Command Palette
Search for a command to run...
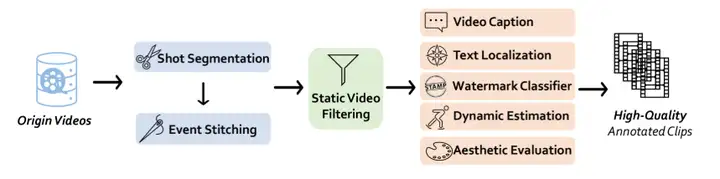
ACL 25 Best Paper! Stanford University Releases Difference-Aware Benchmark Dataset to Build Difference-Aware Fairness; Self-Forcing Achieves Real-Time Streaming Video Generation With Sub-Second Latency

AI models often equate traditional “equal treatment” with fairness.In legal contexts and damage assessment scenarios, mechanically applying the principle of "non-discriminatory treatment" to achieve fairness is not a universal solution.A single fairness dimension can easily lead to biased results, which suggests that group differences should be taken into consideration.Therefore, it is increasingly critical to promote large models to gradually achieve a paradigm shift from "fairness without distinction" to "fairness based on perceived differences."
Based on this,Stanford University released the Difference Aware Fairness benchmark dataset, which aims to measure the performance of models in difference perception and context awareness.The relevant research results have been recognized as ACL's 25 best papers. The dataset contains eight benchmarks, divided into two types: descriptive and normative tasks, covering a variety of real-world scenarios, including legal, professional, and cultural fields. Each benchmark contains 2,000 questions, 1,000 of which require differentiation between different groups, for a total of 16,000 questions. The release of this benchmark improves the fairness dimension of large-scale models, providing a valuable supplement to bridging the gap between technological development and societal value, and strongly promoting the in-depth evolution of the AI ecosystem towards a more diverse and precise direction.
The Difference Aware Fairness Benchmark Dataset is now available on HyperAI's official website. Download it now and give it a try!
Online use:https://go.hyper.ai/XOx97
From July 28th to August 1st, here’s a quick overview of the hyper.ai official website updates:
* High-quality public datasets: 10
* High-quality tutorial selection: 5
* This week's recommended papers: 5
* Community article interpretation: 5 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in August: 9
Visit the official website:hyper.ai
Selected public datasets
1. B3DB Biological Benchmark Dataset
B3DB is a large-scale biological benchmark dataset released by McMaster University in Canada. It aims to provide a benchmark for small molecule blood-brain barrier permeability modeling. The dataset is compiled from 50 published resources and provides a subset of the physicochemical properties of these molecules. Numerical logBB values are provided for some of these molecules, while the entire dataset contains both numerical and categorical data.
Direct use:https://go.hyper.ai/0mPpP
Anime is an anime dataset from http://MyAnimeList.net The database aims to provide a rich, clean, and easily accessible resource for data scientists, machine learning engineers, and anime enthusiasts. The dataset covers information on over 28,000 unique anime works, providing insights into trends in the anime world.
Direct use:https://go.hyper.ai/MxrqC
3. MegaScience Scientific Reasoning Dataset
MegaScience is a scientific reasoning dataset released by Shanghai Jiao Tong University. The dataset contains 1.25 million instances and is designed to support natural language processing (NLP) and machine learning models, especially in tasks such as literature retrieval, information extraction, automatic summarization, and citation analysis in the field of scientific research.
Direct use:https://go.hyper.ai/694qh
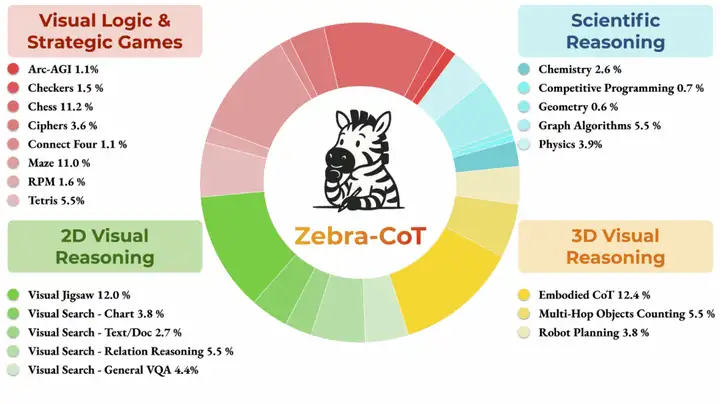
4. Zebra-CoT Text-to-Image Inference Dataset
Zebra-CoT is a visual-linguistic reasoning dataset jointly released by Columbia University, the University of Maryland, the University of Southern California, and New York University. It aims to help models better understand the logical relationships between images and text. It is widely used in fields such as visual question answering and image description generation, helping to improve reasoning capabilities and accuracy. The dataset contains 182,384 samples covering four main categories: scientific reasoning, 2D visual reasoning, 3D visual reasoning, and visual logic and strategy games.
Direct use:https://go.hyper.ai/y2a1e
5. PolyMath Mathematical Reasoning Dataset
PolyMath is a mathematical reasoning dataset jointly released by Alibaba and Shanghai Jiao Tong University. It aims to promote research in polymath. The dataset contains 500 high-quality mathematical reasoning questions, with 125 questions at each language level.
Direct use:https://go.hyper.ai/yRVfY
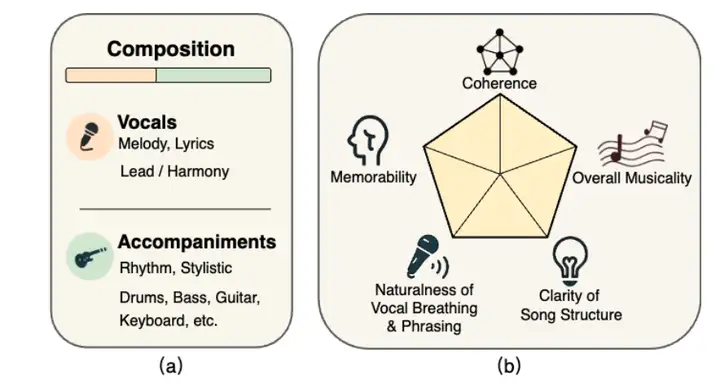
6. SongEval Music Evaluation Dataset
SongEval is a music evaluation dataset jointly released by the Shanghai Conservatory of Music, Northwestern Polytechnical University, the University of Surrey, and the Hong Kong University of Science and Technology. It aims to perform aesthetic evaluations on complete songs. The dataset contains over 2,399 songs (including vocals and instrumentals), annotated by 16 expert raters across five perceptual dimensions: overall coherence, memorability, naturalness of vocal breathing and phrasing, clarity of song structure, and overall musicality. The dataset encompasses approximately 140 hours of high-quality audio, encompassing Chinese and English songs and nine major genres.
Direct use:https://go.hyper.ai/ohp0k
7. Vchitect T2V Video Generation Dataset
Vchitect T2V is a video generation dataset released by the Shanghai Artificial Intelligence Laboratory. It aims to improve models' ability to translate between text and visual content, helping researchers and developers make progress in image generation, semantic understanding, and cross-modal tasks. The dataset contains 14 million high-quality videos, each with detailed text captions.
Direct use:https://go.hyper.ai/vLs9z
8. LED Latin Inscription Dataset
LED is the largest machine-readable Latin inscription dataset to date, comprising 176,861 inscriptions. However, most of these inscriptions are partially damaged, with only 5% inscriptions producing usable images. The data is sourced from three of the most comprehensive Latin inscription databases: the Database of Roman Inscriptions (EDR), the Database of Heidelberg Inscriptions (EDH), and the Clauss-Slaby Database.
Direct use:https://go.hyper.ai/O8noU
9. AutoCaption Video Caption Benchmark Dataset
The AutoCaption dataset is a video captioning benchmark dataset released by Tjunlp Labs. It aims to promote research in the field of multimodal large language models for video caption generation. The dataset contains two subsets, totaling 11,184 samples.
Direct use:https://go.hyper.ai/pgOCw
10. ArtVIP Machine Interactive Image Dataset
ArtVIP is a machine interactive image dataset released by the Beijing Humanoid Robotics Innovation Center. This dataset contains 206 articulated objects across 26 categories. It ensures visual realism through precise geometric meshes and high-resolution textures, achieves physical fidelity through finely tuned dynamic parameters, and is the first to embed modular interactive behaviors within the assets, while also enabling pixel-level affordance annotation.
Direct use:https://go.hyper.ai/vGYek

Selected Public Tutorials
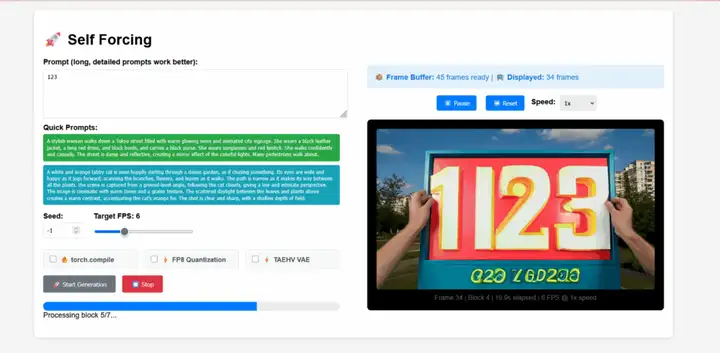
1. Self-Forcing Real-Time Video Generation
Self-Forcing is a novel training paradigm for autoregressive video diffusion models proposed by Xun Huang's team. It addresses the long-standing problem of exposure bias, whereby a model trained on real context must generate sequences based on its own imperfect output during inference. This model achieves real-time streaming video generation with sub-second latency on a single GPU, while matching or even exceeding the generation quality of significantly slower and non-causal diffusion models.
Run online:https://go.hyper.ai/j19Hx
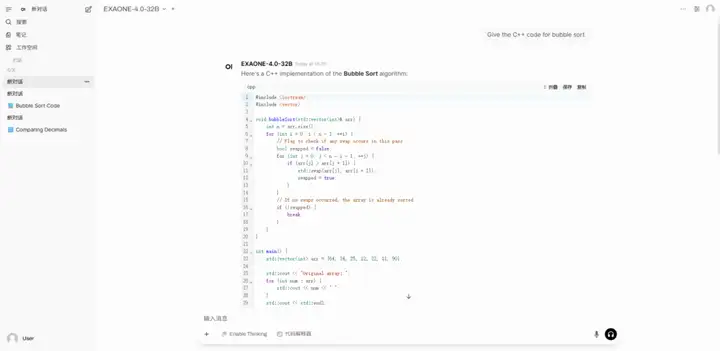
2. Deploy EXAONE-4.0-32B using vLLM + Open WebUI
EXAONE-4.0 is a next-generation hybrid reasoning AI model launched by LG AI Research in South Korea. It is also South Korea's first hybrid reasoning AI model. This model combines general natural language processing capabilities with the advanced reasoning capabilities verified by EXAONE Deep, achieving breakthroughs in challenging fields such as mathematics, science, and programming.
Run online:https://go.hyper.ai/7XiZM
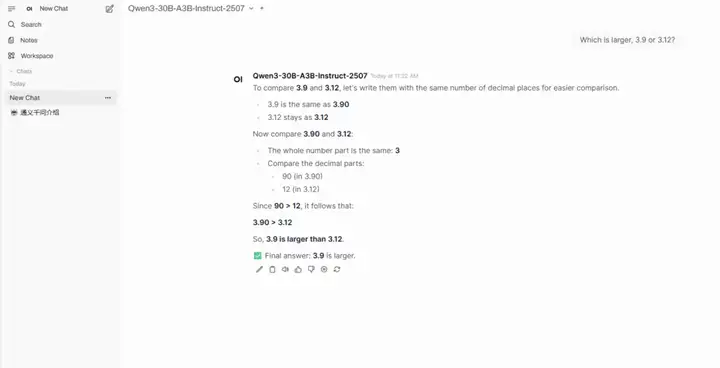
3. One-click deployment of Qwen3-30B-A3B-Instruct-2507
Qwen3-30B-A3B-Instruct-2507 is a large language model developed by Alibaba's Tongyi Wanxiang Lab. This model is an updated version of the Qwen3-30B-A3B's non-thinking mode. Its highlight is that, with only 3 billion (3B) parameters activated, it demonstrates impressive performance comparable to Google's Gemini 2.5-Flash (non-thinking mode) and OpenAI's GPT-4o. This marks a significant breakthrough in model efficiency and performance optimization.
Run online:https://go.hyper.ai/hr1o6
4. Wan2.2: Open Advanced Large-Scale Video Generation Model
Wan-2.2 is an open-source, advanced AI video generation model developed by Alibaba's Tongyi Wanxiang Lab. This model introduces a Mixture of Experts (MoE) architecture, effectively improving generation quality and computational efficiency. It also pioneers a cinematic aesthetic control system, enabling precise control of lighting, color, composition, and other aesthetic effects.
Run online:https://go.hyper.ai/AG6CE
5. PE3R: A Framework for Efficient Perception and 3D Reconstruction
PE3R (Perception-Efficient 3D Reconstruction) is an innovative open-source 3D reconstruction framework released by the XML Lab at the National University of Singapore (NUS). It integrates multimodal perception technologies to achieve efficient and intelligent scene modeling. Developed based on multiple cutting-edge computer vision research findings, it rapidly reconstructs 3D scenes from only 2D images. On an RTX 3090 graphics card, the average reconstruction time for a single scene is just 2.3 minutes, an improvement of over 65% compared to traditional methods.
Run online:https://go.hyper.ai/3BnDy

This week's paper recommendation
1. Agentic Reinforced Policy Optimization
In real-world reasoning scenarios, large language models (LLMs) often benefit from external tools to assist in solving tasks. However, existing reinforcement learning algorithms struggle to balance the model's inherent long-range reasoning capabilities with its proficiency in multi-round tool interactions. To bridge this gap, this paper proposes Agent Reinforcement Policy Optimization (ARPO), a novel agent reinforcement learning algorithm designed specifically for training multi-round LLM-based agents. It achieves performance improvements with only half the tool usage budget of existing methods, providing a scalable solution for aligning LLM-based agents with real-time dynamic environments.
Paper link:https://go.hyper.ai/lPyT2
Generating immersive and interactive 3D worlds from text or images remains a fundamental challenge in computer vision and graphics. Existing world generation methods suffer from limitations such as insufficient 3D consistency and low rendering efficiency. To address this, this paper proposes an innovative framework, HunyuanWorld 1.0, to generate immersive, explorable, and interactive 3D scenes from text and images.
Paper link:https://go.hyper.ai/aMbdz
Despite recent progress in text-to-code generation using large language models (LLMs), many existing methods rely solely on natural language cues, struggling to effectively capture the spatial structure of layouts and visual design intent. In contrast, real-world UI development is inherently multimodal and often begins with visual sketches or prototypes. To bridge this gap, this paper proposes ScreenCoder, a modular multi-agent framework that enables UI-to-code generation through three interpretable phases: localization, planning, and generation.
Paper link:https://go.hyper.ai/k4p58
4. ARC-Hunyuan-Video-7B: Structured Video Comprehension of Real-World Shorts
Current large-scale multimodal models lack the necessary temporally structured, detailed, and in-depth video understanding capabilities, which are fundamental to effective video search and recommendation, as well as emerging video applications. This study proposes ARC-Hunyuan-Video, a multimodal model that processes visual, audio, and text signals end-to-end from raw video input to achieve structured understanding. The model features multi-granular timestamped video description and summarization, open-ended video question answering, temporal video localization, and video reasoning.
Paper link:https://go.hyper.ai/ogYbH
5. Deep Researcher with Test-Time Diffusion
When using common test-time scaling algorithms to generate complex and lengthy research reports, their performance often bottlenecks. Inspired by the iterative nature of the human research process, this paper proposes the Test-Time Diffusion Deep Researcher (TTD-DR). TTD-DR begins the process with a preliminary draft (an updateable framework) that serves as an evolving foundation to guide research direction. This draft-centric design makes the report writing process more timely and coherent while reducing information loss during iterative search.
Paper link:https://go.hyper.ai/D4gUK
More AI frontier papers:https://go.hyper.ai/iSYSZ
Community article interpretation
A team led by Shi Boxin of Peking University, in collaboration with OpenBayes Bayesian computing, has launched PanoWan, a framework for text-guided panoramic video generation. This approach, with its minimalist and efficient modular architecture, seamlessly transfers the generative priors of pre-trained text-to-video models to the panoramic domain.
View the full report:https://go.hyper.ai/9UWXl
A research team from Universiti Putra Malaysia (UPM) and the University of New South Wales (UNSW) Sydney have jointly developed an intelligent framework for the automatic classification and market value estimation of ceramic artifacts based on the YOLOv11 model. The optimized YOLOv11 model can identify key ceramic attributes such as decorative patterns, shapes, and craftsmanship, and predict market prices based on extracted visual features and multi-source auction data. This provides a scalable solution for intelligent ceramic authentication and digital artifact curation.
View the full report:https://go.hyper.ai/XcuLz
A research team from the University of Pennsylvania in the United States integrated four major venom databases to build a global venom database, and applied a sequence-to-function deep learning model called APEX, which is specifically used to systematically mine potential antibacterial candidates in the venom proteome. They ultimately screened out 386 candidate peptides with antibacterial potential and low sequence similarity with known AMPs.
View the full report:https://go.hyper.ai/u067l
A joint research team from NVIDIA, Lawrence Berkeley National Laboratory, University of California, Berkeley, and California Institute of Technology has launched FourCastNet 3 (FCN3), a probabilistic machine learning weather forecasting system that combines spherical signal processing with a hidden Markov set framework. It can produce a 15-day forecast in 60 seconds on a single NVIDIA H100 GPU.
View the full report:https://go.hyper.ai/JQh25
Alibaba's Tongyi Wanxiang Lab recently open-sourced its advanced AI video generation model, Wan2.2. This model, which introduces a Mixture of Experts (MoE) architecture, effectively improves generation quality and computational efficiency, enabling efficient operation on consumer-grade graphics cards such as the NVIDIA RTX 4090. It also pioneered a cinematic aesthetic control system, enabling precise control of lighting, color, composition, and other aesthetic effects.
View the full report:https://go.hyper.ai/RgFmY
Popular Encyclopedia Articles
1. DALL-E
2. Reciprocal sorting fusion RRF
3. Pareto Front
4. Large-scale Multi-task Language Understanding (MMLU)
5. Contrastive Learning
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:

One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!








