Command Palette
Search for a command to run...
OmniGen2 Multimodal Reasoning × self-correction Dual Engine, Leading a New Paradigm for Image Generation; 950,000 Classification Labels! TreeOfLife-200M Unlocks a New Dimension of Species Cognition

In recent years, generative AI technology has made significant breakthroughs in the field of images. Models such as the Stable Diffusion series and DALL-E3 have achieved high-quality text-to-image generation through diffusion models. However, these models lack the comprehensive perceptual understanding and generation capabilities required for general models of visual generation. OmniGen was born to provide a unified solution for various generation tasks based on the diffusion model architecture. It has multi-task processing capabilities and can generate high-quality images without additional plug-ins. It is undeniable that the model still has limitations in multimodal decoupling and data diversity.
To overcome these difficulties and further improve the flexibility and expressiveness of the system, OmniGen2 has achieved a major breakthrough.It has two independent decoding paths for text and image modalities.It uses unshared parameters and a separate image tagger. This design enables OmniGen2 to build on existing multimodal understanding models without refitting the variational autoencoder input, thus preserving the original text generation capabilities.
At present, the HyperAI official website has launched the "OmniGen2: Exploring Advanced Multimodal Generation" tutorial, come and try it~
OmniGen2: Exploring Advanced Multimodal Generation
Online use:https://go.hyper.ai/fKbUP
From June 30 to July 4, hyper.ai official website updates:
* High-quality public datasets: 10
* High-quality tutorial selection: 7
* This week's recommended papers: 5
* Community article interpretation: 5 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in July: 4
Visit the official website:hyper.ai
Selected public datasets
1. ShareGPT-4o-Image image generation dataset
ShareGPT-4o-Image is a large-scale, high-quality image generation dataset that aims to migrate GPT-4o-level image generation capabilities to open source multimodal models. All images in this dataset are generated by GPT-4o's image generation function, and the data contains a total of 92,256 image generation samples from GPT-4o.
Direct use:https://go.hyper.ai/5G48Y

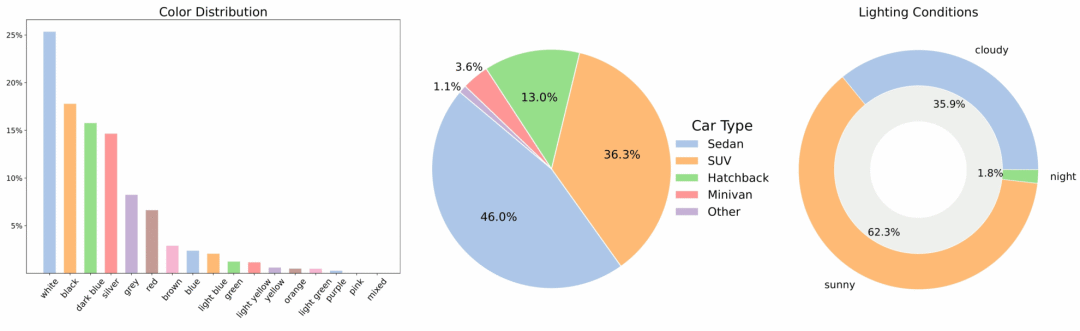
2. MAD-Cars Multi-view Car Video Dataset
MAD-Cars is a large-scale multi-view car video dataset in the wild, which greatly expands the scope of existing public multi-view car datasets. The dataset contains about 70,000 car video instances, with an average of 85 frames per instance. Most car instances have a resolution of 1920×1080, covering about 150 brands of cars, including multiple models, colors, and 3 lighting conditions.
Direct use:https://go.hyper.ai/xuB9I
3. Plants and Crops crop image dataset
The Plants and Crops dataset is a comprehensive crop image dataset for the agricultural AI field, containing 100,000 standardized images, covering 139 crops widely grown around the world. The dataset covers multiple growth stages of crops from seedlings to flowering and fruiting, and the image content covers multiple structural parts such as leaves, stems, and fruits, with rich representation information. All images are unified to 224×224 pixels to reduce the impact of size differences on model training.
Direct use:https://go.hyper.ai/PLVJp

4. Multimodal-Textbook-6.5M Multimodal Textbook Dataset
Multimodal-Textbook-6.5M aims to enhance multimodal pre-training and expand the model's ability to handle interlaced visual and text inputs. The dataset contains 6.5 million images and 800 million text data from teaching videos. All images and texts are extracted from online teaching videos, covering six basic subjects such as mathematics, physics, and chemistry.
Direct use:https://go.hyper.ai/q8Iin
5. IndicVault Indian Question-Answer Pairs Dataset
Indic Vault is an Indian everyday language question-answer dataset suitable for tuning chatbots and voice assistants. The dataset contains question-answer pairs written in contemporary everyday language used across India in 2025, capturing real, colloquial expressions used in daily conversations, covering 20 core categories.
Direct use:https://go.hyper.ai/JhEUR
6. DREAM-1K video description benchmark dataset
The dataset contains 1,000 annotated video clips of varying complexity from 5 different categories, each containing at least 1 dynamic event that cannot be accurately identified from a single frame. Each video is provided with fine-grained manual annotations covering all events, actions, and motions.
Direct use:https://go.hyper.ai/AgOm0
7. Brain MRI brain tumor detection analysis dataset
Brain MRI contains high-quality multi-sequence brain MRI scans from different patients. These scans contain T1-weighted, T2-weighted, FLAIR, and diffusion-weighted imaging sequences. This dataset covers multiple types of brain tumors and is compared with healthy controls, making it suitable for the development and validation of any advanced machine learning models and clinical research applications.
Direct use:https://go.hyper.ai/oZWNu
8. AceReason-1.1-SFT Mathematical Code Reasoning Dataset
This dataset is used as SFT training data for the math and code reasoning model AceReason-Nemotron-1.1-7B. All answers in the dataset are generated by DeepSeek-R1. The AceReason-1.1-SFT dataset contains 2,668,741 math samples and 1,301,591 code samples, covering data from multiple data sources. The dataset has been cleaned and samples with 9-gram overlaps with any test samples in the math and coding benchmarks have been filtered.
Direct use:https://go.hyper.ai/WGl1k
9. TreeOfLife-200M biological vision dataset
TreeOfLife-200M is the largest and most diverse public machine learning-ready dataset for biological computer vision models. The dataset contains nearly 214 million images, covering 952,000 species categories, and integrates images and metadata from 4 core biodiversity data providers.
Direct use:https://go.hyper.ai/UKC0H
10. VL-Health Medical Reasoning Generation Dataset
VL-Health is the first comprehensive dataset for medical multimodal understanding and generation. The dataset integrates 765,000 understanding task samples and 783,000 generation task samples, covering 11 medical modalities and multiple disease scenarios.
Direct use:https://go.hyper.ai/GvKlu
Selected Public Tutorials
This week, we have compiled 3 types of high-quality public tutorials:
*Image generation and editing tutorials: 3
*3D generation tutorials: 2
* Audio Generation Tutorials: 2
Image Generation and Editing Tutorial
1. OmniGen2: Exploring Advanced Multimodal Generation
OmniGen2 aims to provide a unified solution for multiple generation tasks, including text-to-image generation, image editing, and context generation. The design of non-shared parameters and separate image tokenizers enables OmniGen2 to build on existing multimodal understanding models without re-adapting VAE inputs, retaining the original text generation capabilities.
Run online:https://go.hyper.ai/fKbUP

2. FLUX.1-Kontext-dev: Text-driven one-click image editing
FLUX.1 Kontext's image editing is image editing in a broad sense, which not only supports local image editing (targeted modification of specific elements in the image without affecting the rest), but also achieves character consistency (retaining unique elements in the image such as reference characters or objects to keep them consistent in multiple scenes and environments).
Run online:https://go.hyper.ai/PqRGn

3. Flow-GRPO flow matching text graph model demo
This model pioneered the integration of online reinforcement learning framework and flow matching theory, and achieved breakthrough progress in the GenEval 2025 benchmark test: the combined generation accuracy of the SD 3.5 Medium model jumped from the benchmark value of 63% to 95%, and the generation quality evaluation index surpassed GPT-4o for the first time.
Run online:https://go.hyper.ai/v7xkq
3D Generation Tutorial
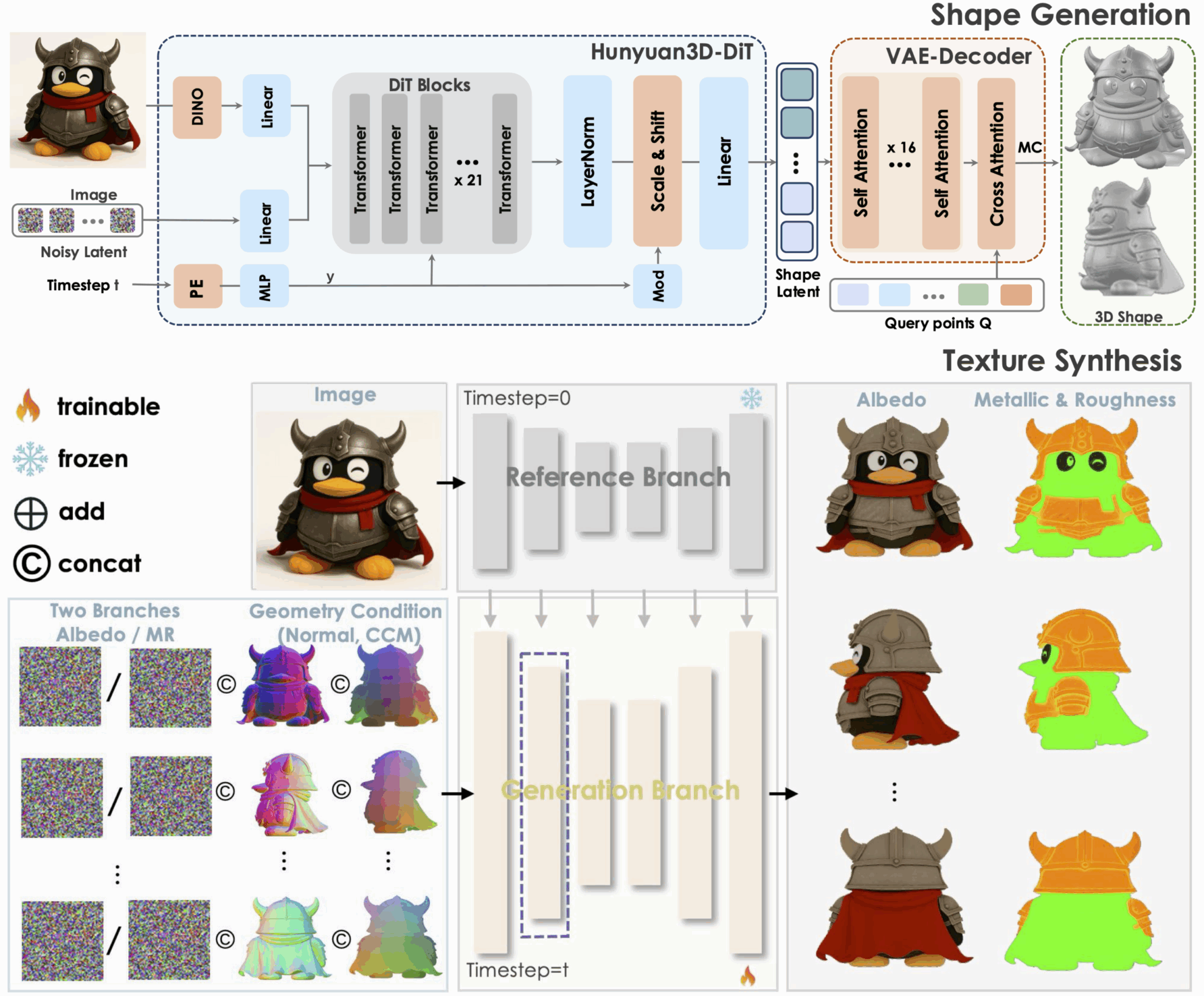
1. Hunyuan3D-2.1: 3D generative model supporting physical rendering textures
Tencent Hunyuan3D-2.1 is an industrial-grade open source 3D generation model and a scalable 3D asset creation system. It promotes the development of cutting-edge 3D generation technology through two key innovations: a fully open source framework and physically based rendering texture synthesis. At the same time, it fully opens up data processing, training and reasoning codes, etc., providing a reproducible baseline for academic research and reducing repeated development costs for industrial implementation.
Run online:https://go.hyper.ai/0H91Z
2. Direct3D‑S2: A framework for high-resolution 3D rendering
Direct3D‑S2 is a high-resolution 3D generation framework that greatly improves the computational efficiency of the diffusion transformer and significantly reduces the training cost based on sparse volume representation and innovative spatial sparse attention mechanism. The framework surpasses existing methods in both generation quality and efficiency, providing strong technical support for high-resolution 3D content creation.
Run online:https://go.hyper.ai/67LQM

Audio Generation Tutorial
1. PlayDiffusion: Open Source Audio Local Editing Model
PlayDiffusion encodes audio into discrete token sequences, masks the parts that need to be modified, and uses a diffusion model to denoise the masked areas given the updated text to achieve high-quality audio editing. It can seamlessly preserve context, ensure the coherence and naturalness of speech, and support efficient text-to-speech synthesis, providing high temporal consistency and scalability.
Run online:https://go.hyper.ai/WTlI4
2. OuteTTS: Speech Generation Engine
OuteTTS is an open source text-to-speech synthesis project. Its core innovation lies in the use of pure language modeling methods to generate high-quality speech without relying on complex adapters or external modules in traditional TTS systems. Its main functions include text-to-speech synthesis and voice cloning.
Run online:https://go.hyper.ai/eQVHL
💡We have also established a Stable Diffusion tutorial exchange group. Welcome friends to scan the QR code and remark [SD tutorial] to join the group to discuss various technical issues and share application results~

This week's paper recommendation
1. GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
This paper presents GLM-4.1V-Thinking, a visual-language model (VLM) designed to advance general multimodal understanding and reasoning. We propose a method that combines reinforcement learning with curriculum sampling to fully tap the model's potential, thereby achieving comprehensive capabilities in tasks as diverse as STEM problem solving, video understanding, content recognition, programming, coreference resolution, GUI-based agents, and long document understanding. GLM-4.1V-9B-Thinking achieves state-of-the-art performance among open source models of the same size, and also shows comparable or better performance than closed source models such as GPT-4o on challenging tasks such as long document understanding and STEM reasoning.
Paper link:https://go.hyper.ai/5UuYG
2. Ovis-U1 Technical Report
This paper introduces Ovis-U1, a unified model with 3 billion parameters that integrates multimodal understanding, text-to-image generation, and image editing. Building on the foundation of the Ovis family, Ovis-U1 combines a diffuse visual decoder and a bidirectional tagging refiner, making it comparable to leading models such as GPT-4o on image generation tasks. Ovis-U1 scores 69.6 on the OpenCompass multimodal academic benchmark, surpassing recent state-of-the-art models such as Ristretto-3B and SAIL-VL-1.5-2B.
Paper link:https://go.hyper.ai/7Q8JV
3. BlenderFusion: 3D-Grounded Visual Editing and Generative Compositing
This paper proposes BlenderFusion, a generative visual synthesis framework that synthesizes new scenes by recombining objects, cameras, and backgrounds. The framework follows a layer-edit-synthesize pipeline: visual inputs are segmented and converted into editable 3D entities; edited using 3D-based controls in Blender; and fused into a coherent scene using a generative compositor. Experimental results show that BlenderFusion significantly outperforms previous methods in complex composite scene editing tasks.
Paper link:https://go.hyper.ai/YoirX
4. SciArena: An Open Evaluation Platform for Foundation Models in Scientific Literature Tasks
This paper introduces SciArena, an open and collaborative platform for evaluating base models on scientific literature tasks. Unlike traditional scientific literature understanding and synthesis benchmarks, SciArena directly engages the research community and adopts an evaluation method similar to Chatbot Arena, where models are compared through community voting. Currently, the platform supports 23 open source and proprietary base models and has collected more than 13,000 votes from trusted researchers in multiple scientific fields.
Paper link:https://go.hyper.ai/oPbpP
5. SPIRAL: Self-Play on Zero-Sum Games Incentivizes Reasoning via Multi-Agent Multi-Turn Reinforcement Learning
This paper introduces SPIRAL, a self-play framework in which models learn by playing multi-round, zero-sum games against continuously improving versions of themselves, eliminating the need for human supervision. To enable large-scale self-play training, the researchers implemented a fully online, multi-round, multi-agent reinforcement learning system and proposed role-conditioned advantage estimation to stabilize multi-agent training. Self-play training for zero-sum games using SPIRAL can produce widely transferable reasoning capabilities.
Paper link:https://go.hyper.ai/n7J4m
More AI frontier papers:https://go.hyper.ai/iSYSZ
Community article interpretation
A research team from Virginia Tech and Meta AI proposed a unified model called UNIMATE, which solves the key bottlenecks in the current AI design of metamaterials through an innovative model architecture. It also realizes for the first time the unified modeling and collaborative processing of the three core elements of metamaterial design, namely three-dimensional topological structure, density conditions and mechanical properties.
View the full report:https://go.hyper.ai/1x8iJ
Zhejiang University, in collaboration with teams from the University of Electronic Science and Technology of China and other institutions, proposed the HealthGPT model. Through an innovative heterogeneous knowledge adaptation framework, they successfully built the first large-scale visual language model that unifies medical multimodal understanding and generation, opening up a new path for the development of medical AI. Related results have been selected for ICML 2025.
View the full report:https://go.hyper.ai/F7W6a
In his speech titled "Construction and Application of Protein Intelligent Computing System", Associate Professor Zhang Shugang from the School of Computer Science at Ocean University of China systematically elaborated on the innovative breakthroughs brought about by intelligent computing technology, focusing on the traditional challenges in the field of protein research, and focusing on the research results of the team in the fields of functional annotation, interaction identification and design optimization. This article is a transcript of Associate Professor Zhang Shugang's speech.
View the full report:https://go.hyper.ai/rTgSi
A team from the Technical University of Munich in Germany and the University of Zurich in Switzerland proposed a new method to generate satellite images using Stable Diffusion 3 (SD3) conditioned on geographic climate cues, and created the largest and most comprehensive remote sensing dataset to date, EcoMapper. The dataset collects more than 2.9 million RGB satellite image data from 104,424 locations around the world from Sentinel-2, covering 15 land cover types and corresponding climate records, laying the foundation for two satellite image generation methods using a fine-tuned SD3 model.
View the full report:https://go.hyper.ai/1zpeD
Science released an exclusive report saying that the funding for CASP from the National Institutes of Health (NIH) has been exhausted, and although the University of California, Davis (UC Davis), which is responsible for managing the project funds, has provided emergency support, it will also be exhausted on August 8, and CASP is facing the crisis of suspension.
View the full report:https://go.hyper.ai/3kTMU
Popular Encyclopedia Articles
1. KAN
2. Sigmoid function
3. Human-machine loop HITL
4. Retrieval Enhancement Generates RAG
5. Reinforcement Fine-Tuning
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
July deadline for the top conference
July 11 7:59:59 POPL 2026
July 15 7:59:59 SODA 2026
July 18 7:59:59 SIGMOD 2026
July 19 7:59:59 ICSE 2026
One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!








