Command Palette
Search for a command to run...
MiniCPM-V 4.0 Surpasses GPT-4.1-mini in Performance, Reaching New Heights in on-device Image Modeling; HelpSteer3 Brings AI Responses Closer to Human thinking.

The technological evolution of multimodal large language models (MLLMs) is driving the development of the AI ecosystem. User demand for real-time interaction on mobile devices, such as phones and tablets, is growing significantly. However, while traditional large models offer excellent performance, they are burdened with a large number of parameters, making them difficult to deploy and operate on-device in mobile and offline scenarios.Large models on the edge still require cloud-side support and optimization when involved in some complex tasks, and there is still room for improvement in edge performance and multimodal capabilities.
In this context,Tsinghua University's Natural Language Processing Laboratory and Mianbi Intelligence jointly launched the efficient large-scale end-to-end model MiniCPM-V 4.0.This model not only inherits the powerful single-image, multi-image and video understanding performance of its predecessor MiniCPM-V 2.6, but also surpasses mainstream models such as GPT-4.1-mini-20250414, Qwen2.5-VL-3B-Instruct and InternVL2.5-8B in image understanding capabilities in the OpenCompass evaluation. It also achieves a parameter reduction of halved to 4.1B, significantly lowering the deployment threshold.The research team also simultaneously open-sourced iOS applications for iPhone and iPad, allowing users to experience "cloud-level capabilities and edge-level efficiency" on their phones.
As an important exploration of end-side MLLM, MiniCPM-V 4.0 promotes lightweight deployment of terminals to open up a broader development space and provides a good example for the expansion of other modalities such as voice and video to edge devices.
Currently, the HyperAI official website has launched "MiniCPM-V4.0: Extremely Efficient Large-Scale On-Device Model". Come and try it out!
Online use:https://go.hyper.ai/pZ5aZ
From August 11th to August 15th, here’s a quick overview of the hyper.ai official website updates:
* High-quality public datasets: 10
* High-quality tutorial selection: 6
* This week's recommended papers: 5
* Community article interpretation: 5 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in August: 2
Visit the official website:hyper.ai
Selected public datasets
1. NuminaMath-LEAN Mathematical Problem Dataset
NuminaMath-LEAN is a mathematical problem dataset jointly released by Numina and the Kimi Team. It aims to provide manually annotated formal statements and proofs for the training and evaluation of automated theorem proving models. The dataset contains 100,000 math competition problems, including those from prestigious competitions such as the International Mathematical Olympiad (IMO) and the United States Mathematical Olympiad (USAMO).
Direct use:https://go.hyper.ai/YSJM2
2. Trendyol Security Instruction Tuning Dataset
Trendyol is a security instruction tuning dataset designed to train advanced AI assistants for defensive cybersecurity. This dataset contains 53,202 instruction tuning examples covering over 200 cybersecurity domains, including cloud-native threats, AI/ML security, and other modern security challenges. It provides high-quality corpus for training defensive security AI models.
Direct use:https://go.hyper.ai/hfxLQ
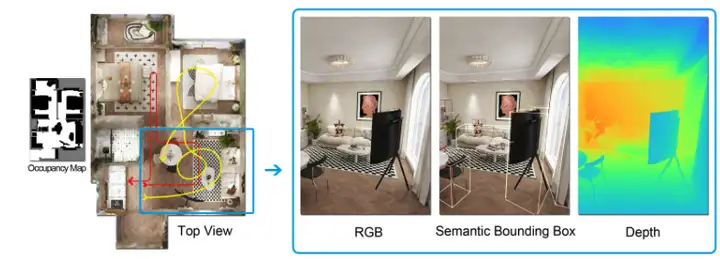
3. InteriorGS 3D Indoor Scene Dataset
InteriorGS is a 3D indoor scene dataset designed to overcome the limitations of existing indoor scene datasets in terms of geometric completeness, semantic annotation, and spatial interaction capabilities. The dataset provides high-quality 3D Gaussian scattering representations, as well as instance-level semantic bounding boxes and occupancy maps indicating the accessible areas of agents.
Direct use:https://go.hyper.ai/8pxTq
4. CognitiveKernel-Pro-Query Text Generation Benchmark Dataset
CognitiveKernel-Pro-Query is a text generation benchmark dataset released by Tencent, designed to evaluate the performance of models when processing long texts. The dataset contains over 10,000 long texts, covering application scenarios such as news articles, technical documents, and books.
Direct use:https://go.hyper.ai/onijU
5. Satellite Embedding Earth Observation Dataset
Satellite Embedding is an Earth observation dataset released by Google. It aims to provide a highly versatile geospatial representation, integrating spatial, temporal, and measurement context from multiple sources to accurately and efficiently generate maps and monitoring systems from local to global scales.
Direct use:https://go.hyper.ai/Yfw8K

6. LongText-Bench Text Understanding Benchmark Dataset
LongText-Bench is a text understanding benchmark dataset designed to evaluate models' ability to accurately understand long passages of Chinese and English text. The dataset contains 160 prompts for evaluating long text rendering tasks, covering eight different scenarios (road signs, labeled objects, printed materials, web pages, slides, posters, headlines, and dialogues).
Direct use:https://go.hyper.ai/k6Kj8
7. nuPlan Autonomous Driving Dataset
nuPlan is an autonomous driving dataset released by Motional. It aims to provide a machine learning-based planner development and training framework, a lightweight closed-loop simulator, dedicated motion planning metrics, and interactive tools for visualizing results. The dataset contains 1,200 hours of human driving data from four cities in the United States and Asia: Boston, Pittsburgh, Las Vegas, and Singapore.
Direct use:https://go.hyper.ai/BcEC8

8. HelpSteer3 Human Preference Dataset
HelpSteer3 is a human preference dataset released by NVIDIA. It aims to improve models' responsiveness to user prompts through human feedback and reinforcement learning techniques. The dataset contains 40,476 preference examples, each of which includes a domain, language, context, two replies, an overall preference rating between the two replies, and individual preference ratings from up to three annotators.
Direct use:https://go.hyper.ai/hByqe
9. NHR-Edit Image Editing Dataset
NHR-Edit is an image editing dataset designed to support the training of general image editing models that can follow diverse natural editing instructions. The dataset contains 286,608 unique source images and 358,463 image edit triplets. Each example also contains additional metadata such as edit type, style, and image resolution, making it suitable for training fine-grained, controllable image editing models.
Direct use:https://go.hyper.ai/LZtkd

10. A-WetDri Severe Weather Driving Dataset
A-WetDri is a severe weather driving dataset designed to improve the robustness and generalization of autonomous driving perception models in adverse weather conditions. The dataset contains 42,390 samples across four environmental scenarios (rain, fog, night, snow, and clear weather) and various object categories (cars, trucks, bicycles, motorcycles, pedestrians, and traffic signs and lights).
Direct use:https://go.hyper.ai/W2XE7

Selected Public Tutorials
1. MiniCPM-V4.0: Extremely Efficient Large-Scale End-to-End Model
MiniCPM-V 4.0 is an extremely efficient, large-scale, on-device model developed open-source by the Natural Language Processing Laboratory of Tsinghua University and Mianbi Intelligence. In the OpenCompass test, MiniCPM-V 4.0 surpassed GPT-4.1-mini-20250414, Qwen2.5-VL-3B-Instruct, and InternVL2.5-8B in image understanding capabilities.
Run online:https://go.hyper.ai/pZ5aZ

2. Exploratory Data Analysis | Explaining XGBoost's SHAP Values
This tutorial revolves around the multi-classification problem of "predicting the optimal fertilizer" and fully presents the end-to-end process from data exploration to model training to interpretable analysis.
Run online:https://go.hyper.ai/41z6K
3. dots.ocr: Multilingual Document Parsing Model
dots.ocr is a multilingual document layout parsing model developed by Xiaohongshu's hi lab. Based on a 1.7 billion-parameter visual language model (VLM), it integrates layout detection and content recognition, maintaining a good reading order. This model offers a simple and efficient architecture, requiring only a change in the input prompt to switch tasks. Its fast inference speed makes it suitable for a variety of document parsing scenarios.
Run online:https://go.hyper.ai/JewLR

4. Deploy Phi-4-mini-flash reasoning using vLLM+Open-WebUI
Phi-4-mini-flash-reasoning is a lightweight open-source model released by the Microsoft team. Built on synthetic data, it focuses on high-quality, dense inference data and is further fine-tuned to achieve more advanced mathematical reasoning capabilities. This model, part of the Phi-4 model family, supports 64K token context lengths and utilizes a decoder-hybrid-decoder architecture, combined with an attention mechanism and a state-space model (SSM), achieving excellent inference efficiency.
Run online:https://go.hyper.ai/ENYcL
5. llama.cpp+Open-WebUI deploy gpt-oss-120b
gpt-oss-120b is an open-source reasoning model released by OpenAI, designed for strong reasoning, agent-based tasks, and diverse development scenarios. Based on the MoE architecture, this model supports a context length of 128k and excels in tool invocation, few-shot function calls, chained reasoning, and health question-answering.
Run online:https://go.hyper.ai/3BnDy
6. llama.cpp+Open-WebUI deploy gpt-oss-20b
gpt-oss-20b is an open-source inference model released by OpenAI. It is suitable for low-latency, local, or specialized vertical applications. It runs smoothly on consumer-grade hardware (such as laptops and edge devices), with performance comparable to the o3‑mini.
Run online:https://go.hyper.ai/28FXJ
This week's paper recommendation
1. ReasonRank: Empowering Passage Ranking with Strong Reasoning Ability
Due to the scarcity of high-inference-intensive training data, existing rerankers perform poorly in many complex ranking scenarios, and their ranking capabilities are still in their early stages of development. This paper proposes an automated high-inference-intensive training data synthesis framework for the first time. This framework extracts training queries and paragraphs from multiple domains and utilizes the DeepSeek-R1 model to generate high-quality training labels. Furthermore, a self-consistent data filtering mechanism is designed to ensure data quality.
Paper link:https://go.hyper.ai/nmaou
2. WideSearch: Benchmarking Agentic Broad Info-Seeking
This paper introduces a new benchmark, WideSearch, designed to evaluate the reliability of agents on large-scale collection tasks. It consists of 200 carefully curated questions from over 15 different domains, based on real user queries. Each task requires the agent to collect large amounts of atomic information and organize it into a clearly structured output.
Paper link:https://go.hyper.ai/87pbh
3. WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent
This paper presents WebWatcher, a multimodal Deep Research agent with enhanced vision-language reasoning capabilities. This agent achieves efficient cold-start training through high-quality synthetic multimodal trajectories, combines multiple tools for deep reasoning, and further improves generalization through reinforcement learning.
Paper link:https://go.hyper.ai/n9IKZ
4. Matrix-3D: Omnidirectional Explorable 3D World Generation
This paper proposes the Matrix-3D framework, which uses a panoramic representation to generate large-scale, fully explorable 3D worlds. It combines conditional video generation with panoramic 3D reconstruction techniques. The researchers first trained a trajectory-guided panoramic video diffusion model, conditioned on a scene mesh rendering, to achieve high-quality, geometrically consistent scene video generation.
Paper link:https://go.hyper.ai/ojvKE
5. Voost: A Unified and Scalable Diffusion Transformer for Bidirectional Virtual Try-On and Try-Off
Virtual try-on aims to generate realistic images of a person wearing a target garment, but accurately modeling the correspondence between the garment and the human body remains a persistent challenge, especially in the presence of pose and appearance variations. In this paper, we propose a unified and scalable framework, named Voost, that jointly learns the virtual try-on and try-off tasks via a single diffusion transformer.
Paper link:https://go.hyper.ai/qCCaH
More AI frontier papers:https://go.hyper.ai/iSYSZ
Community article interpretation
Google DeepMind and Google Research have jointly released Perch 2.0, pushing bioacoustics research to new heights. Compared to its predecessor, Perch 2.0 focuses on species classification as its core training task. It not only incorporates more training data from non-avian groups, but also employs new data augmentation strategies and training objectives. This has resulted in new state-of-the-art results on both the BirdSET and BEANS bioacoustics benchmarks.
View the full report:https://go.hyper.ai/B7ZUk
A research team from Peking University has proposed MediCLIP, an efficient, few-shot medical image anomaly detection solution. Requiring only a minimal number of normal medical images, this method achieves leading performance in anomaly detection and localization tasks. It effectively detects different diseases across a wide range of medical image types, demonstrating impressive zero-shot generalization capabilities.
View the full report:https://go.hyper.ai/VAhFb
Paper With Code has officially ceased operations, and deep users around the world have spoken out. On the one hand, they highly praised the value of the website in machine learning research, and on the other hand, they expressed real needs - in addition to the correspondence between papers and open source codes, functions such as SOTA and leaderboards are equally important.
View the full report:https://go.hyper.ai/poRWa
To address the problem of histochemical staining in imaging mass spectrometry, the UCLA research team proposed a virtual histological staining method based on a diffusion model, which can enhance spatial resolution and digitally introduce cell morphology contrast into mass spectrometry images of label-free human tissues, thereby realizing the prediction of high-resolution cell tissue pathological structure based on low-resolution IMS data.
View the full report:https://go.hyper.ai/gcZ5U
Ainnova Tech, a health technology company, has built its Vision AI platform, leveraging intelligent diagnostic technology based on fundus images. This platform can detect diabetic retinopathy (with an accuracy exceeding 90.1% TP3T), cardiovascular risk, and other multi-system diseases in seconds. Serving over 20 countries, Ainnova Tech successfully completed its pre-submission meeting with the FDA in July 2025 and has now launched a free screening model in Latin America, driving innovation in the early diagnosis of chronic diseases.
View the full report:https://go.hyper.ai/Ete2g
Popular Encyclopedia Articles
1. DALL-E
2. Reciprocal sorting fusion RRF
3. Pareto Front
4. Large-scale Multi-task Language Understanding (MMLU)
5. Contrastive Learning
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
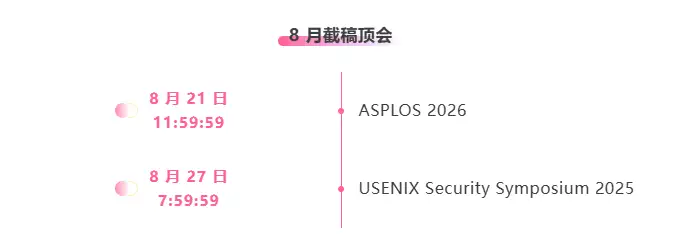
One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!








