Command Palette
Search for a command to run...
With 2.6k Stars, MonkeyOCR-3B Surpasses 72B Model in English Document Parsing Task and Reaches SOTA Performance

Today, OCR (Optical Character Recognition) technology is no longer limited to text recognition, but is gradually evolving into a more complex document parsing system. From the initial simple character extraction to the multimodal large model that has emerged in recent years,OCR has been integrated into tasks such as layout understanding, semantic recognition and structure restoration, and has been widely used in document recognition, subtitle recognition, logistics sorting, literature retrieval and other fields.The rich application scenarios also place more stringent requirements on the model.
For example, most traditional OCR models adopt a modular design, which requires document parsing to be decomposed into multiple fine-grained subtasks, which is inefficient and difficult to optimize uniformly. Although the end-to-end large model is powerful, it has extremely high resource requirements and is difficult to implement universally. Complex documents composed of multiple elements such as text, tables, mathematical expressions, and embedded graphics are still a "hard injury" to accuracy...
In view of this,Huazhong University of Science and Technology and Kingsoft Office jointly launched a document parsing model called MonkeyOCR.It can efficiently convert unstructured document content into structured information. Under the SRR paradigm, document parsing is abstracted into three basic questions: where (structure), what (recognition), and how to organize (relation), which correspond to layout analysis, content recognition, and logical sorting, respectively. This clear task decomposition achieves a balance between accuracy and speed.Supports efficient and scalable processing without compromising accuracy.
In order to provide sufficient data support for the model, the research team constructed a dataset called MonkeyDoc.This is the most comprehensive document parsing dataset to date, containing 3.9 million instances and covering a variety of document types (such as notes, PPTs, magazines, test papers, etc.).At the same time, various structural blocks (tables, images, texts, formulas, etc.) are also marked in detail.
According to the experimental results of the research team, MonkeyOCR performs well when processing complex documents, such as those containing formulas and tables.The performance on formula and table parsing tasks improved by 15.0% and 8.6% respectively.It also far exceeds other models in terms of multi-page document processing speed, reaching 0.84 pages per second.
It is worth mentioning that in the English document parsing task, its 3B parameter model surpasses the mainstream 72B model, and the average performance reaches the SOTA level. Today, MonkeyOCR is still less than a month old, and its GitHub stars have reached 2.6k.
"MonkeyOCR: Document Parsing Based on the Structure-Recognition-Relation Triple Paradigm" has been launched on the "Tutorial" section of HyperAI Super Neural Official Website (hyper.ai), come and experience it⬇️
Tutorial Link:
Demo Run
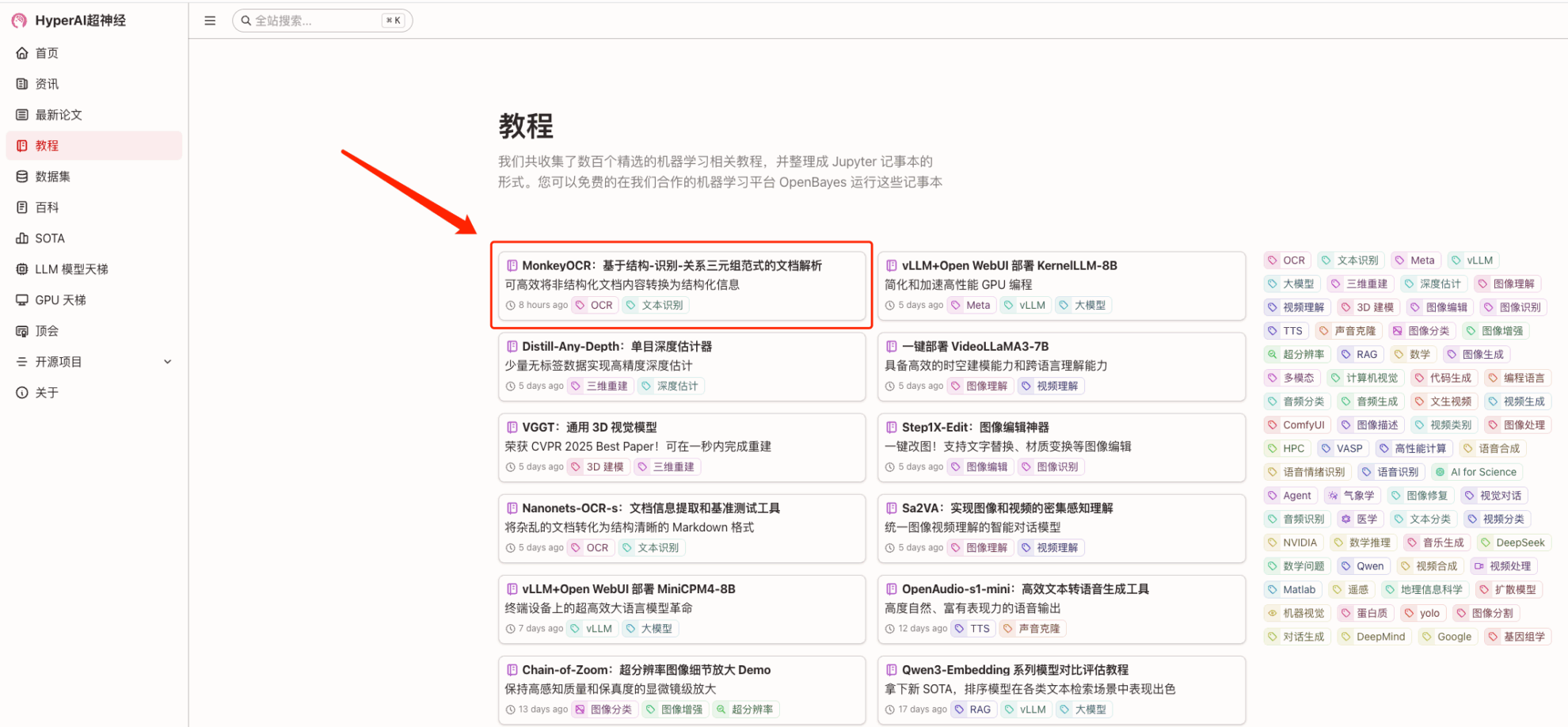
1. After entering the hyper.ai homepage, select the "Tutorial" page, select "MonkeyOCR: Document Parsing Based on the Structure-Recognition-Relation Triple Paradigm", and click "Run this tutorial online".
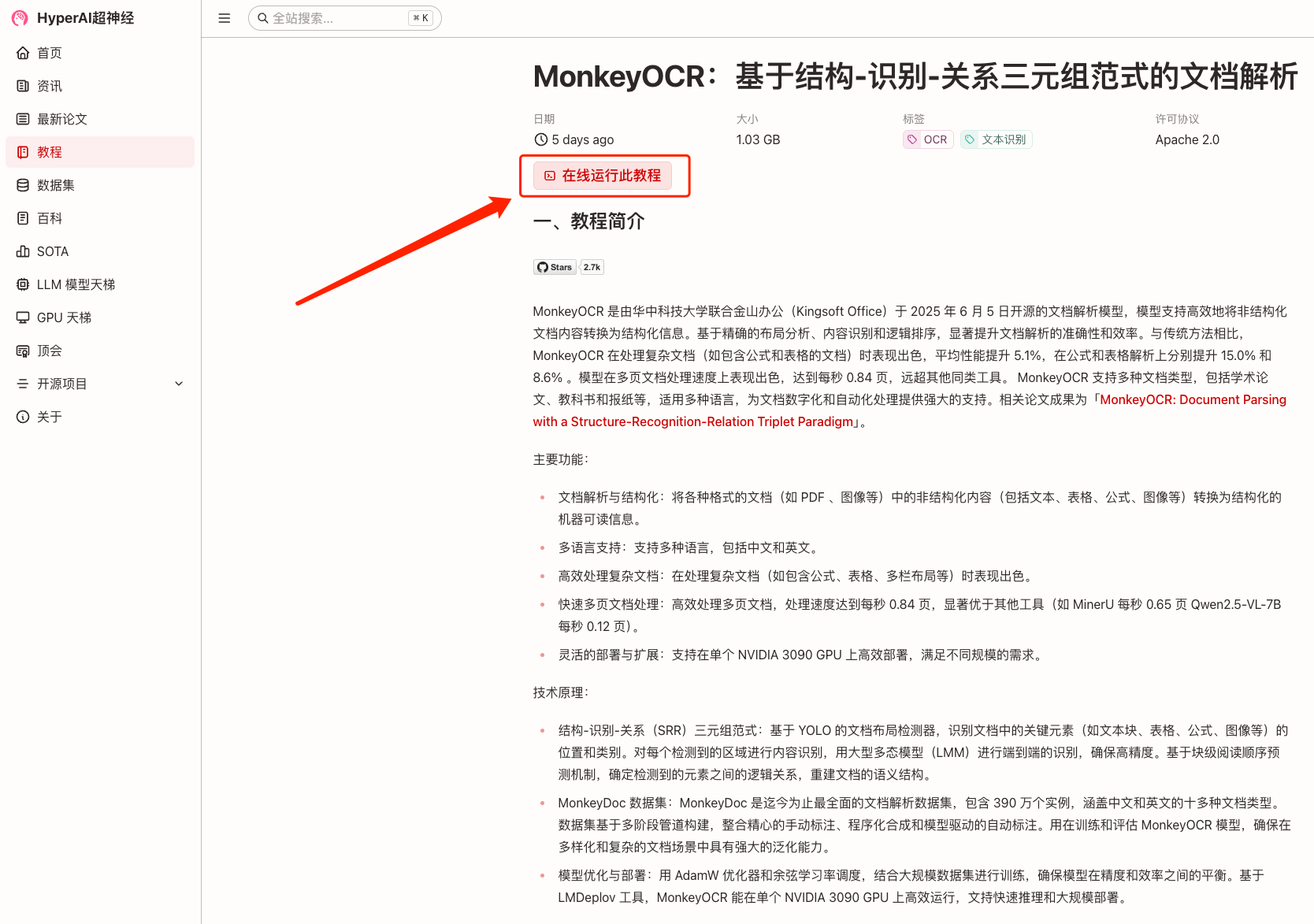
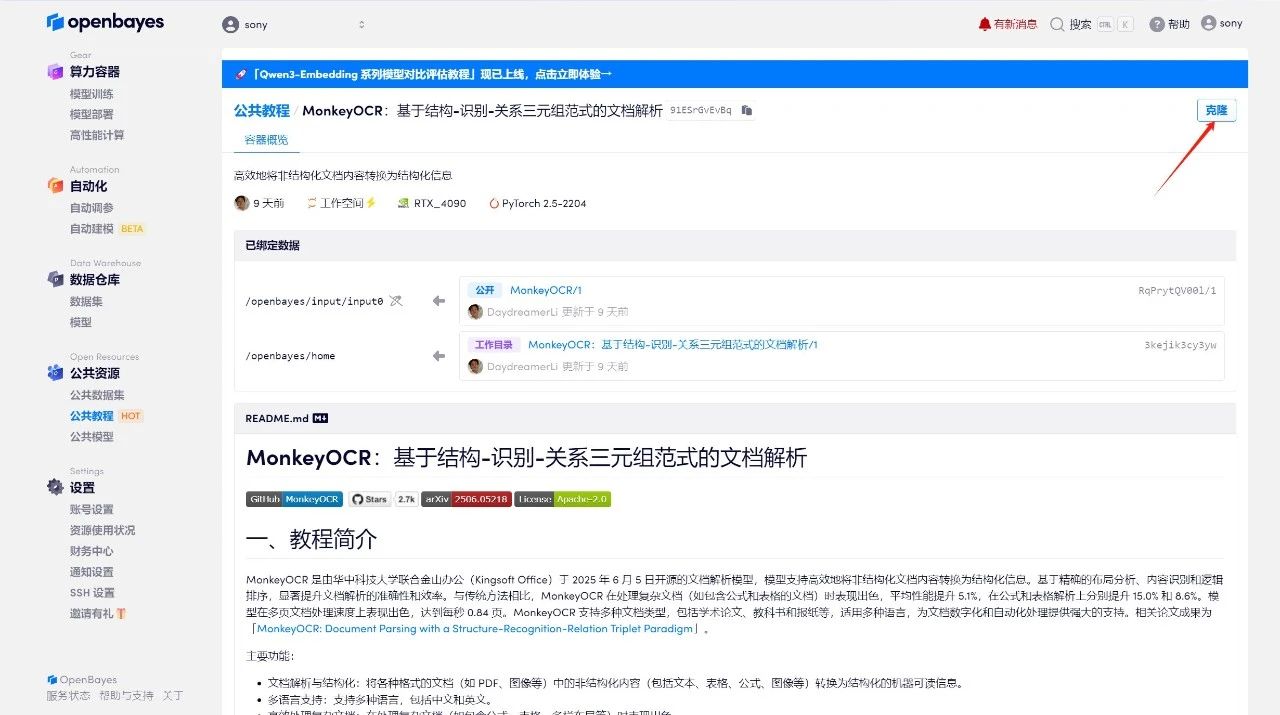
2. After the page jumps, click "Clone" in the upper right corner to clone the tutorial into your own container.
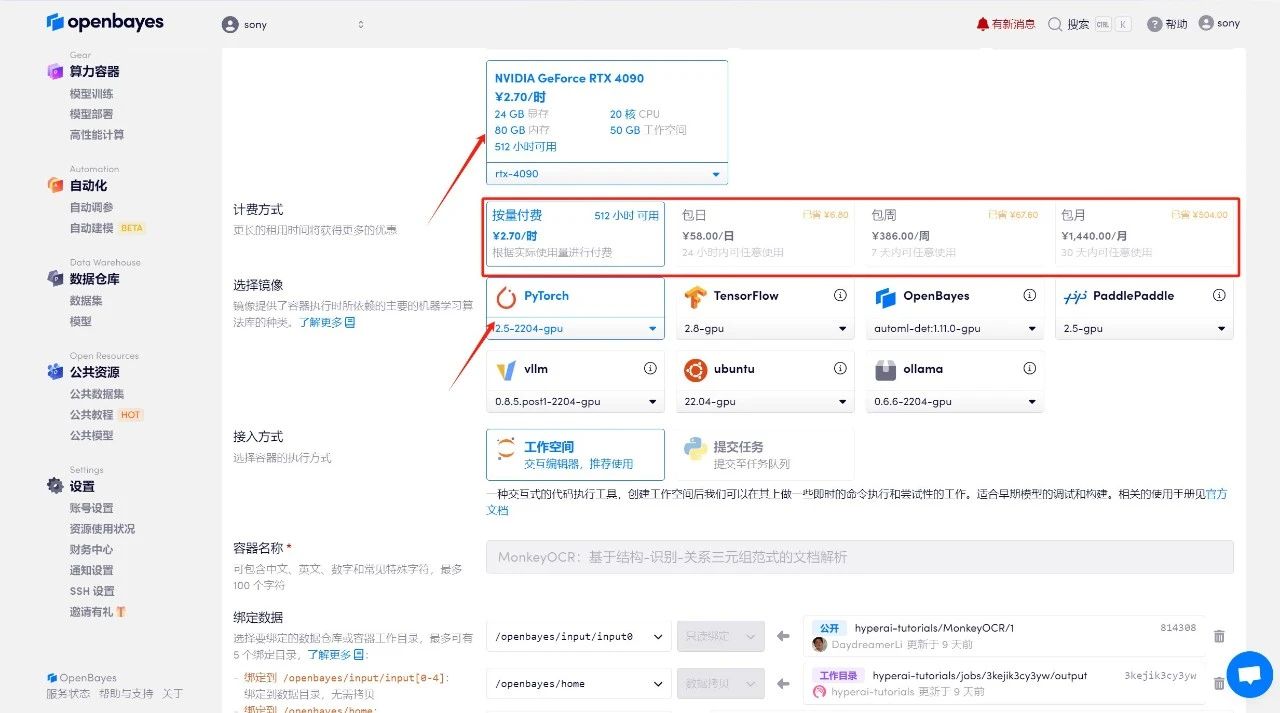
3. Select "NVIDIA GeForce RTX 4090" and "PyTorch" images. The OpenBayes platform provides 4 billing methods. You can choose "Pay as you go" or "Pay per day/week/month" according to your needs. Click "Continue". New users can register using the invitation link below to get 4 hours of RTX 4090 + 5 hours of CPU free time!
HyperAI exclusive invitation link (copy and open in browser):
https://openbayes.com/console/signup?r=Ada0322_NR0n
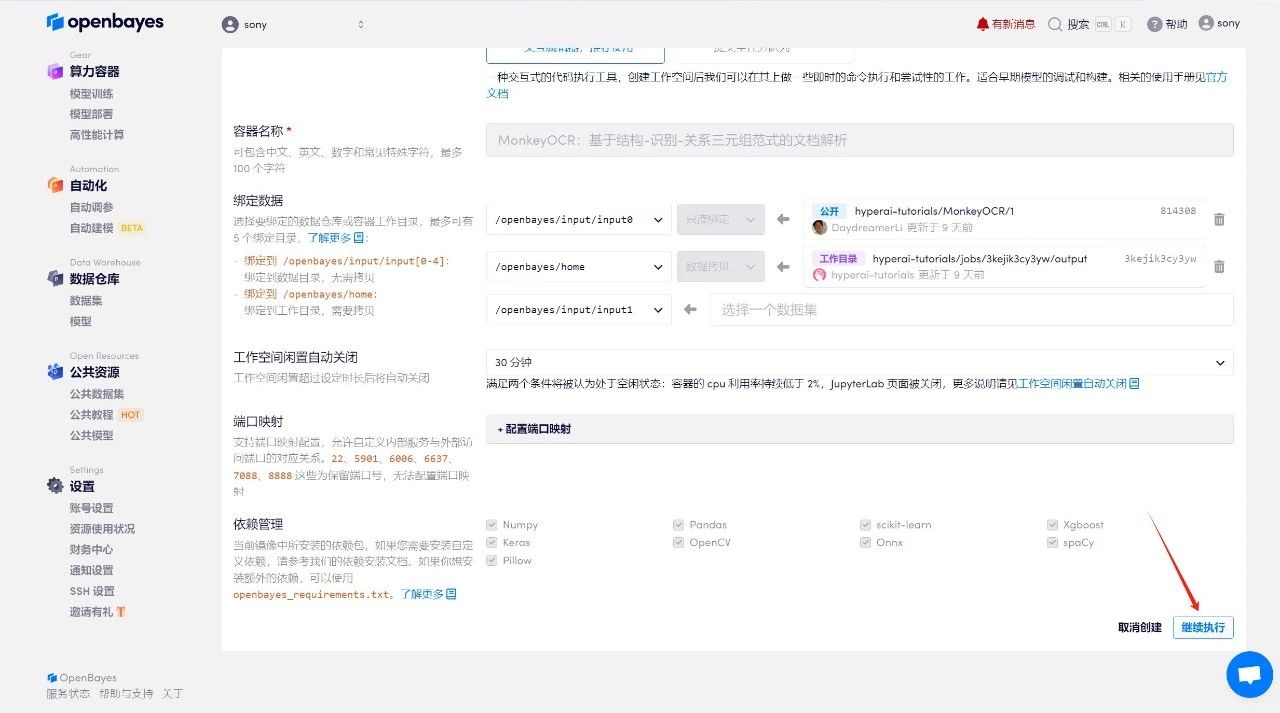
4. Wait for resources to be allocated. The first clone will take about 2 minutes. When the status changes to "Running", click the jump arrow next to "API Address" to jump to the Demo page. Please note that users must complete real-name authentication before using the API address access function.
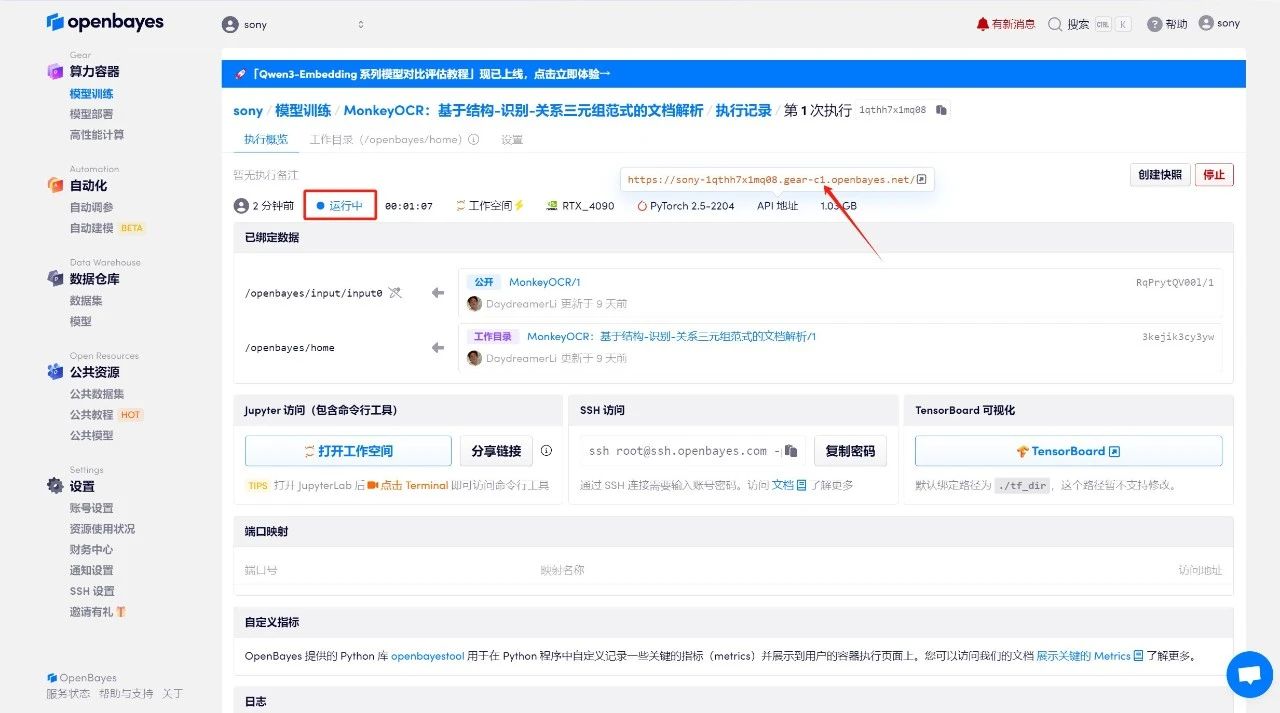
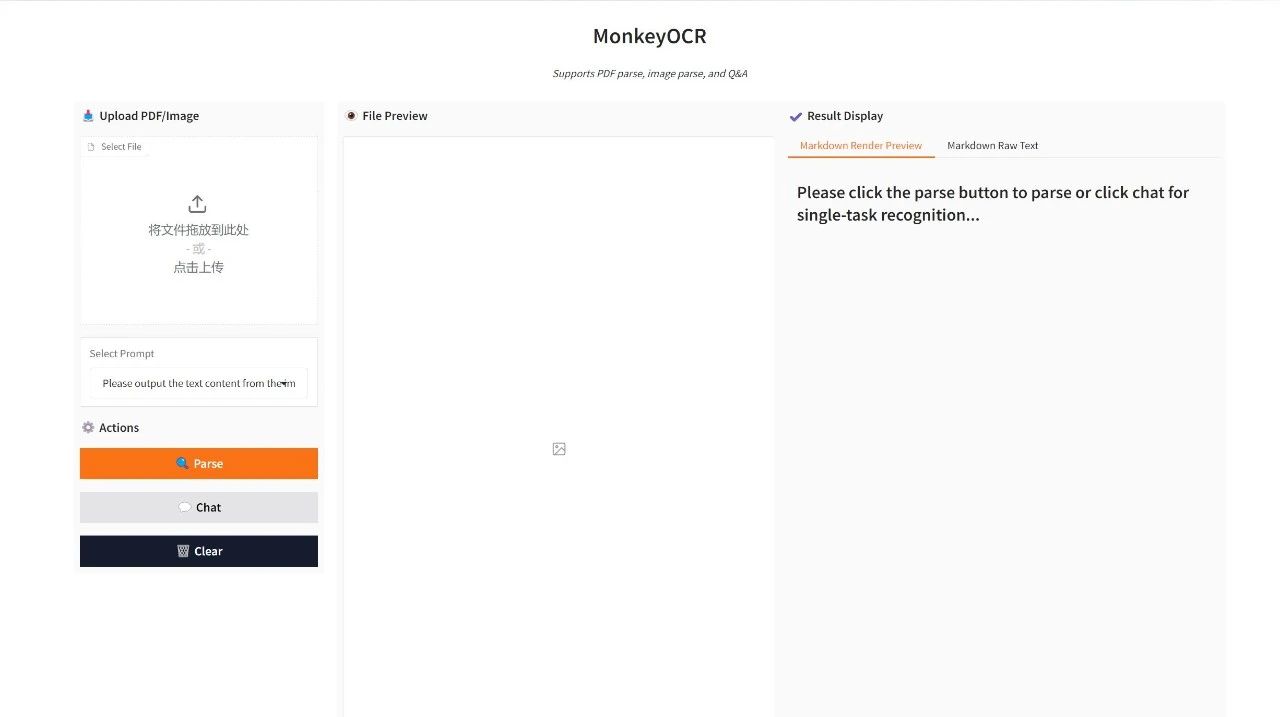
Effect Demonstration
Upload a PDF or image and click "Parse" to parse it. If you choose "Chat" mode, you need to select Prompt in "Select Prompt".
The output results will be displayed in "Result Display". Click "Download PDF Layout/Download Markdown" to download the PDF/Markdown format document to your local computer.
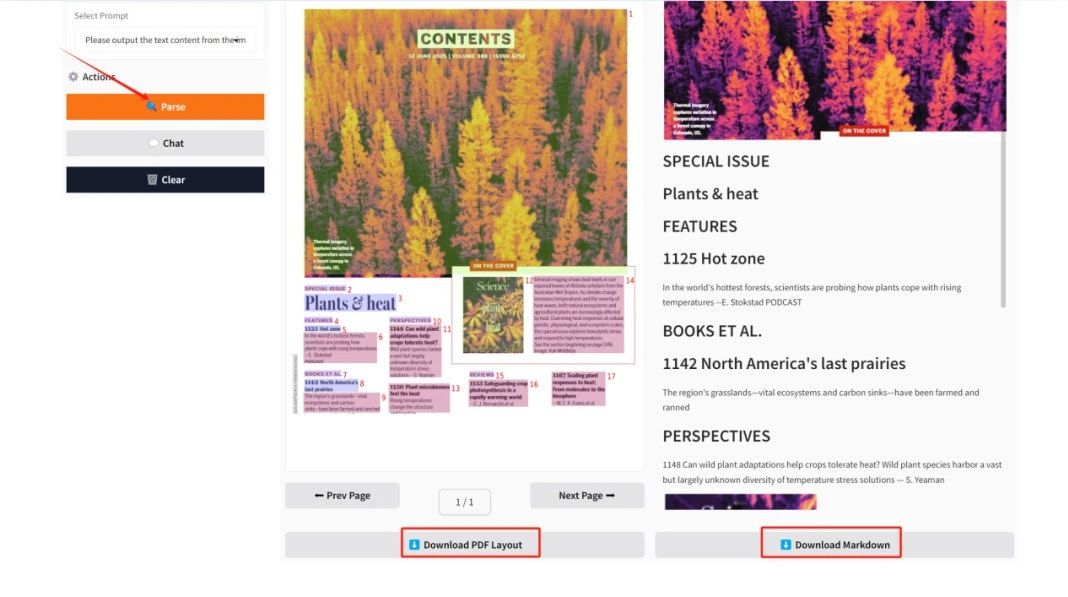

The above is the recommended tutorial for this issue. Welcome everyone to experience it ⬇️
Tutorial Link:








