 10 characteristics:
* Task adaptation.Strong relevance to the target scenario and task, with comprehensive coverage and representativeness;
* High quality and consistency.Accurate, complete, consistent, deduplicated, and noise-controlled;
* Meet the requirements of the body and marking,It has high-quality labels, hierarchies, and ontology mappings, and is annotated with audits;
* Engineering available.Machine-readable, such as having a standard format, reasonable sharding/bucketing, streamability, and parallelization;
* Evaluable and reusable.Strictly divide training, test, and validation data, and the benchmark set has clear and reasonable evaluation indicators;
* Metadata and enrichment.Covers metadata collection method, time, device system, context, version and other information;
* Data deviation control.Such as sampling bias, label bias, and historical bias;
* Available.Stable access interface, documentation and examples;
* Reasonable and compliant.Permissions and usage rights, privacy protection, and best PII;
* Safe and reliable.Encryption (in transit/at rest), least privilege, key management, etc.
In practical research, data is not only used to train models but also must support model evaluation. Therefore, datasets require the establishment of corresponding evaluation metrics, such as precision, recall, and F1 score. However, while these metrics are generally applicable to some tasks (such as classification), they are less effective for problems like regression. This places higher demands on the quality of AI-Ready datasets and presents challenges.
at present,In addition to containing ontological and annotated data, a qualified AI-Ready dataset should also provide metadata, including information such as a description of the AI task. More importantly, an AI-Ready dataset must be directly associated with valuable AI tasks.Taking light sources as an example, their AI applications should be able to effectively support specific scientific tasks such as imaging, spectroscopy, and diffraction scattering.
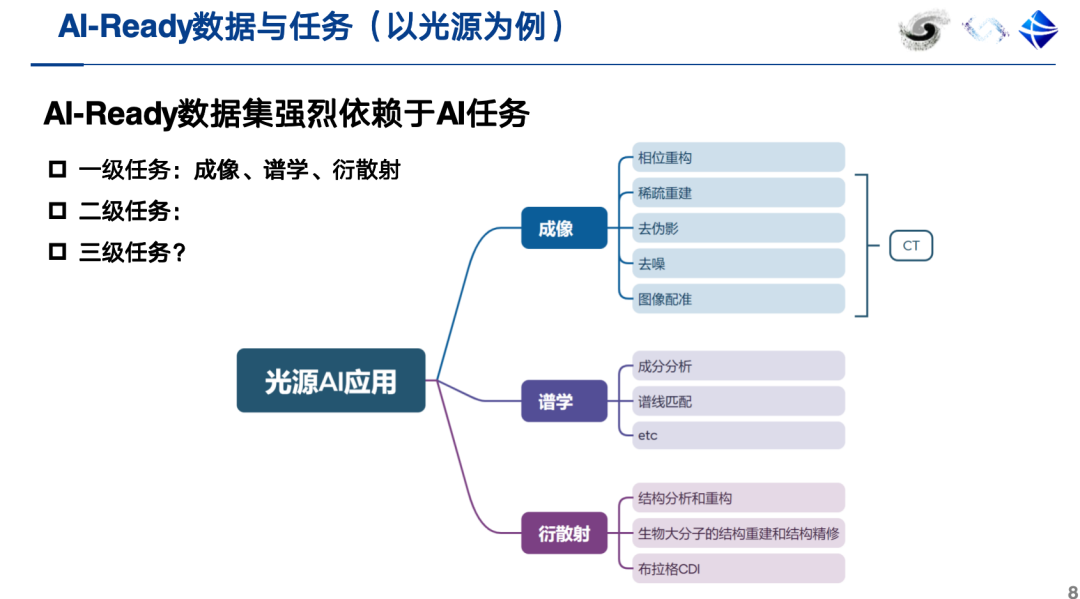
Next, I'll use two examples to illustrate what constitutes an AI-ready dataset. For example, the nanofiber orientation prediction AI dataset has a clear AI task: directly predicting nanofiber orientation parameters based on wide-angle diffraction spectra. Constructing such a dataset requires the combined efforts of both simulated and experimental data.
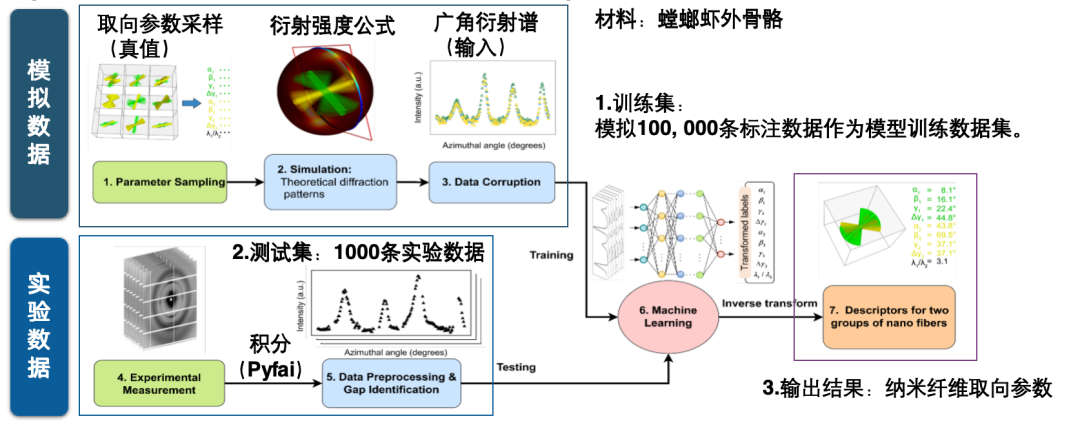
For example, the AI dataset for rapid reconstruction of stacked imaging can complete the AI task of inputting a diffraction pattern, predicting its phase and amplitude, and calculating the reconstructed image, completing the extensive computational effort involved in image reconstruction. This architecture includes two branches, one for predicting phase and the other for amplitude. The true values are derived using a scientific computing iterative algorithm and a high number of projections.
Applying agent technology to data processing
The definition of an agent is very close to the original definition of artificial intelligence, which refers to software or systems that can make decisions or perform actions on behalf of users based on their knowledge, programs, environment and input information.
Although intelligent agents have similarities with automation technology, the latter usually relies on fixed processes to operate. Unlike traditional automation, intelligent agents are particularly suitable for processing workflows that cannot be effectively covered by deterministic rules and can handle tasks that traditional rule-based computing methods are difficult to handle.Intelligent agents are not suitable for all scenarios. Their effectiveness is highly dependent on the specific task environment and requires full consideration of the complexity of decision-making and processing. Therefore, building intelligent agents requires rethinking how the system should deal with complex decision-making processes.
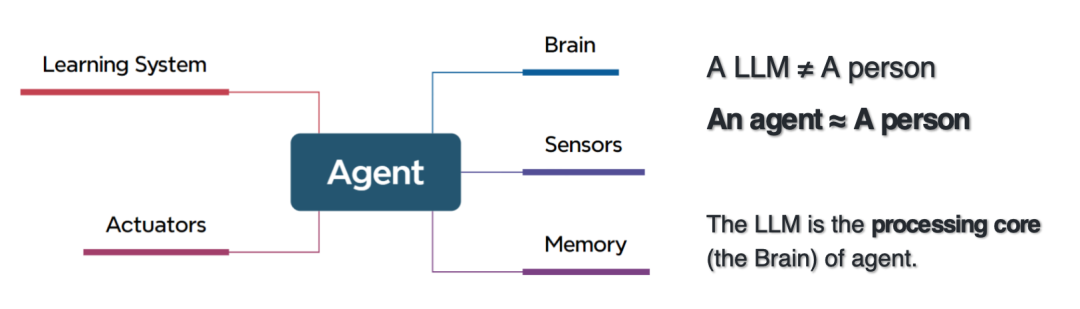
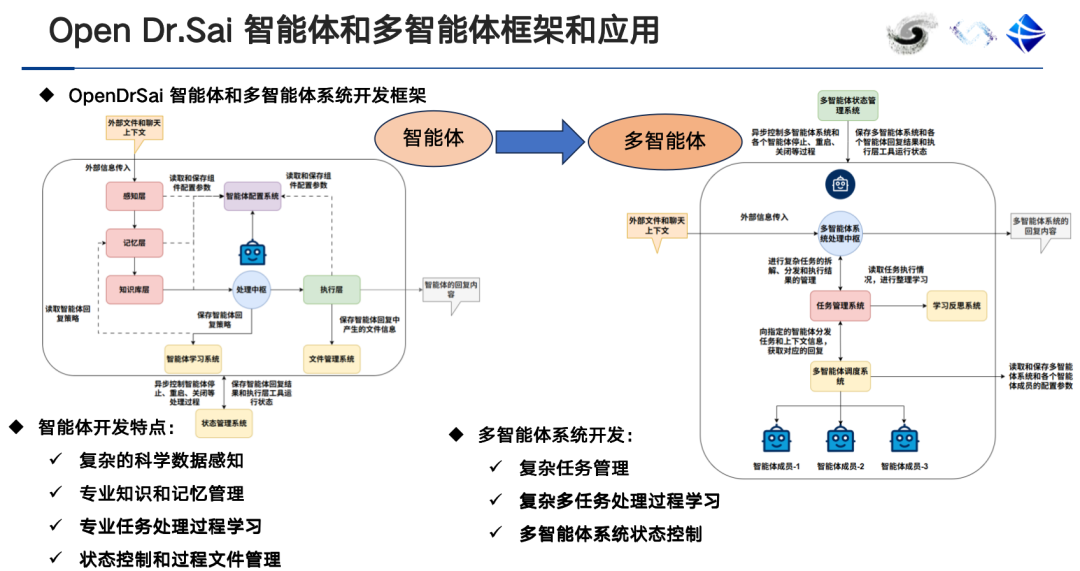
The brain of the intelligent agent is a large model, so the relationship between the intelligent agent and the large model is actually an inclusion relationship.The difference between an intelligent agent and a large model is that it includes a perception layer, an execution layer, a memory layer, and a processing center.Be able to learn domain expertise, scientific analysis tools, perceive data and metadata, write code and execute programs, task planning, role allocation and collaboration, etc.
At the same time, the application scenarios of single-agent and multi-agent systems are also different. Generally speaking, a single-agent system is equipped with a single tool. When the number of tools it carries increases, the accuracy of tool selection decreases. In this case, multi-agent systems can be used to avoid confusion.
AI-Ready data labeling based on labeling tools has high accuracy but requires high manual participation. AI-Ready data labeling based on intelligent agents is highly automated and efficient, and can provide data information understanding and assistance. It is suitable for interdisciplinary research, but the initial accuracy may be relatively low, and the labeling accuracy needs to be continuously improved through continuous learning and feedback mechanisms.At present, many annotation tools based on annotation have gradually transitioned to the model of "equipped with intelligent agent module + human-computer interaction + intelligent assistance + review system + database".
Data Agent Applied to Light Source Scenes
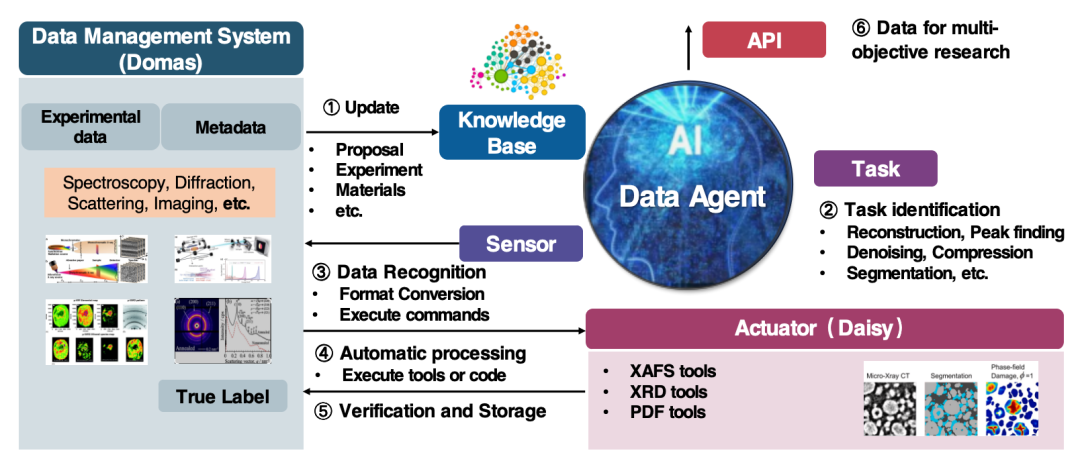
Our team's data agent is primarily used in light source (HEPS)/neutron source (CSNS) scenarios, supporting data processing and supply. The agent's upstream is the Domas data management system, which in turn is connected to the data collection system of the big data device, which in turn is connected to the detector itself.
For more information about Data Agents:
https://github.com/hepaihub/drsai
HepAI platform link:
The agent workflow is divided into 5 steps:
* Connect to Domas to obtain data information including experimental data and metadata;
* Update the knowledge base based on the acquired data;
* The agent further perceives data based on specific tasks and completes data interaction by converting data formats and executing commands;
* Use a variety of scientific computing tools to process data;
* Input data into the executor to drive task execution, and input the output results back into Domas.
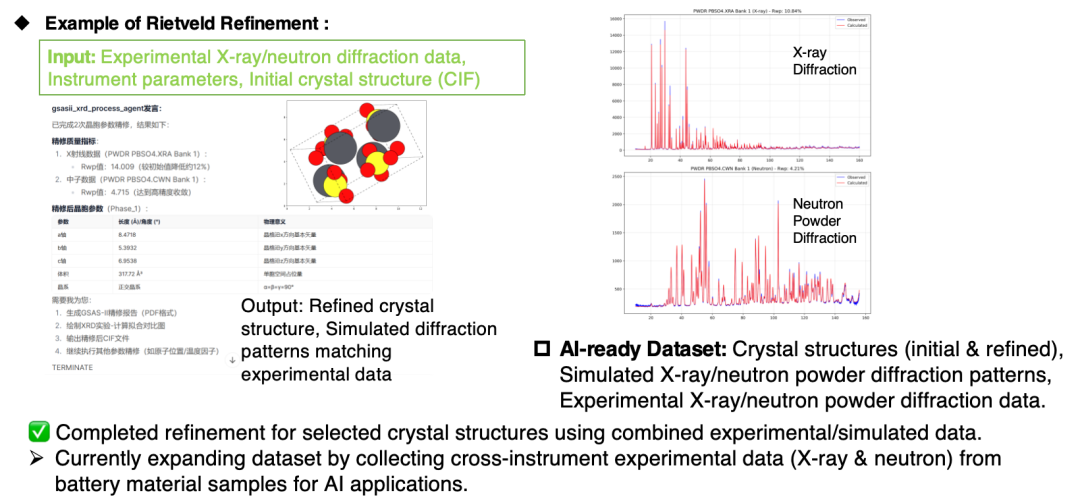
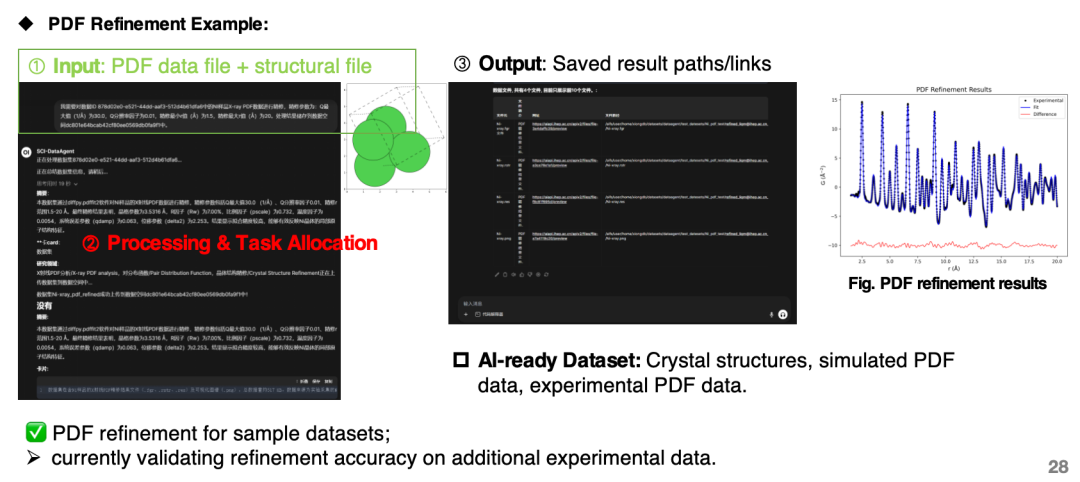
Currently, the agent can be used to construct AI datasets of cross-device X-ray diffraction and neutron powder diffraction experiments and simulations, and to construct experimental-simulation fusion datasets of pair distribution functions (PDFs).
AI-driven scientific discovery system
The reason why we use intelligent agent technology in data processing is that AI4S has gradually become a development trend. AI is helpful for the research and discovery of high-energy physics, but it has high requirements for data.Therefore, we adopted the strategy of "AI4Data" to "Data4AI", using AI to convert raw data into AI-Ready form to promote research and development results and build an AI-driven scientific discovery system.
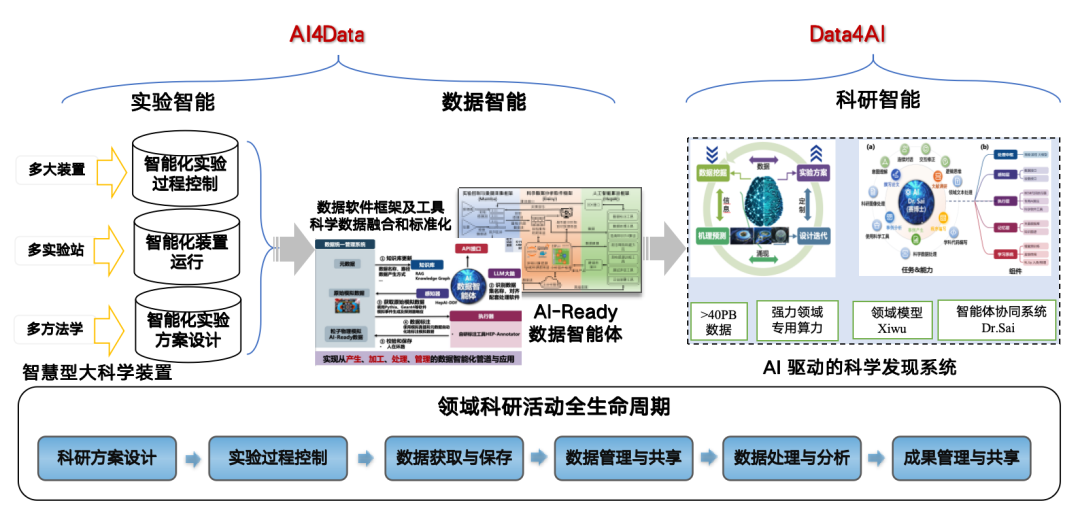
About Researcher Zhang Zhengde and his team
Dr. Zhang Zhengde is a Distinguished Young Researcher at the Institute of High Energy Physics, Chinese Academy of Sciences. He graduated from the Shanghai Institute of Applied Physics, Chinese Academy of Sciences with a Ph.D. in Particle Physics and Nuclear Physics. His main research areas are AI algorithms, large models, and intelligent agents for scientific discovery, covering deep learning algorithms, large models for scientific data, artificial intelligence platforms, and software systems. His main goal is to promote the application of AI in particle physics, particle astrophysics, synchrotron radiation, neutron science, and accelerators.

At present, researcher Zhang Zhengde has released 6 representative open source projects on GitHub, developed neural networks such as CDNet, FINet, and MWNet, developed the high-energy Xiwu language model and the "Science Doctor" scientific research agent, and planned and built the high-energy physics artificial intelligence platform HepAI[4]. At the same time, he presided over a number of important scientific research projects, including "From 0 to 1 Project - Research on AI Big Model Driven High-Energy Physics Scientific Discovery" and "Research and Demonstration of High-Energy Physics Big Data Technology Based on Artificial Intelligence".
References:
[3] hepai-group. (nd). Open drsai [Computer software]. GitHub. https://github.com/hepaihub/drsai
[4] hepai-group. (nd). HepAI Platform. https://ai.ihep.ac.cn
Get high-quality papers and in-depth interpretation articles in the field of AI4S from 2023 to 2024 with one click⬇️









