Command Palette
Search for a command to run...
Tile-level Primitives Are Integrated With Automatic Reasoning mechanisms. The Initiator of the TileAI Community Deeply Analyzes the Core Technology and Advantages of TileLang

On July 5, the 7th Meet AI Compiler Technology Salon was successfully concluded in Beijing. Experts from the industry shared the latest developments and practical and implementation experiences, while researchers from universities explained in detail the implementation paths and advantages of innovative technologies.
in,Dr. Lei Wang, founder of the TileAI community, gave a speech titled “Bridge Programmability and Performance in Modern AI Workloads”.The innovative operator programming language TileLang is introduced in an easy-to-understand manner, sharing its core design concepts and technical advantages.
TileLang aims to improve the efficiency of AI kernel programming, decoupling the scheduling space (including thread binding, layout, tensorize, and pipeline) from the data flow and encapsulating it into a set of customizable annotations and primitives. This approach allows users to focus on the kernel data flow itself, while leaving most other optimization work to the compiler.
The evaluation results show thatTileLang achieves industry-leading performance on multiple key kernels.It fully demonstrates its unified Block-Thread programming paradigm and transparent scheduling capabilities, which can provide the required performance and flexibility for modern AI system development.
HyperAI has compiled and summarized the speech without violating the original intention. The following is the transcript of the speech.
Follow the WeChat public account "HyperAI Super Neuro" and reply to the keyword "0705 AI Compiler" to obtain the authorized lecturer's speech PPT.
Why do we need a “new DSL”?
This sharing mainly introduces the new DSL TileLang for AI Workloads that our team open-sourced on GitHub in January 2025.
First of all, I would like to talk to you about why we need a new DSL?
From a personal perspective, during my internship at Microsoft, I participated in a project called BitBLAS to study mixed-precision computing. At that time, it was mainly based on TVM/Tensor IR, and finally achieved very good experimental results. However, we still found that it had many problems, such as difficulty in maintenance. For each operator, such as the mixed-precision calculation of the matrix layer, I wrote 500 lines of Schedule Primitives. Although it was written elegantly,But I am the only one who can understand this scheduling code, and it is difficult to find others to maintain or expand it.
In addition, I found that it was difficult to describe new requirements or optimizations based on the Schedule IR. For example, when I was working on the kernel, I wrote three Schedule Primitives to assist in optimizing the program, including Flash Attention, Linear Attention, etc. These operators were difficult to describe based on the Schedule. Therefore, I thought at the time that if the project was to continue to scale, using TIR might not work, and other solutions were needed.
So why not Triton?
I also tried Triton,But I found it difficult to customize a high-performance kernel.For example, when I write the Dequantize operator, I may need to control the behavior of each thread. How to implement the Dequantize of each thread on a high-performance kernel is still very particular.
The second is how to cache the Buffer into a suitable Memory Scope.For example, on some GPUs, it is better to cache data in registers for dequantization and then write it to shared memory, while on others, it is better to write it directly back to shared memory. But it is difficult to control on Triton.
at last,I think Triton's Index is a bit complicated.For example, if you need to cache a Tile to Local, you need to write the code shown on the left side of the figure below, but on the Tensor IR you can use subscripts to index as shown on the right, which I think is very good.
Based on this, I found that the existing DSLs could not meet my needs, so we wanted to make an innovative DSL that supports more backends and custom operators and achieves better performance.To achieve better performance, it is necessary to optimize various design spaces such as Tiling and Pipeline.To this end, we proposed the TileLang project.
What is TileLang?
Why "Tile"?
First, we found that the concept of Tile is very important. As long as the hardware has the concept of cache, registers, and shared memory, then when writing high-performance programs, we must consider computing blocks, that is, Tile. Secondly, because everyone tends to write Python programs, we want to design a Python-like programming language that is as easy to write as Triton and has better performance.
To this end, we designed the framework shown on the right side of the following figure:If you are an expert,That is, if you know CUDA or hardware well, you can directly write low-level code;If you are a developer,That is, if you can write Triton and understand concepts such as Tile and register, you can write a Tile-level program just like writing Triton;If you are a beginner who knows nothing about hardware and only knows algorithms,Then you can write a high-level expression like writing TRL, and then use Auto Schedule to Lower it into the corresponding code.
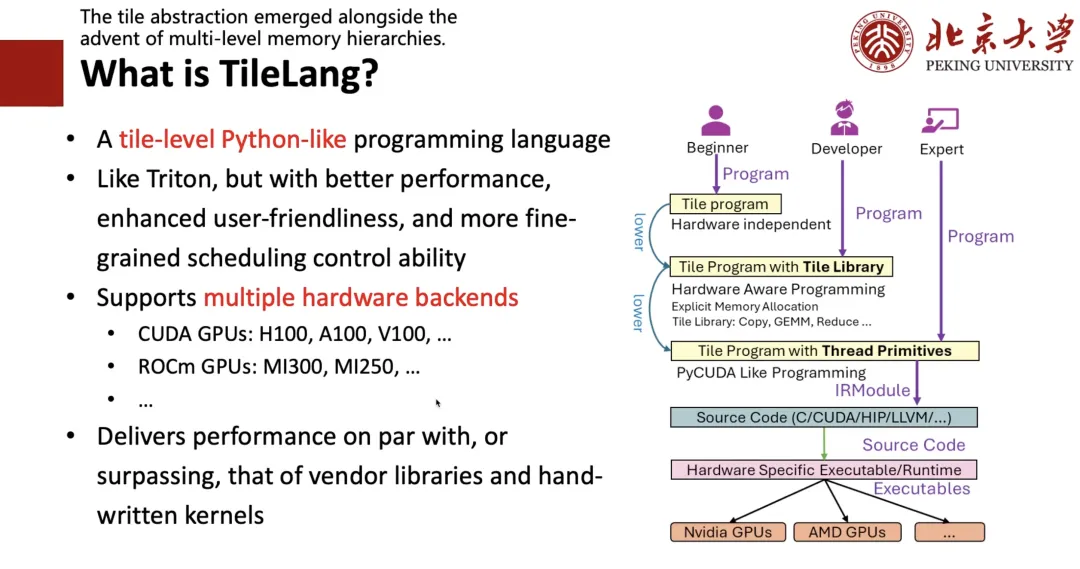
As shown in the figure below, the Dequant Schedule on the left is written by me using TIR, which can be seamlessly equivalently written in the form of TileLang on the right, realizing the coexistence of Level 1 and Level 2.

Next, I will introduce what issues need to be considered in the design of TileLang.
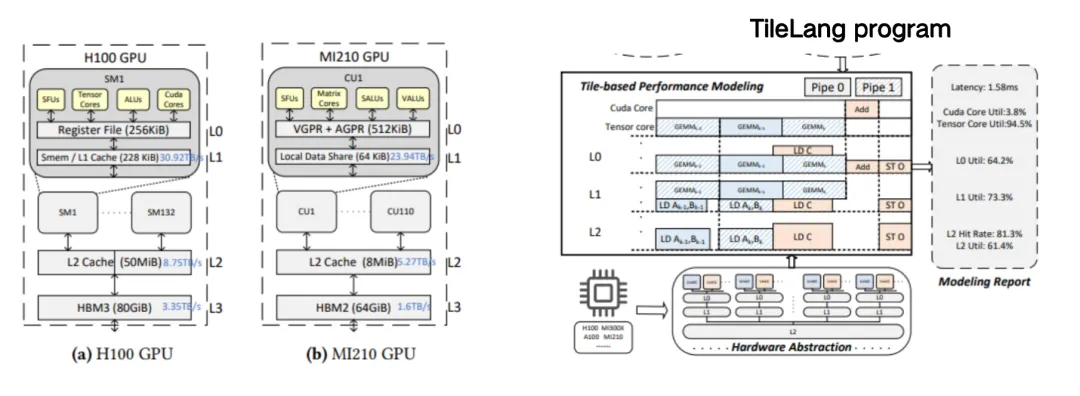
The left side of the figure below is the TileLang implementation of DeepSeek MLA, which has about 50 lines of code. In this kernel, we can see that users need to manage many things, such as how many blocks (thread blocks) need to be specified to perform computing tasks in parallel when starting a GPU kernel (kernel function), and how many threads should be given to each block? This is what we call Tile Configuration, that is, each code below has a context. Users need to control which memory scope the buffer is on, and also need to decide what the layout of shared memory or registers is, and also need to pay attention to pipelines, etc. These all require the compiler to help users manage.

For this purpose, we divide the optimization space into two categories:One is Inference.That is, the compiler directly helps the user to derive a better solution;One is Recommend,That is, selecting a plan through recommendation.
After comprehensively considering all optimization spaces,We compressed a high-performance FlashMLA implementation that originally consisted of more than 500 code blocks into only 50 lines of TileLang code, while retaining the performance of 95%.
Next, I will introduce TileLang from the very bottom.
As shown in the figure below, students who are familiar with TIR should be able to find that this is a TIR expression. Then, we can do PyCUDA programming based on TIR. For example, if we write two Python negative loops, we can generate them into CUDA expressions through TIR Codegen.
If we use thread primitives, such as vectorization, we can implement CUDA vectorization, and further implement thread binding. The above are all programs that TIR originally has, and users can write programs like writing CUDA, but it is still more complicated to write in Python.
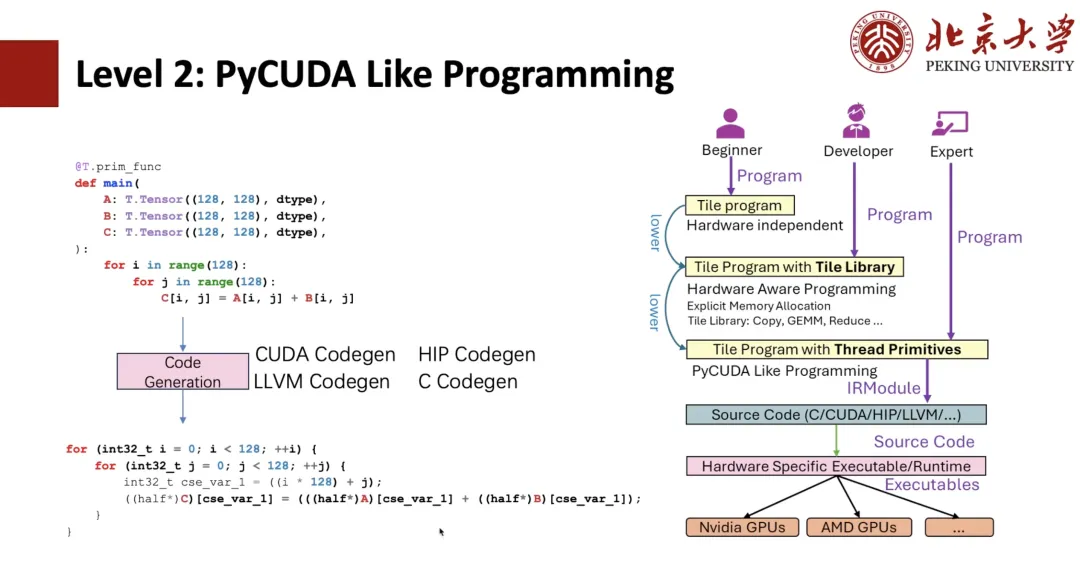
In order to make the operation easier for users,The writing method of Level 1 Tile Library was proposed.For example, we give a kernel context with 128 threads, and then wrap Copy with "T.Parallel". After the compiler's inference, it can deduce the high-performance form just shown, and finally codegen into a CUDA code. If you want to be more "elegant", you can directly write "T.copy" and directly expand Copy into the expression of "T.Parallel".
T.Parallel can not only perform Copy, but also implement complex calculations, and can automatically implement vectorization and thread binding. Currently, in addition to Copy, we also provide a collection of Tile Libraries such as Reduce, Fill, Clear, etc. Then, based on Tile Library, you can write a good operator like Triton.
So,The core concept that supports "T.Parallel" is Memory Layout.
In TileLang, we support indexing multidimensional arrays using high-level interfaces, such as A[i, k]. This high-level index is ultimately converted to a physical memory address through a series of software and hardware abstraction layers. In order to model this index conversion process,We introduced Layout to describe how data is organized and mapped in Memory.
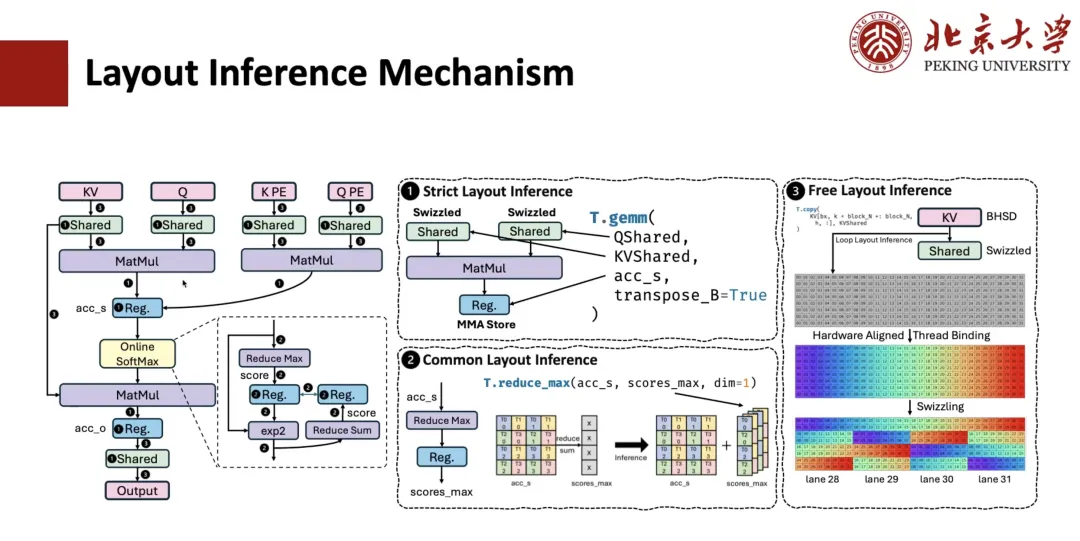
How is the layout derivation for MLA calculations implemented? Usually, this process includes 3 steps.
The first step is Strict Layout Inference.For example, operators like matrix multiplication have strong constraints on data layout and must follow the specified layout, so the layout of the registers connected to it is also determined. If shared memory is involved and we know that this operator needs to perform a spill operation, then the corresponding memory layout will also be determined.
The second step is Common Layout Inference.For example, for expressions connected to the determined Layout in the previous step, their Layout should also be determined. For example, suppose we have a reduce operation from accum_s to scope_max, where the Layout of QMS is specified through the matrix layer, then we can deduce the Layout of scope_max based on it. Through this level of general reasoning, the Layout of most intermediate expressions can be determined.
The third step is Free Layout Inference.That is, the remaining Free Layout is deduced. Since it is not strongly constrained, some Layout Inference strategies aligned with the hardware are usually adopted to infer the optimal Layout solution based on the access mode and Memory Scope.
The following describes how Pipeline performs derivation.
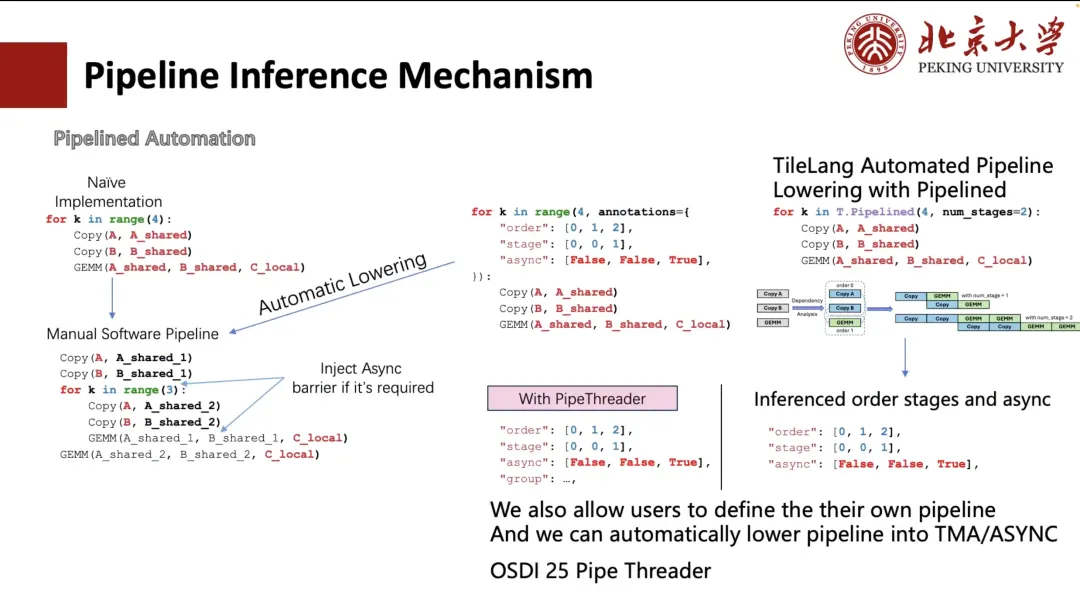
Generally, we can manually expand the Pipeline, but this writing method is cumbersome and not user-friendly. Therefore, TVM has explored simplifying the process through annotation. Users only need to specify the execution order and scheduling stage of the loop.TVM can automatically transform the loop into a structure equivalent to manual unrolling (as shown in the lower left corner of the figure below).
But it is still complicated and troublesome for users. Therefore, in TileLang, we reduce it to "num_stage". Users only need to specify the "num_stage" value, and the system can automatically analyze the dependencies in the calculation and schedule and divide them accordingly. On GPU or most other devices, in fact, only Copy and GEMM can achieve true asynchronous execution, especially Copy operation, which can support asynchronous transmission through mechanisms such as ASYNC or TMA.
therefore,In scheduling, we will separate the copy operation into a separate stage.And automatically derive the appropriate stage division for the entire Pipeline. Of course, users can also choose to manually specify the scheduling method, such as the two custom arrangements shown in the figure on the left.
In addition, we also support automatic layout inference and scheduling optimization based on hardware features (such as TMA modules on A100 and H100). This part of the work comes from our project Pipe Threader that will be published at OSDI 25 this year.
Next, I will share with you the Inference of instructions.
Taking matrix multiplication as an example, there are many hardware instructions that can be called for "T.GEMM". For example, under INT8 precision, it may be possible to use DP4A instructions, or use INT8 implementation based on TensorCore. And each instruction itself supports multiple shapes, so how to choose the optimal Tile configuration among these implementations is a key issue.
To this end, TileLang provides two ways of use:
The first is that TileLang allows users to write ASM by calling PTX.But the disadvantage of this method is that the combination space is huge - if you want to be compatible with all PTX, you need to write a lot of code, and you also need to manage Layout. But this method is very free, and I personally like this method very much.
But we are now using the second method.That is, "T.GEMM" is followed by a Tile Library such as CUTE/CK-TILE.It provides a tile-level library interface commonly used for matrix multiplication, but its disadvantage is that it takes a very long time to compile due to template expansion. On RTX 4090, compiling a Flash Attention may take 10 seconds, of which more than 90% is spent on template expansion. Another problem is that it is highly separated from the Python front end.
So we think,Tile Library is a direction we will focus on in the future.That is, through Tile's native syntax, various Tile-level libraries such as "T.GEMM" and "T.GEMMSP" are supported.
Future work prospects
Finally, I would like to introduce to you some of our team’s future work.
The first is Tile Sight, which is specifically designed to accelerate the performance optimization of large-scale complex kernels (such as FlashAttention and FlashMLA) in large language models.This is a lightweight automatic tuning framework that aims to generate and evaluate efficient Tile configurations (i.e. tiling strategies or scheduling hints) for multiple backends such as GPUs, CPUs, and accelerators, helping developers quickly find scheduling strategies with superior performance and reduce manual tuning time.
Based on the above custom model, it is easier for users to write a difficult kernel, such as MLA. The custom model can guide users to place each cache on the corresponding shared.
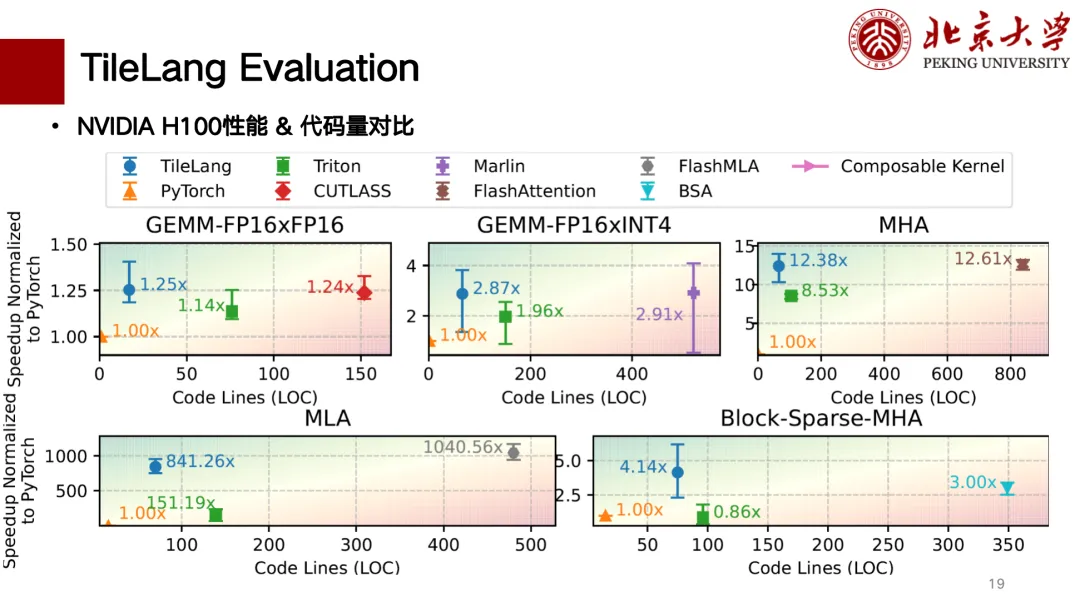
Below is a partial performance evaluation of TileLang. We have mainly completed the support for H cards and A cards. The figure below is a correlation comparison chart between the number of lines of code and performance. The performance is better towards the upper left corner. Among them, for matrix multiplication, TileLang can achieve performance similar to CUTLASS. In addition, operators such as MLA, Flash Attention, Block Sparse, etc. can also achieve similar performance to CUTLASS, and the number of lines of code is relatively small, and it is also relatively "clean" to write.
In the TileLang ecosystem, some users are already using it. For example, the core quantization operator of Microsoft's low-precision large model BitNet model is developed based on TileLang, and Microsoft's BitBLAS is also completely based on TileLang. In terms of domestic chip support, we have also provided some support for Suanneng TPU and Ascend NPU.








