Command Palette
Search for a command to run...
58k+ Stars! RAGFlow Integrates Qwen3 Embedding to Easily Process Complex Format Data; Webclick Unlocks a New Dimension of Web Page Understanding
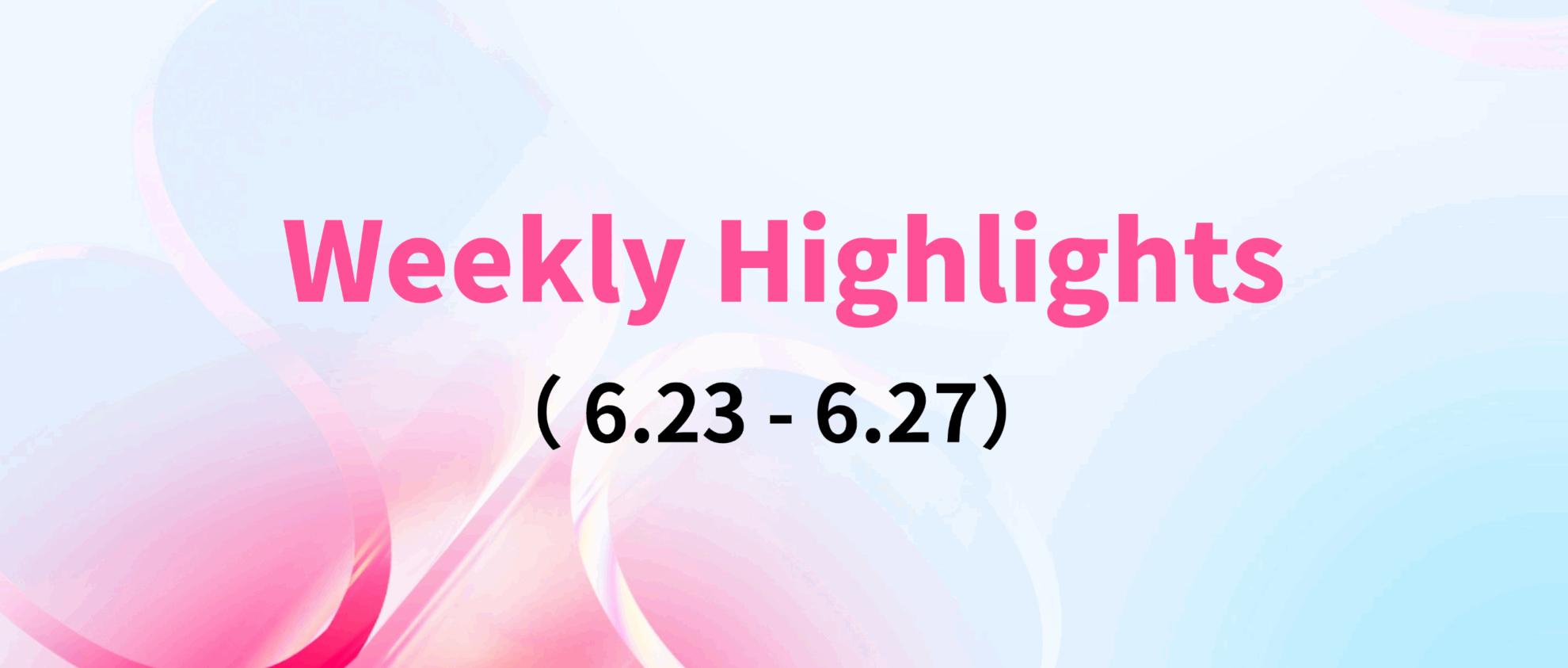
The RAG (Retrieval-Augmented Generation) framework proposed by Meta in 2020 effectively improves the accuracy and reliability of LLM output. The technology has evolved from the initial simple retrieval + generation to an advanced form with agent features such as multi-round reasoning, tool use, and context memory. Most current RAG engines are relatively simple in document parsing and rely on off-the-shelf retrieval middleware, resulting in poor retrieval accuracy.
Based on this, InfiniFlow has open-sourced RAGFlow, an open-source RAG engine based on deep document understanding. It not only solves the above difficulties, but also provides a pre-built RAG workflow. Users only need to follow the process step by step to quickly build a RAG system.After integration with Qwen3 Embedding, it is possible to build a local knowledge base, intelligent question-answering system and Agent in one stop.
At present, the HyperAI official website has launched the "Building a RAG System: Practice Based on Qwen3 Embedding" tutorial, come and try it~
Building a RAG system: Practice based on Qwen3 Embedding
Online use:https://go.hyper.ai/FFA7f
From June 23rd to June 27th, hyper.ai official website updates:
* High-quality public datasets: 10
* High-quality tutorial selection: 6
* This week's recommended papers: 5
* Community article interpretation: 3 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in July: 5
Visit the official website:hyper.ai
Selected public datasets
1. Sekai World Video Dataset
Sekai is a high-quality first-person perspective global video dataset designed to inspire valuable applications in the fields of video generation and world exploration. The dataset focuses on egocentric world exploration and consists of two parts: Sekai-Real and Sekai-Game. It contains more than 5,000 hours of walking or drone perspective videos from more than 100 countries and regions and 750 cities.
Direct use:https://go.hyper.ai/YyBKB
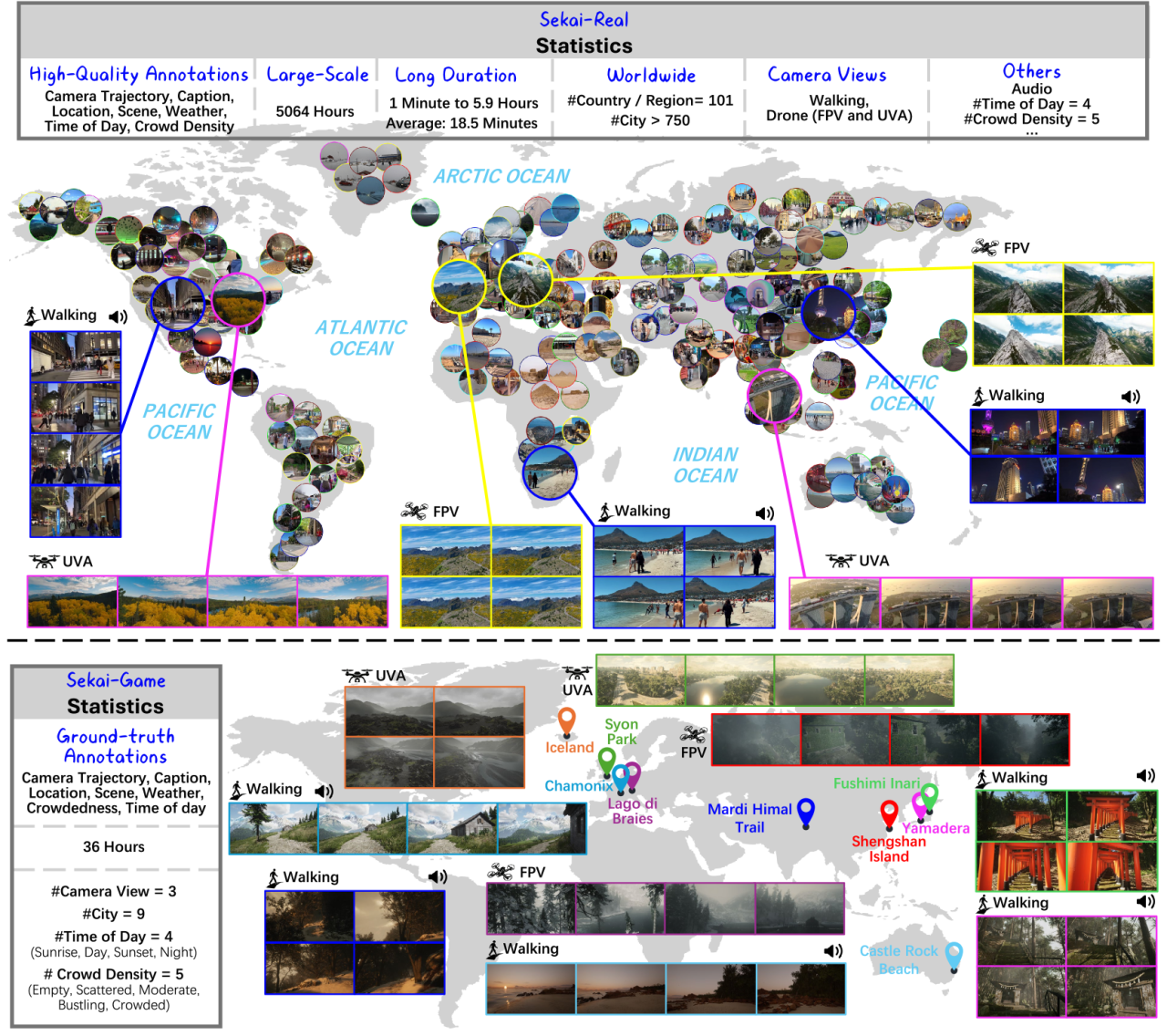
2. Ecomapper Satellite Imagery Dataset
The dataset contains more than 2.9 million satellite images, including RGB images and specific multispectral channel data. The data images are from the Copernicus Sentinel satellite mission, covering a variety of land cover types and multiple time points. The training set has 98,930 different geographic locations and the test set contains 5,494 locations. Each timestamp of each image is accompanied by relevant weather metadata, such as temperature, solar radiation, and precipitation information.
Direct use:https://go.hyper.ai/1u8s6
3. NuScenes Autonomous Driving Dataset
NuScenes is a public dataset for autonomous driving that contains approximately 1.4 million camera images, 390,000 lidar scan images, 1.4 million radar scan images, and 1.4 million object bounding boxes in 40,000 keyframes from Boston and Singapore.
Direct use:https://go.hyper.ai/rgw1k
4. Tahoe-100M single cell dataset
Tahoe‑100M is the world’s largest single-cell dataset, designed to provide a realistic and structured experimental data foundation for large language models (LLMs) with intervention understanding capabilities. The dataset contains more than 100 million cells, covers more than 60,000 molecular intervention experiments, and maps the responses of 50 cancer models to more than 1,100 drug treatments.
Direct use:https://go.hyper.ai/Hfzva
5. WebClick Web Page Understanding Benchmark Dataset
WebClick is a high-quality web page understanding benchmark dataset for evaluating the ability of multimodal models and agents to understand web interfaces, interpret user commands, and take precise actions in digital environments. The dataset contains 1,639 English web page screenshots from more than 100 websites, which are accompanied by accurately annotated natural language commands and pixel-level click targets.
Direct use:https://go.hyper.ai/ezz46
6. DeepResearch Bench Deep Research Bench
DeepResearch Bench is a deep research agent benchmark dataset that aims to reveal the true distribution of human deep research needs in different fields. The dataset contains 100 doctoral-level research tasks, each of which is carefully crafted by experts in 22 different fields.
Direct use:https://go.hyper.ai/yVHfH
7. SA-Text image text dataset
SA-Text is a large-scale benchmark dataset of high-quality scene images designed for text-aware image restoration tasks. The dataset contains 105,330 high-resolution scene images with polygon-level text annotations that accurately describe the location and shape of text in the image, enabling the model to better understand the location and structure of text in the image.
Direct use:https://go.hyper.ai/ICYIY
8. OCRBench text recognition benchmark dataset
The dataset contains 1,000 manually screened and corrected question-answer pairs from five representative text-related tasks: text recognition, scene text center, document orientation, key information, and handwritten mathematical expressions.
Direct use:https://go.hyper.ai/ZcKoD
9. Parse-PBMC single-cell RNA sequencing dataset
Parse-PBMC is an open-source single-cell RNA sequencing dataset that analyzes 10 million cells from 1,152 samples in one experiment, and is mainly used to study the gene expression characteristics of human peripheral blood mononuclear cells under different conditions.
Direct use:https://go.hyper.ai/CwOMc
10. VIRESET Video Instance Editing Dataset
VIRESET aims to provide accurate annotation support for tasks such as video instance redrawing and temporal segmentation. The dataset contains 2 contents, SA-V enhanced mask annotation and 86k video clips.
Direct use:https://go.hyper.ai/5hnGF
Selected Public Tutorials
This week, we have compiled 2 types of high-quality public tutorials:
*Large model deployment tutorials: 3
* Video generation tutorials: 3
Large model deploymentTutorial
1. Building a RAG system: Practice based on Qwen3 Embedding
RAGFlow is an open source RAG (Retrieval Augmented Generation) engine based on deep document understanding. When integrated with LLM, it can provide real question-answering capabilities, supported by reliable references from data in various complex formats.
Run online:https://go.hyper.ai/FFA7f
2. Deploy QwenLong-L1-32B using vLLM+Open WebUI
QwenLong-L1-32B is the first large model for long text reasoning based on reinforcement learning training. It focuses on solving the problems of poor memory and logical confusion that traditional large models encounter when processing ultra-long contexts (such as 120,000 tokens). It breaks through the contextual limitations of traditional large models and provides a low-cost, high-performance solution for high-precision scenarios such as finance and law.
Run online:https://go.hyper.ai/f73C2
3. vLLM+Open WebUI deployment Magistral-Small-2506
Magistral-Small-2506 is built on Mistral Small 3.1 (2503) with increased reasoning capabilities, SFT through Magistral Medium tracking and reinforcement learning on top. It is a small and efficient reasoning model with 24B parameters, capable of long chain reasoning tracking before providing answers to more deeply understand and handle complex problems, thereby improving the accuracy and rationality of answers.
Run online:https://go.hyper.ai/yLeoh
Video Generation Tutorial
1. MAGI-1: The world's first large-scale autoregressive video generation model
Magi-1 is the world's first large-scale autoregressive video generation model that generates videos by autoregressively predicting a series of video blocks, defined as fixed-length segments of consecutive frames. It achieves strong performance on image-to-video tasks conditioned on text instructions, providing high temporal consistency and scalability.
Run online:https://go.hyper.ai/NZ6cc
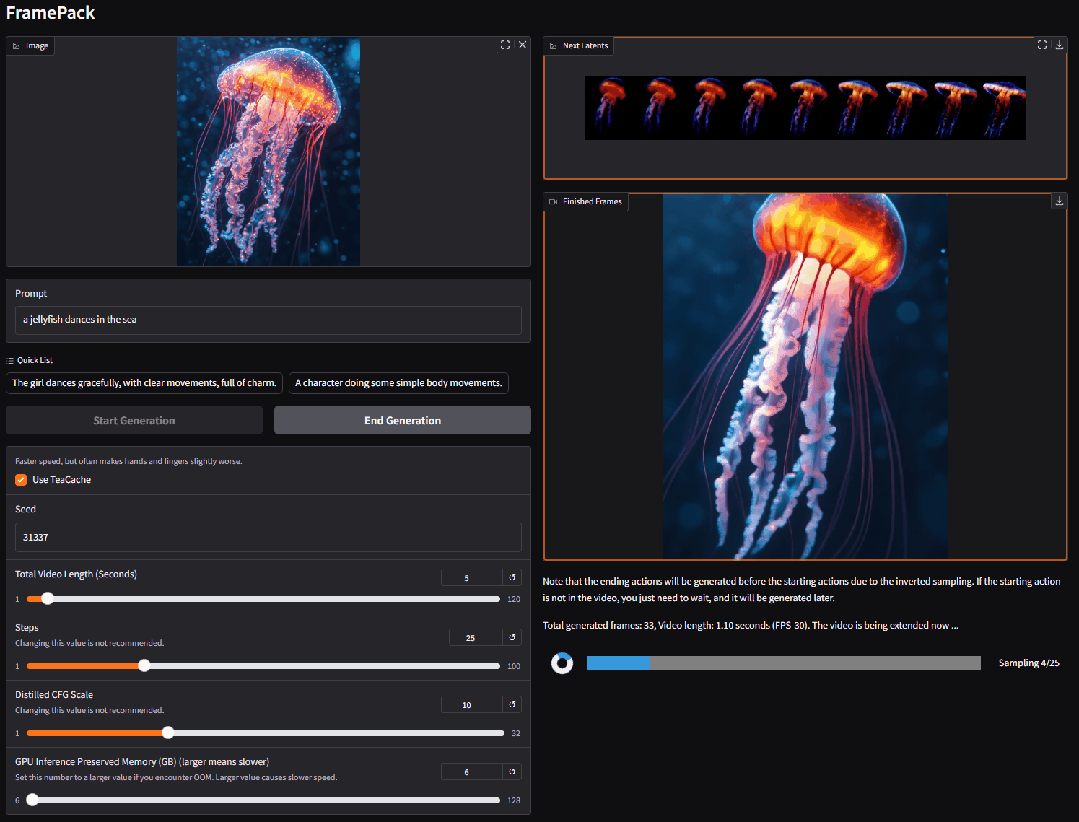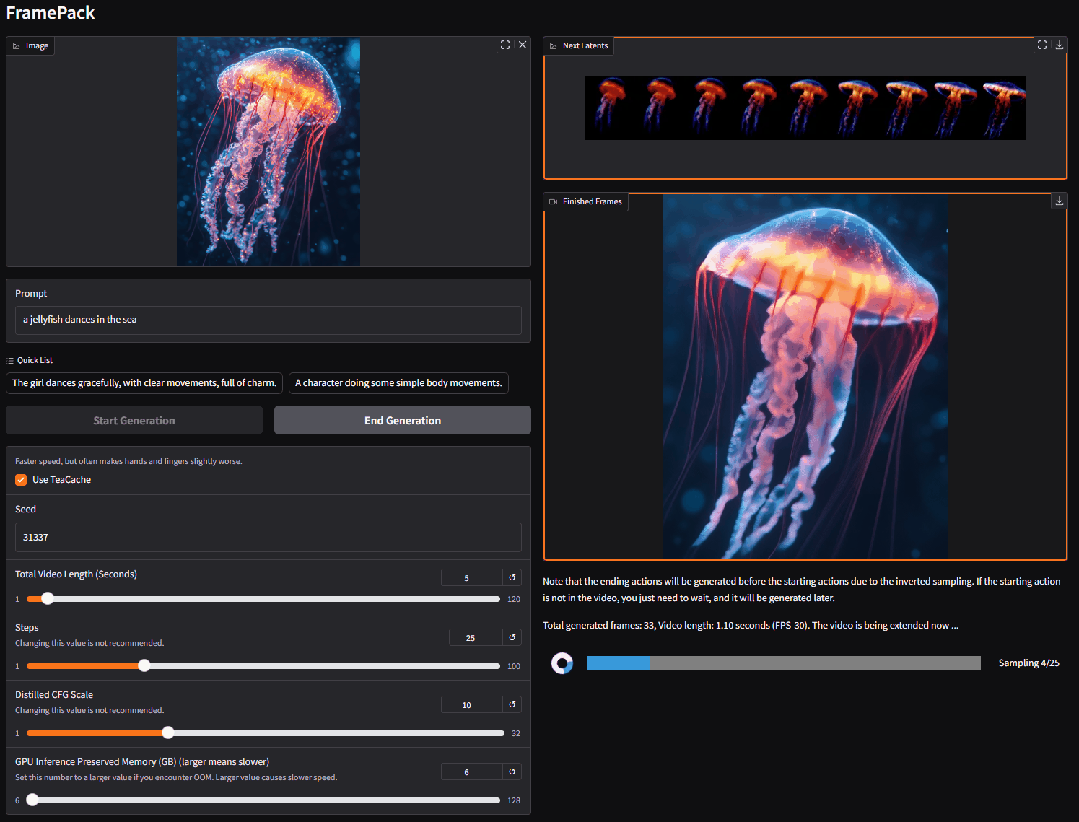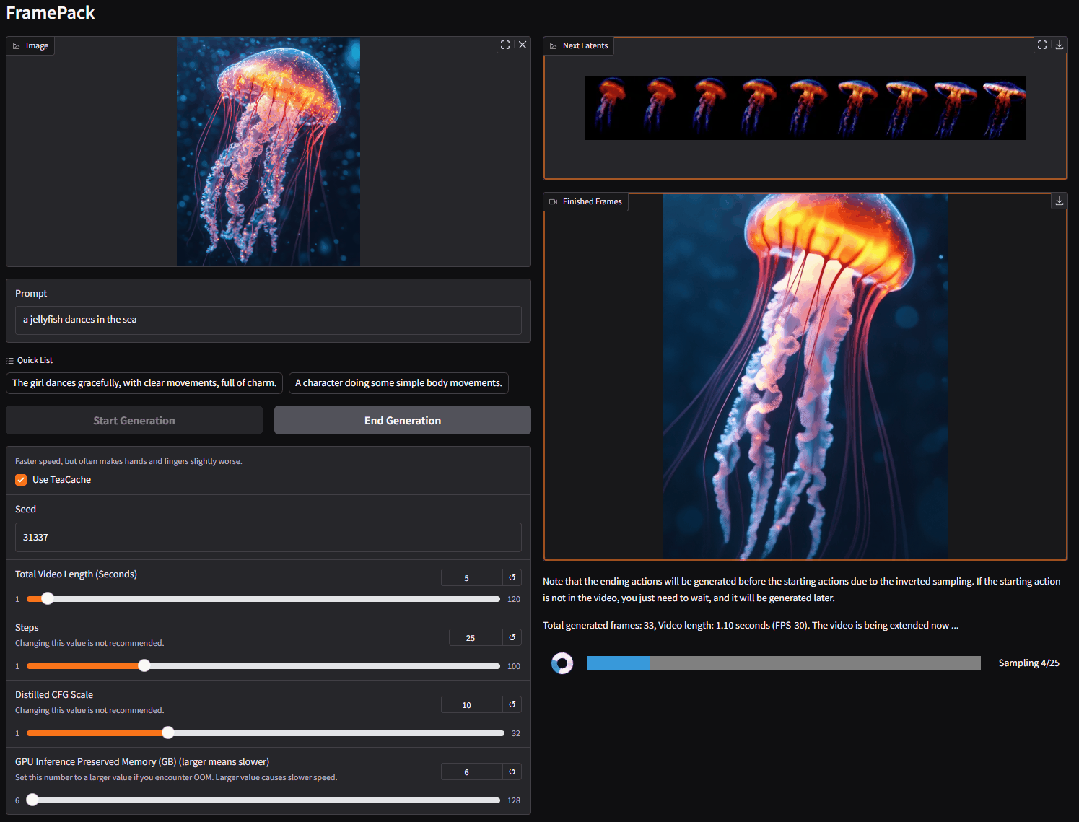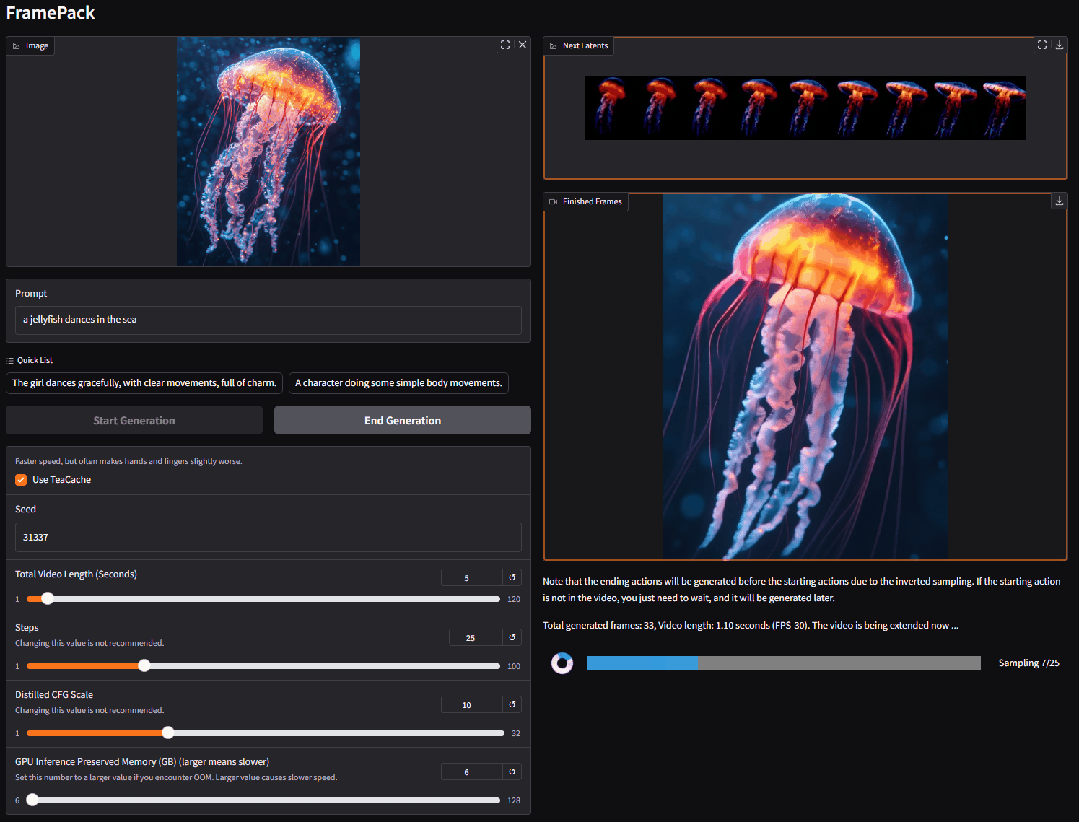
2. FramePackLoop: Open source seamless looping video generation tool
FramePackLoop is an automated frame sequence processing and loop generation tool designed to simplify video production workflows. The tool uses a modular architecture to achieve frame sequence packing, temporal alignment, and seamless loop synthesis. Specifically, it combines optical flow estimation with attention-based temporal modeling to maintain the coherence of inter-frame motion.
Run online:https://go.hyper.ai/WIRoM
3. VIRES: Sketch-and-text dual-guided video redrawing
VIRES is a video instance redrawing method that combines sketches and text guidance, supporting multiple editing operations such as redrawing, replacing, generating, and removing video subjects. This method uses the prior knowledge of text-generated video models to ensure temporal consistency. Experimental results show that VIRES performs well in many aspects, including video quality, temporal consistency, conditional alignment, and user ratings.
Run online:https://go.hyper.ai/GeZxZ

💡We have also established a Stable Diffusion tutorial exchange group. Welcome friends to scan the QR code and remark [SD tutorial] to join the group to discuss various technical issues and share application results~

This week's paper recommendation
1. Drag-and-Drop LLMs: Zero-Shot Prompt-to-Weights
This paper introduces Drag-n-Drop Large Language Models (DnD), a prompt-based parameter generator that eliminates the need for per-task training by directly mapping a small number of unlabeled task prompts to LoRA weight updates. A lightweight text encoder refines each prompt batch into conditional embeddings, which are then converted into a full set of LoRA matrices by a cascaded hyperconvolutional decoder.
Paper link:https://go.hyper.ai/hAO8y
2. Light of Normals: Unified Feature Representation for Universal Photometric Stereo
In this paper, we propose a novel Universal Photometric Stereo (UniPS) method to solve the problem of recovering high-precision surface normals under arbitrary lighting conditions. Experimental results show that LINO-UniPS outperforms existing state-of-the-art Universal Photometric Stereo methods on public benchmarks and shows strong generalization capabilities to cope with different material properties and lighting scenarios.
Paper link:https://go.hyper.ai/oTFMo
3. Vision-Guided Chunking Is All You Need: Enhancing RAG with Multimodal Document Understanding
This paper proposes a novel multimodal document chunking method that leverages Large Multimodal Models (LMMs) to batch process PDF documents while maintaining semantic coherence and structural integrity. The method processes documents in configurable page batches and preserves contextual information across batches, enabling accurate processing of tables, embedded visual elements, and procedural content spanning multiple pages.
Paper link:https://go.hyper.ai/IZA15
4. OmniGen2: Exploration to Advanced Multimodal Generation
This paper introduces OmniGen2, a versatile and open-source generative model that aims to provide a unified solution for multiple generative tasks, including text-to-image generation, image editing, and context generation. Unlike OmniGen v1, OmniGen2 designs two independent decoding paths for text and image modalities, using non-shared parameters and separate image tokenizers. This design enables OmniGen2 to build on existing multimodal understanding models without re-adapting VAE inputs, thus preserving the original text generation capabilities.
Paper link:https://go.hyper.ai/iCFzp
5. PAROAttention: Pattern-Aware ReOrdering for Efficient Sparse and Quantized Attention in Visual Generation Models
This paper proposes a new pattern-aware tag reordering (PARO) technique that unifies diverse attention patterns into hardware-friendly block patterns. This unification significantly simplifies and enhances the effects of sparsification and quantization. In this method, PARO Attention achieves video and image generation with almost no loss of metrics, and achieves almost the same results as the full-precision baseline with significantly reduced density and bit width, achieving 1.9x to 2.7x end-to-end latency acceleration.
Paper link:https://go.hyper.ai/sScNH
More AI frontier papers:https://go.hyper.ai/iSYSZ
Community article interpretation
Google DeepMind released the AlphaGenome model, which can predict thousands of molecular properties related to their regulatory activity, and can also evaluate the impact of gene variation or mutation by comparing the prediction results of variant and non-variant sequences. One of the important breakthroughs of AlphaGenome is the ability to predict splicing junctions directly from sequences and use them for variant effect prediction.
View the full report:https://go.hyper.ai/o8E1F
Professor Li Dong, Director of the Medical Data Science Center of Tsinghua Chang Gung Hospital, gave a special presentation on "How to use medical data to conduct innovative research in the era of smart healthcare" at the 2025 Beijing Zhiyuan Conference, introducing the innovations brought about by big models in the era of smart healthcare.
View the full report:https://go.hyper.ai/rAabv
The non-profit research organization Arc Institute, in collaboration with research teams from UC Berkeley, Stanford and other universities, launched the virtual cell model STATE, which can predict the response of stem cells, cancer cells and immune cells to drugs, cytokines or genetic interventions. Experimental results show that State significantly outperforms current mainstream methods in predicting transcriptome changes after intervention.
View the full report:https://go.hyper.ai/B3Rc6
Popular Encyclopedia Articles
1. DALL-E
2. Reciprocal sorting fusion RRF
3. Pareto Front
4. Large-scale Multi-task Language Understanding (MMLU)
5. Contrastive Learning
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
July deadline for the top conference
July 2 7:59:59 VLDB 2026
July 11 7:59:59 POPL 2026
July 15 7:59:59 SODA 2026
July 18 7:59:59 SIGMOD 2026
July 19 7:59:59 ICSE 2026
One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!








