Command Palette
Search for a command to run...
From Architectural Features to Ecosystem Construction, Muxi Dong Zhaohua Deeply Analyzes the Application Practice of TVM on Domestic GPUs

On July 5, the 7th Meet AI Compiler Technology Salon hosted by HyperAI came to a successful conclusion. From the underlying innovation of GPU architecture to the top-level design of cross-hardware compilation ecology; from single-chip operator optimization to breakthroughs in multi-node distributed compilation... Practitioners and scholars from the field of AI compilation gathered together for this top technology feast. The event site was packed with people and the atmosphere of communication was strong.
Follow the WeChat public account "HyperAI Super Neuro" and reply to the keyword "0705 AI Compiler" to obtain the authorized lecturer's speech PPT.
At the event, architect Zhang Ning from AMD gave us an in-depth analysis of the performance optimization secrets of the Triton compiler on the AMD GPU platform, revealing how to make Python code easily control the high-performance GPU Kernel; Director Dong Zhaohua of Muxi Integrated Circuit brought practical experience in TVM applications on domestic GPUs, showing the sparks of collision between independent chips and open source compilation frameworks; Researcher Zheng Size from ByteDance unveiled the mystery of Triton-distributed and shared how Python subverts the performance ceiling of distributed communications; TileLang brought by Dr. Wang Lei of Peking University redefines the efficiency boundary of operator development.




In the keynote speech "TVM Application Practice on Muxi GPU",Dong Zhaohua, senior director of Muxi Integrated Circuit, introduced the technical characteristics of its GPU products, TVM compiler adaptation solutions, practical application cases and ecological construction vision.It demonstrated the technological breakthroughs and application potential of domestic GPUs in the fields of high-performance computing and AI.
HyperAI has compiled and summarized Professor Dong Zhaohua’s speech without violating the original intention. The following is the transcript of the speech.
Muxi GPU Introduction
Muxi GPU currently includes multiple product lines such as the N series, C series, and G series, covering a wide range of scenarios from AI training and reasoning to scientific computing. By building a multi-level software stack, it achieves seamless integration with mainstream frameworks. As the core module on the software stack, the compiler is responsible for providing a user-friendly programming interface, optimizing upper-level applications, generating corresponding machine codes according to different machine architectures, and delivering them to the GPU for execution. After precise adjustments by engineers, its performance has reached the international advanced level, and it has formed a corresponding adaptation relationship with the mainstream computing libraries in the industry.
Muxi GPU has a rich instruction-level function interface.Our self-developed MACA C interface is based on the extension of C language, integrates grammatical elements of specific fields, and has functional equivalence with the underlying programming interfaces of mainstream manufacturers, so developers can quickly complete migration and adaptation. At the same time, it provides diversified programming interfaces such as Python, Triton, and Fortran, supports parallel programming standards such as OpenACC and OpenCL, and has excellent efficiency in automatic parallelization code generation.
also,Muxi GPU adopts GPGPU (general purpose graphics processing unit) architecture.The LLVM-based compilation system supports full-process optimization from high-level languages to low-level machine codes, takes into account both development efficiency and hardware performance, and provides a high-performance software stack.
TVM Adaptation on Muxi GPU
As an open source deep learning compiler, TVM can convert deep learning models into code that can run efficiently on different hardware. The Muxi team built a complete TVM adaptation solution based on the characteristics of its own GPU to achieve full-process optimization from model definition to hardware execution.
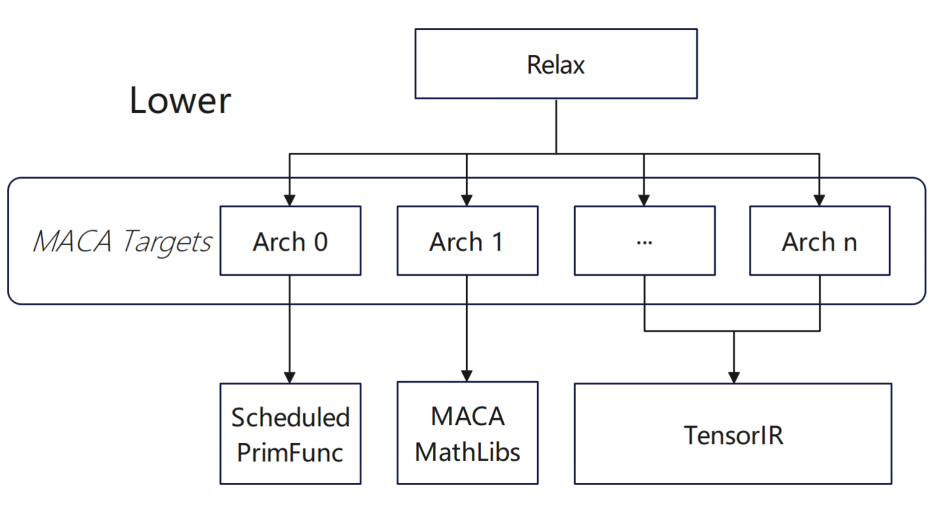
From the perspective of compiler architecture, full support has been achieved.And in theory, it can connect to four core levels.
For the adaptation of the C++ interface, we want to convert it into MACA language for solution. This process is quite difficult and there are certain challenges in implementing tool-based automatic conversion.
If the code abstraction is high, it is easier to achieve cross-level adaptation. In addition, when connecting to LLVM, you need to pay attention to version compatibility issues - because there are many LLVM versions, the adaptation of a specific version depends on the support of the corresponding version, and version mismatches may cause abnormal compilation processes.
In terms of GPU adaptation of Muxi Arch:
tvm.Target adds MACA Target and adds support for each stage: first, add the pipeline of MACA Target in transform/lower to reuse the general GPU process; then add the scheduling rules of MACA Target in the tuning stage; finally, add support for CodeGenMACA and compile MACAC code.
In addition, the use of MACA Device and MACA Runtime API is added to tvm.Device, including memory operations on MACA Device and kernel launch at runtime.
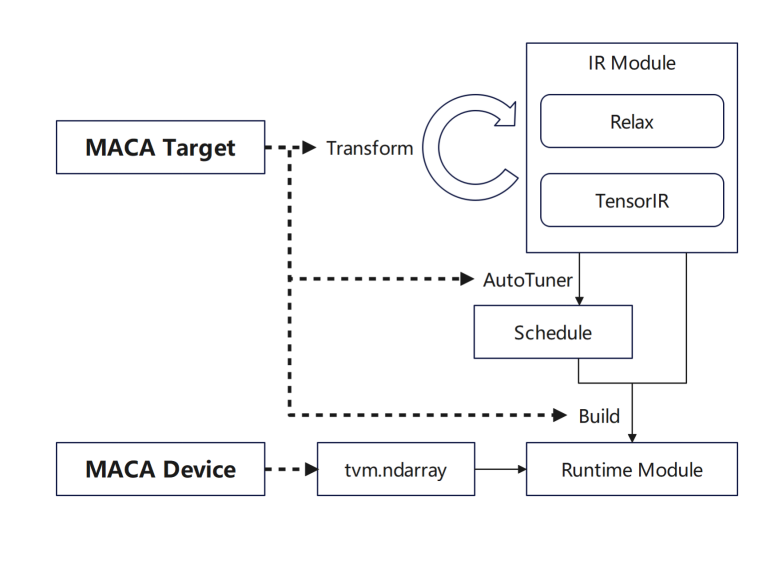
Now many of our products support subdevices at the TVM level, and the backend performs optimization actions for different products based on subdevices.In different products, the compiler will automatically select the corresponding adaptation solution based on the difference in device types;At the same time, in batch compilation scenarios, we are trying to make fixed selection configurations for different architectures.During the general compilation phase, the compiler will dynamically adjust function-related compilation rules for different architectures based on the specific configuration.
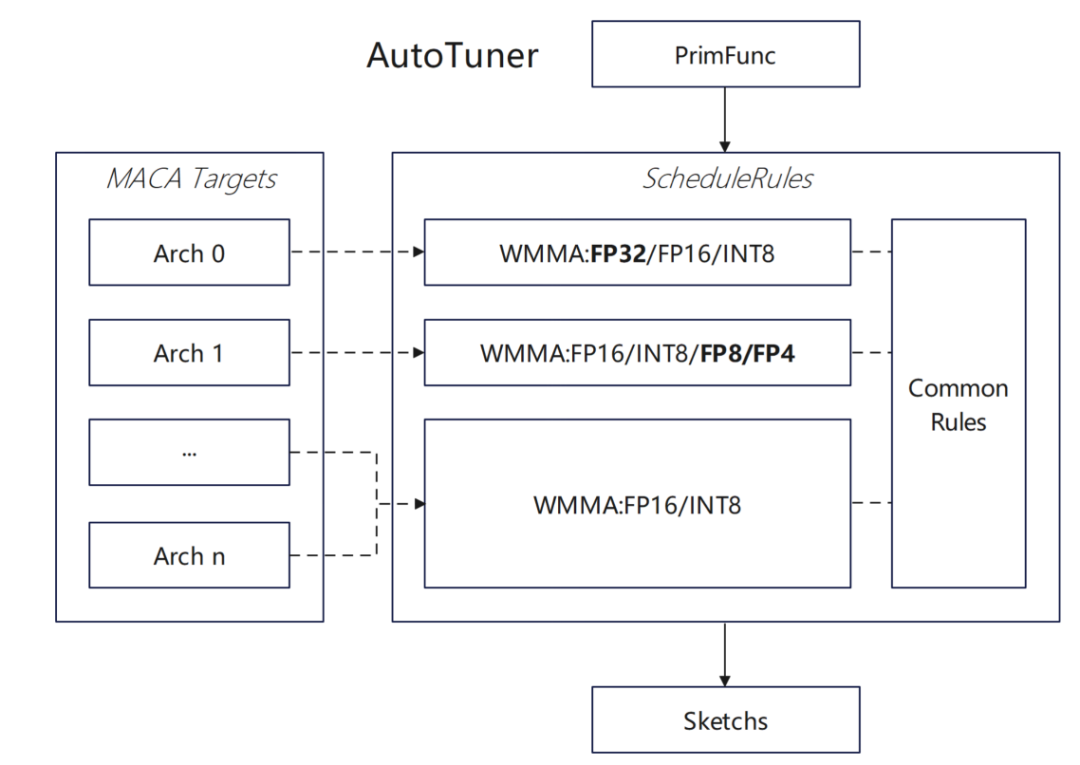
In terms of operator adaptation, we have done upper-level configuration, mainly including:
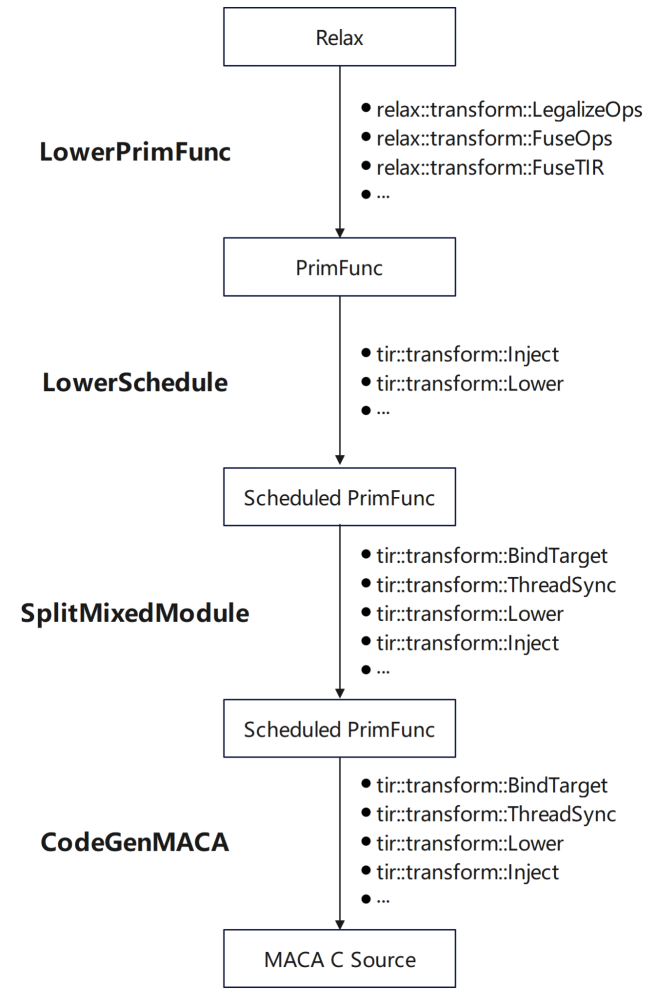
* In Lower Schedule, add schedule to PrimFunc through TIR scheduling primitive
* In Split Mixed Module, add target and other information, inject maca builtin, and add synchronization instructions for MACA
* When CodeGenMACA, include the header files that MACA depends on, generate the usage of maca wmma api from tir.mma related instructions, and declare and use variables of different types.
During the adaptation process, in order to achieve better performance, we performed special processing based on its characteristics:
* Unable to enable tensorize during tuning: the conv2d operator parameter group is not 1, and the implementation of the MACA operator library is directly used in TOPI;
* Customized operators after onnx model is imported: The Multi Head AttentionV1 operator is highly optimized in the MACA onnx runtime. The call to the operator is encapsulated in contrib, so that TVM can directly use the manually optimized high-performance operator implementation after importing the onnx model.
For us,Vendor custom optimization operators are more likely to be implemented in Python and MAC A:
* In the Python interface, Relax.Function is defined by combining basic operators; tir.PrimFunc uses tir to define the implementation of the operator and add schedules as needed
* In the MACA C interface, tir.call_packed encapsulates the implementation of the high-performance operator library and uses it; tir.call_kernel uses the kernel code implemented in MACA C and compiles it into a PackedFunc call through the TVM stack.
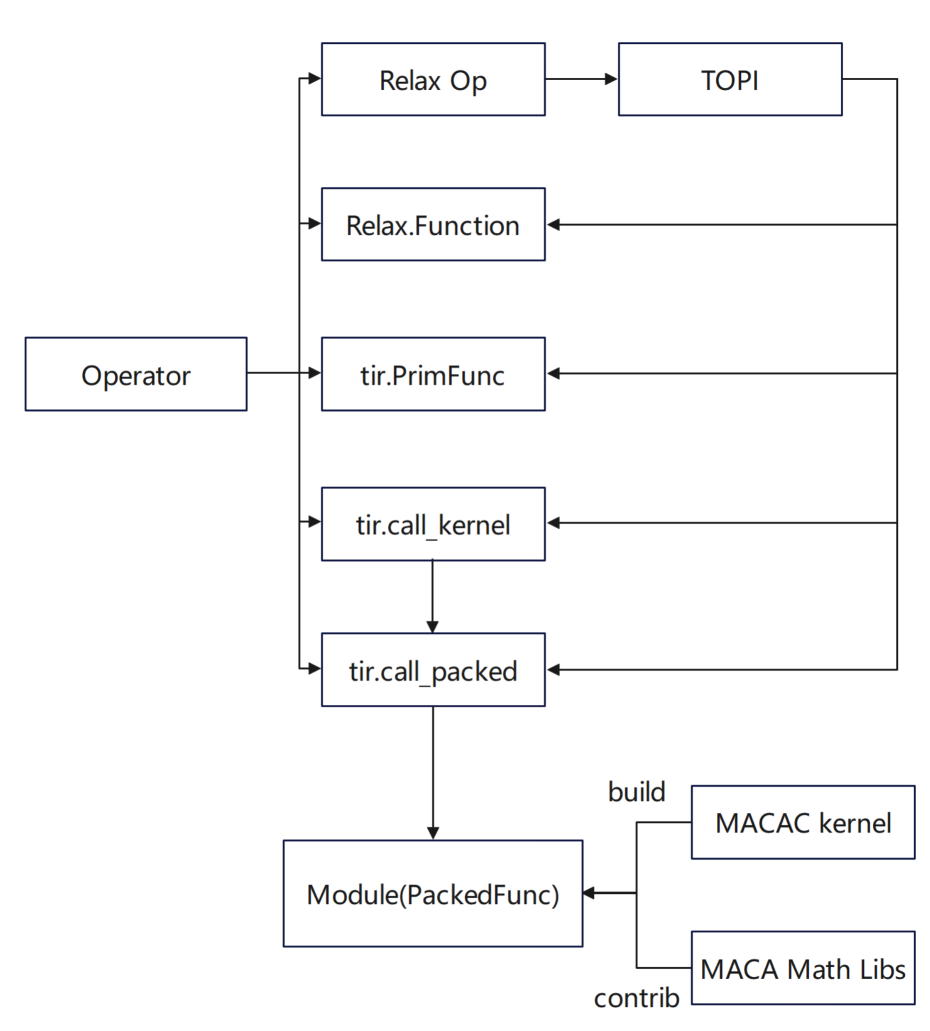
In addition, in order to give full play to the hardware characteristics of Muxi GPU,The team has deeply optimized the TVM scheduling algorithm:
* Added support for WMMA float32 type for MACA target:
First, support float32 type wmma api in MACA, add float32 type auto tensorize rule in MACA ScheduleRules, so that TVM can automatically identify and use hardware WMMA, and add corresponding float32 tensorize optimization in dlight optimization framework to improve matrix operation efficiency.
* Evaluate the impact of asynchronous copy on the scheduling algorithm:
Optimize multiple wmma calculations from loading one group and calculating one group to asynchronously loading the next group of data and synchronously calculating the current group of data, improve pipeline efficiency, and enable software pipeline optimization logic in MACA ScheduleRules, and add asynchronous copy instruction injection and code generation for MACA target
We have also made some attempts to support new datatypes:Enable MACA target adaptation in the DataType system; support auto tensorize logic of Float8 type in MACA ScheduleRules, and expand TVM's support for custom data types such as Float8; implement support for Float8 type conversion and operation code generation in CodeGenMACA, and supplement related operation definitions in maca_half_t.h.
TVM application on Muxi GPU
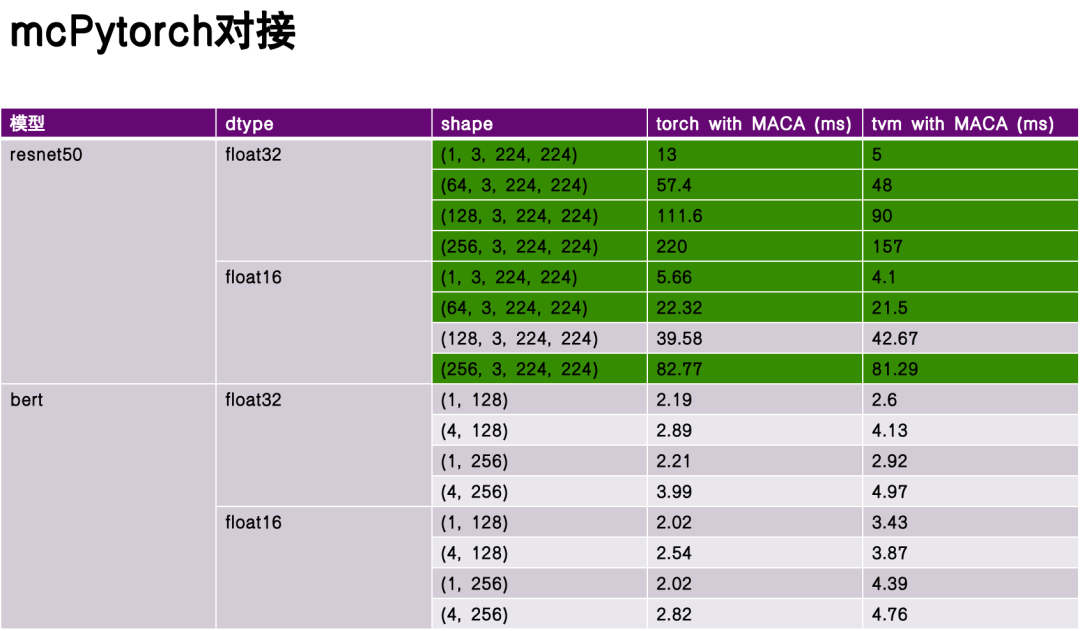
In terms of framework design, the team implemented two access methods:One is to directly import the torch model and execute it in the Relay frontend, and the other is to use torch.compile to use TVM as the backend.It achieves efficient connection between the upper-level framework and the underlying hardware.
In the performance evaluation phase, I selected ReseNet50 and Bert as benchmark models, and compared the performance of Torch and TVM compilation and execution without deep optimization.Experimental data show that TVM has significant advantages in some aspects, and its performance surpasses torch in some scenarios.This is due to the flexibility of TVM intermediate representation (IR) and its targeted optimization for hardware characteristics.
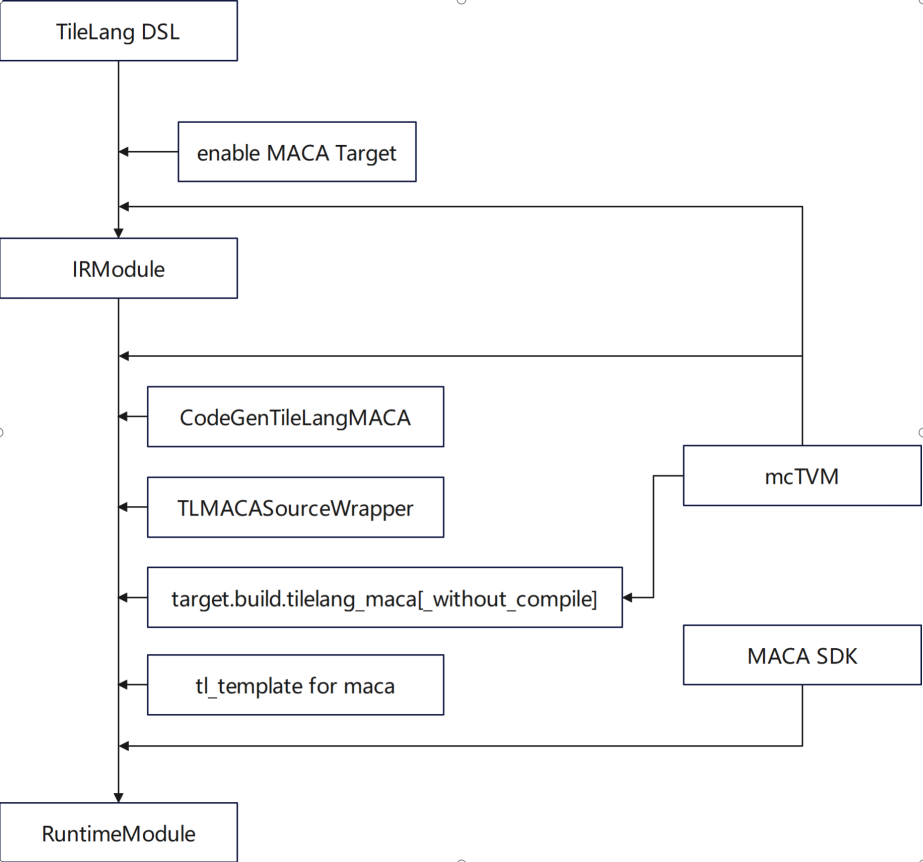
TileLang is a domain-specific language (DSL) in the TVM ecosystem, focusing on the refined optimization of tensor computing.Our team has carried out in-depth functional adaptation in the following aspects:* Support the use of MACA target * Add CodeGenTileLangMACA to generate MACA C Kernel code * Replace and use mcTVM as dependency * Add processing logic of MACA target in libgen, adapter and wrapper * Add MACA target definition using gemm in tl_template
In terms of optimization, the work mainly revolves around the implementation of gemm in tl_template and the implementation of algorithms that adapt to the characteristics of Muxi GPU.
In terms of the interaction between vendors and the community, TileLang's design and development must balance three major principles:
In terms of language design,The first thing to solve is the balance between abstraction and high performance.Specifically, when faced with multiple computing units, the compiler should provide a flexible strategy selection mechanism - allowing developers who have a deep understanding of the underlying hardware characteristics to specify specific code generation paths, while also supporting ordinary developers to achieve efficient programming through abstract interfaces without having to pay attention to the underlying details. This balance is the core element that TileLang, as a DSL, needs to focus on during the design phase.
Secondly,The customized configuration of the Vendor and the standardization of the DSL need to be considered.The compiler should support multi-level optimization option configuration, for example, allowing advanced users to adjust the underlying compilation strategies such as loop unrolling level and inherited pressure through parameters, so as to obtain better code generation results. At the same time, for different hardware architectures, the compiler needs to provide targeted optimization tips and annotation mechanisms to assist developers in selecting the optimal compilation path according to hardware characteristics and improve development efficiency.
third,The interface continuity between generations of products must be ensured.During the iteration process of compilers and language tool chains, backward compatibility of interface design should be ensured - the compilation logic and generated code of the current version can still run effectively in the next generation of hardware products to avoid code reconstruction costs caused by architecture iteration. This continuity is the foundation of ecological construction, which can achieve the "additive" accumulation of compiler tool chain functions rather than "subtractive" loss due to incompatibility. At the same time, it can reduce the user's learning and migration costs and avoid usage confusion.
Challenges and opportunities
Finally, I would like to talk about the challenges and opportunities facing the current development of the industry.The challenges are mainly reflected in the following aspects:
The first is that frameworks and application-based algorithms change quickly.With the rapid development of fields such as deep learning, the update cycle of upper-level frameworks and algorithms continues to shorten, and the increase in functionality and performance has brought pressure on compiler adaptation - the compiler community needs to establish an efficient adaptation mechanism to quickly respond to the support needs of new operators and new computing models.
Secondly, the hardware architecture continues to evolve.Currently, the compiler can support the features of some GPU architectures. If new hardware architecture features emerge in the future, the compiler must also be able to accommodate heterogeneous hardware features.
The third is that programming paradigms continue to evolve.From traditional C/C++ to the emerging functional programming and heterogeneous programming models, how to define the ecological chain related to Python is a big challenge.
Finally, it is a balance between accuracy, performance and power consumption.In practical applications, compilers not only need to pay attention to code performance, but also hardware power consumption, which is equally important. These factors are related to the subsequent instruction selection and architecture design.
future,We would like to do some co-construction with the community:
In terms of open source strategy, we plan to open the core components of the framework and operator library, including key computing modules such as FlashMLA. Through the open source model, we will promote the iterative optimization of the compiler tool chain and form an ecological scale effect.
Secondly, we hope that the industry's applications, frameworks, operator libraries, compilers, and hardware architectures will have closer opportunities for cooperation. Through regular technical exchanges (such as industry forums), we will focus on core issues such as compilation optimization difficulties and operator scheduling strategies, promote cross-domain cooperation, and explore technological innovations.
Muxi also focuses on ecosystem co-construction. Its construction initiatives include: building a technical community forum to receive developers' feedback and problem reports on compiler tool chains; holding theme competitions for operators and frameworks; providing benchmarks, and co-building field-specific Test Suites and Benchmarks with the community.








