Command Palette
Search for a command to run...
Based on Over 176k Inscription Data, Google DeepMind Released Aeneas, Which for the First Time Achieved Arbitrary Length Restoration of Ancient Roman Inscriptions

All memories of the early human civilization are hidden in inscriptions and words. Inscriptions are one of the earliest forms of writing, providing a window for people to understand the thoughts, language and history of ancient civilizations. From the emperor's decrees to the tombstones of slaves, these words engraved on stone tablets and bronzes have become direct evidence for determining the age and understanding the culture. It is estimated that 1,500 new Latin inscriptions are still discovered every year, but the study of epigraphy faces many difficulties such as incomplete texts, difficulties in interpretation, and limited knowledge.
On July 23, 2025, researchers from Google DeepMind, together with the University of Nottingham, the University of Warwick and other universities, published a research paper titled "Contextualizing ancient texts with generative neural networks" in the world's top academic journal Nature.
This research contains three major innovative highlights:
* Aeneas is able to receive both text transcription and image information of the inscription. The image is processed by a shallow visual neural network and combined with text features, it is particularly helpful for geographical attribution tasks.
* Previously, AI could only repair texts of known length, but Aeneas broke through the repair limitations and pioneered the ability to "repair texts of any length" for the first time.
* Aeneas' core capability is to find the most relevant "parallel texts" for the target inscription. These parallel texts not only contain similar phrases, but also cover deep connections such as cultural background and social functions, far beyond the limitations of traditional string matching.
Model architecture: Multimodal generative neural network Aeneas
Aeneas is a multimodal generative neural network.A Transformer-based decoder is used to process the text and image input of the inscription, and a shallow visual neural network is used to retrieve similar inscriptions from the Latin inscription dataset and sort them by relevance. The input text is processed by the core part of the model, the "torso".
Aeneas is designed for contextual analysis of Latin inscriptions. Its architecture consists of input processing, core modules, task headers, and contextualization mechanisms.
Input processing:The input is the character sequence of the inscription and a 224×224 grayscale image. The character sequence is up to 768 characters long, "-" is used to mark missing characters of known length, "#" is used to mark missing characters of unknown length, and < is used as the sentence start marker;
Core modules:The text is processed by a torso improved on the T5 Transformer decoder, with 16 layers, 8 attention heads per layer, and relative position rotation embedding, and the image is processed by a ResNet-8 visual network. The outputs of the torso and visual networks are then directed to dedicated neural networks in heads, which use the text to handle character restoration and dating tasks, and each head is customized to handle 3 key epigraphic tasks.
Task Header (task head):The output has dedicated task heads for text repair (including auxiliary heads for unknown length repair, using beam search to generate hypotheses), geographic attribution (combining text and visual features to classify 62 Roman provinces), and chronological attribution (mapping dates into 160 discrete decade intervals), all with saliency maps.
Contextualization Mechanism:By integrating the intermediate representation of torso and task head to generate historically enriched embeddings, relevant parallel inscriptions are retrieved based on cosine similarity to assist historians in their research.
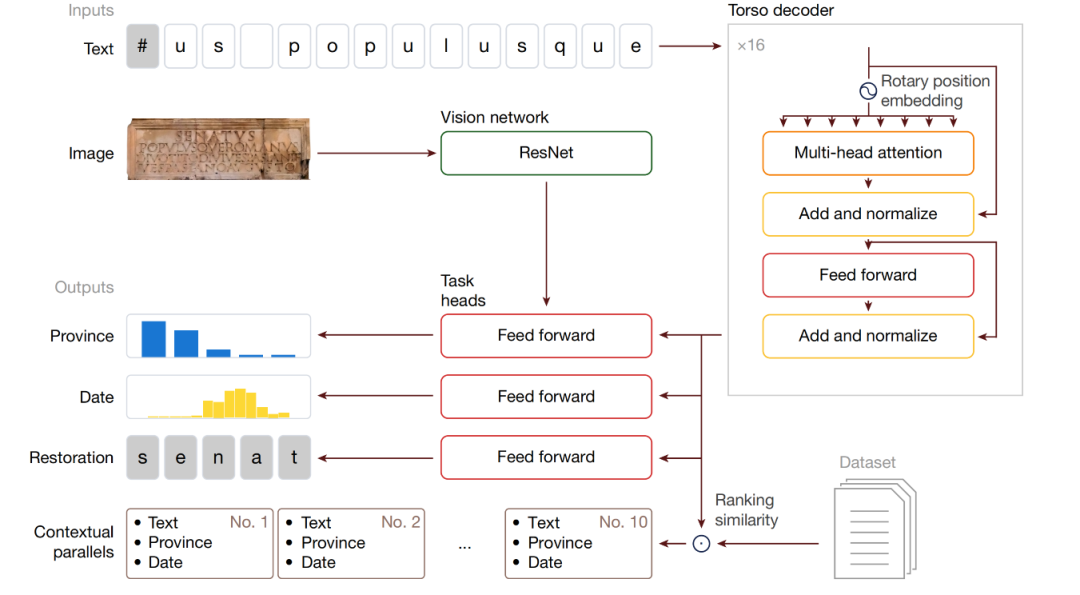
Take Aeneas’s processing of the phrase “Senatus populusque Romanus” as an example: given an image of an inscription and its text transcription (where damaged parts of unknown length are marked with “#”), Aeneas processes the text using torsos. Heads are responsible for character recovery, dating, and geographic attribution (the geographic attribution task also incorporates visual features). The intermediate representations of torsos are fused into a unified, historically rich embedding vector to retrieve similar inscriptions from the Latin Inscriptions Dataset (LED) and sort them by relevance.
It should be noted thatThe Aeneas model incorporates additional input from the vision network only for the geo-attribution heads; the text inpainting and chronological attribution tasks do not use the visual modality.The restoration task excludes visual input to prevent accidental information "leakage". Since part of the text is artificially masked and its exact position in the image is unknown, the model may use visual clues to infer and restore the hidden characters, thereby compromising the integrity of the task.
Dataset: The largest machine-readable dataset of Latin inscriptions
The corpus database used to train the Aeneas model is called the Latin Inscriptions Dataset (LED) in the study, which is the largest machine-operable Latin inscriptions dataset to date. The comprehensive corpus data of the LED dataset comes from the three most comprehensive Latin inscription databases: the Roman Inscription Database (EDR), the Heidelberg Inscription Database (EDH), and the Clauss-Slaby database, which contain inscriptions from the seventh century BC to the eighth century AD, and the geographical coverage ranges from the Roman provinces of Britannia (now Britain) and Lusitania (Portugal) in the west to Egypt and Mesopotamia in the east. To ensure the consistency of the entire LED dataset, the study used identifiers in the Trismegistos data platform to handle ambiguities in the data, and applied a set of filtering rules to systematically process human annotations so that the text can be processed by machines.
To obtain standardized metadata,The study converted all metadata related to dates and historical periods into numbers ranging from 800 BC to 800 AD.Inscriptions outside this range were excluded. In order to improve the learning and generalization capabilities of the model, the substantive text content in the dataset was converted into a machine-operable format according to the standard:
* Remove or normalize the historians' annotations on the inscription and keep the version that is closest to the original inscription.
* Latin abbreviations are not parsed, while word forms that display alternative spellings for diachronic, bidirectional, or inflectional reasons are retained so that the model learns their epigraphic, geographical, or chronological specific variations.
* Preserve missing characters that were restored by the editor or that could not be ultimately restored, use pound signs (#) as placeholders when the exact number of missing characters is uncertain, and collapse extra spaces to ensure concise output.
* Remove non-Latin characters, leaving only Latin characters, predefined punctuation marks, and placeholders.
* Filter duplicate inscriptions. Texts exceeding the 90% content similarity threshold are considered duplicates.
After converting the format, the study divided the LEDs into training, validation, and test sets based on the last digit of the unique inscription identifier, ensuring an even distribution of images across subsets.

After implementing the automatic filtering process, the study obtained usable inscription images from the dataset by applying a threshold to the color histogram to eliminate images mainly composed of a single pure color, using the variance of the Laplacian matrix to identify and discard blurred images, and converting the cleaned images into grayscale images. The LED dataset contains a total of 176,861 inscriptions, but most of them are partially damaged, and only 5% inscriptions can produce usable corresponding images.
Experimental conclusion/performance
The researchers evaluated the performance of the Aeneas model from three aspects: task execution, Onomastics baseline, contextualization mechanism and research efficiency.
* Onomastics is the study of the origin, structure, evolution and meaning of proper names such as names of people, places, tribes and gods.
Task execution indicators
This study uses three indicators of text restoration, geographical attribution and temporal attribution to form an evaluation framework.Among them, the researchers used artificial methods to destroy text of arbitrary length and submitted the model to generate repaired objects; in the geographic attribution task, the standard Top-1 and Top-3 accuracy indicators were used to evaluate the performance; for time attribution, an explainable indicator was used to evaluate the temporal proximity between the predicted results and the real data.
Experiments show that Aeneas' architecture provides multimodal capabilities.Able to recover text sequences of unknown length,It can also be adapted to any ancient language and written media such as papyrus and coins, capturing the connection between inscriptions and history in the contextualization process of ancient text research.
Onomastics baseline
The Aeneas model's automated evaluation of metadata derived from Onomastics becomes a key indicator of its attribution prediction capabilities.Since there is no pre-compiled list of Roman proper nouns,The research team manually removed 350 items from the proper noun repository that did not represent proper nouns.Entries that were shorter or contained non-Latin characters due to usage ambiguity were excluded, resulting in a curated list of approximately 38,000 proper nouns.
To enhance the robustness of the approach, the most common words in the dataset were identified and filtered to consist only of entries from a curated list of proper nouns, and their average temporal and geographical distribution in the training dataset was then calculated so that the Aeneas model could leverage the processed proper noun data to predict the date and provenance of new inscriptions when analyzing them.
The evaluation method of the Aeneas model for this task can be applied to the entire dataset and achieves improved scalability.
Contextualization Mechanism and Research Efficiency
The study evaluated the effectiveness of the contextualization mechanism of the Aeneas model as a fundamental tool for historical research. 23 epigraphers from diverse backgrounds participated anonymously in the evaluation.Based on the experience of executing three inscription tasks, the efficiency of using Aeneas contextualization mechanism as a research auxiliary tool was evaluated:
* The Aeneas model can significantly reduce the time spent searching for relevant information, allowing researchers to focus on deeper historical interpretation and the construction of research questions.
* The information retrieved by the Aeneas model is accurate and provides valuable insights into the type and context of the inscription, helping advance the research task.
* Aeneas broadens searches and refines results by identifying important but previously unnoticed related information and overlooked text features.
Some experts doubt the authenticity
"Aeneas is the beginning of artificial intelligence in the field of history," said David Galbraith, a technical expert in the field of artificial intelligence. The breakthrough of Aeneas is not only a technical advancement, but also a sign of the deep integration of humanities and AI. For historians, it is not a replacement for scholars, but more of a "super assistant" to reduce mechanical labor and expand research horizons. At the same time, in the field of AI, it proves the potential of multimodal and contextualized models in processing complex humanities data, and provides a model for the future development of research on other ancient languages.
Aeneas still has limitations. In the face of Aeneas's breakthrough, another artificial intelligence expert expressed concern that "over-reliance on AI to fill in the gaps will raise questions about authenticity."

Admittedly, AI is a tool, not a real substitute. In the training data, only 5% of inscriptions are equipped with images, and the number of inscriptions in some regions (such as Sicily) and periods (such as before 600 BC) is insufficient, resulting in a decrease in prediction accuracy. These are all warnings that the current AI technology is still immature, and we should rationally choose its proportion in scientific research and life.








