Command Palette
Search for a command to run...
Training Performance Has Been Significantly improved. Bytedance's Zheng Size Explains the Triton-distributed Framework to Achieve Efficient Distributed Communication and Computing Integration for Large Models

In 2025, the Meet AI Complier Technology Salon hosted by HyperAI has reached its 7th session. With the support of community partners and many industry experts, we have established multiple bases in Beijing, Shanghai, Shenzhen and other places to provide a communication platform for developers and enthusiasts, unveil the mystery of pioneering technologies, face the application feedback of front-line developers, share practical experience in technology implementation, and listen to innovative thinking from multiple angles.
Follow the WeChat public account "HyperAI Super Neuro" and reply to the keyword "0705 AI Compiler" to obtain the authorized lecturer's speech PPT.




In the keynote speech "Triton-distributed: Native Python Programming for High-Performance Communications",Zheng Size, Seed Research Scientist from ByteDanceIt analyzes in detail the breakthrough in communication efficiency and cross-platform adaptability of Triton-distributed in large-model training, as well as how to achieve deep integration of communication and computing through Python programming.After the sharing, the scene quickly entered a peak of questions. There were endless discussions on details such as the FLUX framework, Tile programming model, AllGather and ReduceScatter optimization, etc. The discussions focused on core technical difficulties and practical experience, and effectively promoted the combination of theory and application.
HyperAI has compiled and summarized Mr. Zheng Size's speech without violating the original intention. The following is the transcript of the speech.
Real challenges of distributed training
In the context of the rapid evolution of large models, both training and reasoning areDistributed systems have become an indispensable part.We have also conducted compiler-level exploration in this direction and have open-sourced the project, naming it Triton-Distributed.
The current mainstream hardware interconnection methods include NVLink, PCIe, and cross-node network communication. Under ideal conditions, the NVLink unidirectional bandwidth of H100 can reach 450GB/s, but in most domestic deployments, the more common one is H800, whose unidirectional bandwidth is only about 200GB/s, and the overall communication capability and topology complexity are greatly reduced.An obvious challenge we encountered in the project was the system performance bottleneck caused by insufficient bandwidth and asymmetric communication topology.
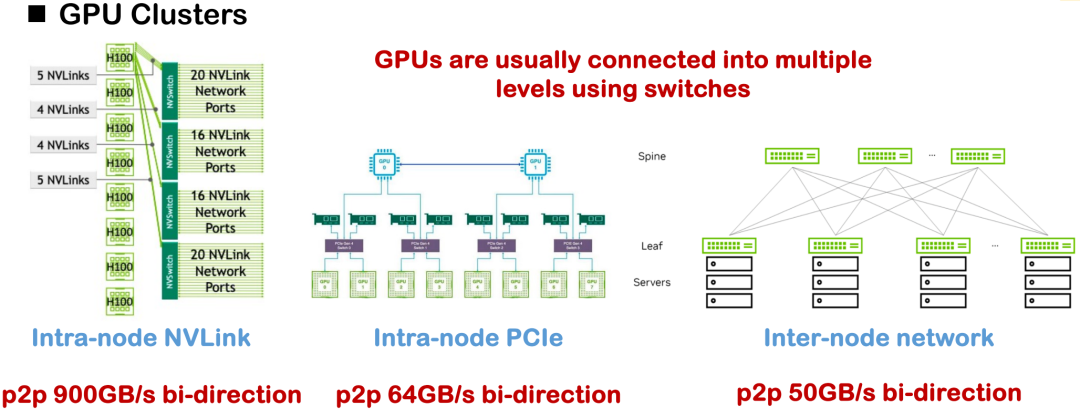
In view of this, early distributed optimization often relied on a large number of manually implemented communication operators, including strategies such as Tensor parallelism, Pipeline parallelism, and Data parallelism, all of which required careful writing of the underlying communication logic. A common practice is to call communication libraries such as NCCL and ROCm CCL, but such solutions often lack versatility and portability, and have high development and maintenance costs.
When analyzing the bottlenecks of the existing system, we summarized 3 key facts:
Fact 1: Hardware bandwidth is limited, and communication latency becomes a bottleneck
The first is the limitation brought by the basic hardware conditions. If H100 is used to train a large model, the computing delay is often significantly higher than the communication delay, so there is no need to pay special attention to the overlapping scheduling of computing and communication. However, in the current H800 environment, the communication delay is significantly lengthened. We have evaluated that in some scenarios, nearly half of the training time will be consumed by communication delay, resulting in a significant decrease in the overall MSU (Model Scale Utilization). If the overlap of communication and computing is not optimized, the system will face serious resource waste problems.
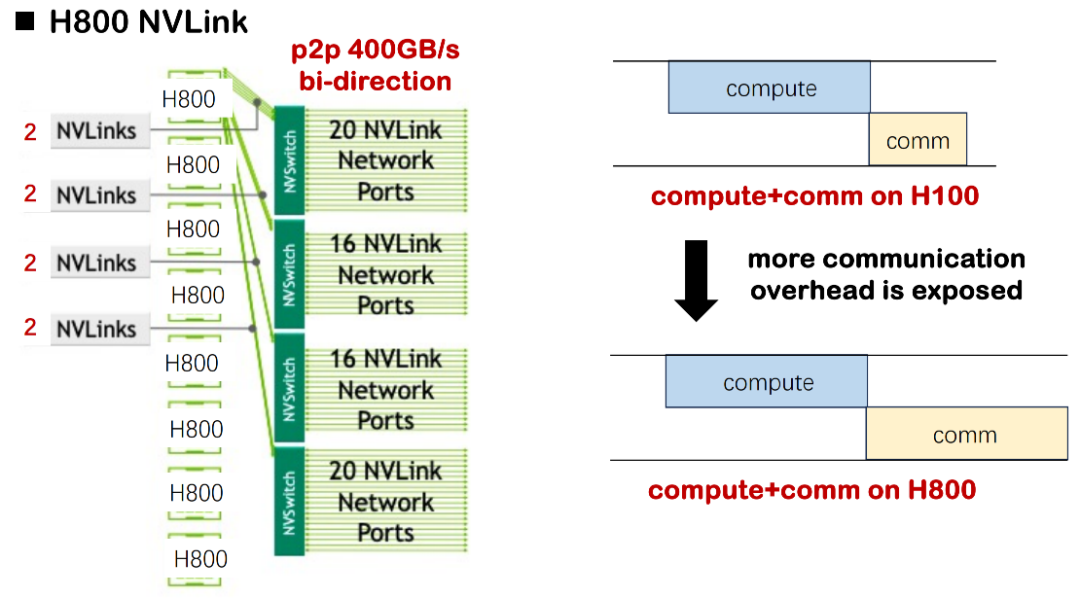
In small and medium-sized cases, this loss is acceptable; but once the model is expanded to thousands of cards, such as in the training practice of MegaScale or DeepSeek, the accumulated resource loss will reach millions or even tens of millions of dollars, which is a very real cost pressure for enterprises.
The same is true for inference scenarios. DeepSeek's early inference deployment used up to 320 cards. Despite subsequent compression and optimization, communication latency is still an unavoidable core problem of distributed systems. Therefore, how to effectively schedule communication and computing at the program level and improve overall efficiency has become a key issue that we must face head-on.
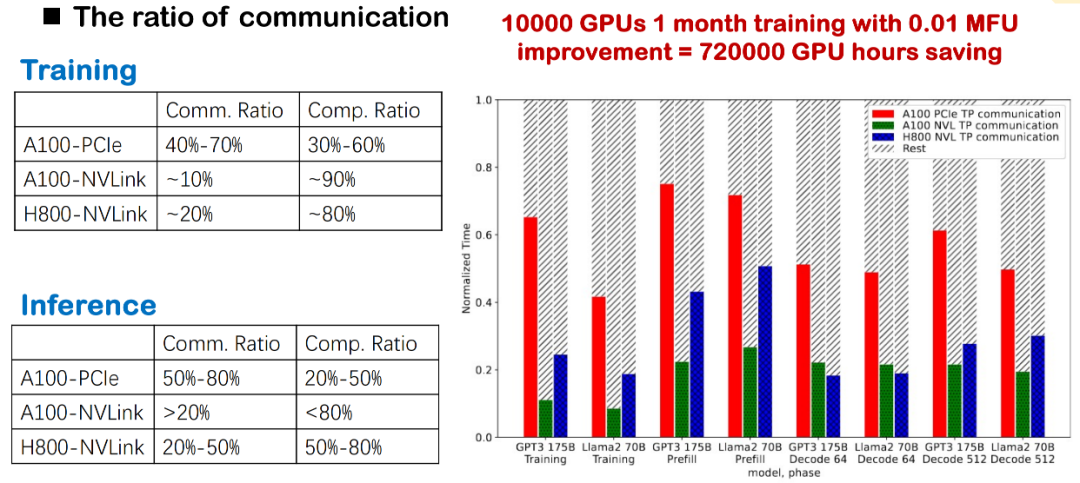
Fact 2: High communication overhead directly affects MFU performance
In current large-scale model training and reasoning, communication overhead is always a major bottleneck. We have observed that whether the underlying layer uses NVLink, PCIe, or different generations of GPUs (such as A100 and H800), the proportion of communication is very high. Especially in actual domestic deployments, due to more obvious bandwidth limitations, communication delays will directly slow down overall efficiency.
For large model training, this high-frequency cross-card communication will significantly reduce the system's MFU. Therefore, optimizing communication overhead is a critical improvement point for improving training and inference performance, and it is also one of our key areas of focus.
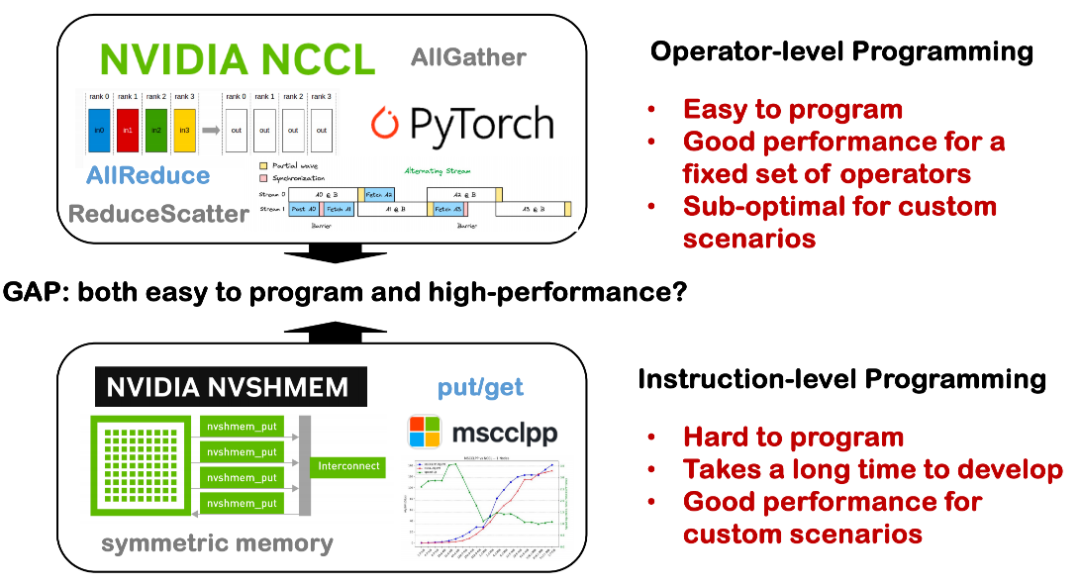
Fact 3: The gap between programmability and performance
Currently, there is still a large gap between programmability and performance in distributed systems. In the past, we paid more attention to the optimization capabilities of single-card compilers, such as how to achieve excellent performance on a single card; but when we expand to a single machine with multiple cards, or even a distributed system across nodes, the situation becomes more complicated.
On the one hand, distributed communication involves a lot of underlying technical details, such as NCCL, MPI, and topology, which are scattered in various dedicated libraries and have a high threshold for use. In many cases, developers need to manually implement communication logic, manually schedule calculations and synchronization, which results in high development costs and error rates. On the other hand, if there are tools that can automatically handle complex communication scheduling and operator optimization under distributed conditions, it can help developers significantly lower the development threshold and improve the availability and maintainability of distributed systems. This is one of the problems we hope to solve in Triton-Distributed.
Based on the three practical problems mentioned above, we proposed three core directions in Triton-Distributed:
First, promote the overlapping mechanism of communication and computing.In distributed scenarios where communication overhead is becoming increasingly prominent, we hope to schedule parallel windows of computing and communication as much as possible to improve the overall efficiency of the system.
Secondly, it is necessary to deeply integrate and adapt the computing and communication modes of large models.For example, we try to integrate the common communication patterns such as AllReduce and Broadcast in the model with the computing pattern to reduce synchronous waiting and compress the execution path.
Finally, we believe that these optimizations should be done by the compiler rather than relying on developers to hand-write highly customized CUDA implementations.Making the development of distributed systems more abstract and efficient is the direction we are working towards.
Triton-distributed architecture analysis: native Python for high-performance communication
We hope to achieve overlapping in distributed training, but it is not easy to implement. Conceptually, overlapping means performing computation and communication concurrently through multiple streams to mask communication delays. This is easier in scenarios where there is no dependency between operators, but in Tensor Parallel (TP) or Expert Parallel (EP), AllGather must be completed before GEMM can be performed. The two are in the critical path, and overlapping is very difficult.
Common methods currently include: first, dividing the task into multiple Micro-Batches, and achieving overlap with the independence of batches; second, splitting at a finer granularity (such as tile granularity) within a single batch, and achieving parallel effects through kernel fusion. We have also explored this type of splitting and scheduling mechanism in Flux. At the same time, the communication mode in large model training is highly complex. For example, DeepSeek needs to customize All-to-All communication when doing MoE to take into account bandwidth and load balancing; for example, in low-latency reasoning and quantization scenarios, general libraries such as NCCL are difficult to meet performance requirements, and often require handwritten communication kernels, which increases the customization cost.
Therefore, we believeThe optimization capability of communication-computing fusion should be undertaken by the compiler layer to cope with complex model structures and diverse hardware environments, and avoid the development burden brought by repeated manual implementation.
Two-layer communication primitive abstraction
In our compiler design, we adopted a two-layer communication primitives abstract structure to take into account both the upper-layer optimization expression capability and the feasibility of the underlying deployment.
The first layer is a relatively high-level primitive, which mainly completes computing scheduling at the tile granularity and provides an abstract interface for communication.It uses push/get operations between ranks as communication abstractions and distinguishes each communication behavior through a tag identification mechanism, making it easier for the scheduler to track data flows and dependencies.
The second layer is closer to the underlying implementation and uses a primitive system similar to the Open Shared Memory standard (OpenSHMEM).This layer is mainly used to map to existing communication libraries or hardware backends to implement real communication behaviors.
also,In the multi-rank scenario, we also need to introduce barrier and signal control mechanisms for cross-rank synchronization.For example, when you need to notify other ranks that your data has been written, or when you are waiting for a certain rank's data to be ready, this type of synchronization signal is very critical.

Compiler Architecture and Semantic Modeling
In terms of the compilation stack, our overall process is still based on the original Triton compilation framework. Starting from the source code, Triton will first convert the user code into an abstract syntax tree (AST), and then translate it into Triton IR. In the Triton-Distributed we built, weThe original Triton IR has been extended and a new IR layer for distributed semantics has been added.This distributed IR introduces semantic modeling of synchronization operations, such as wait and notify, to describe the communication dependencies between ranks. At the same time, we also design a set of semantic interfaces for OpenSHMEM to support lower-level communication calls.
In the actual code generation phase, these semantics can be mapped to external calls to the underlying communication library. We directly link these calls to the bitcode version of the library (not the source code) provided by OpenSHMEM through the LLVM middle layer to achieve efficient shared memory communication across ranks. This method bypasses the limitation that Triton does not support direct access to external lib from source code, allowing shared memory-related calls to complete symbol resolution and linking smoothly during compilation.
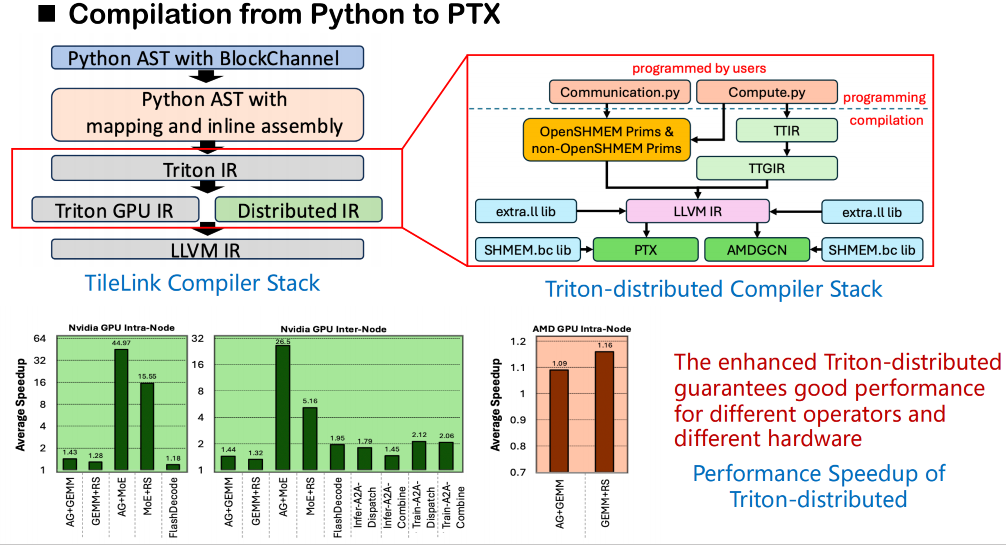
Mapping mechanism between high-level primitives and low-level execution
In Triton-distributed, we designed a system of communication primitives covering high-level abstraction and low-level control.Taking consumer_tile_wait as an example, developers only need to declare the tile ID to wait for, and the system will automatically deduce the specific rank and offset of the communication target based on the current operator semantics (such as AllGather) to complete the synchronization logic. High-level primitives shield the details of specific data sources and signal transmission, improving development efficiency.
In contrast, low-level primitives provide finer-grained control capabilities. Developers need to manually specify signal pointers, scopes (GPU or system), memory semantics (acquire, release, etc.), and expected values. Although this mechanism is more complex, it is suitable for scenarios with extremely high requirements for communication latency and scheduling accuracy.
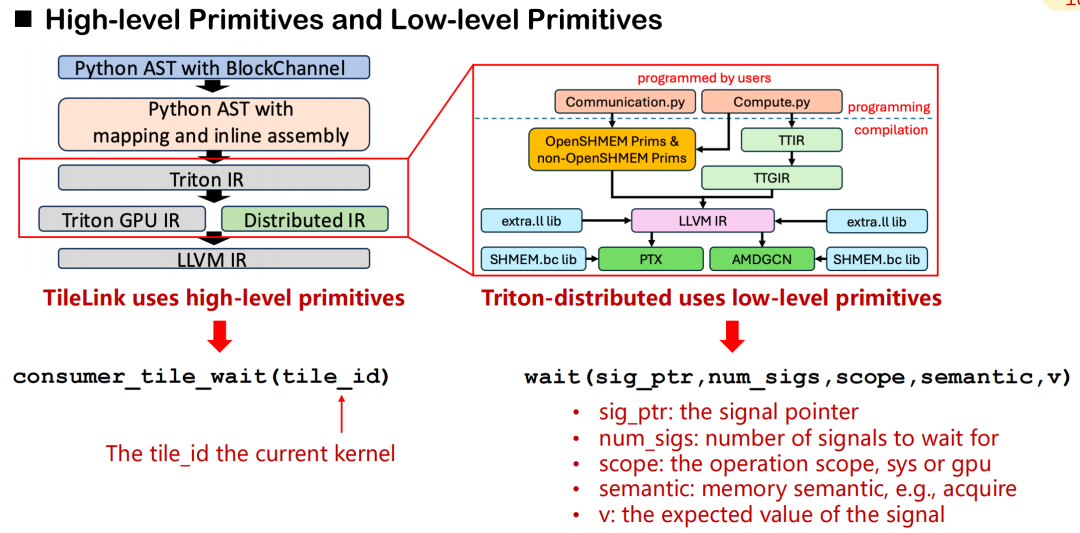
High-level primitives can be roughly divided into two categories: signal control and data control. In the semantics of signal control,We mainly define three types of roles: producer, consumer and peer.They achieve synchronization through read and write signals, which is similar to the handshake mechanism in distributed communication. For data transmission, Triton-distributed provides two primitives: push and pull, which correspond to actively sending data to the remote card or pulling data from the remote card to the local card.
All low-level communication primitives follow the OpenSHMEM standard, and currently support NVSHMEM and ROCSHMEM. There is a clear mapping relationship between high-level and low-level primitives, and the compiler is responsible for automatically converting concise interfaces into low-level synchronization and transmission instructions. Through this mechanism,Triton-distributed not only retains the high performance capabilities of communication scheduling, but also greatly reduces the complexity of distributed programming.
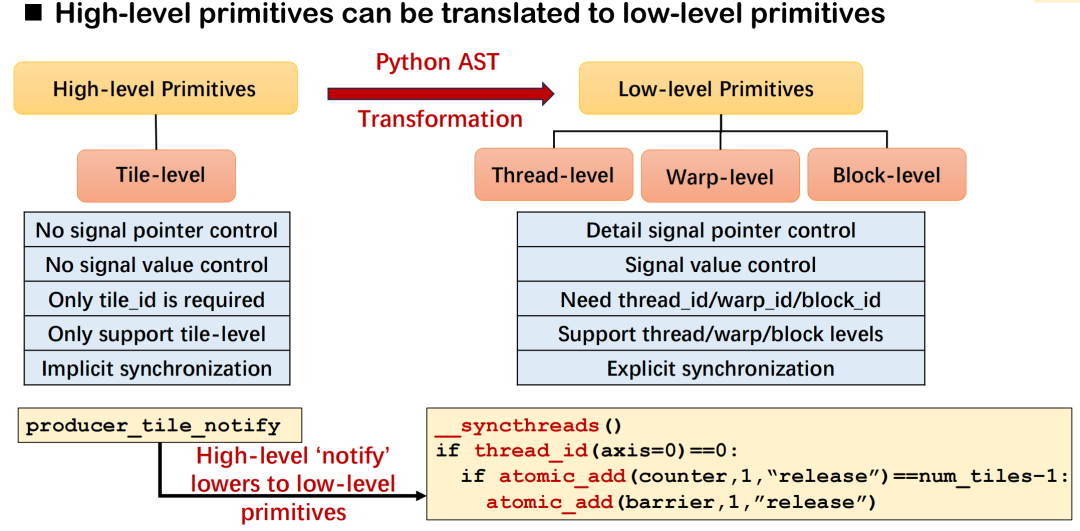
In Triton-distributed, the design goal of high-level communication primitives (such as notify and wait) is to describe cross-card synchronization requirements with concise semantics, and the compiler is responsible for translating them into the corresponding underlying execution logic. Take notify as an example, it and wait form a pair of synchronization semantics: the former is used to send notifications, and the latter is used to wait for data preparation to be completed. Developers only need to specify the tile ID, and the system can automatically deduce the underlying details such as communication targets and signal offsets based on the operator type and communication topology.
The specific underlying implementation will vary depending on the deployment environment. For example, in a scenario with 8 GPUs, this type of synchronization can be achieved through _syncthreads() and atomic_dd within a thread; in cross-machine deployment, it relies on primitives such as signal_up provided by NVSHMEM or ROCSHMEM to complete equivalent operations. These mechanisms together constitute the mapping relationship between high-level semantics and low-level primitives, and have good versatility and scalability.
Take a GEMM ReduceScatter communication scenario as an example: Assume that there are 4 GPUs in the system, and the target position of each tile is determined by pre-calculated meta information (such as the tile allocation and barrier number for each rank). Developers only need to add a notify statement in the GEMM kernel written in Triton, and the ReduceScatter kernel uses wait to synchronously receive data.
The entire process can be expressed in Python, and it also supports the kernel mode of dual-stream startup, with clear communication logic and easy scheduling. This mechanism not only improves the expressibility of cross-card communication programming, but also greatly reduces the complexity of the underlying implementation, providing strong basic capability support for efficient training and reasoning of large distributed models.
Multi-dimensional Overlapping Optimization: From Scheduling Mechanism to Topology Awareness
Although Triton-distributed has provided a relatively concise high-level communication primitive interface, there are still certain technical barriers in the actual process of writing and optimizing the kernel. We have observed that although the primitive design has good expressive power, the number of users who can truly flexibly apply and deeply optimize is still limited. In essence, communication optimization is still a task that relies heavily on engineering experience and scheduling understanding, and currently still needs to be manually controlled by developers. Around this issue, we have summarized some key optimization paths. The following are typical implementation strategies in Triton-distributed.
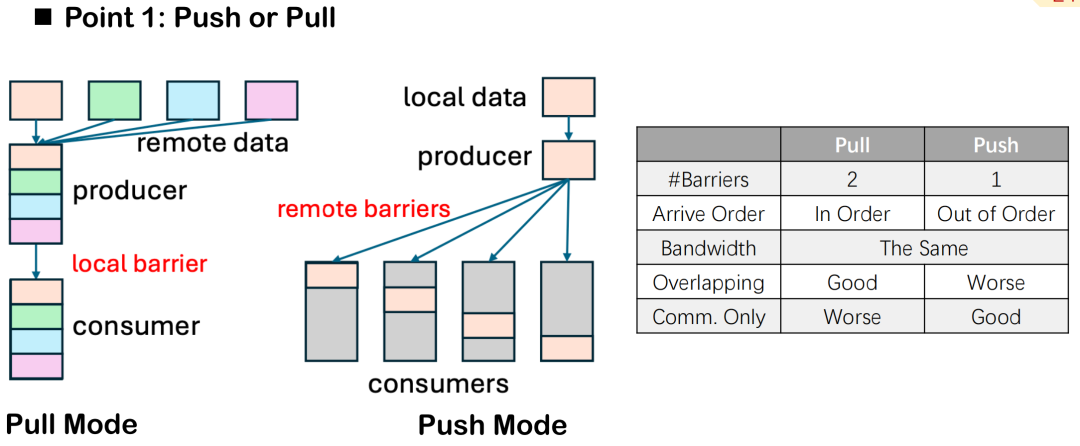
Push vs. Pull: Data flow direction and barrier number control
In the overlap optimization of communication and computation,Triton-distributed provides two data transmission methods: push and pull.Although the semantic difference between them is only the direction of "active sending" and "passive pulling", in actual distributed execution, there are obvious differences in their performance and scheduling control capabilities.
Taking the number of barriers as an example, the pull mode usually requires two barriers: one to ensure that the local data is ready before being pulled by the other party, and the other to protect the data from being modified by the local task during the entire communication cycle, thereby preventing data inconsistency or read-write conflicts. In the push mode, only one barrier needs to be set after the data is written to the remote end to synchronize all devices, making overall control simpler.
However, the pull mode also has its advantages. It allows local nodes to actively control the order of data pulling, thereby more accurately scheduling the timing of communication and the overlap of computing. When we want to maximize the overlap effect and achieve parallelism between communication and computing, pull provides greater flexibility.
In general, if the main goal is to improve overlap, pull is recommended; in some pure communication tasks, such as a separate AllGather or ReduceScatter kernel, push mode is more common due to its simplicity and lower overhead.
Swizzling Scheduling: Dynamically Adjusting Order Based on Data Locality
The overlap of communication and computation depends not only on the choice of primitives, but also on the scheduling strategy. Among them, Swizzling is a scheduling optimization method based on topology awareness, which aims to reduce execution idleness during cross-card computing. From a distributed perspective, each GPU card can be regarded as an independent execution unit. Since each card initially holds different data fragments, if all cards start computing from the same tile index, some ranks will have to wait for the data to be ready, resulting in long idle periods in the execution phase, thereby reducing the overall computing efficiency.
The core idea of Swizzling is:The starting calculation offset is dynamically adjusted based on the location of the existing local data on each card.For example, in the AllGather scenario, each card can prioritize processing its own data and initiate pulls from remote tiles at the same time, thus achieving concurrent scheduling of communication and computation. If all cards start processing from tile 0, only rank 0 can start computing immediately, and the remaining ranks will incur serial delays due to waiting for data.
In more complex situations, such as the cross-machine ReduceScatter scenario, the Swizzling strategy needs to be designed in combination with the network topology. Taking two nodes as an example, a reasonable scheduling method is: give priority to calculating the data required by the other node, trigger cross-machine point-to-point communication as early as possible; and during the transmission process, calculate the data required by the local node in parallel to maximize the overlap effect of communication and computing.
Currently, this type of scheduling optimization is still controlled by the programmer to avoid the compiler sacrificing key performance paths in general optimization. We also realize that understanding details such as Swizzling is a certain threshold for developers. In the future, we hope to provide more practical cases and template codes to help developers master the distributed operator development model more quickly and gradually build an open and efficient Triton-distributed programming ecosystem.

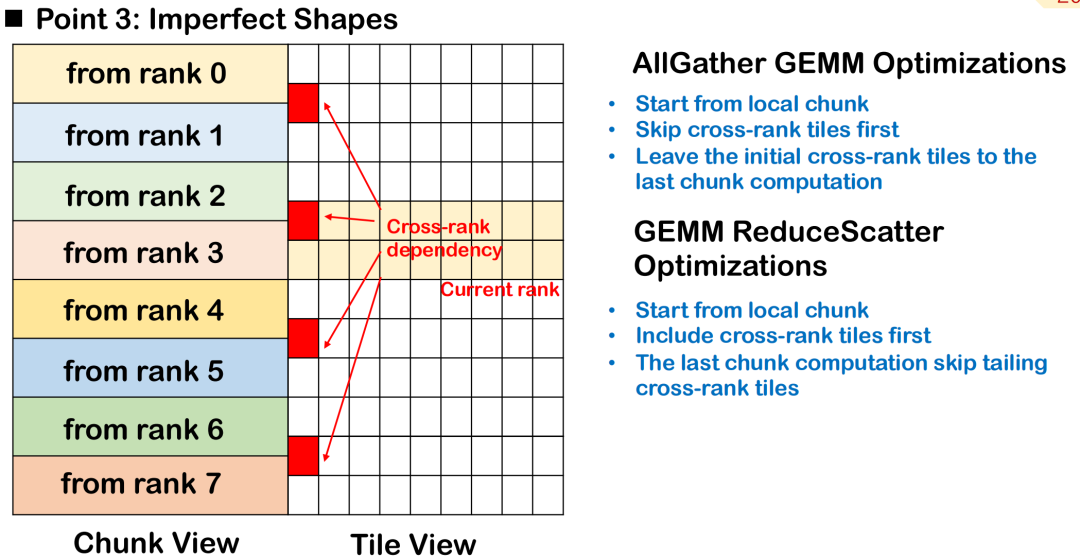
Imperfect block scheduling: Processing priorities across rank tiles
In actual large-model training and inference scenarios, the input shape of the operator is often irregular, especially when the token length is not fixed, and it is difficult to keep the tile blocks neat and uniform.This imperfect tiling will cause some tiles to span multiple ranks, that is, the data of the same tile is distributed on multiple devices, increasing the complexity of scheduling and synchronization.
Taking AllGather GEMM as an example, suppose a tile contains both local and remote data. If the calculation starts from this tile, it must wait for the remote data to be transmitted first, which will introduce additional bubbles and affect the parallelism of the overall calculation. A better approach is to skip this cross-rank tile, give priority to processing completely locally available data, and schedule the tile waiting for remote input to be executed last, so as to achieve maximum overlap between communication and calculation.
In the ReduceScatter scenario, the scheduling order should be reversed. Since the calculation results of cross-rank tiles need to be sent to the remote end as soon as possible, the best strategy is to prioritize the tiles that are relied upon by the remote nodes, so as to complete the cross-machine data transmission as soon as possible and reduce the remote dependency.
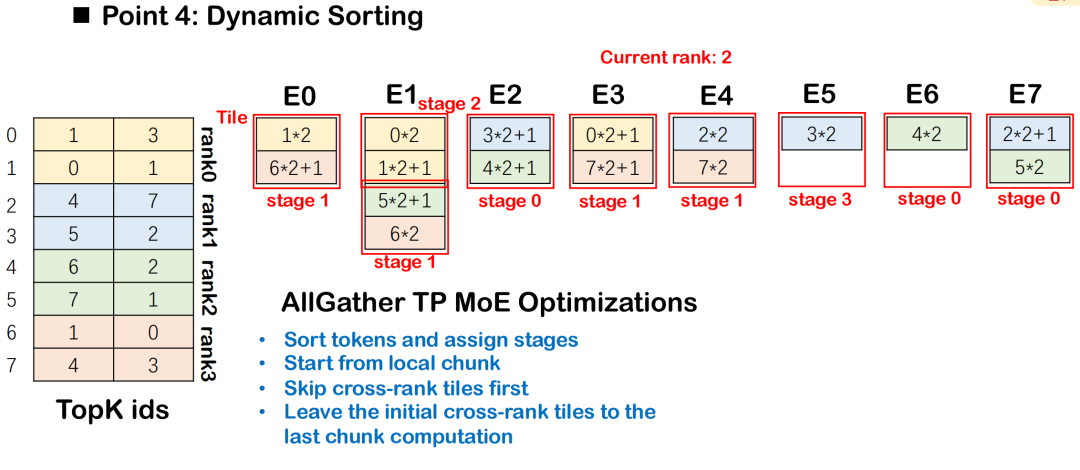
Dynamic Sorting Strategy under MoE
In the MoE (Mixture-of-Experts) model, tokens need to be distributed to multiple experts based on routing results, usually accompanied by All-to-All communication and Group GEMM calculations. In order to improve the overlapping efficiency of communication and computing, Triton-distributed introduces Dynamic Sorting, which schedules computing tasks in stages according to the intensity of their dependence on communication data, giving priority to those with less data dependence.
This ordering ensures that the computation of each stage can start with the lowest possible communication blocking, thereby achieving better overlap between All-to-All and Group GEMM.The overall scheduling starts from the tile with the least data dependencies and gradually expands to the tiles with complex dependencies, maximizing the execution concurrency.
Hardware-based communication acceleration
Triton-distributed also supports communication optimization in combination with specific hardware capabilities.Especially when using the NVSwitch architecture, its built-in SHARP Accelerator can be used to perform low-latency communication calculations. This module can complete operations such as Broadcast and AllReduce in the switch chip to achieve data aggregation acceleration in the transmission path, reducing latency and bandwidth consumption. Relevant instructions have been integrated into Triton-distributed, and users with corresponding hardware can directly call them to build a more efficient communication kernel.
AOT compilation optimization: reducing inference latency overhead
Triton-distributed introduces the AOT (Ahead-of-Time) mechanism, which is specifically optimized for extremely latency-sensitive requirements in inference scenarios. Triton uses the JIT (Just-In-Time compilation) compilation method by default, and there is a significant compilation and cache overhead when the function is executed for the first time.
The AOT mechanism allows users to precompile functions into bytecode before running, and directly load and execute them during the inference phase, avoiding the JIT compilation process, thereby effectively reducing the delay caused by compilation and caching. Based on this, Triton-distributed has expanded the AOT mechanism and now supports AOT compilation and deployment in distributed environments, further improving the performance of distributed inference.
Performance measurement and case reproduction
We conducted a comprehensive test of Triton-distributed's performance in multi-platform and multi-task scenarios, covering NVIDIA H800, AMD GPU, 8-card GPU and cross-machine clusters, and compared mainstream distributed implementation solutions such as PyTorch and Flux.
On 8 GPU cards,Triton-distributed achieves significant speedup compared to PyTorch implementation in AG GEMM and GEMM RS tasks.Compared with the manually optimized Flux solution, it also achieves better performance, thanks to multiple optimizations such as Swizzling scheduling, communication offload, and AOT compilation. At the same time, compared with the combination of PyTorch + RCCL on the AMD platform, although the overall acceleration is slightly smaller, it also achieves significant optimization. The main limitations come from the weak computing power of the test hardware and the non-switch topology.
In the AllReduce task,Triton-distributed has significant speedups over NCCL in the hardware configurations we tested for a variety of message sizes from small to large, with an average speedup of about 1.6 times.In the Attention scenario, we mainly tested the gather-KV type of attention operation. Compared with the native implementation of PyTorch Touch, the performance of Triton-distributed on 8 GPU cards can be improved by about 5 times; it is also better than the open source Ring Attention implementation, with an improvement of about 2 times.
Cross-machine testing:AG GEMM is 1.3 times faster and GEMM RS is 1.4 times faster, which is slightly lower than Flux, but has more advantages in shape flexibility and scalability.We also tested single token decoding in high-speed inference scenarios. The latency was controlled within 20–30 microseconds in a 1M token context, and it is compatible with NVLink and PCIe.
In addition, we reproduced the distributed scheduling logic in DeepEP, mainly aligning its All-to-All routing and context distribution strategies. In scenarios with less than 64 cards, the performance of Triton-distributed is basically the same as that of DeepEP, and slightly improved in some configurations.
Finally, we also provide a prefill and decode Demo based on Qwen-32B, which supports deployment and operation on 8 GPU cards. The actual test shows that the inference acceleration effect can be achieved by about 1.2 times.
Building an open distributed compilation ecosystem
We are currently facing the challenge of customized overlapping scenarios, which we have mainly relied on manual optimization to solve in the past, which is labor-intensive and costly.We proposed and open-sourced the Triton-distributed framework.Although it is implemented based on Triton, no matter what compiler or underlying communication library each company uses, it can be integrated to create an open distributed ecosystem.
This field is still relatively blank in China and even in the world. We hope to use the power of the community to attract more developers to participate, whether in syntax design, performance optimization, or support for more types of hardware devices, to jointly promote technological progress. Finally, we have achieved good performance, and all related examples are open source. Welcome to actively raise issues for communication, and look forward to more partners joining us to create a better future!








