Command Palette
Search for a command to run...
AMD AI Architect Zhang Ning: Analyzing AMD Triton Compiler From Multiple Perspectives to Help Build an Open Source Ecosystem

On July 5, the 7th Meet AI Compiler Technology Salon hosted by HyperAI was held as scheduled. Despite the scorching heat of midsummer, the enthusiasm of the audience was still strong. The venue was packed with people, and many of them even stood to listen to every sharing session. Many lecturers from AMD, Muxi Integrated Circuits, ByteDance, and Peking University took turns to take the stage, bringing profound industry insights and trend analysis from the bottom-level compilation to the actual implementation, full of practical information!
Follow the WeChat public account "HyperAI Super Neuro" and reply to the keyword "0705 AI Compiler" to obtain the authorized lecturer's speech PPT.




As a programming language designed to simplify high-performance GPU Kernel development, Triton has become a key tool in the LLM reasoning and training framework by simplifying complex parallel computing programming. Its core advantage is to balance development efficiency and hardware performance - it avoids the exposure of underlying hardware details and can release GPU computing power through compiler optimization. This feature has made it quickly popular in the open source community.
As a leading company in the GPU field, AMD has taken the lead in supporting the Triton language and contributing relevant code to the open source community to promote cross-vendor compatibility of the Triton ecosystem. This move not only strengthens AMD's technical influence in the field of high-performance computing, but also provides global developers with more flexible GPU programming options through an open source collaboration model, especially in large model training and reasoning scenarios, providing a new path for computing power optimization.
In a speech titled "Supporting the open source community, analyzing the AMD Triton compiler", Zhang Ning, an AI architect from AMD, systematically interpreted the core technology, underlying architecture support, and ecological construction achievements of the AMD Triton compiler, focusing on the company's technical contributions to the open source community.It provides developers with a comprehensive perspective to deeply understand high-performance GPU programming and compiler optimization.
HyperAI has compiled and summarized Professor Zhang Ning’s speech without violating the original intention. The following is the transcript of the speech.
Triton: efficient programming, real-time compilation, flexible iteration
Triton was proposed by OpenAI and is an open source programming language and compiler designed to simplify the development of high-performance GPU kernels.It is widely used in mainstream LLM reasoning training frameworks. Its core features include:
* Efficient programming can simplify Kernel development, allowing developers to efficiently write GPU code without having to deeply understand the complex underlying GPU architecture;
* Real-time compilation, supporting just-in-time compilation, can dynamically generate and optimize GPU code to adapt to different hardware and task requirements;
* Flexible iteration space structure, based on block program and scalar thread, enhances iteration space flexibility, facilitates handling of sparse operations and optimizes data locality.
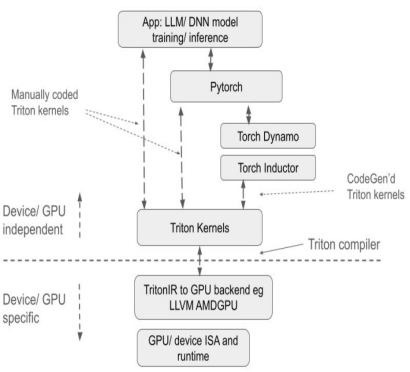
Compared with traditional solutions, Triton has significant advantages:
first,As an open source project, Triton provides a Python-based programming environment. Users can implement GPU Kernel by developing Python Triton code without paying attention to the details of the underlying GPU architecture, which greatly reduces the difficulty of development and significantly improves product development efficiency compared to other GPU programming methods such as AMD HIP. Its compiler uses a variety of optimization strategies based on GPU architecture characteristics to convert Python code into optimized GPU assembly code, realize automatic compilation of upper-level tensor operations to underlying GPU instructions, and ensure efficient operation of the code on the GPU.
Secondly,Triton has good cross-hardware compatibility. The same set of code can theoretically run on a variety of hardware, including NVIDIA and AMD GPUs and domestic GPUs that support Triton. In terms of performance and flexibility, it can provide better performance and optimization flexibility than platforms such as PyTorch, and can hide the underlying GPU operation details compared to CUDA, allowing developers to focus more on algorithm implementation.
Compared with PyTorch API, it focuses more on the specific implementation of computing operations, allowing developers to flexibly define thread block segmentation methods, operate block/tile level data reading and writing, and execute hardware-related computing primitives. It is particularly suitable for developing performance optimization strategies such as operator fusion and parameter tuning.
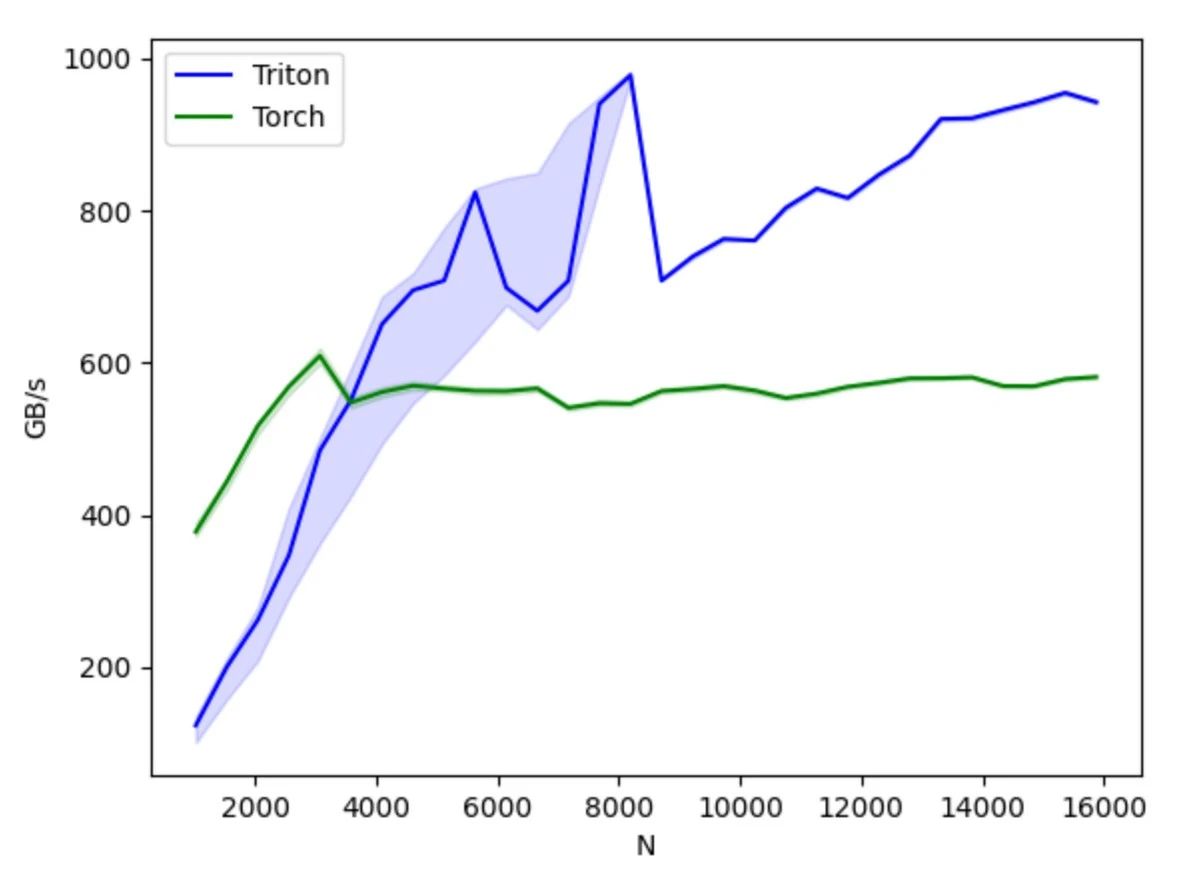
Compared to CUDA, Triton hides the thread-level operation control and instead lets the compiler automatically take over details such as shared storage, thread parallelism, merged memory access, and tensor layout, reducing the difficulty of the parallel programming model while improving the efficiency of GPU code development, achieving an effective balance between development efficiency and program performance. Developers can focus on the design and implementation of the algorithm without having to worry too much about the underlying hardware details and programming optimization techniques. As long as they understand simple parallel programming principles, they can quickly develop GPU code with better performance.
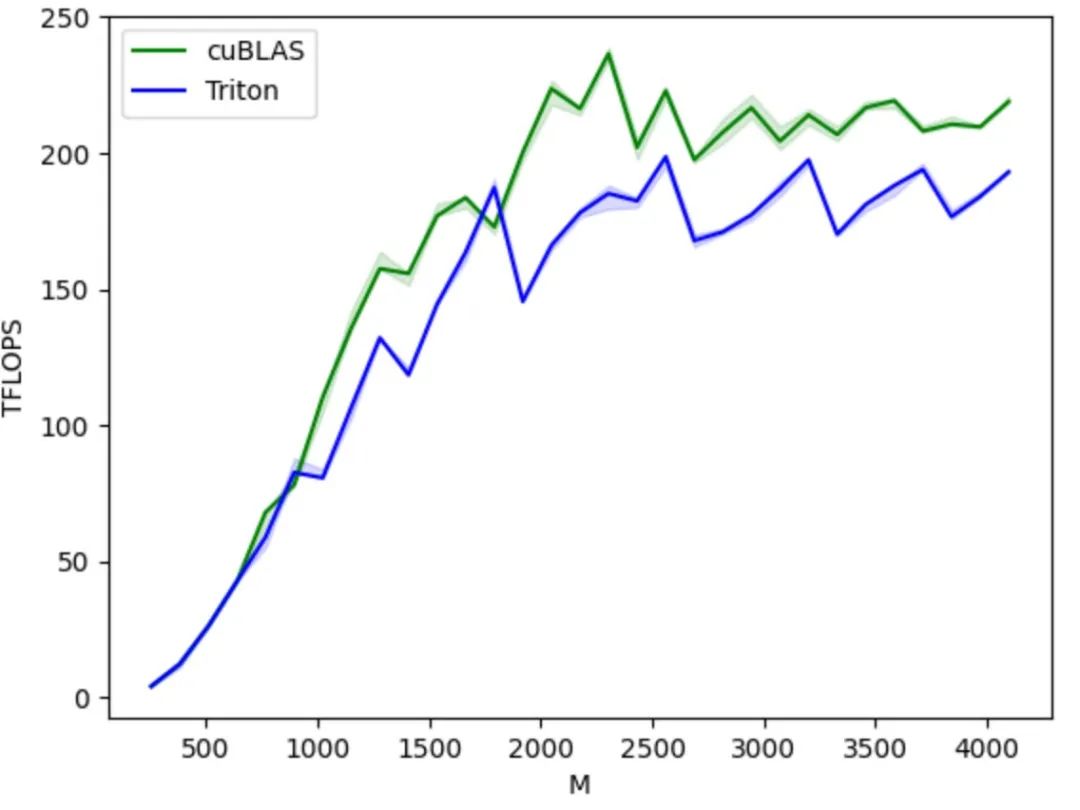
From an ecological perspective, it is based on the Python language environment and uses the tensor data type defined by PyTorch, and its functions can be seamlessly integrated into the PyTorch ecosystem. Compared with the closed CUDA, Triton's open source code and open ecosystem also make it easier for AI chip manufacturers to port it to their own chips and use the open source community to improve their tool chain, which also promotes the healthy development of the Triton ecosystem.
AMD Triton Compiler Process
The Triton compiler consists of three key modules: the front-end module, the optimizer module, and the back-end machine code generation module, as shown in the following figure:
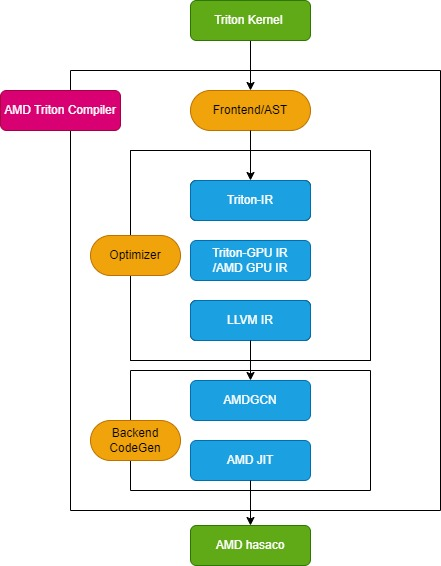
Front-end module
The frontend module traverses the abstract syntax tree (AST) of the Python Triton kernel function to create the Triton intermediate representation (Triton-IR), and its kernel function is converted to Triton-IR.For example, the add_kernel kernel function marked with the @triton.jit decorator will be converted into the corresponding IR in this module. The JIT decorator entry function first checks the value of the TRITON_INTERPRET environment variable. If the variable is True, InterpretedFunction is called to run the Triton kernel in interpreted mode; if it is False, JITFunction is run to compile and execute the Triton kernel on the actual device.
The entry point for kernel compilation is the Triton compile function, which is called with the target device and compilation option information. This process creates the kernel cache manager, starts the compilation pipeline, and fills the kernel metadata. In addition, it loads backend-specific dialects, such as TritonAMDGPUDialect for AMD platforms, and backend-specific LLVM modules that handle LLVM-IR compilation. If all preparations are ready, the ast_to_ttir function is called to generate the Triton-IR file for the kernel.
Optimizer module
The optimizer module is divided into 3 core parts: Triton-IR optimization, Triton-GPU IR optimization and LLVM-IR optimization.
* Triton-IR Optimization
On AMD platforms, the Triton-IR optimization pipeline is defined by the make_ttir function. At this stage, optimizations are hardware-independent and include inlining, common subexpression elimination, normalization, dead code elimination, loop-invariant code motion, and loop unrolling.
* Triton-GPU IR optimization
On the AMD platform, the Triton-IR optimization process is defined by the make_ttgir function to improve GPU performance. Based on the characteristics of AMD GPUs and optimization experience, we have also developed a specific optimization process, as shown in the following figure:
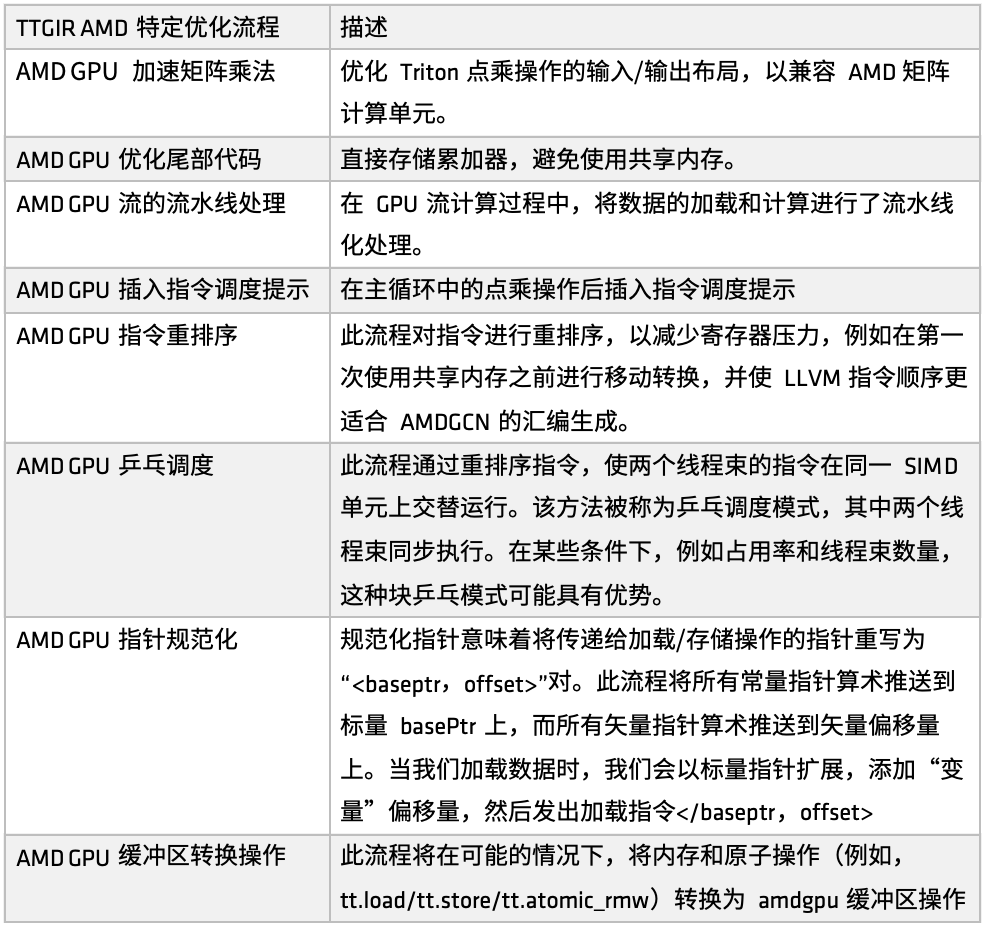
First, accelerated matrix multiplication for AMD GPUs,The optimization focuses on the input/output layout of the point multiplication operation in Triton, making it more compatible with AMD's matrix computing unit (such as Matrix). This optimization involves a lot of matching processing for the CDNA architecture, which is a relatively large part of the entire implementation. If you want to deeply optimize the code generated by Triton on the AMD platform, this part of the implementation is worth focusing on.
Secondly, in the tail processing stage,The optimization strategy is to directly store the accumulator, thereby avoiding the use of shared memory, reducing the access pressure of shared memory, and improving overall efficiency.
Next, in the GPU stream computing process, pipeline processing of loading and computing was introduced.That is, while the previous task is being executed, the corresponding memory is called to load data, forming a mode of parallel execution of loading and computing. This mechanism has achieved good results in many user scenarios. On the basis of pipeline optimization, instruction scheduling hints are also introduced to guide the instruction flow after the computing unit or remote operation is completed, thereby improving the response efficiency at the instruction level.
Subsequently, AMD implemented multiple sets of instruction reordering for different purposes.Including: relieving register pressure, avoiding redundant resource allocation and release, optimizing the connection between load and calculation process, etc. One part of the reordering is closely integrated with the pipeline mechanism, and the other part focuses on adjusting the instruction order of LLVM IR to better serve the generation rules of AMDGCN assembly.
In addition to instruction reordering and scheduling hints,We also introduced another scheduling optimization strategy - ping-pong scheduling.Through the circular scheduling mechanism, two thread warps are executed alternately on the same SIMD unit to avoid idleness and waiting, thereby improving the utilization of computing resources.
Additionally, AMD has made optimizations in pointer normalization and buffer operation conversions.The main goal of this optimization is to effectively map instructions to specific business applications and achieve more efficient atomic instruction execution.
These optimization processes first convert Triton-IR to Triton-GPU IR. In this process, layout information is embedded into the IR. Take the following figure as an example, where the tensor is represented in the form of #blocked layout.

If we try another Triton matrix multiplication example, the above optimization flow introduces shared memory access to improve performance, which is a common optimization solution for matrix multiplication, while using the amd_mfma layout designed for the AMD MFMA accelerator.
at last,In the experimental verification, I took a more complex Matrix Multiplication matrix layer as an example. In the process of confirming the GPR (General Purpose Register) mapping, a large number of hardware-related instructions were inserted, such as MFMA, transposed, shared memory calls, etc. By reducing bank conflicts, applying swizzled operations, and combining instruction reordering and pipeline processing strategies, all these optimizations will be automatically added during the Triton IR conversion process to achieve stronger hardware adaptability and performance improvement.

* LLVM-IR optimization
On AMD platforms, the optimization process is defined by the make_llir function. This function includes 2 parts: IR-level optimization and AMD GPU LLVM compiler configuration. For IR-level optimization, the AMD GPU-specific optimization process includes LDS/shared memory related optimizations and general optimizations at the LLVM-IR level, as shown in the following figure:
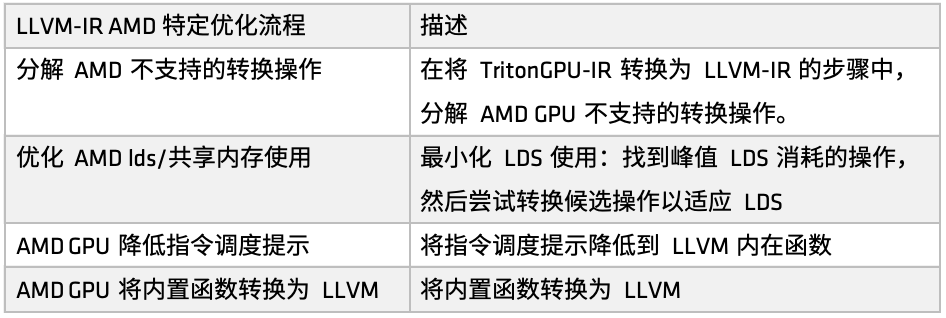
first,Decompose some conversion operations that AMD does not support. For example, when converting Triton GPU IR to LLVM-IR, if we encounter conversion paths that are not currently supported, we will decompose these operations into more basic sub-operations to ensure that the entire conversion process can be completed smoothly.
When configuring the AMD GPU LLVM compiler, first initialize the LLVM target library and context, set the compilation parameters on the LLVM module, then set the calling convention for the AMD GPU HIP kernel, and configure some LLVM-IR properties such as amdgpu-flat-work-group-size, amdgpu-waves-per-eu, and denormal-fp-math-f32, and finally run LLVM optimizations and set the optimization level to OPTIMIZE_O3.
Property configuration reference documentation:
https://llvm.org/docs/AMDGPUUsage.html
Backend machine code generation module
The backend machine code generation module is mainly responsible for converting the intermediate code into a binary file that can run on the hardware. This stage is mainly divided into two steps: generating AMDGCN assembly code and building the final AMD hsaco ELF file.
First, call the translateLLVMIRToASM function to generate AMD assembly code in the make_amdgcn stage. This process completes the mapping from the intermediate code to the target architecture instruction set, laying the foundation for subsequent binary generation. Subsequently, the compiler uses the assemble_amdgcn function and the ROCm link module to generate an AMD hsaco ELF (Executable and Linkable Format) binary file in the make_hsaco stage. This file is the final binary that can be run directly on the AMD GPU and contains complete device-side instructions and metadata.
Through these two steps, the compiler efficiently converts high-level intermediate representation into low-level GPU executable code, ensuring that the program can run smoothly on GPUs such as the AMD Instinct series and fully utilize the performance of the underlying hardware.
AMD GPU Developer Cloud
AMD officially opens its high-performance GPU cloud platform, AMD Developer Cloud, to global developers and open source communities.It aims to enable every developer to have unimpeded access to world-class computing resources, conveniently access AMD Instinct MI series GPU resources, and quickly get started with AI and high-performance computing tasks.
In AMD Developer Cloud, developers can flexibly choose computing resources based on their needs:
* Small: 1 MI series GPU (192 GB VRAM)
* Large: 8 MI series GPUs (1536 GB VRAM)
The platform minimizes the configuration threshold, and users can instantly start the cloud-based Jupyter Notebook without complicated installation. Configuration can be easily completed with just a GitHub account or email. In addition, AMD Developer Cloud provides pre-configured Docker containers with built-in mainstream AI software frameworks, which minimizes the time to set up the environment while retaining a high degree of flexibility, allowing developers to customize the code according to specific project needs.
Developers are welcome to experience AMD Developer Cloud in person, run your code and verify your ideas here. The platform will provide you with stable, powerful and flexible computing power support to accelerate innovation and implementation.
AMD Developer Cloud Link:
https://www.amd.com/en/developer/resources/cloud-access/amd-developer-cloud.html
Get the PPT:Follow the WeChat public account "HyperAI Super Neuro" and reply to the keyword "0705 AI Compiler" to obtain the authorized lecturer's speech PPT.








