Command Palette
Search for a command to run...
Tutorial Included: New Breakthrough in Medical VLM! HealthGPT Achieves 99.7% Accuracy in Complex MRI Modality Understanding, and a Single Model Can Handle Multiple Generation Tasks

Modern medical diagnosis and research are highly dependent on the interpretation and generation of medical images. From lesion identification in X-rays to image conversion from MRI to CT, each link places stringent requirements on the multimodal processing capabilities of AI systems. However, the current development of medical visual language models (LVLMs) faces two bottlenecks: on the one hand,The particularity of medical data leads to the scarcity of large-scale high-quality annotated data.The size of publicly available medical imaging datasets is usually only one ten-thousandth of the general datasets, which is difficult to support the need to build a unified model from scratch. On the other hand,The inherent contradiction between understanding and generating tasks is difficult to reconcile——Understanding tasks require abstract semantic generalization, while generation tasks require precise retention of details. Traditional hybrid training often leads to performance degradation due to "losing one thing while focusing on another".
From the perspective of technological evolution, early medical LVLMs such as Med-Flamingo and LLaVA-Med mainly focused on visual understanding tasks, achieving semantic interpretation of medical images through image-text alignment, but lacked "visualization" generation capabilities. General-purpose unified LVLMs such as Unified-IO 2 and Show-o, although they have generation functions, perform poorly in professional tasks due to insufficient medical data adaptation. The 2024 Nobel Prize in Chemistry was awarded for breakthroughs in the field of AI protein structure prediction, which indirectly confirmed the potential of AI in the field of life sciences and made the academic community realize that building medical LVLMs with both understanding and generation capabilities has become the key to breaking through the current bottleneck of medical AI applications.
In this regard,Zhejiang University and the University of Electronic Science and Technology of China jointly proposed the HealthGPT model, through an innovative heterogeneous knowledge adaptation framework,Successfully built the first large-scale visual language model that unifies medical multimodal understanding and generation.It has opened up a new path for the development of medical AI, and related results have been selected for ICML 2025.
Paper address:
In response to the two major challenges of medical data limitation and task conflict, the research team proposed a three-layer progressive solution:
First, the heterogeneous low-rank adaptation (H-LoRA) technology is designed.Through the task-gated decoupling mechanism, the understanding and generation knowledge are stored in independent "plugins", avoiding the conflict problem of traditional joint optimization;
Second, develop a hierarchical visual perception (HVP) framework,Utilize the hierarchical feature extraction capability of Vision Transformer to provide abstract semantic features for understanding tasks and retain detailed visual features for generation tasks, thus achieving “on-demand” feature regulation.
Finally, a three-stage learning strategy (TLS) is constructed.From multimodal alignment to heterogeneous plug-in fusion, and then to visual instruction fine-tuning, the model is gradually endowed with specialized multimodal processing capabilities.
Dataset: VL-Health's Multimodal Medical Knowledge Graph
To support HealthGPT training,The research team built the first comprehensive dataset VL-Health for medical multimodal understanding and generation.The dataset integrates 765,000 comprehension task samples and 783,000 generation task samples, covering 11 medical modalities (including CT, MRI, X-ray, OCT, etc.) and multiple disease scenarios (from lung diseases to brain tumors).
Dataset address:
https://hyper.ai/cn/datasets/40990
In terms of understanding tasks, VL-Health integrates professional data sets such as VQA-RAD (radiology questions), SLAKE (semantic annotation knowledge enhancement), PathVQA (pathology question answering), and supplements large-scale multimodal data such as LLaVA-Med and PubMedVision to ensure that the model learns the full chain of capabilities from basic image recognition to complex pathology reasoning. The generation tasks mainly focus on four major directions: modality conversion, super-resolution, text-image generation, and image reconstruction:
* Modal conversion:Based on the CT-MRI paired data of SynthRAD2023, the inter-modality conversion capability of the model is trained;
* Super Resolution:Using high-resolution brain MRI from the IXI dataset to improve the accuracy of image detail reconstruction;
* Text-image generation:X-ray images and reports based on MIMIC-CXR, realizing the generation from text description to image;
* Image reconstruction:Adapted the LLaVA-558k dataset to train the model's image encoding-decoding capabilities.
During the data processing phase, the team performed standardized preprocessing of medical images, including slice extraction, image registration, and data enhancement.And unify all samples into the "command-response" format,Facilitates instruction following training of the model.
Model architecture: full chain design from visual perception to autoregressive generation
HealthGPT adopts a layered architecture of "visual encoder-LLM core-H-LoRA plug-in" to achieve efficient processing of multimodal information:
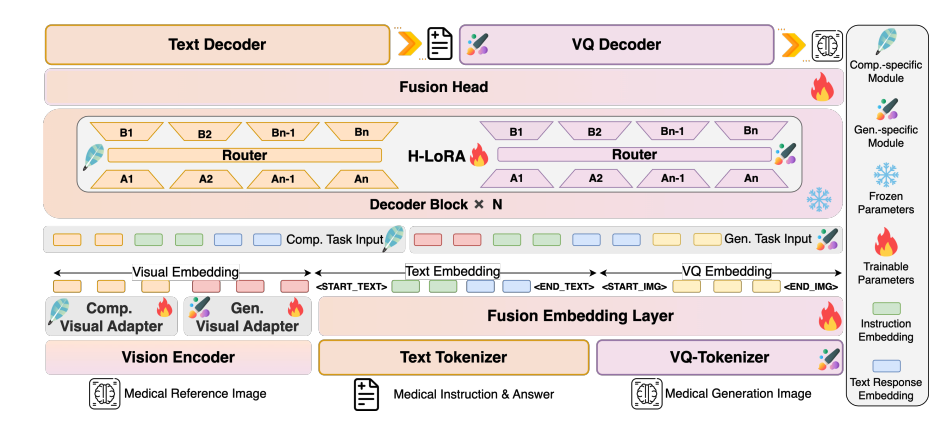
Model architecture diagram
Visual Encoding Layer: Hierarchical Feature Extraction
CLIP-L/14 is used as a visual encoder to extract shallow (2nd layer) and deep (2nd to last layer) features. Shallow features are converted into specific granular features through a 2-layer MLP adapter to preserve image details; deep features are processed into abstract granular features by the adapter to capture semantic concepts. This dual-track feature extraction mechanism provides adaptive visual representation for subsequent understanding and generation tasks.
LLM Core: General Knowledge Base
Based on Phi-3-mini and Phi-4, two models with different parameters are built: HealthGPT-M3 (model parameter volume is 3.8B) and HealthGPT-L14 (model parameter volume is 14B). The LLM core is not only responsible for text understanding and generation, but also uniformly processes visual token sequences through an autoregressive mechanism - outputting text responses for understanding tasks and outputting VQGAN index sequences for generation tasks, and then reconstructing images through the VQGAN decoder.
H-LoRA plugin: mission-specific adapter
Insert the H-LoRA plug-in into each Transformer block of LLM, including two types of sub-modules: understanding and generation. Each sub-module contains multiple LoRA experts, and selective activation of knowledge is achieved through dynamic routing of task types and input hidden states. The plug-in is combined with the frozen weights of LLM to form a hybrid reasoning mode of "general knowledge + task expertise".
Experimental conclusion: HealthGPT is far ahead in medical visual understanding and generation tasks
Understanding the mission: leading in professional capabilities
In the medical visual understanding task, HealthGPT significantly surpasses existing models. By comparing HealthGPT with other medical-specific and general models (such as Med-Flamingo, LLA-VA-Med, HuatuoGPT-Vision, BLIP-2, etc.), the results show thatHealthGPT performs well on medical visual understanding tasks, significantly outperforming other medical-specific and general models.
On the VQA-RAD dataset, HealthGPT-L14 achieved an accuracy of 77.7%, an improvement of 29.1% over LLaVA-Med; in the OmniMedVQA benchmark test, its average score was 74.4%, and it achieved the best results in 6 of the 7 subtasks including CT, MRI, and OCT. In particular, its accuracy in complex MRI modality understanding was as high as 99.7%, demonstrating its deep understanding of highly difficult medical images.
Generation tasks: breakthroughs in modality conversion and super-resolution
The generative task experiment shows that HealthGPT performs well in medical image conversion and enhancement. In the CT-MRI modality conversion task, the SSIM index of HealthGPT-M3 reached 79.38 (Brain CT2MRI), which is 11.6% higher than the traditional method Pix2Pix, and the conversion accuracy in complex areas such as the pelvis is also leading; in the super-resolution task, its SSIM reached 78.19 and PSNR 32.76, surpassing SRGAN, DASR and other dedicated models in detail recovery, especially in the fine reconstruction of brain structures.
It is worth noting thatHealthGPT can handle multiple generation tasks in a single model.The traditional method requires training an independent model for each subtask, which highlights the efficiency advantage of the unified framework.
Method validation: the value of H-LoRA and the three-phase strategy
Ablation experiments confirmed the necessity of the core technology: after removing H-LoRA, the average performance of the understanding and generation tasks decreased by 18.7%; when hybrid training was adopted instead of the three-stage strategy, task conflict caused performance degradation of 23.4%.
The comparison between H-LoRA and MoELoRA shows that when using 4 experts, H-LoRA training time is only 67% of MoELoRA, but the performance is improved by 5.2%, proving its dual advantages in computational efficiency and task performance. The role of layered visual perception has also been verified.The convergence speed is improved by 40% when abstract features are used in the comprehension task, and the image fidelity is improved by 25% when specific features are used in the generation task.
Potential for clinical application: a bridge from research to practice
In the Human Evaluation experiment, five clinicians blindly evaluated the responses to 1,000 open questions.The proportion of HealthGPT-L14 answers selected as "best answers" reached 65.7%,Far exceeding LLaVA-Med (34.08%) and HuatuoGPT-Vision (21.94%).
at present,HyperAI Hyper.aiThe "HealthGPT: AI Medical Assistant" tutorial is now available in the tutorial section.Simply upload medical images to start a consultation conversation comparable to that of professional doctors. Come and experience it!
Tutorial Link:
Demo Run
1. After entering the hyper.ai homepage, select the "Tutorials" page, select "HealthGPT: AI Medical Assistant", and click "Run this tutorial online".

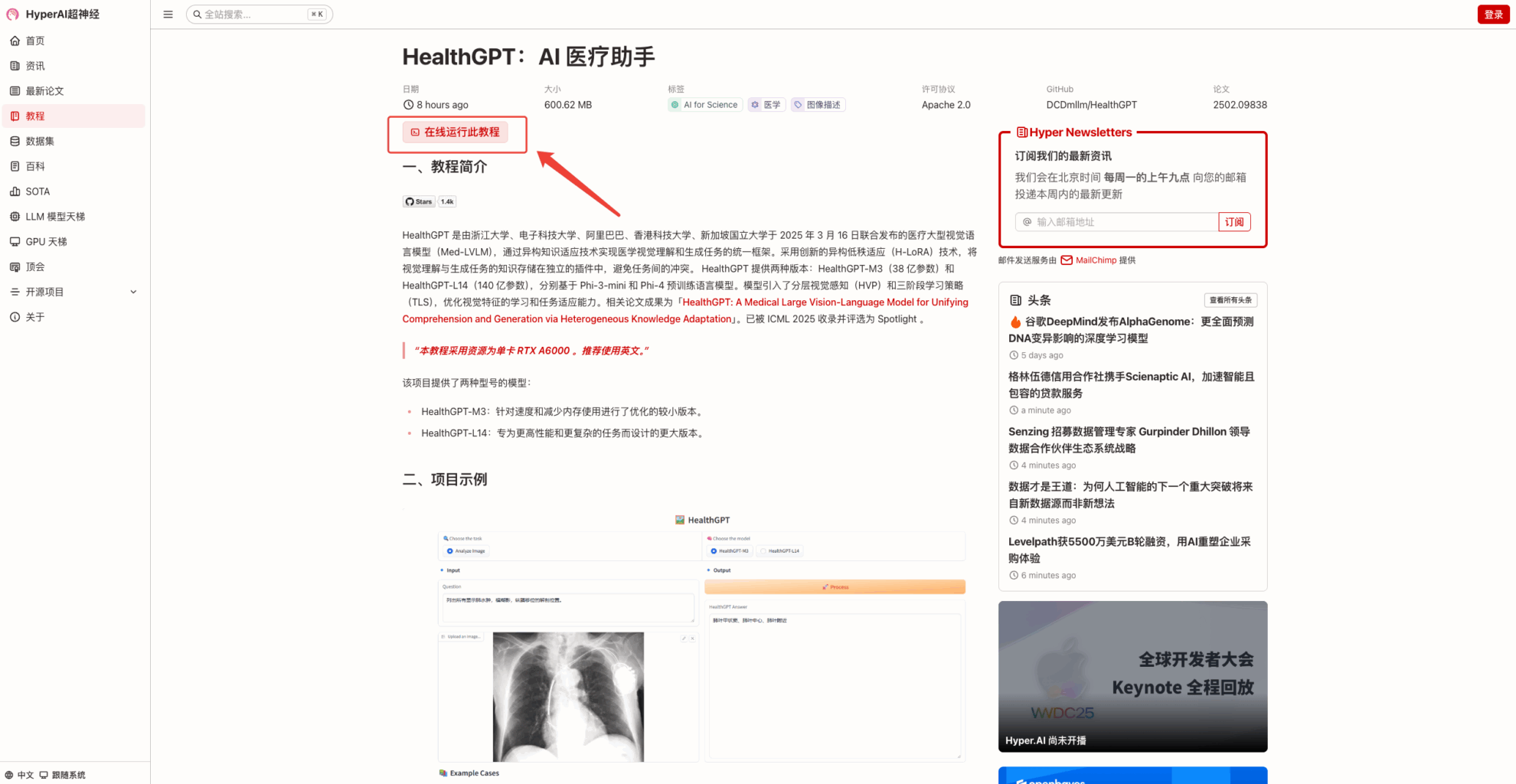
2. After the page jumps, click "Clone" in the upper right corner to clone the tutorial into your own container.
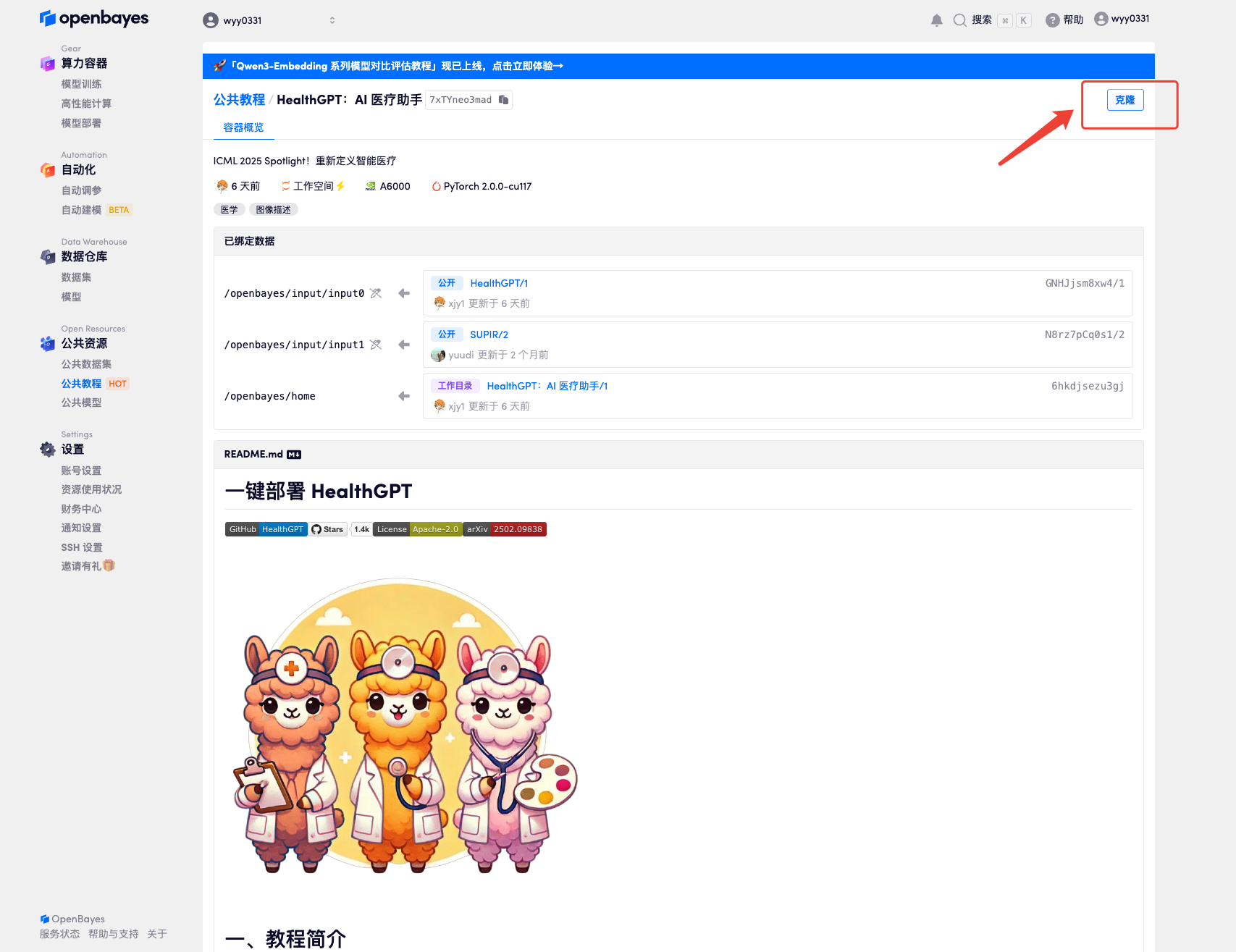
3. Select "NVIDIA RTX A6000" and "PyTorch" images. The OpenBayes platform provides 4 billing methods. You can choose "pay as you go" or "daily/weekly/monthly" according to your needs. Click "Continue". New users can register using the invitation link below to get 4 hours of RTX 4090 + 5 hours of CPU free time!
HyperAI exclusive invitation link (copy and open in browser):
https://openbayes.com/console/signup?r=Ada0322_NR0n
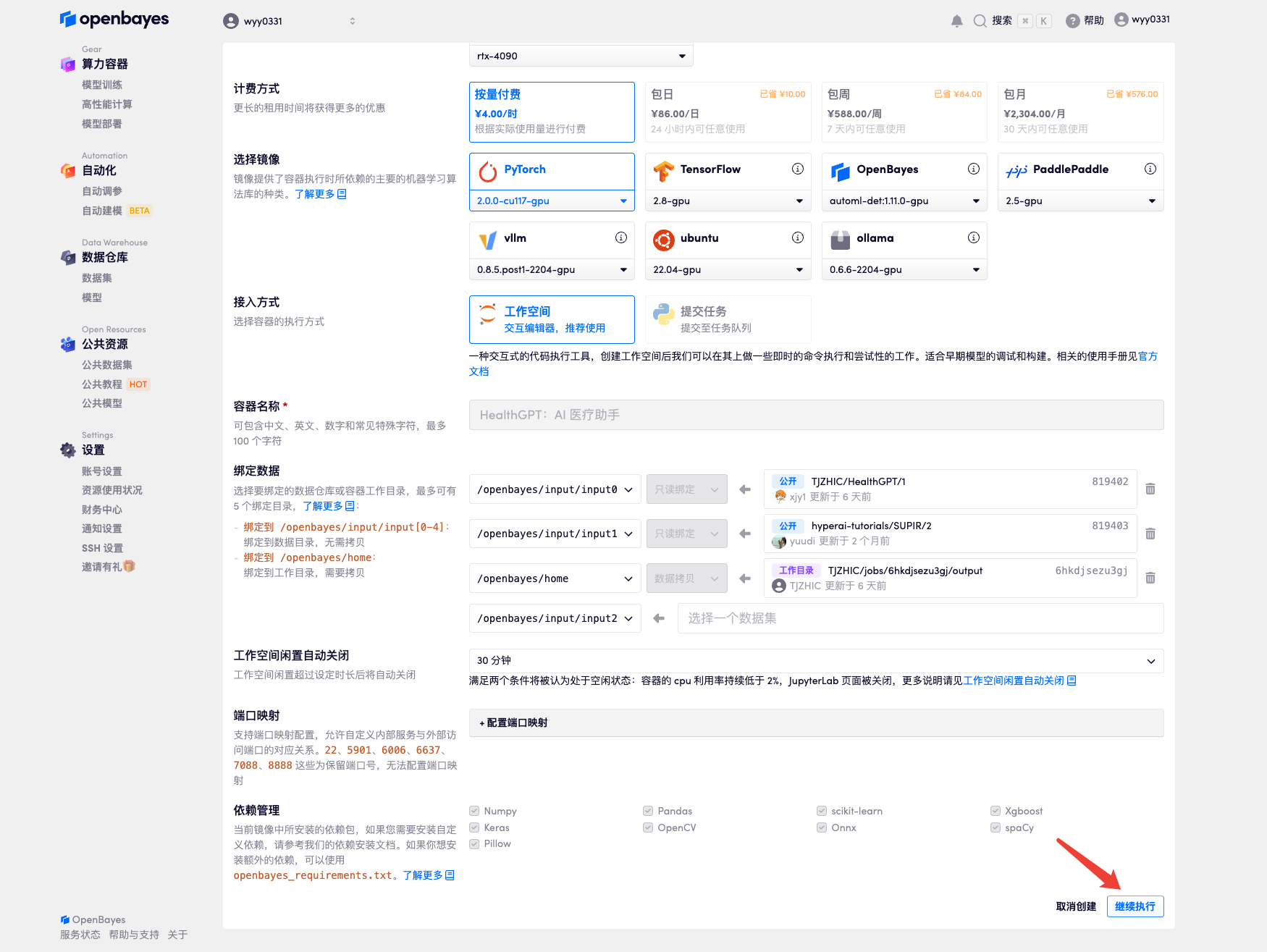
4. Wait for resources to be allocated. The first clone will take about 2 minutes. When the status changes to "Running", click the jump arrow next to "API Address" to jump to the Demo page. Due to the large model, it will take about 3 minutes to display the WebUI interface, otherwise "Bad Gateway" will be displayed. Please note that users must complete real-name authentication before using the API address access function.
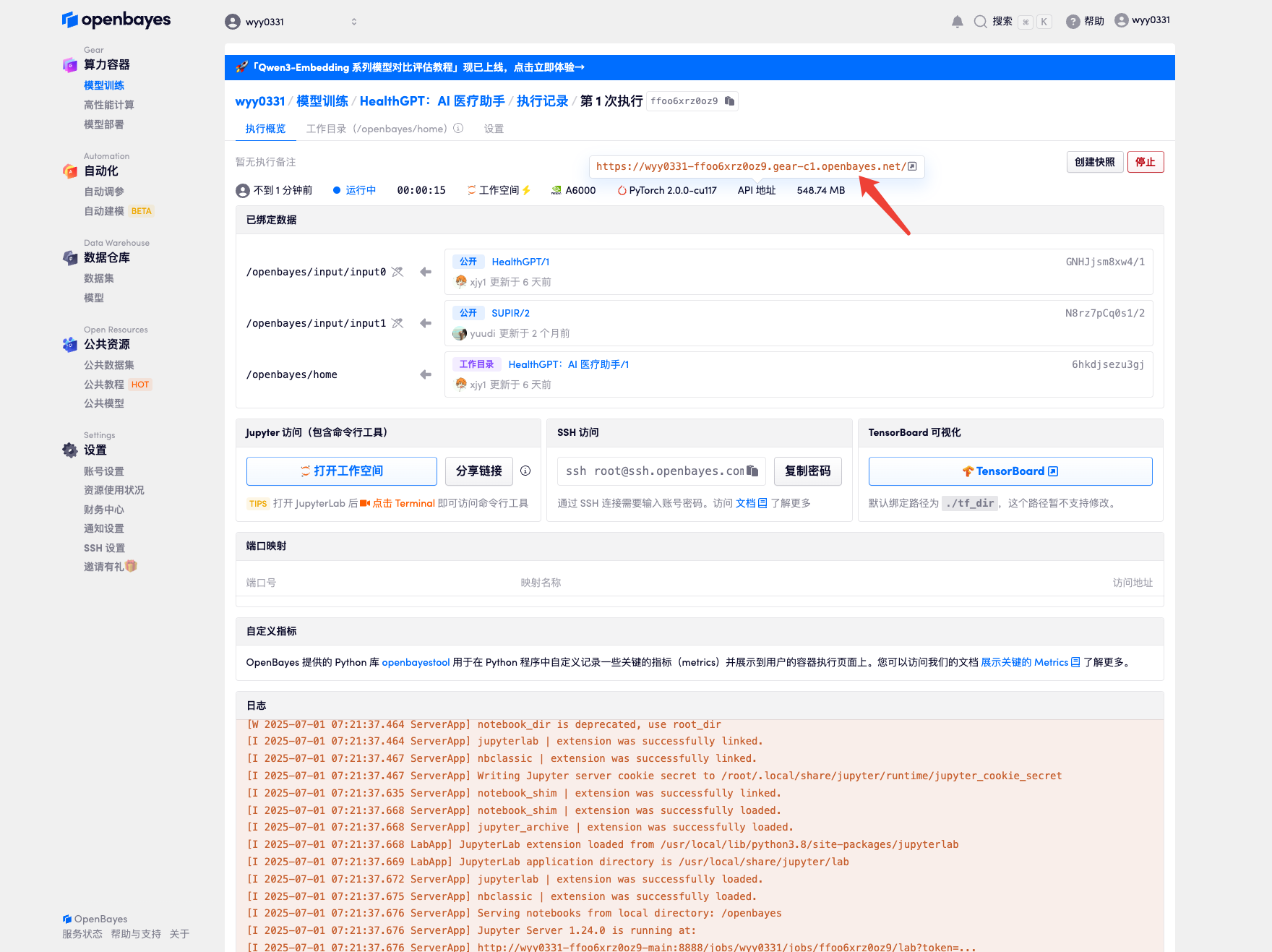
Effect Demonstration
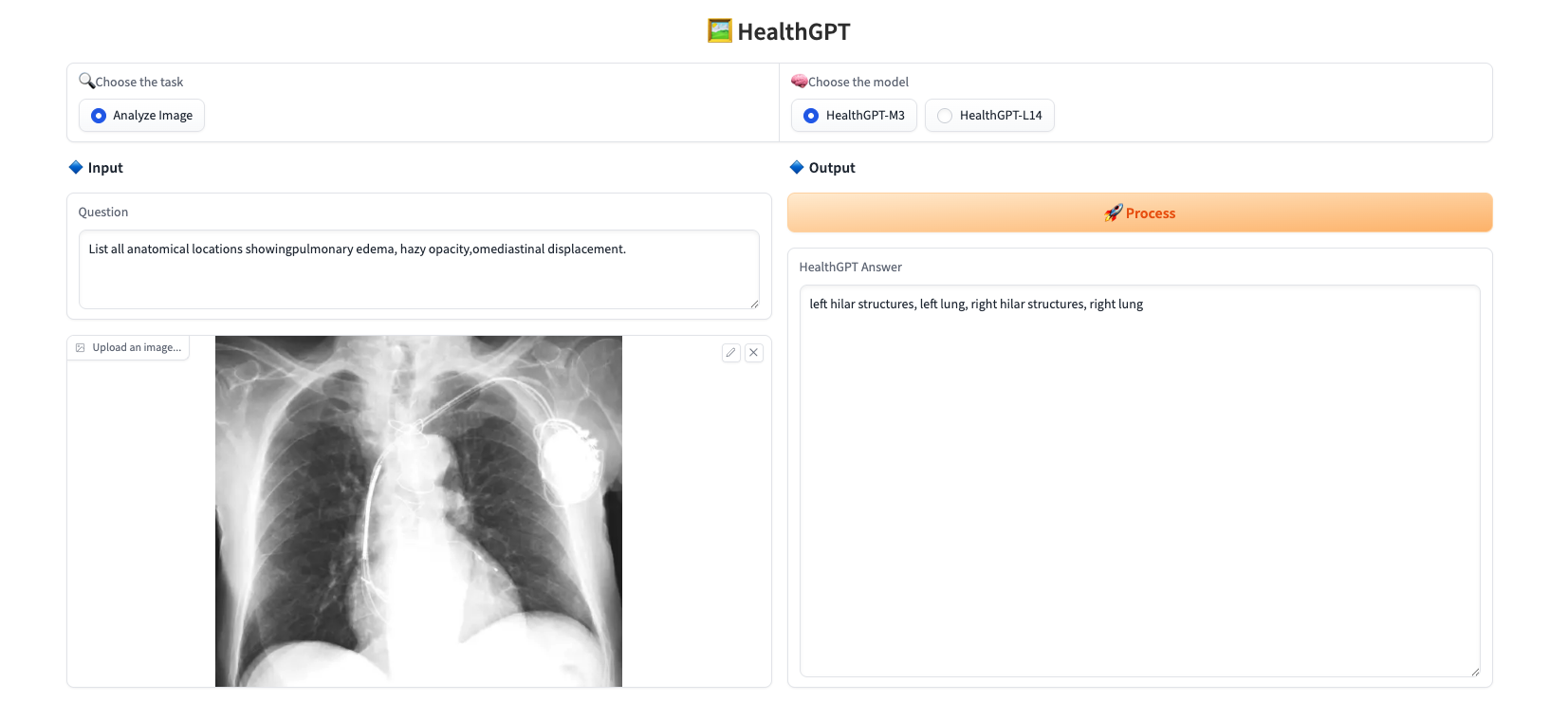
Upload a picture, enter the question you want to ask in "Question", select the model in "Choose the model", and click "Process" to answer it in real time. This project provides two models:
* HealthGPT-M3: A smaller version optimized for speed and reduced memory usage.
* HealthGPT-L14: A larger version designed for higher performance and more complex tasks.
The response example is shown below:
The above is the tutorial recommended by HyperAI. Interested readers are welcome to experience it ⬇️
Tutorial Link:








