Command Palette
Search for a command to run...
Online Tutorial | Mistral AI's First Open Source Audio Model Voxtral, 24B and 3B Versions Take Into Account multi-scenario Speech Deep Understanding

As the most natural way of interaction for humans, voice is gradually becoming the core scenario of human-computer interaction. With the popularization of voice interaction, audio models are also constantly innovating and optimizing according to demand.However, rapid development is accompanied by polarization of market supply: low-cost open source models are more prone to problems such as high error rates and weak semantic understanding, while high-cost closed-source models are usually expensive and have deployment limitations. Both are difficult to meet diverse needs.
Based on this,Mistral AI recently officially released its first advanced audio model, Voxtral, which focuses on the pain points of the voice intelligence market with open source high performance and low cost.The model is available in two versions: 24B and 3B. The former is suitable for enterprise-level large-scale deployment, while the latter lowers the entry threshold for individual lightweight deployment. In terms of functions, based on excellent voice transcription and deep understanding capabilities, Voxtral supports multiple languages, long text context processing, built-in question-answering and summarization functions, and its performance surpasses existing open source audio models in multiple benchmarks. At the same time, it is lower in cost and widely used in various scenarios, helping to popularize voice interaction.
Voxtral is using technology to promote the qualitative change of voice interaction models from "usable" to "easy to use".It not only meets the market demand for high-performance audio models, but also broadens the application scenarios of voice interaction, truly building the intelligent ecological cornerstone of natural dialogue.
「Voxtral-Small-3B/24B-2507 speech understanding model Demo」The "Tutorial" section of HyperAI's official website (hyper.ai) is now online.Let us start an immersive experience of voice interaction where we can “hear more accurately and understand more deeply” and witness new breakthroughs in advanced audio models!
Tutorial Link:
* Voxtral-Mini-3B-2507 speech understanding model Demo:
* Voxtral-Small-24B-2507 speech understanding model Demo:
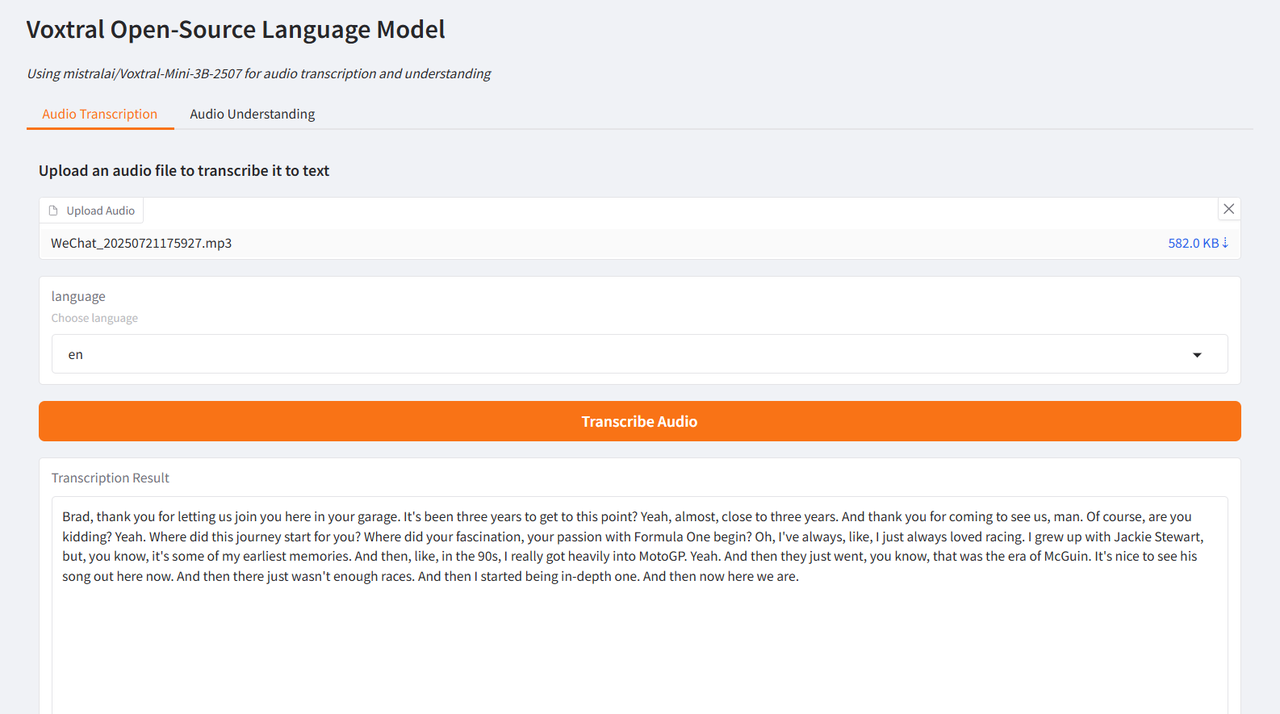
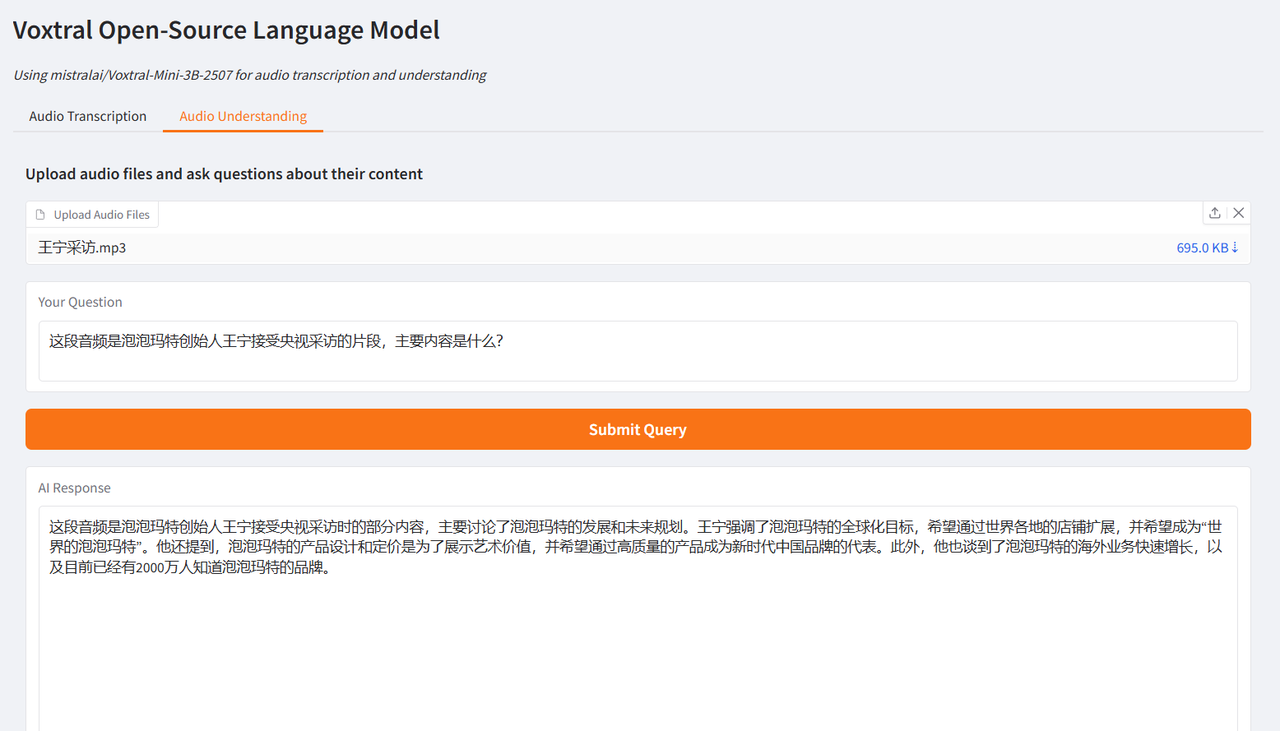
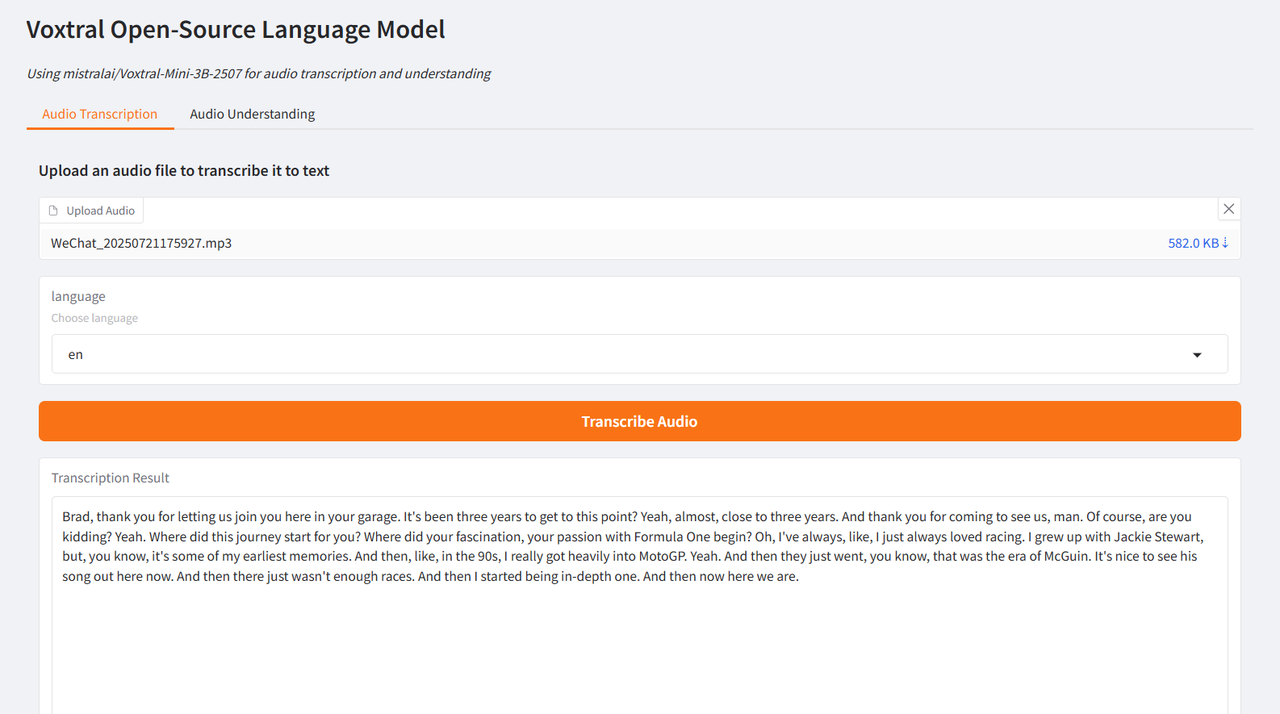
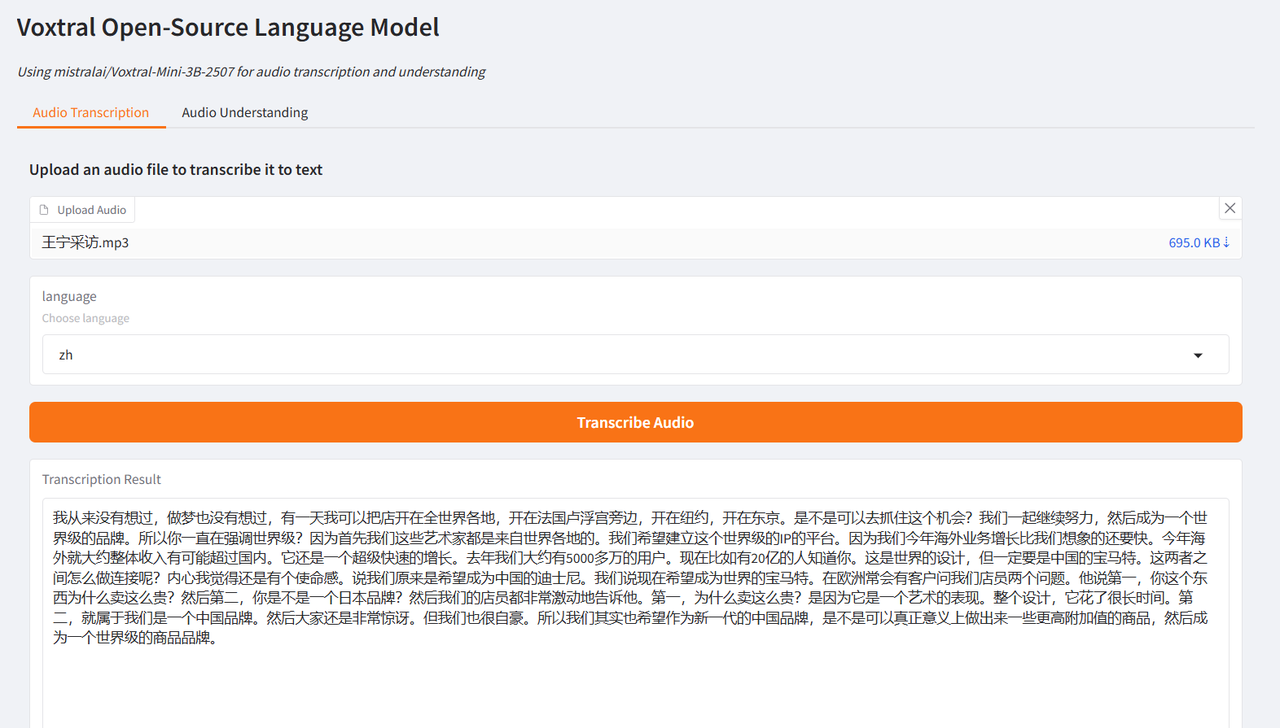
The author tested it using interview clips of Brad Pitt, the leading actor of "F1: Wild Race", and Wang Ning, the founder of Pop Mart, interviewed by CCTV. The generated results were very ideal, verifying the powerful functions of Voxtral.
Demo Run
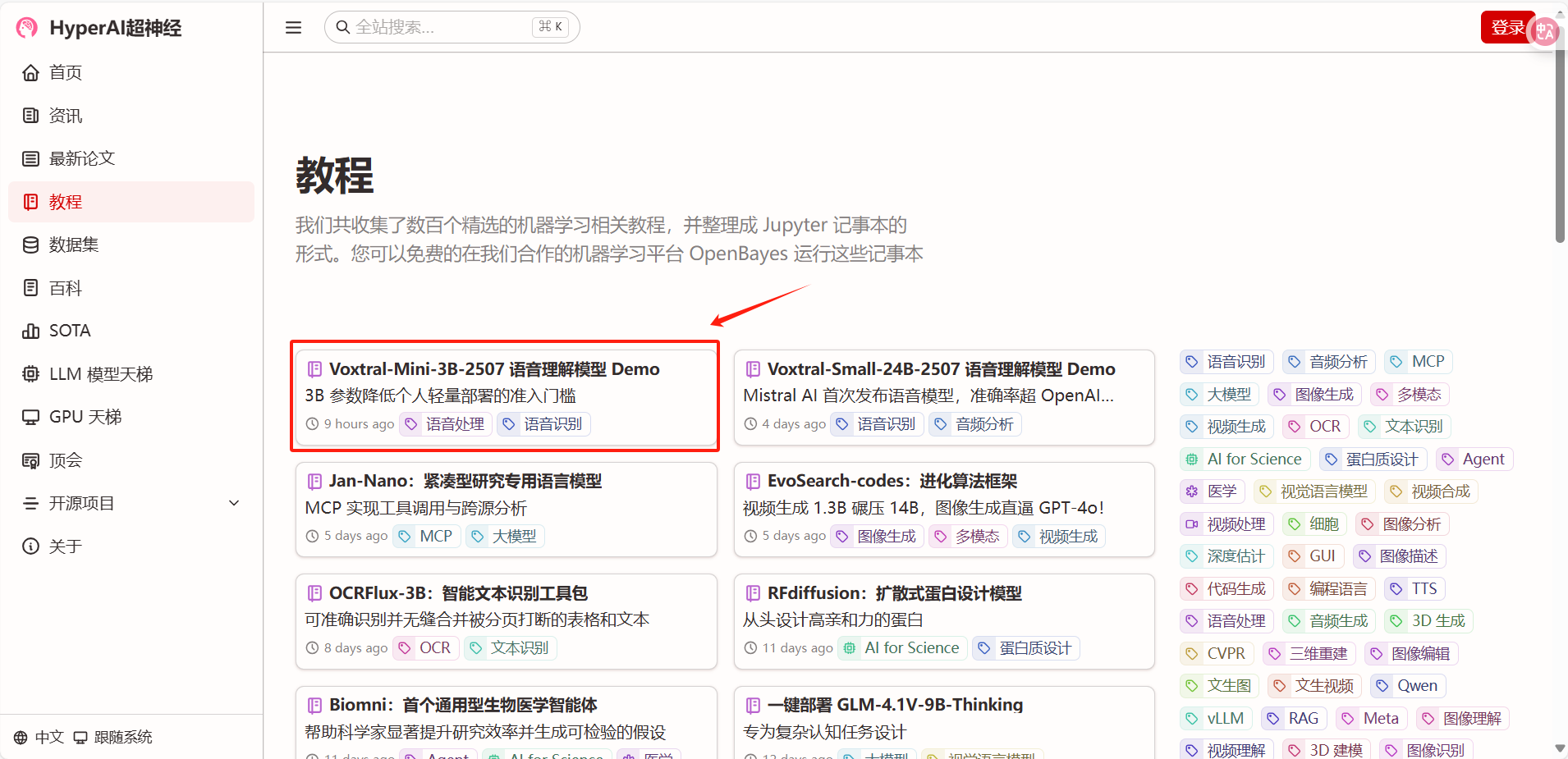
1. After entering the hyper.ai homepage, select the "Tutorial" page, select "Voxtral-Mini-3B-2507 Speech Understanding Model Demo", and click "Run this tutorial online".
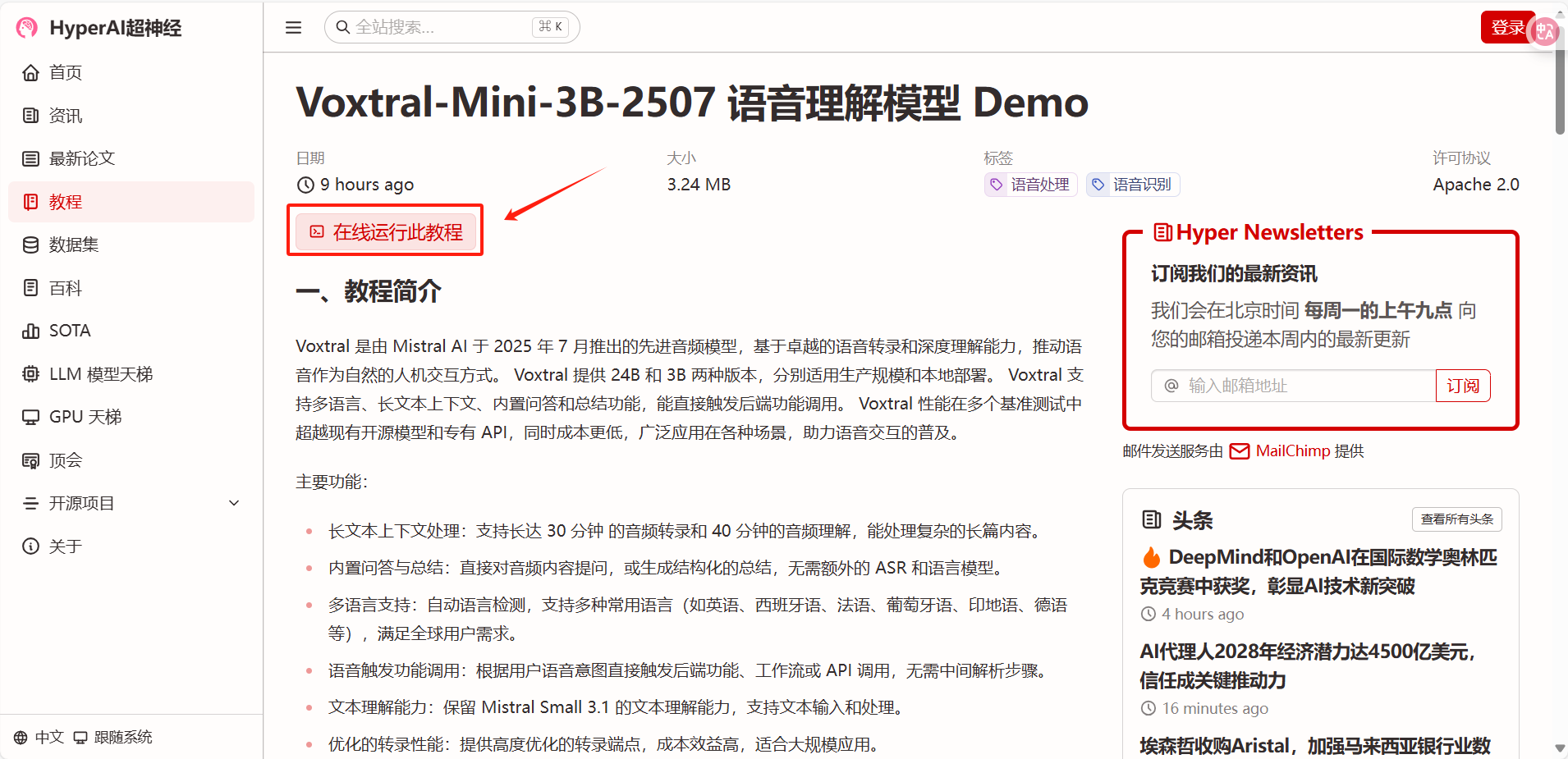
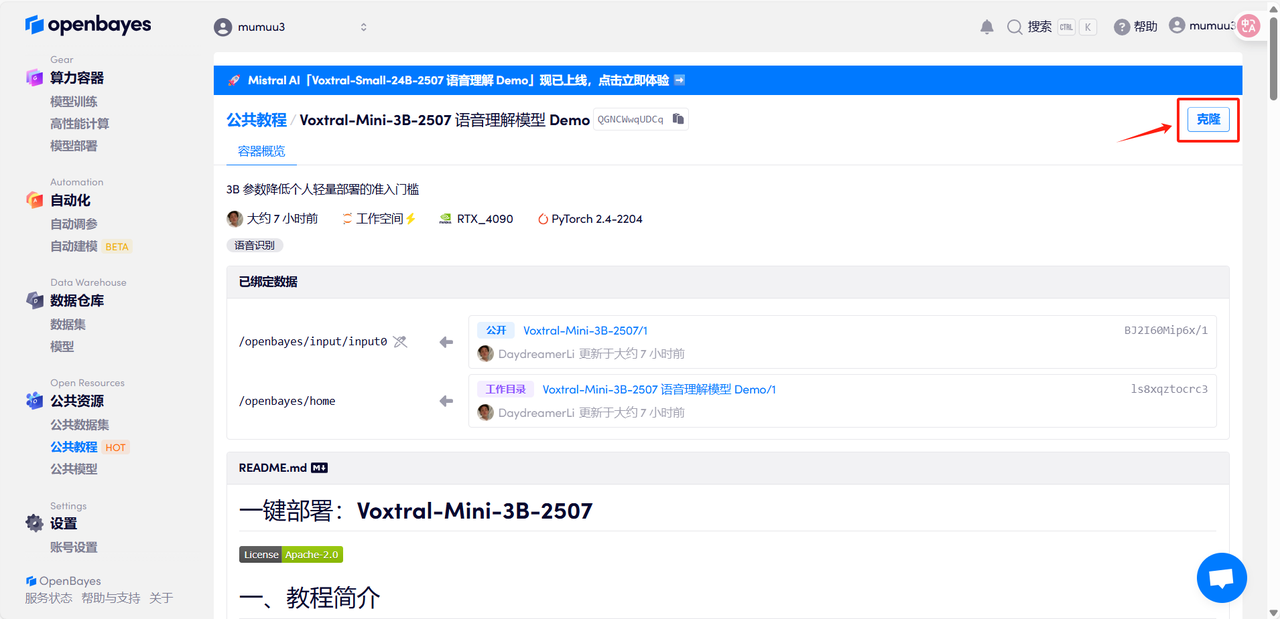
2. After the page jumps, click "Clone" in the upper right corner to clone the tutorial into your own container.
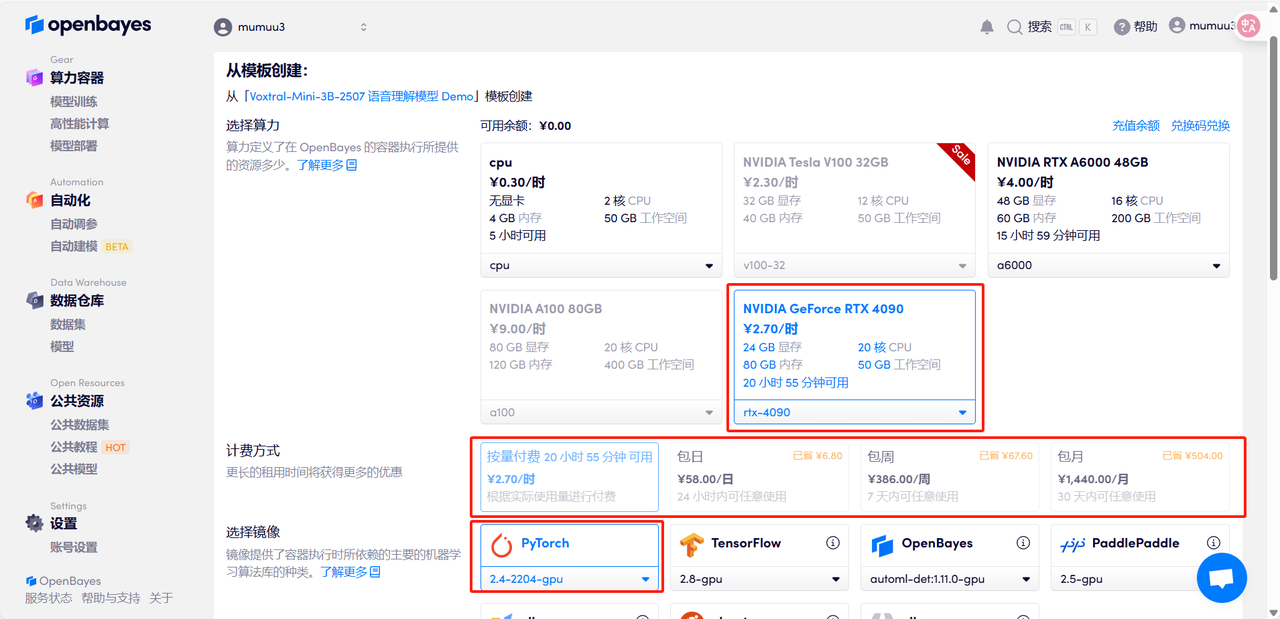
3. Select "NVIDIA GeForce RTX 4090" and "PyTorch" images, select "Pay as you go" or "Daily/Weekly/Monthly Package" according to your needs, and click "Continue". New users can register using the invitation link below to get 4 hours of RTX 4090 + 5 hours of CPU free time!
HyperAI exclusive invitation link (copy and open in browser):
https://openbayes.com/console/signup?r=Ada0322_NR0n
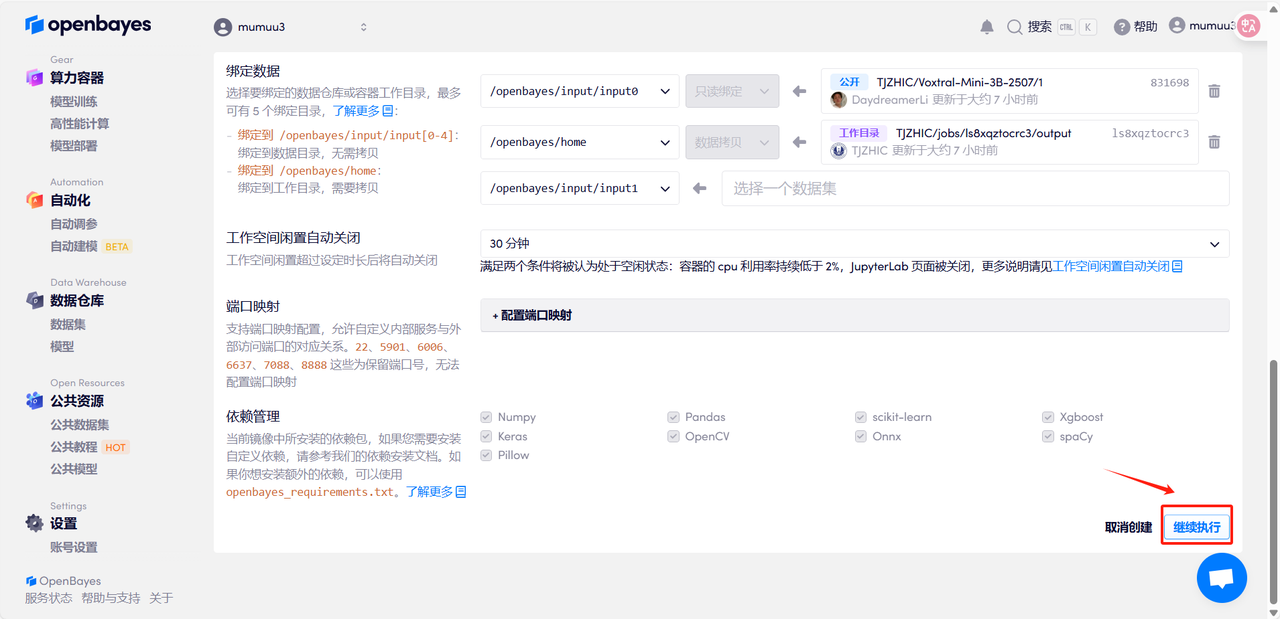
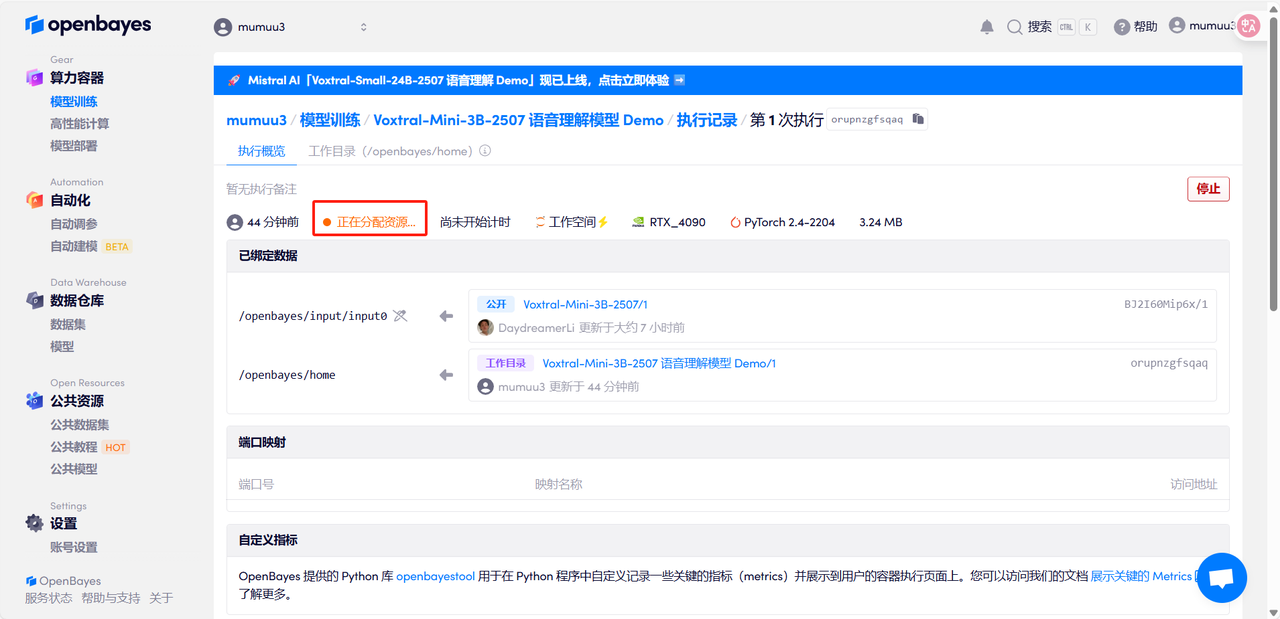
4. Wait for resources to be allocated. The first clone will take about 3 minutes. When the status changes to "Running", click the jump arrow next to "API Address" to jump to the Demo page. Please note that users must complete real-name authentication before using the API address access function.
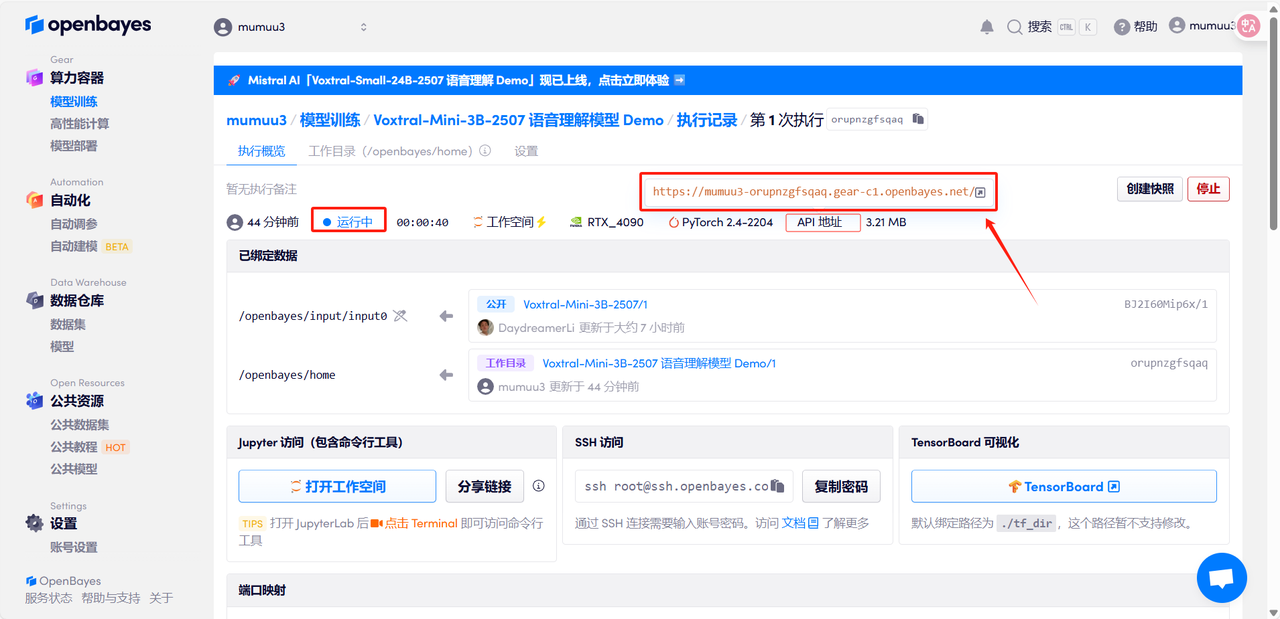
Effect Demonstration
The author tested it using interview clips of Brad Pitt, the leading actor of "F1: Wild Race", and Wang Ning, the founder of Pop Mart, interviewed by CCTV. The generated results were very ideal, verifying the powerful functions of Voxtral.
Select the "Audio Transcription" test function, upload an audio clip, select the language and click "Transcribe Audio". The result will be generated after a while.
Select the "Audio Understanding" test function, upload an audio clip, enter the question, click "Submit Query", and the results will be generated after a while.
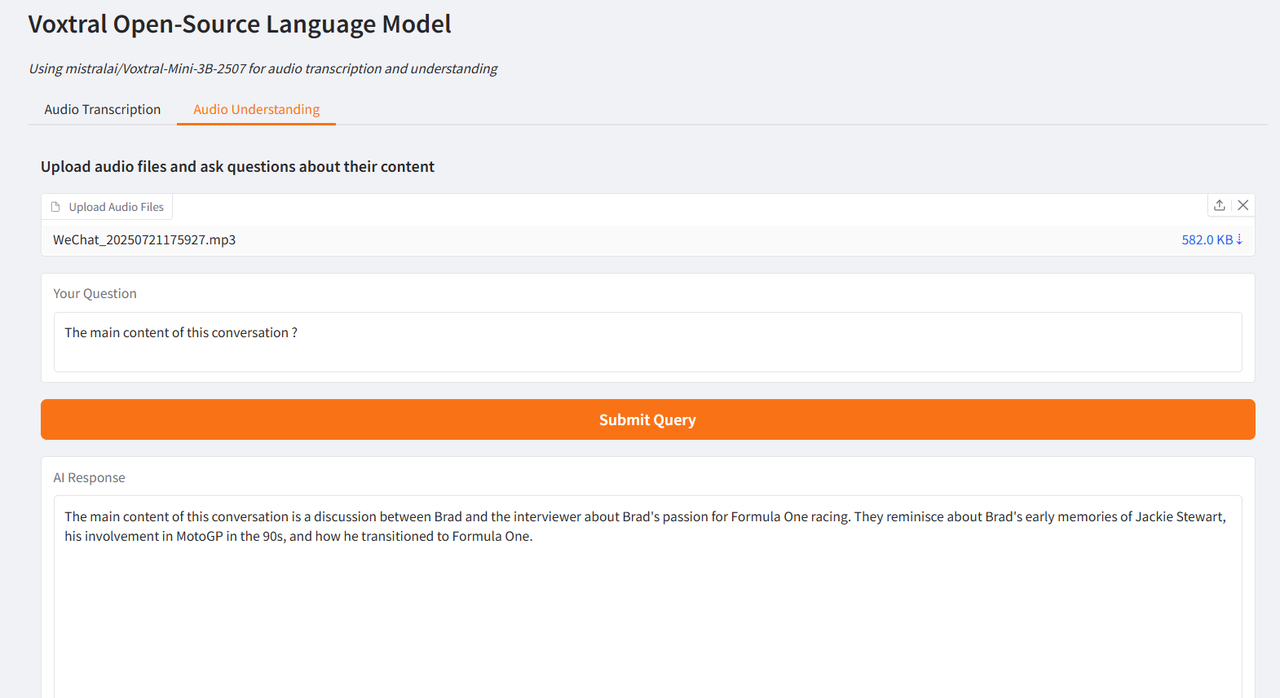
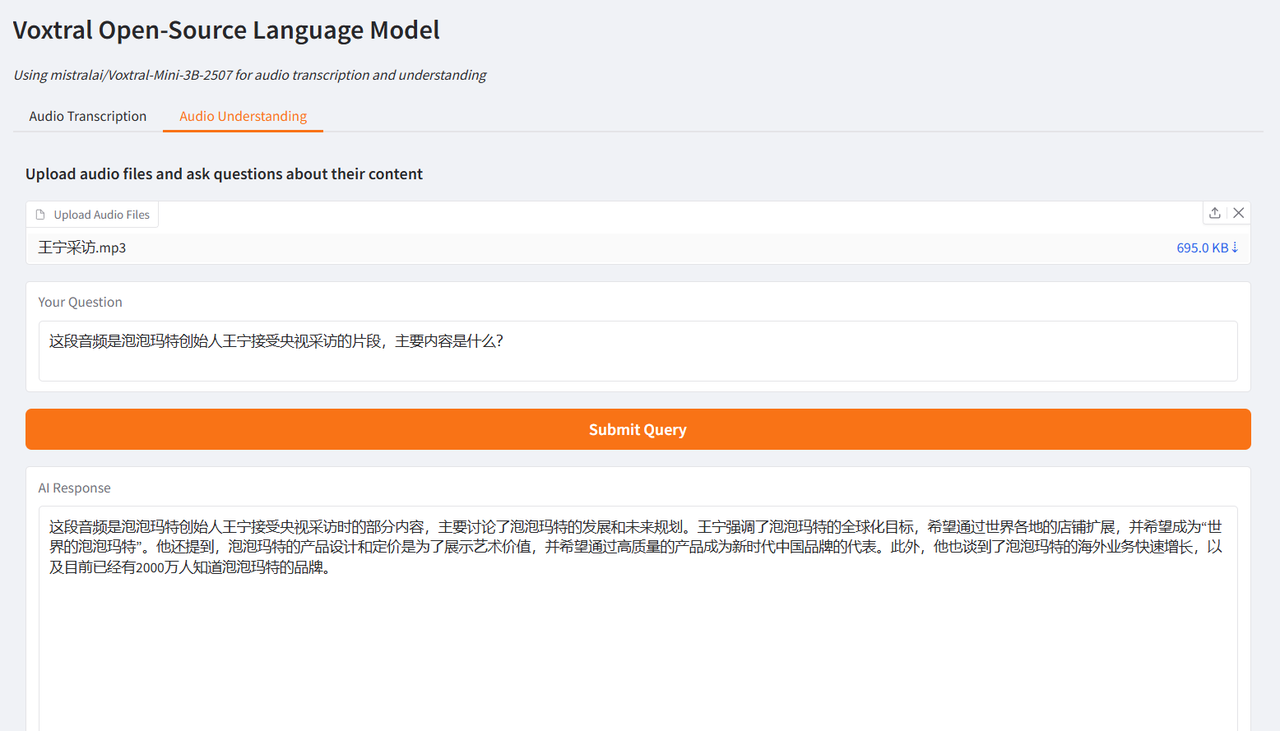
In addition, the 24B version provided by Voxtral is suitable for enterprise-level large-scale deployment. It is now available in the "Tutorial" section of the HyperAI official website (hyper.ai), and users can experience it as needed!
Tutorial Link:
* Voxtral-Mini-3B-2507 speech understanding model Demo:
* Voxtral-Small-24B-2507 speech understanding model Demo:








