Command Palette
Search for a command to run...
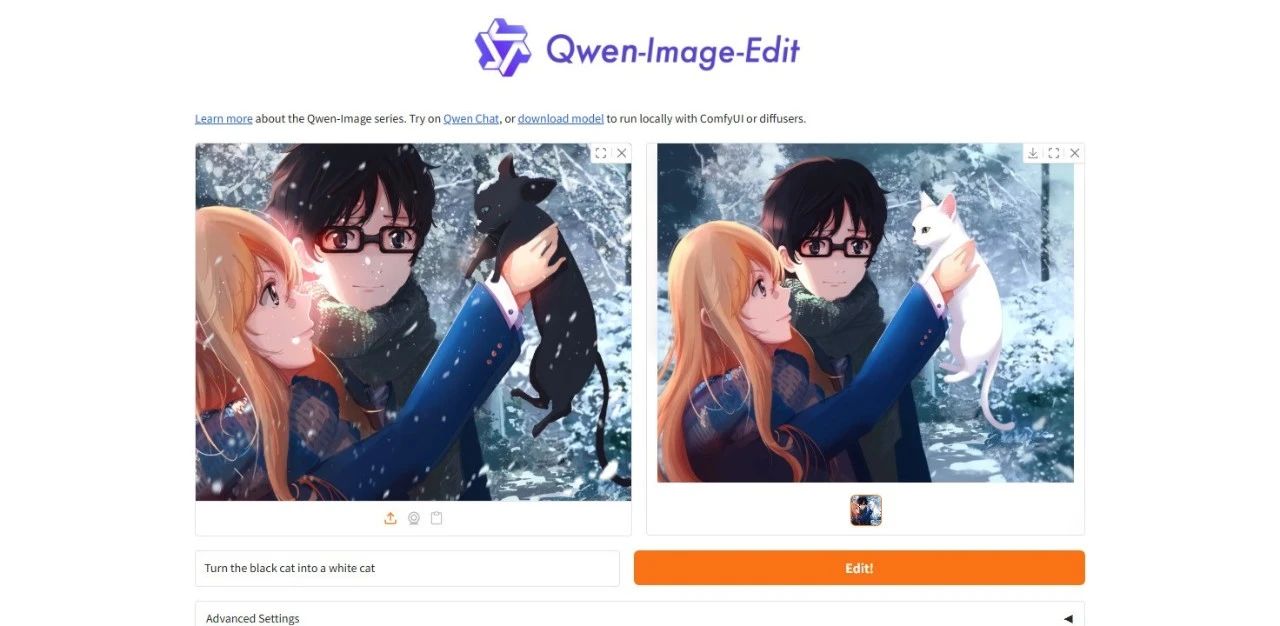
The New state-of-the-art in Image Editing! Qwen-Image-Edit Combines Both Semantic and Appearance Editing Capabilities; Granary Solves the Data Shortage for Multilingual Models in 25 European languages.

As image models continue to develop and mature, users' demand for using large models is no longer limited to single image generation, and they also hope to make more detailed and controllable modifications to existing images. "Editing" is a more detailed and microscopic use requirement than "generating".Traditional image editing software (such as Photoshop) has a certain usage threshold and often requires users to conduct systematic learning; and the current existing image editing AI applications have room for improvement in both functions and effects, especially in text rendering and editing capabilities.
Based on this,The Alitong Yiqianwen team released the all-round image editing model Qwen-Image-Edit, which has dual editing capabilities of semantics and appearance.It can not only accurately understand the instruction intent of appearance editing, but also perform advanced visual semantic editing while maintaining the consistency of the image's visual style.This model also extends Qwen-Image's excellent Chinese text rendering capabilities to the field of image editing, enabling precise editing of text in images.
As a new version of Qwen-Image, Qwen-Image-Edit improves the closed loop from image generation, chain editing to final effect presentation, greatly improving the usability of images.Evaluations on multiple public benchmarks demonstrate state-of-the-art performance on image editing tasks.
The HyperAI official website has launched the "Qwen-Image-Edit: All-in-One Image Editing Model Demo." Come and try it out!
Online use:https://go.hyper.ai/nmjYo
From August 18th to August 22nd, here’s a quick overview of the hyper.ai official website updates:
* High-quality public datasets: 10
* High-quality tutorial selection: 4
* This week's recommended papers: 5
* Community article interpretation: 5 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in August: 2
Visit the official website:hyper.ai
Selected public datasets
1. Granary European Speech Recognition and Translation Dataset
Granary is a large-scale multilingual speech dataset released by NVIDIA, designed to provide high-quality training and evaluation material for multilingual ASR/AST models. The dataset contains approximately 1 million hours of high-quality pseudo-labeled ASR speech data covering 25 European languages.
Direct use:https://go.hyper.ai/D3926
2. M3-Bench Long Video Question Answering Benchmark Dataset
M3-Bench, a long-video question-answering benchmark dataset released by the ByteDance Seed team, is designed to evaluate the long-term memory and reasoning capabilities of multimodal agents. The dataset contains 1,020 video samples, each of which includes captions, intermediate outputs, and memory graphs.
Direct use:https://go.hyper.ai/LIHsO
3. HiFiTTS-2 Large-Scale High-Bandwidth Speech Dataset
HiFiTTS-2 is a large-scale, high-bandwidth speech dataset designed to support the training and evaluation of high-quality zero-shot text-to-speech (TTS) models. The dataset contains audio metadata from 5,000 speakers, approximately 36,700 hours of English speech recordings at 22.05 kHz and 31,700 hours at 44.1 kHz, organized into strata based on bandwidth quality and sampling rate.
Direct use:https://go.hyper.ai/XZwDD
4. CulturalGround Multilingual Cultural Visual Question Answering Dataset
CulturalGround is a multilingual and multimodal visual question answering dataset for cultural knowledge alignment released by NeuLab at Carnegie Mellon University. It aims to improve the understanding and reasoning capabilities of multimodal large language models for niche cultural entities and low-resource languages.
Direct use:https://go.hyper.ai/wayAA
5. HPDv3 Human Preference Dataset
HPDv3 is the first broad-spectrum human preference dataset released by MizzenAI and MMLab at the Chinese University of Hong Kong. The related paper has been selected for ICCV 2025. This dataset is designed for the alignment, permutation, and evaluation of text-to-image generation models, aiming to promote model progress in aligning with human aesthetics and improving semantic consistency.
Direct use:https://go.hyper.ai/xV8fK
6. COREVQA Visual Question Answering Benchmark Dataset
COREVQA, a visual question answering benchmark dataset released by the Algoverse AI Research Center, is designed to evaluate the reasoning capabilities of visual language models (VLMs) in crowd scenes. The dataset primarily features real-world crowded scenes, emphasizing challenges such as occlusion, perspective changes, and background interference. It aims to enhance VLMs' fine-grained perception and reasoning capabilities in complex social scenarios.
Direct use:https://go.hyper.ai/tOFNw
7. DDOS UAV Depth and Obstacle Segmentation Dataset
DDOS is a synthetic aerial imagery dataset designed to advance algorithm development in drone autonomy. The dataset is carefully categorized by environment type. The training set consists of 300 flights, totaling 30,000 images; the validation set consists of 20 flights, totaling 2,000 images; and the test set consists of 20 flights, totaling 2,000 images.
Direct use:https://go.hyper.ai/XRE6R

8. Nemotron Multi-Domain Reasoning Dataset
Nemotron is a multi-domain reasoning dataset released by NVIDIA, designed to improve the reasoning efficiency and accuracy of the Llama model. The dataset contains 25.66 million samples covering five categories: conversation, code, math, STEM, and tool calls.
Direct use:https://go.hyper.ai/WP2Ym
9. Document Haystack Multimodal Document Benchmark Dataset
Document Haystack is a multimodal document benchmark dataset released by Amazon AGI. It contains 400 document variants and 8,250 retrieval questions. It aims to evaluate the information retrieval and understanding capabilities of visual language models (VLMs) in long and complex context documents.
Direct use:https://go.hyper.ai/Q08Xt
10. CSEMOTIONS Emotional Audio Dataset
CSEMOTIONS is an emotional audio dataset designed to support research in controllability and natural language speech generation. The dataset contains approximately 10 hours of high-quality audio data, covering seven emotional categories, including calm, happy, and angry, recorded by 10 professional voice actors.
Direct use:https://go.hyper.ai/4fe7A
Selected Public Tutorials
1. vLLM + Open-WebUI deploy Jan-v1-4B
Jan-v1-4B is a 4-billion-parameter open-source language model released by the Jan team. Targeted at intelligent body-based reasoning and tool invocation, it is the first release of the Jan family and optimized for real-world workflow scenarios in Jan apps. Based on Qwen3-4B-Thinking-2507, this model has been fine-tuned and expanded, achieving an accuracy of 91.1% on the SimpleQA benchmark, demonstrating significant performance improvements achieved through model expansion and tuning.
Run online:https://go.hyper.ai/CZf3s
2. Breast Cancer Diagnosis Dataset Machine Learning Classification Prediction Tutorial
This tutorial, based on the Wisconsin Breast Cancer Diagnosis Dataset (WDBC), demonstrates the entire machine learning process for a binary classification problem. This tutorial helps you understand the core logic of feature selection, model tuning, and result visualization, providing a reference for modeling diagnostics for other diseases.
Run online:https://go.hyper.ai/zFjil
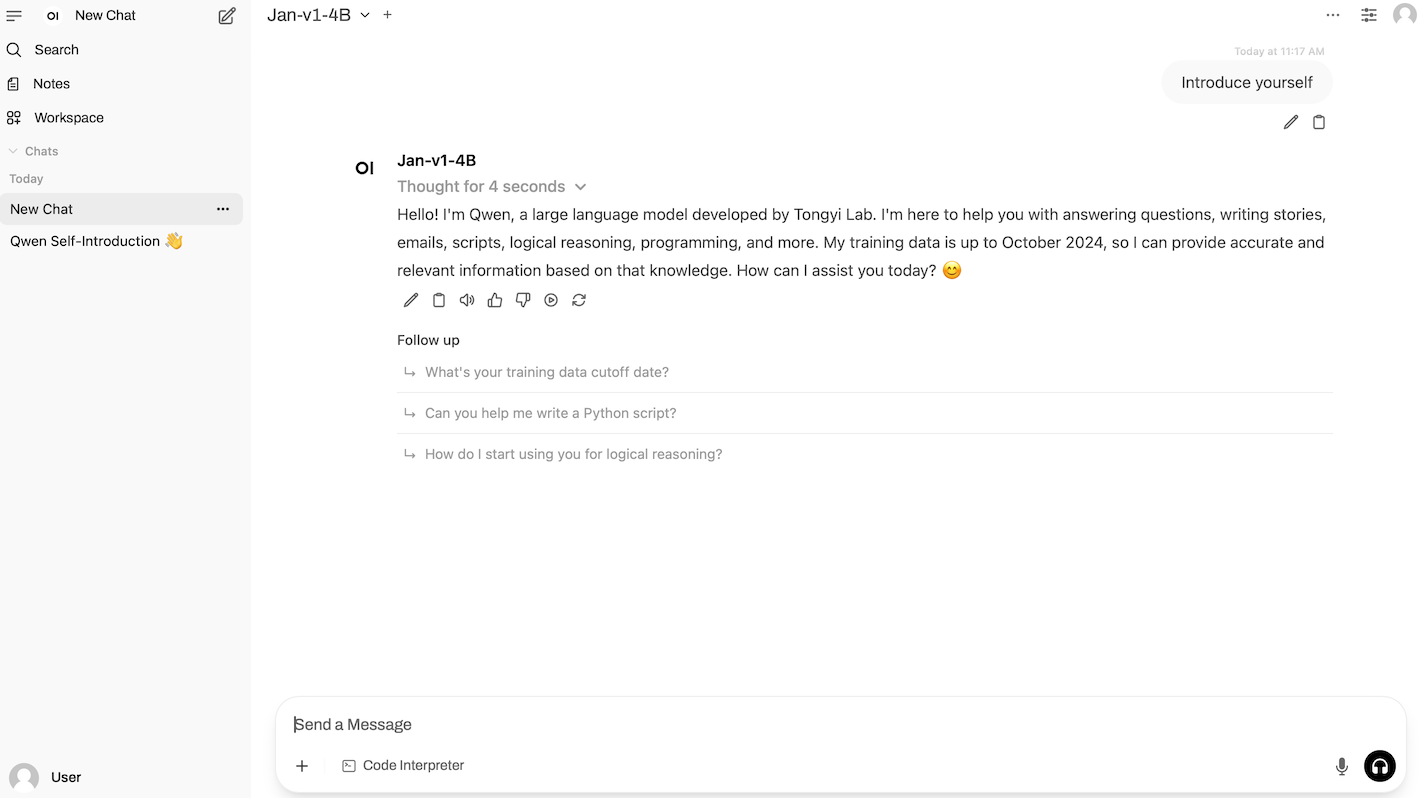
3. Qwen-Image-Edit: All-round image editing model Demo
Qwen-Image-Edit is a comprehensive image editing model developed by the Alibaba Tongyi Qianwen team. It combines both semantic and visual editing capabilities, supports precise editing of text in both Chinese and English, and allows text within images to be modified while preserving the original font, size, and style.
Run online:https://go.hyper.ai/nmjYo
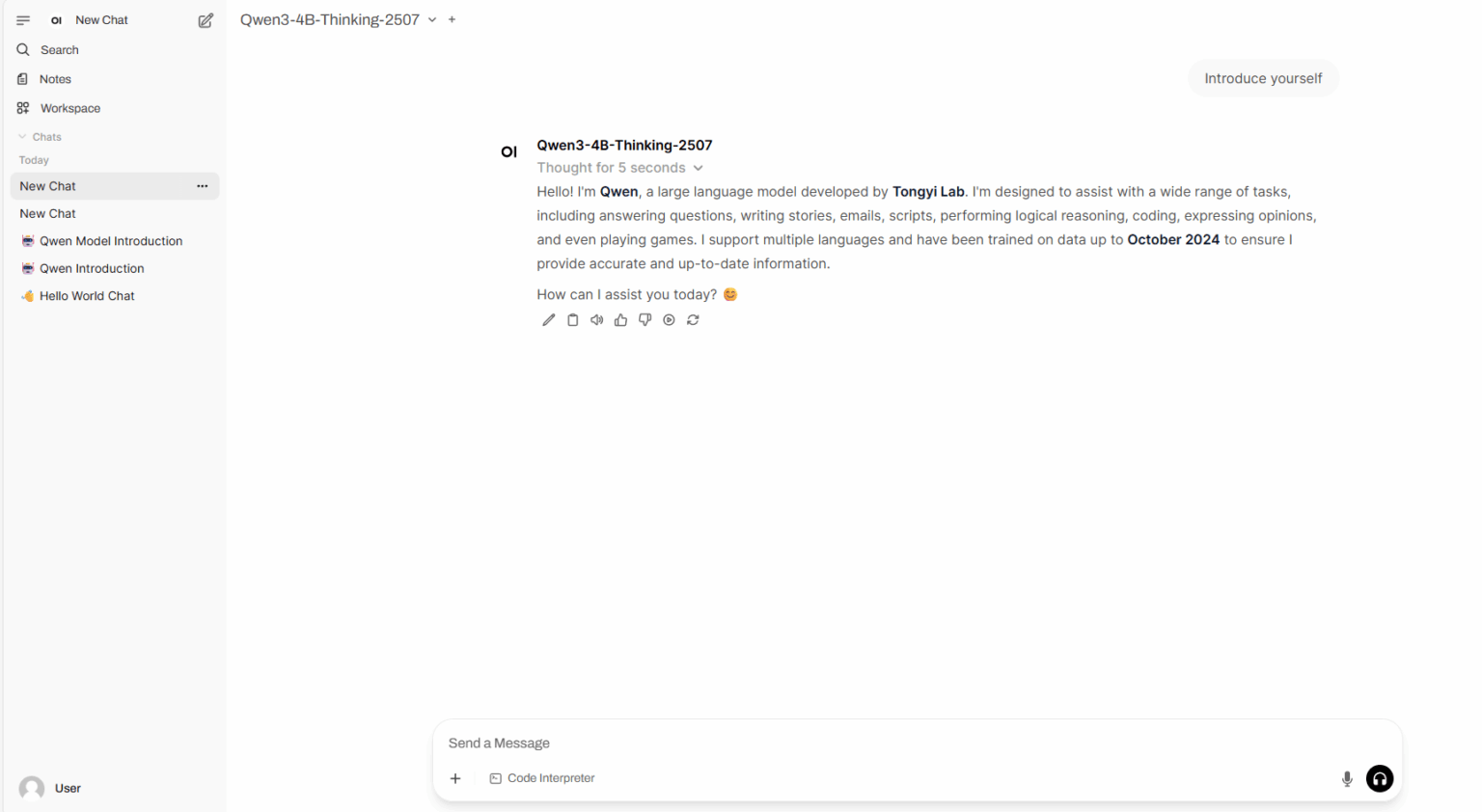
4. One-click deployment of Qwen3-4B-2507
Qwen3-4B-Thinking-2507 and Qwen3-4B-Instruct-2507 are large language models developed by the Alibaba Tongyi Qianwen team. In terms of performance, Qwen3-4B-Thinking-2507 significantly outperforms the smaller Qwen3 model of the same size in complex problem reasoning, mathematical capabilities, coding capabilities, and multi-round function call capabilities. In non-reasoning domains, Qwen3-4B-Instruct-2507 comprehensively surpasses the closed-source small-scale GPT-4.1-nano model in knowledge, reasoning, programming, alignment, and agent capabilities, and approaches performance similar to the medium-sized Qwen3-30B-A3B (non-thinking).
Run online:https://go.hyper.ai/HiqSR
💡We have also established a Stable Diffusion tutorial exchange group. Welcome friends to scan the QR code and remark [SD tutorial] to join the group to discuss various technical issues and share application results~

This week's paper recommendation
1. DINOv3
This technical report introduces DINOv3, which generates high-quality dense features and performs exceptionally well across a wide range of vision tasks, significantly outperforming previous self-supervised and weakly supervised baseline models. Researchers also released the DINOv3 family of vision models, aiming to advance the state of the art across a wide range of tasks and datasets by providing scalable solutions to address diverse resource constraints and deployment scenarios.
Paper link:https://go.hyper.ai/tBuYx
2. Ovis2.5 Technical Report
This paper presents Ovis2.5, the successor to Ovis2, designed for native-resolution visual perception and powerful multimodal reasoning. Ovis2.5 integrates a native-resolution visual transformer that processes images directly at their native, variable resolution, avoiding the quality degradation associated with fixed-resolution segmentation while fully preserving fine details and global layout.
Paper link:https://go.hyper.ai/jlEXl
3. SSRL: Self-Search Reinforcement Learning
Researchers investigate the potential of large language models (LLMs) as efficient simulators for agent search tasks in reinforcement learning (RL), reducing reliance on expensive external search engine interactions. Empirical evaluations demonstrate that policy models trained with SSRL provide a cheap and stable environment for search-driven RL training, significantly reducing reliance on external search engines and facilitating robust transfer from simulation to reality.
Paper link:https://go.hyper.ai/4TFRe
4. Thyme: Think Beyond Images
Since no open source work currently offers a feature set comparable to that of proprietary models, this paper conducts preliminary exploration in this direction and proposes Thyme (Think Beyond Images), which enables multimodal large language models (MLLMs) to go beyond existing "thinking through images" methods and autonomously generate and perform various image processing and computational operations through executable code.
Paper link:https://go.hyper.ai/ZhLMI
5. Chain-of-Agents: End-to-End Agent Foundation Models via Multi-Agent Distillation and Agentic RL
Most existing multi-agent systems rely on hand-crafted prompts or workflow engineering and are built on complex agent frameworks, resulting in computational inefficiency, limited capabilities, and inability to benefit from data-centric learning. This research proposes Chain-of-Agents (CoA), a novel LLM reasoning paradigm that natively enables end-to-end complex problem solving within a single model, using the same mechanics as multi-agent systems.
Paper link:https://go.hyper.ai/5m3gV
More AI frontier papers:https://go.hyper.ai/iSYSZ
Community article interpretation
A joint team from the University of Oxford and others proposed a graph-based RAG method specifically for the medical field—Medical GraphRAG. This method effectively improves the performance of LLM in the medical field by generating evidence-based answers and official medical terminology explanations.
View the full report:https://go.hyper.ai/3458z
The Tongyi Qianwen team continues to enrich its open-source model matrix, focusing on architectural innovation, efficiency improvements, and breakthroughs in deep-dive scenarios, achieving performance comparable to industry leaders. The HyperAI official website's "Tutorials" section has published several Tongyi open-source model tutorials.
View the full report:https://go.hyper.ai/JKJTY
A team from Cornell University has proposed an integrated circuit called a Microwave Neural Network (MNN), which can simultaneously process ultra-high-speed data and wireless communication signals. With its low power consumption and small size, it can provide a new solution for high-bandwidth applications.
View the full report:https://go.hyper.ai/Cki2I
At the 2025 Shanghai Jiao Tong University AI For Bioengineering Summer School, Professor Zhuang Yingping from East China University of Science and Technology shared her views on "AI Assisting Efficient Biomanufacturing Processes". She introduced the technical system and team achievements from three aspects: the relationship between biomanufacturing and synthetic biology, the application fields of synthetic biology products, and intelligent biomanufacturing technology and practice.
View the full report:https://go.hyper.ai/LgKcG
To promote the widespread application of artificial intelligence in the field of protein engineering, Professor Hong Liang's research group at Shanghai Jiao Tong University developed a one-stop open source protein engineering workbench VenusFactory to integrate biological data retrieval, standardized task benchmarking, and pre-trained protein language models.
View the full report:https://go.hyper.ai/p3llU
Popular Encyclopedia Articles
1. DALL-E
2. Reciprocal sorting fusion RRF
3. Pareto Front
4. Large-scale Multi-task Language Understanding (MMLU)
5. Contrastive Learning
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:https://go.hyper.ai/wiki

One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!








