Command Palette
Search for a command to run...
The National University of Singapore Has Implemented fine-grained Patient Cohort Modeling Based on multi-dimensional EHR Data, and the Accuracy of Hospital Stay Prediction Has Increased by 16.3%

In today's era of rapid development of medical information technology, electronic health records (EHR) have become an important core component of the medical system. With its systematic architecture, EHR accurately stores patients' medical records in electronic form.Covering everything from basic demographics to dynamic, time-varying medical characteristics,It provides solid data support for all aspects of medical practice and plays an irreplaceable role in key areas such as assisting clinical decision-making and optimizing patient management.
Looking back at clinical practice during the peak of the COVID-19 pandemic in 2020, doctors discovered key patterns by constructing cohorts of patients of different age groups: patients aged 50-70 were more likely to experience severe symptoms such as dyspnea and cognitive decline, while patients aged 20-40 were mostly mild or asymptomatic. This cohort-based comparative analysis not only provides a direct basis for the formulation of diagnosis and treatment plans, but also reveals the core element of EHR representation learning that has been neglected for a long time - patient cohorts.
As the basic unit of medical research, cohorts identify groups of patients with similar clinical characteristics through shared features. Their value far exceeds the simple accumulation of individual data: they can not only discover the disease patterns of specific populations, such as the correlation between fever symptoms and COVID-19 infection, but also provide targeted evidence for precision medical intervention. However, traditional cohort division methods have many limitations and are difficult to meet the requirements of refined EHR data processing.If fine-grained queue division cannot be achieved, noise is easily introduced and valuable information within and between queues cannot be fully utilized.
In this context,The National University of Singapore and Zhejiang University jointly proposed the innovative method NeuralCohort, which opened up a new path for EHR representation learning.Through its unique dual-module architecture, this method is expected to break through existing difficulties, fully unleash the potential of EHR data, and inject powerful impetus into medical analysis. Its application prospects in the medical field have attracted much attention. It is expected to profoundly transform medical data analysis and clinical decision-making models, and promote the medical industry to move towards a higher level of intelligent and precise development.
The related research results were selected for ICML 2025 under the title "NeuralCohort: Cohort-aware Neural Representation Learning for Healthcare Analytics".
Research highlights:
* NeuralCohort proposed in this study is a queue-aware neural representation learning method that focuses on supporting fine-grained queue generation
* NeuralCohort innovatively exploits both local within-cohort and global between-cohort information, key elements that have not been adequately addressed in previous electronic health record analysis studies
* NeuralCohort’s advantage lies in its excellent compatibility and its ability to be seamlessly integrated into various backbone models. It can be used as a versatile plug-in to incorporate cohort information into medical analysis, thereby improving overall performance.

Paper address:
https://openreview.net/forum?id=bqQVa6VRvm
More AI frontier papers:
https://go.hyper.ai/owxf6
EHR data system: multi-dimensional medical information integration and clinical research data set support
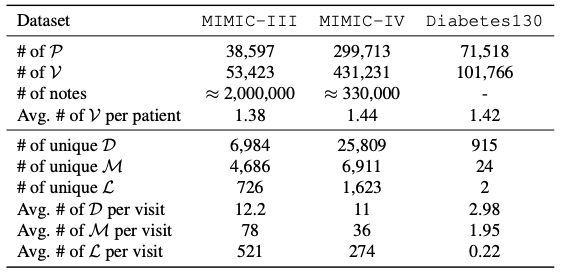
The core data system involved in this study is based on electronic health records (EHR).Its data structure integrates the patient's full-cycle medical information.Including detailed records of hospitalization, outpatient, and emergency, as well as multi-dimensional information such as clinical diagnosis, treatment plan, medication history, test results, imaging reports, and clinical notes, forming a structured database that longitudinally tracks the health status of patients, providing full-chain data support for clinical decision-making, personalized medicine, and population health research. As shown in the table below, the specific data sets used in this study include:
The MIMIC-III dataset is an important publicly accessible medical resource, covering 53,423 unique hospitalization records.It involves adult patients aged 16 years and older admitted to the intensive care unit of Beth Israel Dekaney Medical Center between 2001 and 2012, and also contains 2,083,180 de-identified clinical notes, providing deep insights into the development of patients' illness, treatment process and clinical decision-making.
The MIMIC-IV dataset focuses on patient admission information collected between 2008 and 2022.It adopts a modular data organization structure, emphasizing the traceability and independence of data sources, making it convenient for researchers to flexibly call on different data sources and their joint data according to their needs.
The Diabetes130 dataset collects clinical care data from 130 U.S. hospitals and integrated health care networks between 1999 and 2008., focusing on pattern analysis in the field of diabetes treatment, its unique data themes and long-term data accumulation provide accurate data support for in-depth research on historical diabetes care patterns, optimizing treatment plans for diabetic patients, and achieving safe and personalized medical services.
NeuralCohort model: a dual-module driven cohort-aware EHR representation learning framework
In order to effectively integrate patient cohorts to enhance the representation learning effect of electronic health record (EHR) data, NeuralCohort consists of two core modules: Pre-context Cohort Synthesis Module and Biscale Cohort Learning Module.
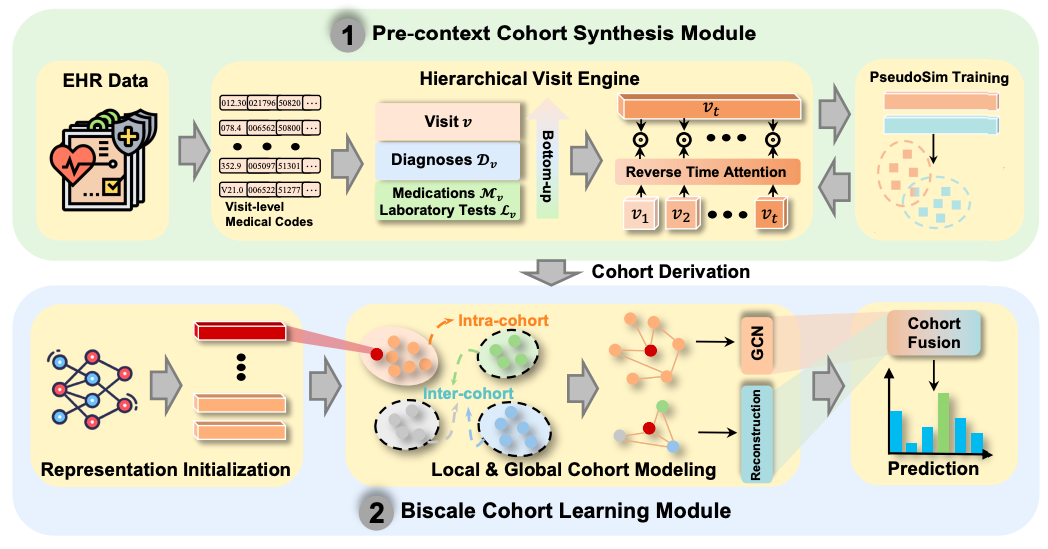
In the pre-context queue synthesis module,The NeuralCohort model first introduced a hierarchical visit engine.It can handle complex diagnostic code ontology structures, such as the tree system of ICD-9. By combining path representation with semantic similarity measurement, the module can effectively distinguish medical terms with hierarchical associations, such as the different codes of diabetes and its complications. At the same time, the model can integrate the hierarchical features of diagnosis, drug, and test codes.And use the reverse time attention mechanism (Reverse Time Attention),The historical visit information is dynamically aggregated with the current visit as the anchor point to capture the temporal dependency of the visit sequence.
To address the inefficiency of traditional manual annotation of patient similarity, the module innovatively introduced the PseudoSim Training task, generated pseudo labels using diagnostic codes, and optimized patient representation through mutual information neural estimation. Finally, cohort derivation was achieved with the help of Jensen-Shannon divergence and Student's t distribution, providing a structured patient grouping scheme for subsequent analysis.
The dual-scale queue learning module is dedicated to mining the common features within the queue and the different features between different queues..In Local Cohort Modeling, the model treats each cohort as a graph structure and constructs an adjacency matrix using the cosine similarity of patient representations. The graph neural network aggregates node information layer by layer to capture the interaction patterns of patients in the same cohort.
Global Cohort Modeling uses an encoder-decoder architecture to maintain the semantic integrity of the cohort through reconstruction loss, while combining contrast loss to strengthen the feature separation of different cohorts and ensure cross-cohort distinguishability.
Finally, the initial representation of the backbone network, the local representation within the queue, and the global representation between queues are fused through the cross-domain attention mechanism to form a final representation containing multi-level queue information. During the model training process, the loss function integrates pseudo-similarity training loss, queue derivation loss, queue comparison loss, and downstream task loss, and multi-objective optimization is achieved through weight parameter adjustment. This enables NeuralCohort to not only learn fine-grained individual patient characteristics, but also capture clinically interpretable queue group patterns, providing a solution that combines accuracy and interpretability for medical data analysis tasks, and is expected to promote the scientific and precise medical decision-making.
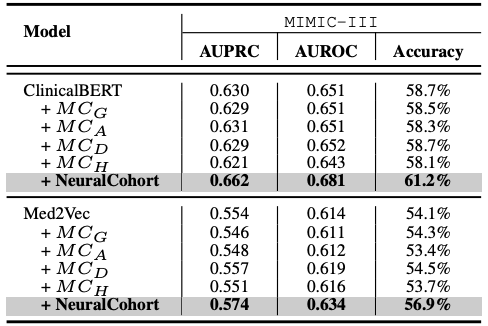
Multi-dimensional experimental verification: NeuralCohort model accuracy increased by 16.3%, significantly enhancing decision-making in patient management
To evaluate the optimization effect of NeuralCohort on electronic health record (EHR) representation learning, the research team constructed a comprehensive experimental framework.
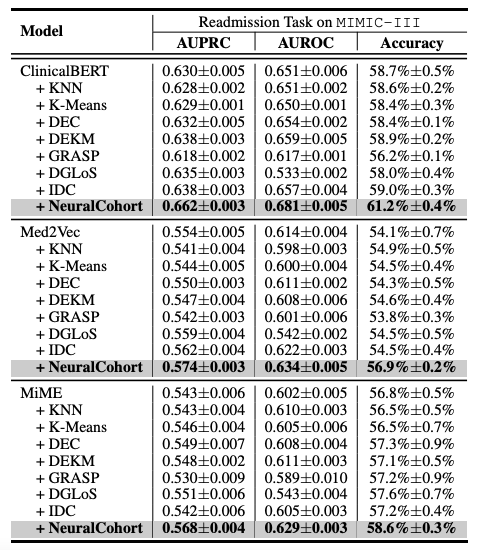
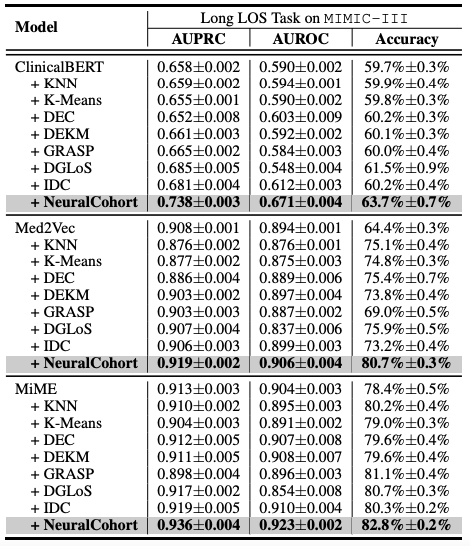
The researchers selected Med2Vec, MiME and ClinicalBERT, three representative models in the field of medical data analysis, as benchmark frameworks. At the same time, in order to make an effective comparison, seven traditional cohort integration algorithms such as KNN and K-Means were included in the experiment as comparison methods.
The experimental design focuses on two key medical prediction tasks: hospital readmission prediction and long-term stay (LOS) prediction.These two tasks are of great significance for medical resource management and improving the quality of patient care. In order to comprehensively evaluate the performance of the model, the researchers used three widely recognized evaluation indicators, AUPRC, AUROC, and accuracy, and conducted five rounds of repeated experiments to obtain stable and reliable statistical results, thereby systematically evaluating the generalization ability of the model.
The overall experimental results are shown in the following table. NeuralCohort performs well in two prediction tasks of the MIMIC-III dataset. Compared with the traditional baseline model,The AUPRC indicator was improved by up to 8.0%, the AUROC indicator was improved by 8.1%, and the accuracy was significantly higher by 16.3%.
Further analysis revealed that the baseline model failed to achieve consistent performance gains.The main reason is that it is insufficient in modeling fine-grained queue information.For example, KNN and K-Means algorithms do not operate in a similarity-aware feature space, the global graph constructed by DGLoS is coarse-grained, GRASP focuses only on modeling between cohorts, and DEC, DEKM, and IDC cannot effectively model medical semantics. These defects cause the baseline model to perform poorly in simulating patient similarities and may even introduce noise into the backbone model, thereby reducing the overall performance.
Compared with traditional medical cohort construction methods, NeuralCohort also shows significant advantages. Traditional methods usually divide cohorts based on limited features such as gender, age, diabetes diagnosis, and hypertension diagnosis. The cohorts generated by this method are relatively coarse-grained, which is difficult to meet the needs of cohort pattern mining, and it is easy to group dissimilar patients into the same cohort, introducing noise. In contrast, NeuralCohort uses the sequential visit level representation of patients within and between cohorts to operate at a fine-grained level.This improved the clinical similarity of patients in the cohort in the MIMIC-III dataset by 23.5%.
Comparison of traditional cohort and NeuralCohort on the MIMIC-III dataset
Interpretability analysis further reveals the advantages of NeuralCohort. The Calinski-Harabasz score shows that the cohort generated by NeuralCohort improves the CH score by 18.7%-25.4% in the long-term LOS task compared with methods such as K-Means. Visual analysis based on t-SNE also shows that the representation directly output by the baseline model has significant cluster overlap, while NeuralCohort, as shown in the figure below, injects cohort information.The discrimination of the eight target cohorts was improved by 41.2%, among which the characteristic boundaries of clinical typical groups such as the cardiovascular disease cohort and the chronic metabolic disease cohort were particularly clear.

In clinical terms,NeuralCohort is able to identify cohort-specific characteristics that directly correlate with clinical outcomes, thereby significantly enhancing patient management.For example, the unique characteristics of the four cohorts identified by t-tests covered different types of patient populations such as cardiovascular diseases, chronic metabolic and blood diseases, renal and urinary problems, and complex chronic and acute diseases.
The identification of these characteristics enables hospitals to allocate resources more specifically, such as telemetry beds, cardiology consultations, diabetes educators, renal teams, etc., and formulate corresponding intervention measures, such as timely use of diuretics, insulin titration, and scheduling of imaging examinations, thereby significantly improving hospital efficiency and patient care quality.
Industry-research collaboration, two-way driven EHR innovation ecosystem
In the field of electronic health record (EHR) representation learning and cohort analysis, the global academic and business communities are promoting the deep release of the value of medical data through cutting-edge technological breakthroughs and clinical practice innovations, injecting new impetus into the development of precision medicine.
The MHGRL model proposed by Professor Wang Xiaoli's team at Xiamen University integrates the internal structure of EHR with external medical knowledge by constructing a multimodal heterogeneous graph.The disease prediction accuracy has been significantly improved on datasets such as MIMIC-III.The reverse-time attention mechanism adopted by this model strengthens the correlation between the current visit and the historical record, which echoes the pre-context queue synthesis module of NeuralCohort in technical logic, and both reflect the emphasis on modeling time series information.
The GEMS model built by the Cornell University team is based on 8 million real EHR data.The study demonstrated the direct application of cohort analysis in clinical decision-making. The study captured the 104-dimensional feature vector of patients with advanced lung cancer through a graph neural network encoder, and combined with a clustering module to identify three sub-phenotypes with significant survival differences. Its c-index for predicting overall survival reached 0.665, far exceeding the traditional baseline model. Its technical path is highly consistent with the dual-scale cohort learning module of NeuralCohort in terms of methodology, and both focus on mining clinically significant cohort features from complex data.
The business community has also achieved remarkable results and is transforming cutting-edge technologies from academia into practical clinical application tools. For example, the PATH program, a collaboration between the UK NHS and Hippocratic AI,Through automated medical history collection and referral verification by conversational agents, the waiting period for specialist consultations can be shortened by 35%.This EHR-based intelligent triage system has a built-in cohort analysis module that can identify high-risk patient groups in real time. For example, it can extract complex features such as "chronic obstructive pulmonary disease with acute exacerbation" from clinical notes through natural language processing and dynamically adjust patient priorities.
In summary, the academic community has built more accurate cohort models through algorithm innovation, continuously expanding the depth and breadth of medical data mining; the business community, relying on its technology transformation capabilities, has transformed these cutting-edge technologies into clinical tools that can be implemented, improving the efficiency and quality of medical services. This two-way driven innovation ecosystem is not only expected to help doctors obtain more accurate diagnostic support, but also to discover early warning signals of individual risks from group characteristics, promote the transformation of medical service models from disease treatment to health management, and provide strong support for the optimization and upgrading of the global medical system.
Reference articles:
1.https://cdmc.xmu.edu.cn/info/1002/3683.htm
2.https://mp.weixin.qq.com/s/Z1Wl0FIPHpwrvnNDCE5KwA
3.https://mp.weixin.qq.com/s/neCUoGm75mTPwjvlND5_sg








