Command Palette
Search for a command to run...
Costs Are Greatly Reduced! Distill-Any-Depth Achieves high-precision Depth Estimation; Selected for CVPR 2025! Real-IADD Unlocks New Heights in Industrial Detection

Monocular metric depth estimation is a computer vision technique that aims to predict absolute depth from a single RGB image. This technique has a wide range of applications in areas such as autonomous driving, augmented reality, robotics, and 3D scene understanding.
Zero-shot monocular depth estimation (MDE) significantly improves generalization capabilities by unifying depth distribution and leveraging large-scale unlabeled data. However, existing methods treat all depth values uniformly, which may amplify noise in pseudo-labels and reduce the distillation effect. Based on this, Zhejiang University of Technology and several other universities released Distill-Any-Depth.
Distill-Any-Depth integrates the advantages of multiple open source models through the distillation algorithm and achieves high-precision depth estimation with only a small amount of unlabeled data.Compared with traditional methods that require millions of annotations, this project only requires 20,000 unlabeled images, greatly reducing data annotation costs.
At present, HyperAI has launched the "Distill-Any-Depth: Monocular Depth Estimator" tutorial. Come and try it~
Distill-Any-Depth: Monocular Depth Estimator
Online use:https://go.hyper.ai/DNSf5
From June 16 to June 20, hyper.ai official website updates:
* High-quality public datasets: 10
* High-quality tutorials: 14
* This week's recommended papers: 5
* Community article interpretation: 5 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in July: 5
Visit the official website:hyper.ai
Selected public datasets
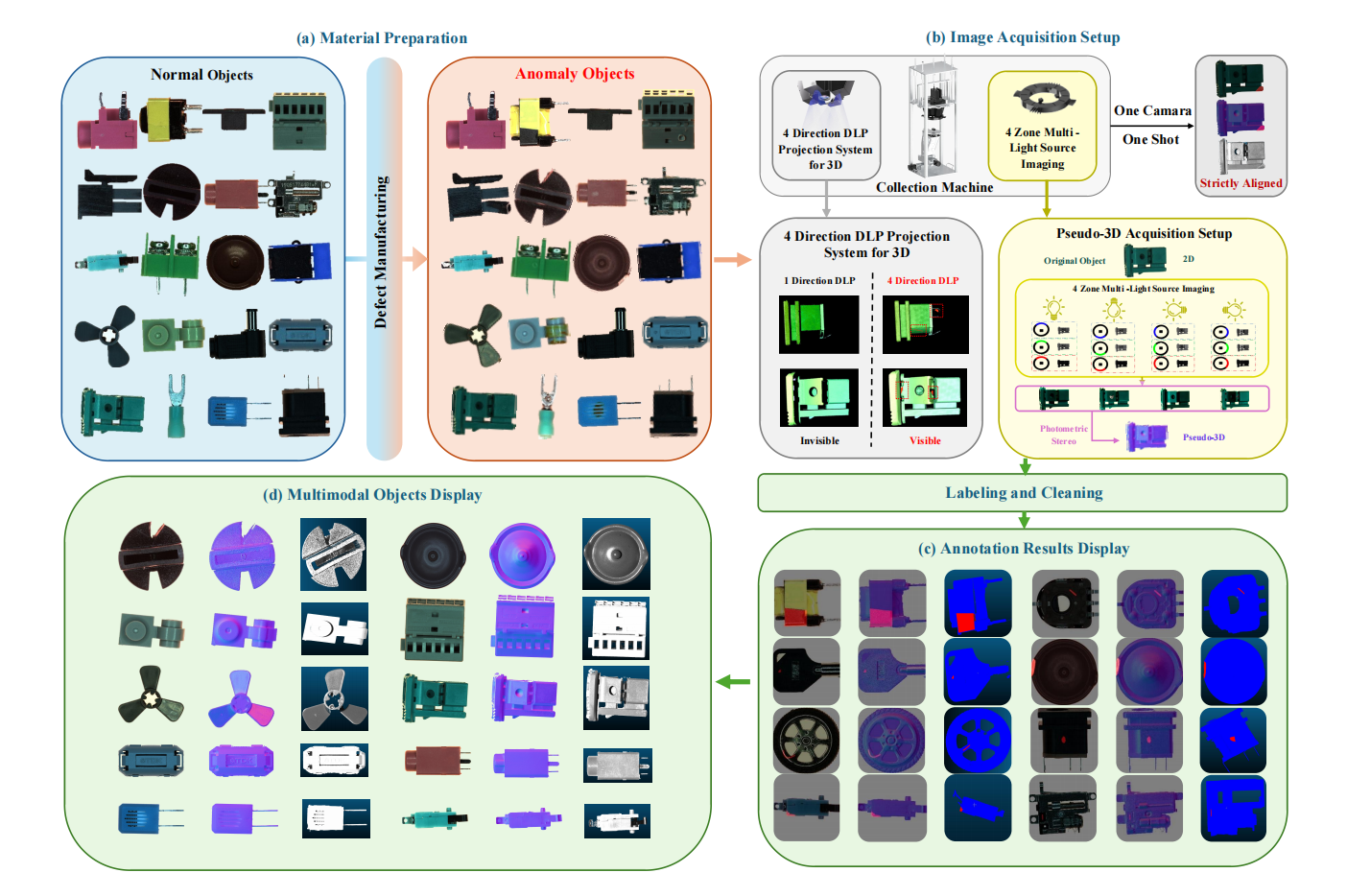
1. Real-IAD D³ Industrial Anomaly Detection Dataset
Real-IAD D³ is a high-precision multimodal dataset, and related papers have been included in the top computer vision conference CVPR 2025. The dataset contains 20 industrial product categories, 69 defect types, and a total of 8,450 samples, including 5,000 normal samples and 3,450 abnormal samples.
Direct use:https://go.hyper.ai/i4T8m
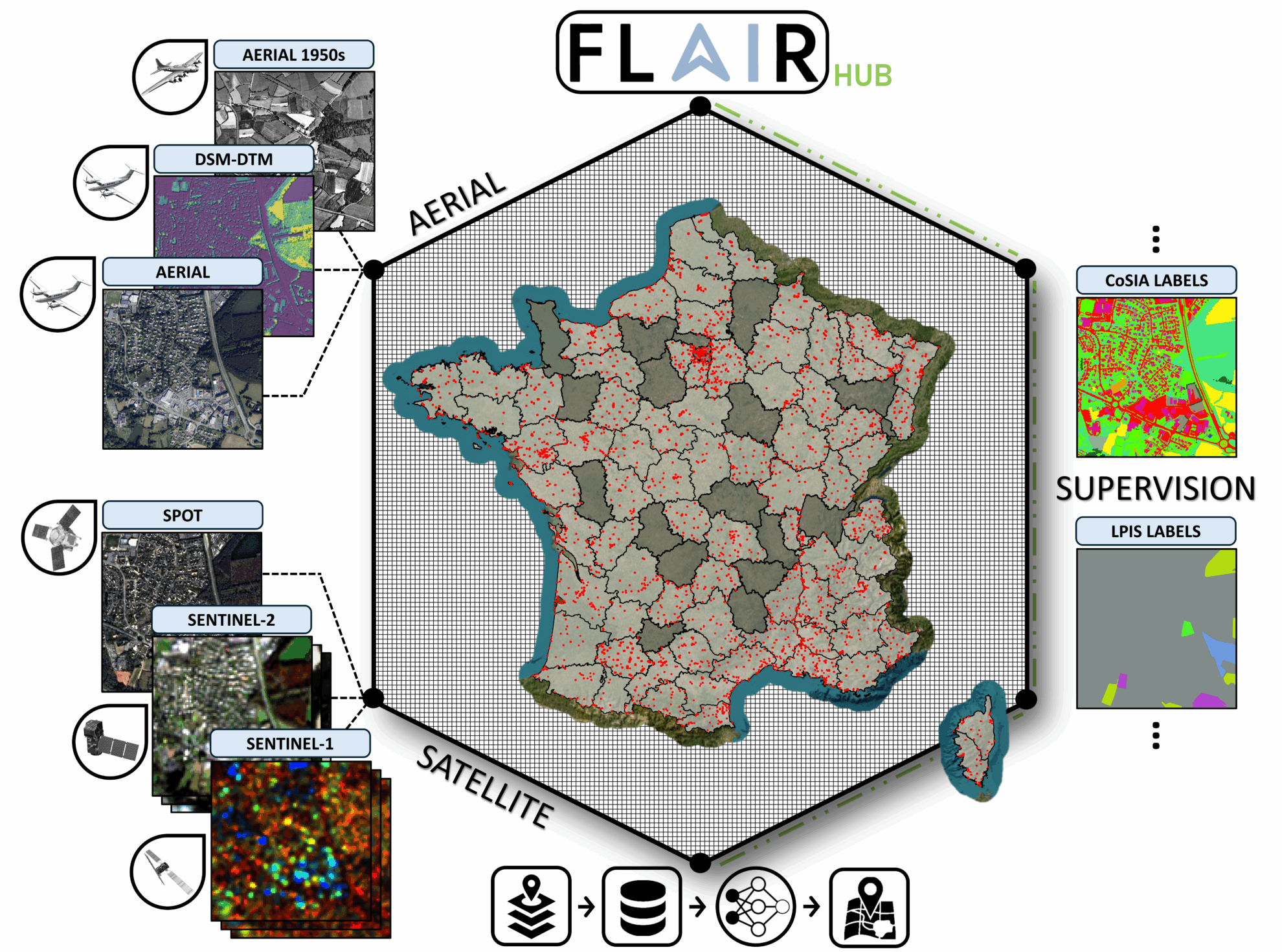
2. FLAIR HUB Multi-sensor French land dataset
FLAIR-HUB covers more than 2,500 km2 of France's diverse eco-climates and landscapes, encompassing 19 land cover classes and 23 crop categories, and contains 63 billion manually annotated pixels, while integrating complementary data sources.
Direct use:https://go.hyper.ai/4VvCI
3. MathFusionQA Mathematical Reasoning Dataset
MathFusionQA focuses on multi-step reasoning and solving of mathematical problems. The data set contains 59,000 high-quality mathematical question-answering samples, covering a variety of question types such as arithmetic operations, algebraic equations, geometric applications, logical reasoning, etc. The question scenarios are rich, covering daily applications, academic training, etc., aiming to improve the mathematical problem-solving ability of the large language model (LLM).
Direct use:https://go.hyper.ai/uGR9C
4. Institutional Books 1.0 Book Dataset
Institutional Books consists of 983,004 public domain books in 254 languages, mainly published in the 19th and 20th centuries. The dataset has 242 billion tokens, 386 million pages of text, and is available in both raw and post-processed OCR export formats.
Direct use:https://go.hyper.ai/ZsSI7
5. ReasonMed Medical Reasoning Dataset
ReasonMed is the largest open source medical reasoning dataset, designed to train and evaluate models for tasks such as medical question answering and text generation. The dataset contains 370,000 high-quality question-answering examples, covering multiple fields such as clinical knowledge, anatomy, and genetics.
Direct use:https://go.hyper.ai/DwGmH
6. Miriad-5.8M medical question answering dataset
The dataset contains 5.82 million medical question-answer pairs, covering all aspects from basic science to clinical practice. MIRIAD provides structured high-quality question-answer pairs to support various downstream tasks such as RAG, medical retrieval, hallucination detection, and instruction adjustment.
Direct use:https://go.hyper.ai/Xw8Ph
7. Common Corpus Large-scale open text dataset
This dataset is currently the largest open-licensed text dataset, containing 2 trillion tokens, covering content in multiple fields such as books, scientific literature, codes, legal documents, etc.; the main languages are English and French, and it also includes 8 languages with over 10 billion tokens (German/Spanish/Italian, etc.) and 33 languages with over 1 billion tokens.
Direct use:https://go.hyper.ai/PnbfK
8. HLE Human Question Reasoning Benchmark Dataset
HLE aims to build the ultimate closed-ended evaluation system covering the frontiers of human knowledge. The dataset contains 2,500 questions covering dozens of disciplines such as mathematics, humanities, and natural sciences, including multiple-choice questions and short-answer questions suitable for automatic scoring.
Direct use:https://go.hyper.ai/Lq7mE
9. MedCaseReasoning Medical Case Reasoning Dataset
MedCaseReasoning contains 13,000 cases, covering multiple disciplines such as internal medicine, neurology, infectious diseases, and cardiology. This dataset integrates the complete diagnosis and treatment process of multi-specialty clinical cases, covering core tasks such as disease diagnosis, differential analysis, and treatment decision-making, aiming to provide standardized resources for the evaluation of the reasoning ability of medical large language models.
Direct use:https://go.hyper.ai/4vqwo
10. FineHARD image-text alignment dataset
FineHARD is an open-source high-quality image-text alignment dataset. The dataset is characterized by scale and refinement, containing 12 million images and their corresponding long and short description texts, covering 40 million bounding boxes.
Direct use:https://go.hyper.ai/L2TOZ
Selected Public Tutorials
This week we have compiled 4 categories of quality public tutorials:
*Large model deployment tutorials: 5
*Multimodal Processing Tutorials: 4
*3D reconstruction tutorials: 3
*OCR Recognition Tutorial: 2
Large model deploymentTutorial
1. vLLM+Open WebUI deployment KernelLLM-8B
KernelLLM aims to automatically translate PyTorch modules into efficient Triton kernel code, thereby simplifying and accelerating the process of high-performance GPU programming. The model is based on the Llama 3.1 Instruct architecture, has 8 billion parameters, and focuses on generating efficient Triton kernel implementations.
Run online:https://go.hyper.ai/DfoWo
2. vLLM+Open WebUI deployment MiniCPM4-8B
MiniCPM 4.0 achieves high-performance reasoning at low computing cost through technologies such as sparse architecture, quantization compression, and efficient reasoning framework. It is particularly suitable for long text processing, privacy-sensitive scenarios, and edge computing device deployment. When processing long sequences, the model shows significantly faster processing speed than Qwen3-8B.
Run online:https://go.hyper.ai/kcANp
3. vLLM+Open WebUI deployment FairyR1-14B-Preview
FairyR1-14B-Preview focuses on math and code tasks. The model is based on the DeepSeek-R1-Distill-Qwen-32B base and is built by combining fine-tuning and model merging techniques.
Run online:https://go.hyper.ai/8jwGm
4. Qwen3-Embedding Series Model Comparison Evaluation Tutorial
The Qwen3 Embedding family represents a significant advancement in a variety of text embedding and ranking tasks, including text retrieval, code retrieval, text classification, text clustering, and bi-text mining.
Through this tutorial, you will systematically understand the core concepts of embedded models and reordering models, and learn how to select and apply them in practical scenarios.
Run online:https://go.hyper.ai/YtMdH
5. vLLM+Open WebUI deployment Devstral-Small-2505
Devstral excels at using tools to explore code bases, edit multiple files, and drive software engineering agents. The model performed well on SWE-bench, becoming the number one open source model in the benchmark.
Run online:https://go.hyper.ai/mnGzy
Multimodal Processing Tutorial
1. One-click deployment of VideoLLaMA3-7B
VideoLLaMA3 is an open source multimodal basic model focusing on image and video understanding tasks. It significantly improves the accuracy and efficiency of video understanding through vision-centric architecture design and high-quality data engineering.
This tutorial uses a single RTX 4090 computing resource and deploys the VideoLLaMA3-7B-Image model, providing two examples of video understanding and image understanding.
Run online:https://go.hyper.ai/t2z4d
2. Step1X-Edit: Image editing tool
Step1X-Edit has three key capabilities: precise semantic analysis, identity consistency maintenance, and high-precision area-level control. It supports 11 types of high-frequency image editing tasks, such as text replacement, style transfer, material transformation, and character retouching.
Run online:https://go.hyper.ai/MdDTI

3. Chain-of-Zoom: Super-resolution image detail enlargement demo
Chain-of-Zoom is a Chained Zoom (COZ) framework that addresses the problem that modern single image super-resolution (SISR) models fail when asked to zoom far beyond that range. The standard 4x diffusion SR model encapsulated in the COZ framework can achieve over 256x zoom while maintaining high perceptual quality and fidelity.
Run online:https://go.hyper.ai/7Lixx

4. Sa2VA: Towards Dense Perceptual Understanding of Images and Videos
Sa2VA is the first unified model for dense perceptual understanding of images and videos. Unlike existing multimodal large language models, which are often limited to specific modalities and tasks, Sa2VA supports a wide range of image and video tasks, including reference segmentation and conversation, with minimal single-shot fine-tuning.
Run online:https://go.hyper.ai/tj2bX
3D Reconstruction Tutorial
1. Distill-Any-Depth: Monocular Depth Estimator
The project integrates the advantages of multiple open source models through the distillation algorithm, achieving high-precision depth estimation with only a small amount of unlabeled data, refreshing the current SOTA (State-of-the-Art) performance.
Run online:https://go.hyper.ai/DNSf5

2. VGGT: A General 3D Vision Model
VGGT is a feed-forward neural network that directly infers all key 3D properties of a scene, including extrinsic and intrinsic camera parameters, point maps, depth maps, and 3D point trajectories, from one, a few, or hundreds of views in seconds. It is also simple and efficient, achieving reconstruction in under a second, even outperforming alternative methods that require post-processing with visual geometry optimization techniques.
Run online:https://go.hyper.ai/e8xzG
3. UniDepthV2: Universal Monocular Metric Depth Estimation
UniDepthV2 is able to reconstruct metric 3D scenes from only a single image across domains. Unlike the existing MMDE paradigm, UniDepthV2 directly predicts metric 3D points from the input image at inference time without any additional information, striving to achieve a general and flexible MMDE solution.
Run online:https://go.hyper.ai/JdgZC
OCR Recognition Tutorial
1. MonkeyOCR: Document parsing based on the structure-recognition-relation triple paradigm
MonkeyOCR supports the efficient conversion of unstructured document content into structured information. The model supports a variety of document types, including academic papers, textbooks, and newspapers, and is applicable to multiple languages, providing strong support for document digitization and automated processing.
Run online:https://go.hyper.ai/s9GE2
2. Nanonets-OCR-s: Document information extraction and benchmarking tool
Nanonets-OCR-s can recognize various elements in documents, such as mathematical formulas, images, signatures, watermarks, checkboxes and tables, and organize them into structured Markdown format. This capability makes it excellent in processing complex documents, such as academic papers, legal documents or business reports.
This tutorial uses a single RTX 4090 card as the resource. The tutorial contains two functions: extracting information and images from documents and converting PDF to Markdown.
Run online:https://go.hyper.ai/1uPym
💡We have also established a Stable Diffusion tutorial exchange group. Welcome friends to add Neural Star (WeChat ID: Hyperai01) and remark [SD Tutorial] to join the group to discuss various technical issues and share application results~
This week's paper recommendation
1.FocalAD: Local Motion Planning for End-to-End Autonomous Driving
This paper proposes FocalAD, a novel end-to-end autonomous driving framework that focuses on critical local neighbors and optimizes planning by enhancing local motion representation. Specifically, FocalAD contains two core modules: Autonomous-Local-Agent Interactor (ELAI) and Focal-Local-Agent Loss (FLA Loss).
Paper link:https://go.hyper.ai/vjBZy
2.Biomni: A General-Purpose Biomedical Al Agent
We present Biomni: a general-purpose biomedical AI assistant designed to autonomously perform a wide range of research tasks across multiple biomedical subfields. To systematically map the biomedical action space, Biomni leverages action discovery agents to mine key tools, databases, and protocols from tens of thousands of papers across 25 biomedical fields, creating the first unified agent environment.
Paper link:https://go.hyper.ai/zTFzy
3.SeerAttention-R: Sparse Attention Adaptation for Long Reasoning
This paper introduces SeerAttention-R, a sparse attention framework designed for long decoding of inference models. The framework extends SeerAttention and retains the design of learning attention sparsity through self-distillation gating mechanism, while removing query pooling to adapt to autoregressive decoding. With the lightweight insertion gating mechanism, SeerAttention-R is flexible and can be easily integrated into existing pre-trained models without modifying the original parameters.
Paper link:https://go.hyper.ai/8XHpf
4.Text-Aware Image Restoration with Diffusion Models
In this paper, we propose a multi-task diffusion framework, TeReDiff, which incorporates the internal features of the diffusion model into a text detection module, allowing both components to benefit from joint training. This enables it to extract rich text representations that can be used as cues in the subsequent denoising step.
Paper link:https://go.hyper.ai/3YDSf
5.Unified differentiable learning of electric response
This paper implements an equivariant machine learning framework in which the response characteristics are derived from the exact differential relationship between the generalized potential function and the applied external field. The method focuses on the response to the electric field, predicting the electric enthalpy, force, polarization, Born charge and polarizability in a unified model that enforces a full set of accurate physical constraints, symmetries and conservation laws.
Paper link:https://go.hyper.ai/AO8dM
More AI frontier papers:https://go.hyper.ai/iSYSZ
Community article interpretation
A joint research team from Harvard University and Bosch proposed an innovative solution and developed a unified differentiable learning framework for electrical response. This framework can simultaneously learn the generalized potential energy and its response function to external stimuli in a single machine learning model, overcoming the inherent defects of traditional independent models and opening up a new path for high-precision research on the dielectric and ferroelectric properties of crystals, disordered and liquid materials.
View the full report:https://go.hyper.ai/d3cAc
HyperAI will hold the 7th Meet AI Compiler Technology Salon in Zhongguancun, Beijing on July 5. This event invited four senior experts from AMD, Muxi Integrated Circuit, ByteDance, and Peking University to explore the cutting-edge practices of AI compilers from multiple perspectives, from low-level compilation to upper-level applications.
View the full report:https://go.hyper.ai/elNCA
Shandong University of Technology, together with research teams from Beijing Forestry University, Guangdong Academy of Agricultural Sciences, University of São Paulo in Brazil, Rosalind Franklin University of Medical Sciences in the UK, and Umeå University in Sweden, jointly constructed the PlantLncBoost model, providing a systematic solution to the generalization problem of plant lncRNA identification.
View the full report:https://go.hyper.ai/M88RZ
The Department of Materials Science and Engineering at MIT, in collaboration with a multi-departmental team, has developed a new data-driven approach based on a large language model (LLM) and a multi-head neural network architecture to achieve large-scale prediction and screening of the reactivity of cement substitute materials.
View the full report:https://go.hyper.ai/rtvf4
In order to let more users know the latest developments in the field of artificial intelligence in academia, HyperAI's official website (hyper.ai) has now launched a "Latest Papers" section, which updates cutting-edge AI research papers every day, covering multiple vertical fields such as machine learning, computational language, computer vision and pattern recognition, and human-computer interaction.
View the full report: https://go.hyper.ai/ttAl7
Popular Encyclopedia Articles
1. DALL-E
2. Reciprocal sorting fusion RRF
3. Pareto Front
4. Large-scale Multi-task Language Understanding (MMLU)
5. Contrastive Learning
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
July deadline for the top conference
July 2 7:59:59 VLDB 2026
July 11 7:59:59 POPL 2026
July 15 7:59:59 SODA 2026
July 18 7:59:59 SIGMOD 2026
July 19 7:59:59 ICSE 2026
One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!








