Command Palette
Search for a command to run...
10 Million Hours of Voice Data! Higgs Audio V2 Speech Model Improves Emotional Capabilities; MathCaptcha10k Improves Verification Code Recognition Technology

"What would happen if 10 million hours of speech data were added to the training of a large language model for text?" With this thought,After research, Li Mu and his team Boson AI officially released the large-scale speech model "Higgs Audio V2".
Traditional TTS (text-to-speech) systems often use mechanical voice output, lacking emotional adaptability and natural rhythm. Multi-character dialogues require manual segmentation, and it is difficult to match timbre with character using models alone. Higgs Audio V2, on the other hand, introduces innovative features rarely seen in traditional TTS.It includes automatic rhythm adaptation during narration, the ability to generate multi-speaker dialogues, zero-sample voice cloning and melodic humming, and simultaneous generation of speech and background music, representing a major leap in audio AI capabilities.
It is worth mentioning that on EmergentTTS-Eval,The model outperformed gpt-4o-mini-tts by 75.7% and 55.7% in the sentiment and question categories, respectively.This reflects that "emotional interaction" has become a key step for the model in the audio field.
Currently, HyperAI's official website has launched "Higgs Audio V2: Redefining the Expressive Power of Speech Generation". Come and try it out!
Online use:https://go.hyper.ai/Ty0CM
From August 4th to August 8th, here’s a quick overview of the hyper.ai official website updates:
* High-quality public datasets: 10
* High-quality tutorial selection: 7
* This week's recommended papers: 5
* Community article interpretation: 5 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in August: 2
Visit the official website:hyper.ai
Selected public datasets
1. STRIDE-QA-Mini Autonomous Driving Question Answering Dataset
STRIDE-QA-Mini is a question-answering dataset for autonomous driving, designed to study the spatiotemporal reasoning capabilities of visual language models (VLMs) in autonomous driving scenarios. The dataset contains 103,220 question-answer pairs and 5,539 image samples. The data is derived from real dashcam footage collected in Tokyo.
Direct use:https://go.hyper.ai/9DVTI
2. MathCaptcha10k arithmetic verification code image dataset
MathCaptcha10K is a dataset of arithmetic CAPTCHA images designed to test and train CAPTCHA recognition algorithms, particularly when dealing with CAPTCHAs with distracting backgrounds and distorted text. The dataset contains 10,000 labeled examples and 11,766 unlabeled examples. Each labeled example contains a CAPTCHA image, the exact characters in the image, and its integer answer.
Direct use:https://go.hyper.ai/QERJt

3. CoSyn-400K Multimodal Synthetic Question Answering Dataset
CoSyn-400K is a multimodal synthetic question-answering dataset jointly released by the University of Pennsylvania and the Allen Institute for Artificial Intelligence. It aims to provide high-quality, scalable synthetic data resources for multimodal model training. The dataset contains over 400,000 image-text question-answer pairs, supporting visual answering tasks.
Direct use:https://go.hyper.ai/aNjiz
4. NonverbalTTS Non-verbal Audio Generation Dataset
NonverbalTTS is a non-verbal audio generation dataset released by VK Lab and Yandex. It aims to promote expressive text-to-audio (TTS) research and support models to generate natural speech containing emotions and non-verbal sounds.
Direct use:https://go.hyper.ai/0Gz9V
5. GPT Image Edit-1.5M Image Generation Dataset
GPT Image Edit-1.5M is an image generation dataset released by the University of California, Santa Cruz, and the University of Edinburgh. It aims to provide a comprehensive multimodal data resource for training and evaluating image editing models. The dataset contains over 1.5 million high-quality triplets (instruction, source image, edited image).
Direct use:https://go.hyper.ai/ohpmD

6. UniRef50 protein sequence dataset
The UniRef50 protein sequence dataset is derived from the UniProt knowledgebase and is derived from UniParc sequences through iterative clustering. This iterative process ensures that the representative sequences in UniRef50 are high-quality, non-redundant, and diverse, providing extensive coverage of the protein sequence space for protein language models.
Direct use:https://go.hyper.ai/EcUF5
7. Difference Aware Fairness Difference Perception Benchmark Dataset
Difference-Aware Fairness is a difference-aware benchmark dataset released by Stanford University. It aims to measure the performance of models in difference perception and context awareness. The related paper was published at ACL 2025 and was awarded the Best Paper Award.
Direct use:https://go.hyper.ai/wwBos
8. T-Wix Russian SFT dataset
T-Wix is an SFT dataset containing 499,598 Russian language samples, designed to enhance the model's capabilities from solving algorithmic and mathematical problems to conversation, logical thinking, and reasoning patterns.
Direct use:https://go.hyper.ai/p0sgT
9. WebInstruct-verified Multi-domain Reasoning Dataset
WebInstruct-verified is a multi-domain reasoning dataset jointly released by the University of Waterloo and the Vector Institute. It aims to enhance LLMs' reasoning abilities across diverse domains while retaining their strengths in mathematics. The dataset contains approximately 230,000 reasoning questions across a variety of answer formats, including multiple-choice questions and numerical expression datasets, with a balanced distribution across domains.
Direct use:https://go.hyper.ai/oCgsZ
10. Finance-Instruct-500k Financial Inference Dataset
Finance-Instruct-500k is a financial reasoning dataset designed for training advanced language models for financial tasks, reasoning, and multi-turn dialogue. The dataset contains over 500,000 high-quality records from the financial domain, covering financial question answering, reasoning, sentiment analysis, topic classification, multilingual named entity recognition, and conversational AI.
Direct use:https://go.hyper.ai/03UVH
Selected Public Tutorials
1. Higgs Audio V2: Redefining the expressive power of speech generation
Higgs Audio V2 is a large speech model released by Li Mu and his team at Boson AI. It achieves state-of-the-art performance on traditional TTS benchmarks, including Seed-TTS Eval and the Emotional Speech Dataset (ESD). The model demonstrates capabilities rarely seen in previous systems, including automatic prosodic adaptation during narration and zero-shot generation of natural multi-speaker conversations in multiple languages.
Run online:https://go.hyper.ai/BqZJD
2. Ovis-U1-3B: Multimodal Understanding and Generation Model
Ovis-U1-3B is a multimodal unified model released by the Alibaba Group's Ovis team. This model integrates three core capabilities: multimodal understanding, text-to-image generation, and image editing. Leveraging advanced architecture and collaborative unified training, it enables high-fidelity image synthesis and efficient text-to-visual interaction.
Run online:https://go.hyper.ai/oSA7p

3. Neta Lumina: High-quality 2D-style image generation model
Neta Lumina is a high-quality Anime-style image generation model released by Neta.art. Based on Lumina-Image-2.0, the open-source work by the Alpha-VLLM team at the Shanghai Artificial Intelligence Laboratory, the model leverages massive amounts of high-quality Anime-style images and multilingual labeled data to provide the model with powerful demand understanding and interpretation capabilities.
Run online:https://go.hyper.ai/nxCwD

4. Qwen-Image: An image model with advanced text rendering capabilities
Qwen-Image is a large-scale model for high-quality image generation and editing, developed by the Alibaba Tongyi Qianwen team. This model achieves breakthroughs in text rendering, supporting high-fidelity output at the multi-line paragraph level in both Chinese and English, and accurately reproducing complex scenes and millimeter-level details.
Run online:https://go.hyper.ai/8s00s

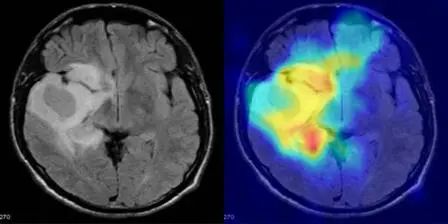
5. MediCLIP: Anomaly Detection in Small Sample Medical Images Using CLIP
MediCLIP, published by Peking University, is an efficient few-shot medical image anomaly detection method that achieves state-of-the-art anomaly detection performance with only a very small number of normal medical images. The model integrates learnable cues, adapters, and realistic medical image anomaly synthesis tasks.
Run online:https://go.hyper.ai/3BnDy
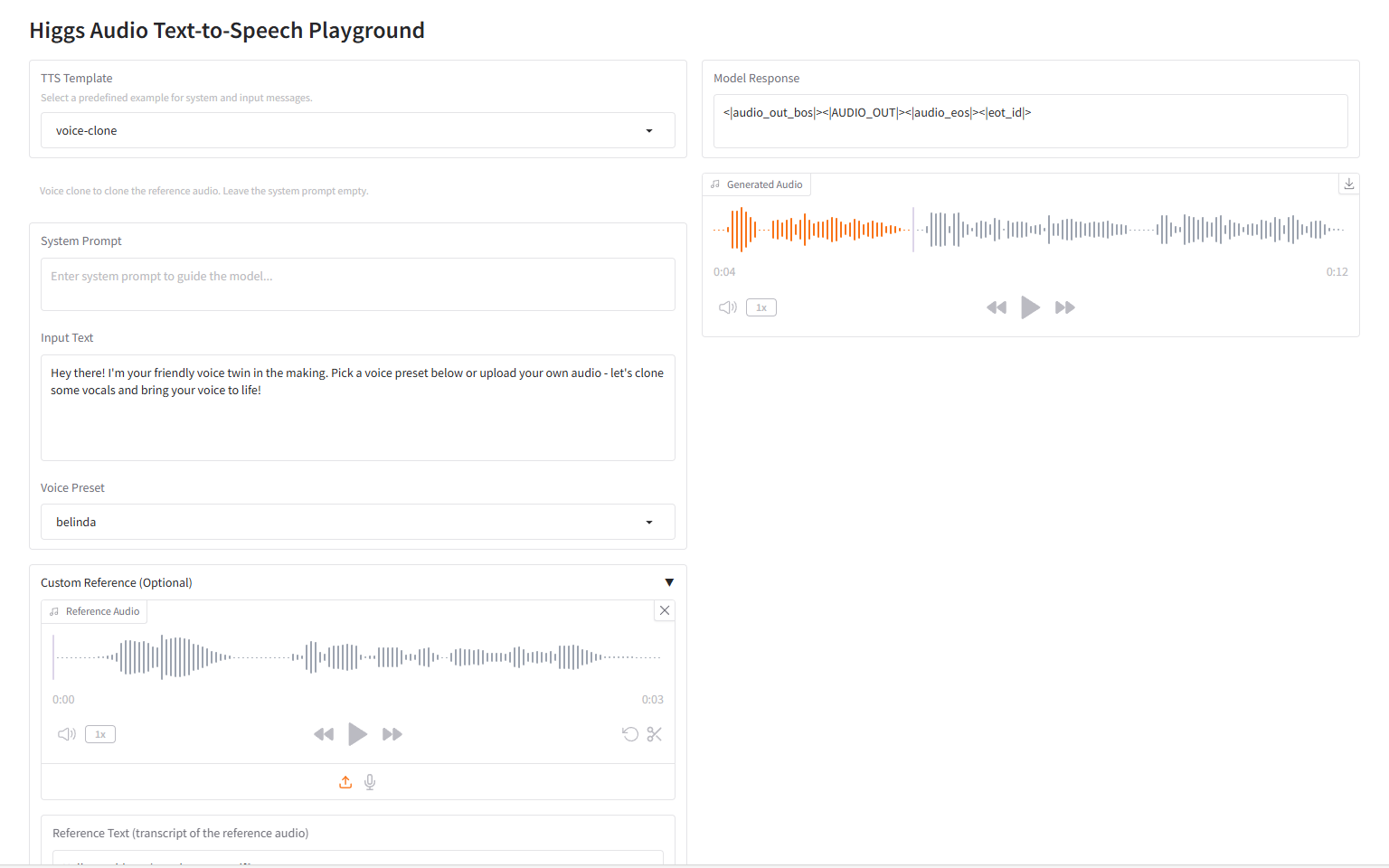
6. Aeneas Model: Ancient Roman Inscription Restoration Demo
Aeneas is a multimodal generative neural network developed by Google DeepMind in collaboration with several universities. It is used for textual restoration, geographical attribution, and chronological attribution of Latin and ancient Greek inscriptions. The release of this model marks a new era in digital epigraphy. Its potential in areas such as ancient text restoration, geographical/chronological attribution, and historical research assistance is enormous, and it is expected to accelerate scientific discovery and interdisciplinary applications.
Run online:https://go.hyper.ai/8ROfT

7. One-click deployment of Qwen3-Coder-30B-A3B-Instruct
Qwen3-Coder-30B-A3B-Instruct is a large language model developed by Alibaba's Tongyi Wanxiang Lab. It demonstrates remarkable performance in open models for proxy coding, proxy browser usage, and other basic coding tasks, and can efficiently handle coding tasks in multiple programming languages. Its powerful contextual understanding and logical reasoning capabilities make it an excellent choice for complex project development and code optimization.
Run online:https://go.hyper.ai/vYf3s
💡We have also established a Stable Diffusion tutorial exchange group. Welcome friends to scan the QR code and remark [SD tutorial] to join the group to discuss various technical issues and share application results~

This week's paper recommendation
1. Qwen-Image Technical Report
Qwen-Image, a foundational image generation model in the Qwen family, has achieved significant progress in complex text rendering and precise image editing. To address the challenges posed by complex text rendering, researchers designed a comprehensive data processing pipeline encompassing large-scale data acquisition, filtering, annotation, synthesis, and balancing. The model achieves state-of-the-art performance across multiple benchmarks, fully demonstrating its powerful capabilities in image generation and editing tasks.
Paper link:https://go.hyper.ai/HWjVM
2. Seed Diffusion: A Large-Scale Diffusion Language Model with High-Speed Inference
This paper proposes Seed Diffusion Preview, a large-scale language model based on a discrete state diffusion mechanism that boasts extremely fast inference speed. Thanks to its non-sequential, parallel generation mechanism, the discrete diffusion model significantly improves inference efficiency and effectively mitigates the inherent latency associated with traditional token-by-token decoding.
Paper link:https://go.hyper.ai/NvrNm
3. Cognitive Kernel-Pro: A Framework for Deep Research Agents and Agent Foundation Models Training
General AI agents are increasingly seen as a cornerstone framework for the next generation of artificial intelligence, enabling complex reasoning, networked interaction, programming, and autonomous research. In this study, researchers propose Cognitive Kernel-Pro, a fully open-source and largely free, multi-module intelligent agent framework designed to democratize the development and evaluation of advanced AI agents.
Paper link:https://go.hyper.ai/65j3v
4. Beyond Fixed: Variable-Length Denoising for Diffusion Large Language Models
In this paper, researchers propose a novel, training-free denoising strategy, DAEDAL, that enables dynamic, adaptive length expansion of DLLMs. Extensive experiments on a variety of DLLMs demonstrate that DAEDAL matches and, in some cases, surpasses the performance of carefully tuned fixed-length baseline models, while significantly improving computational efficiency and achieving a higher effective token ratio.
Paper link:https://go.hyper.ai/p7WxK
5. Skywork UniPic: Unified Autoregressive Modeling for Visual Understanding and Generation
This paper presents Skywork UniPic, a 1.5 billion-parameter autoregressive model that unifies image understanding, text-to-image generation, and image editing within a single architecture, without relying on task-specific adapters or inter-module connectors. By demonstrating that high-fidelity multimodal fusion can be achieved without prohibitive resource costs, Skywork UniPic establishes a practical paradigm for deployable, high-fidelity multimodal AI.
Paper link:https://go.hyper.ai/FiVaf
More AI frontier papers:https://go.hyper.ai/iSYSZ
Community article interpretation
A research team at the University of Nevada, Las Vegas proposed a multivariate analysis method called ICA-Var, which is based on unsupervised machine learning process design. It extracts covariation and time-evolving mutation patterns from wastewater data through independent component analysis, achieving earlier and more accurate detection of variants.
View the full report:https://go.hyper.ai/z1vVo
The Qwen team open-sourced Qwen3-Coder-Flash, which has superior performance among open-source models in proxy coding, proxy browser usage, and other basic coding tasks. It can efficiently handle coding tasks in multiple programming languages. At the same time, its powerful context understanding and logical reasoning capabilities enable it to perform well in complex project development and code optimization.
View the full report:https://go.hyper.ai/FmOep
To address the problem of targeting naturally disordered proteins, David Baker and his team proposed a protein design strategy, called Logos, that allows proteins to bind to naturally disordered regions in a variety of extended conformations, with side chains inserting into complementary binding pockets. This study leverages the RFdiffusion model to reorganize pockets and generalize them to a wide range of sequences, enabling universal recognition of disordered protein regions based on a designed binding protein-target peptide template.
View the full report:https://go.hyper.ai/F0lti
Zhou Hao's research group at the Institute of Intelligent Industries at Tsinghua University, in collaboration with the Shanghai Artificial Intelligence Laboratory, proposed the protein foundation model AMix-1 based on Bayesian flow networks. For the first time, they used the systematic methodology of pretraining scaling law, emergent ability, in-context learning, and test-time scaling to construct a protein foundation model, introducing the successful paradigm of large language models into protein design. Their efficiency and versatility were verified through test-time scaling and real experiments.
View the full report:https://go.hyper.ai/X9iMe
OpenAI has officially released GPT-5, further improving its performance in ChatGPT's three most common use cases: writing, programming, and health. GPT-5 is a unified system consisting of an intelligent and efficient model for answering most questions (GPT-5-main), a deep reasoning model for more complex problems (GPT-5-thinking), and a real-time router that quickly decides which model to use based on the conversation type, question complexity, required tools, and the user's explicit intent.
View the full report:https://go.hyper.ai/gFHQg
Popular Encyclopedia Articles
1. DALL-E
2. Reciprocal sorting fusion RRF
3. Pareto Front
4. Large-scale Multi-task Language Understanding (MMLU)
5. Contrastive Learning
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:https://go.hyper.ai/wiki
August deadline for the summit
August 21 11:59:59 ASPLOS 2026
August 27 7:59:59 USENIX Security Symposium 2025
One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!








