Command Palette
Search for a command to run...
Selected for ICML 2025! Harvard Medical School and Others Launched the world's First Clinical Mind Map Model in the HIE Field, With a 15% Performance Improvement in Neurocognitive Outcome Prediction Tasks

As artificial intelligence technology advances by leaps and bounds, large-scale vision-language models (LVLMs) are reshaping the cognitive boundaries of multiple fields at an astonishing rate.In the field of natural image and video analysis,Relying on advanced neural network architecture, massive labeled data sets and powerful computing support, this type of model can accurately complete high-level tasks such as object recognition and scene analysis.In the field of natural language processing,By learning from TB-level text corpora, LVLMs has achieved professional-level performance in tasks such as machine translation, text summarization, and sentiment analysis. The academic abstracts it generates can even accurately extract the core conclusions of medical literature.
However, as the technology wave surges into the medical field, the implementation of LVLMs has encountered significant resistance. Although the demand for intelligent auxiliary diagnosis in clinical scenarios is extremely urgent, the medical application of such models is still in the primary exploration stage.The core bottleneck stems from the unique properties of medical data:Due to multiple constraints such as patient privacy protection regulations, medical data island effects, and ethical review mechanisms, the scale of publicly available high-quality medical datasets is only one ten-thousandth of that in the general field.Most existing medical datasets use basic visual question answering architectures, focusing on primary pattern recognition tasks such as "which anatomical structure is this?"——For example, a public data set contains 200,000 X-ray annotations, but the annotation content of 90% remains at the organ localization level and cannot touch upon core clinical needs such as lesion severity grading and prognosis risk assessment.
This mismatch between data supply and actual demand results in the model being able to identify abnormal signals in the basal ganglia when faced with neonatal hypoxic-ischemic encephalopathy (HIE) MRI images, but being unable to integrate multi-dimensional information such as gestational age and perinatal medical history to predict neurodevelopmental prognosis.
In order to overcome this dilemma, an interdisciplinary team from Boston Children's Hospital, Harvard Medical School, New York University, and MIT-IBM Watson Laboratory collected ten years of MRI images and expert interpretations of 133 individuals with hypoxic-ischemic encephalopathy (HIE).Constructed a professional-level medical reasoning benchmark dataset,Aims to accurately evaluate the reasoning performance of LVLMs in medical professional fields.The research team also proposed a clinical mind map model (CGoT).The ability to simulate the diagnostic process through clinical knowledge-guided mind-mapping prompts allows the incorporation of domain-specific clinical knowledge as visual and textual inputs, significantly enhancing the predictive power of LVLMs.
The relevant research results, titled "Visual and Domain Knowledge for Professional-level Graph-of-Thought Medical Reasoning", have been successfully selected for ICML 2025.
Research highlights:
* Create a new HIE reasoning benchmark test that combines clinical visual perception with professional medical knowledge for the first time, simulates the clinical decision-making process, and accurately evaluates the professional performance of LVLMs in medical reasoning.
* Comprehensively compare advanced general and medical LVLMs to reveal their limitations in terms of medical domain knowledge and provide directions for model improvement.
* Proposed the CGoT model, which integrates medical expertise with LVLMs, mimics the clinical decision-making process, and effectively enhances medical decision support.

Paper address:
https://openreview.net/forum?id=tnyxtaSve5
More AI frontier papers:
https://go.hyper.ai/owxf6
The open source project "awesome-ai4s" brings together more than 100 AI4S paper interpretations and provides massive data sets and tools:
https://github.com/hyperai/awesome-ai4s
HIE-Reasoning: Construction of multimodal datasets and creation of professional reasoning task system
In terms of data construction, this study focuses on hypoxic-ischemic encephalopathy (HIE), a severe neonatal disease.Over a period of 10 years, high-quality MRI images of 133 HIE children aged 0-14 days were collected.Simultaneously obtain interpretation reports clinically validated by multidisciplinary experts (including a senior neuroradiologist with 30 years of experience) to form a core data set for longitudinal tracking.
As shown in the figure below, the researchers defined six tasks for LVLMs to perform professional clinical reasoning:
* Task 1: Lesion Grading.The task quantifies brain damage by estimating the percentage of brain volume affected by HIE lesions and assessing the severity of the lesions.
* Task 2: Lesion Anatomy.This task identifies the specific area of the brain affected by the lesion.
* Mission 3: Lesion in Rare Locations.This task identifies lesions caused by HIE and classifies the affected areas as common or uncommon, helping to determine whether the patient requires additional attention.
* Task 4: MRI Injury Score.The task outputs an overall injury score from MRI, providing a standardized measure of injury severity to guide treatment and predict outcome.
* Task 5: 2-year neurocognitive outcome.The task predicts patients' neurocognitive outcomes 2 years later, helping clinicians anticipate long-term effects and plan appropriate interventions.
* Task 6: MRI Interpretation Summary.The task is based on a radiologist-recommended neonatal MRI summary template and is able to generate a comprehensive MRI interpretation for the patient.
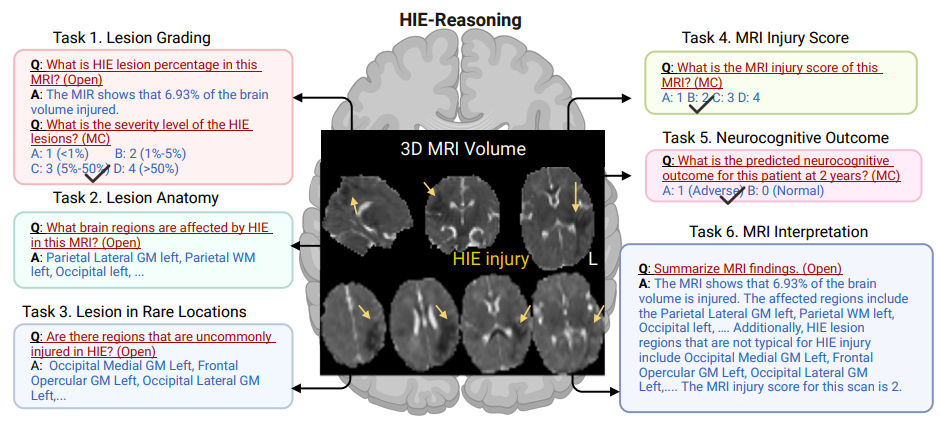
final,The researchers constructed the world's first public HIE dataset, HIE-Reasoning, which contains 749 question-and-answer pairs and 133 MRI interpretation summaries.Unlike traditional medical datasets such as VQAmed and OmiMed-VQA, which focus on basic issues such as imaging method recognition and organ positioning,This dataset transforms the deep reasoning process of clinical experts into a computable evaluation system for the first time.Its data structure innovation adopts a three-layer architecture: patient-level original images and task files, cross-case meta-knowledge reasoning templates, and individual lesion probability maps. It not only retains the integrity of medical data, but also provides the model with explicit knowledge input including pathological mechanisms.
Although the sample size was only 133 cases, through a 17-year (2001-2018) multicenter retrospective collection, combined with the low incidence of HIE in tertiary hospitals of 1-5‰,This dataset has become the first HIE-specific benchmark that integrates imaging, clinical, and prognostic multimodal information.Its labeling accuracy and clinical depth are sufficient to make up for the scale limitations, providing an indispensable benchmark for LVLMs to break through the bottleneck of "basic identification" and enter the deep waters of diagnosis and treatment decision-making.
CGoT model: driven by clinical thinking map, building a new framework for interpretable hierarchical medical reasoning
In order to break through the interpretability bottleneck of traditional large-scale visual-language models (LVLMs) in medical reasoning (as shown in Figure A below), the research team proposed the Clinical Goal Map Model (CGoT), as shown in Figure BC below. By integrating clinical knowledge to guide the language model to simulate the doctor's diagnosis process, the reliability of predicting neurocognitive results can be significantly improved.This model innovatively adopts a structured "reasoning mind map", transforming the diagnostic steps of medical experts into a hierarchical reasoning pipeline to solve complex tasks by gradually accumulating knowledge.
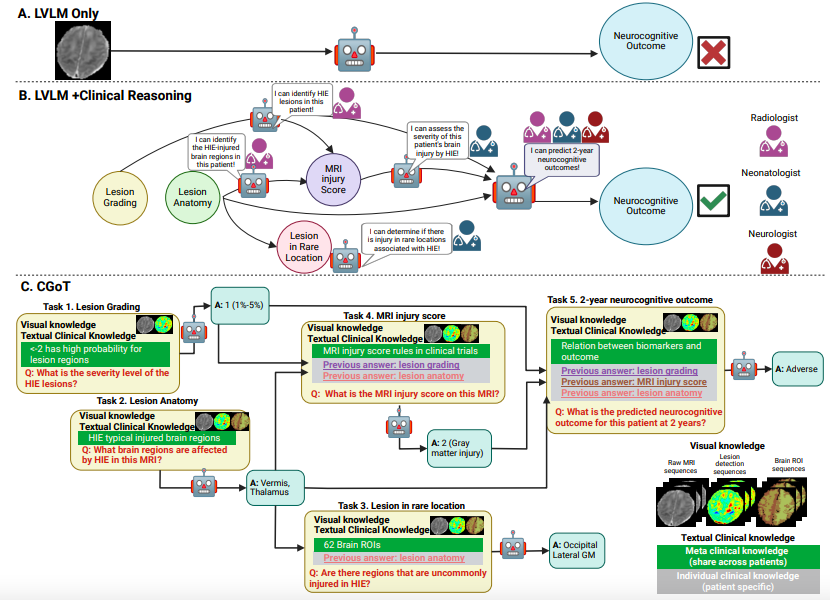
The text knowledge side is divided into meta-clinical knowledge (including general medical background such as brain anatomical maps, lesion distribution patterns, MRI biomarker prognosis associations, etc.) and individual clinical knowledge (patient-specific diagnostic clues dynamically generated through the output of previous tasks). The two types of knowledge are structured and input in a prompt engineering manner to guide LVLM to deduce step by step according to the logical chain of "clinical guidelines-imaging features-individual medical history".
The entire framework transforms implicit medical diagnostic logic into computable model input by integrating structured prompts of clinical graphs with cross-modal knowledge. This not only retains the cross-modal processing capabilities of LVLMs, but also avoids the randomness of the reasoning process by anchoring clinical knowledge.
CGoT clinical reasoning performance evaluation achieves breakthrough improvements in key tasks
To verify the effectiveness of the HIE-Reasoning benchmark and the CGoT model, the research team designed a multi-dimensional experimental system.
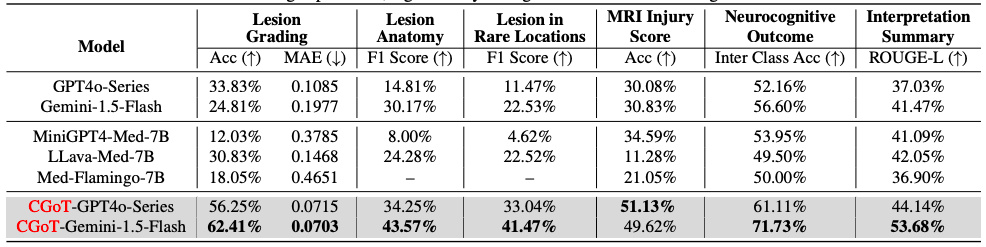
first,The researchers conducted zero-shot evaluations on six large-scale visual-language models.Three types of general LVLMs (Gemini1.5-Flash, GPT4o-Mini, GPT4o) and three types of medical LVLMs (MiniGPT4-Med, LLava-Med, Med-Flamingo) were selected as baseline models. Six major clinical tasks, including lesion grading, anatomical localization, and prognosis prediction, were evaluated using task-specific indicators such as accuracy, MAE, F1 score, and ROUGE-L. The two-year neurocognitive outcome prediction used the average accuracy between categories to balance the label distribution bias.
The experimental results reveal the significant limitations of traditional LVLMs: when MRI slices and task descriptions are directly input, all baseline models perform poorly in professional medical reasoning tasks. Some models have answer hallucinations or conservatively refuse to answer due to lack of clinical knowledge. For example, Med-Flamingo generates meaningless repetitive content in anatomical positioning tasks, and the GPT4o series cannot handle high uncertainty problems due to its alignment strategy.
In sharp contrast, as shown in the following table,The CGoT model achieves breakthrough improvements in key tasks by integrating clinical mind maps and cross-modal knowledge——Especially in the core clinical need of two-year prognosis prediction, its performance is improved by more than 15% compared with the baseline model, and the accuracy and consistency of tasks such as lesion grading and injury scoring are also significantly better than the control group.
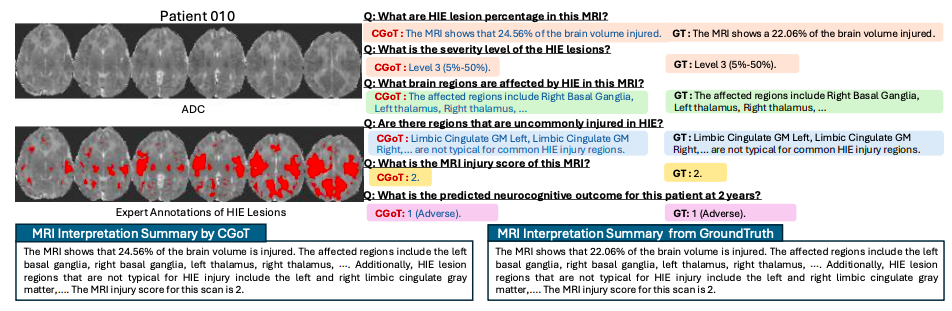
At the same time, robustness experiments show that even when ±1 level score perturbations are introduced into the intermediate task results of 10%-30%, the model performance only shows a gradual decline, demonstrating its ability to adapt to common data noise in clinical practice. These findings together indicate thatBy simulating the hierarchical reasoning process of clinical diagnosis, CGoT not only breaks through the knowledge blind spots of traditional models, but also builds a reliable decision support system that is close to real diagnosis and treatment scenarios.
The dual-wheel drive of medical LVLMs: innovative practices and trends in academia and business
Globally, the research and application of Large Vision-Language Models (LVLMs) in the medical field are undergoing a paradigm shift, and innovative practices in academia and the business community are jointly driving breakthroughs in this field.
At the academic research level, the Shanghai Artificial Intelligence Laboratory, together with the University of Washington, Monash University, East China Normal University and other research institutions, jointly released the GMAI-MMBench benchmark test.It integrates 284 clinical task datasets, covering 38 medical imaging modalities and 18 core clinical needs (such as tumor diagnosis, neuroimaging analysis, etc.).The benchmark uses a vocabulary tree classification system to accurately classify cases by department, modality, and task type, providing a standardized framework for evaluating the clinical reasoning ability of LVLMs.
* Click here to view the full report: Containing 284 data sets, covering 18 clinical tasks, Shanghai AI Lab and others released the multimodal medical benchmark GMAI-MMBench
In addition, Med-R1, jointly developed by Emory University, University of Southern California, University of Tokyo, and Johns Hopkins University, innovatively introduces group relative policy optimization (GRPO) to address the limitations of traditional supervised fine-tuning (SFT) methods.Stable policy updates through rule rewards and group comparisons without complex value models.Open source LVLMs such as MedDr launched by the Hong Kong University of Science and Technology have achieved performance close to commercial models in specific tasks (such as lesion grading), demonstrating the potential of the open source ecosystem in the field of medical AI.
The business community is accelerating the clinical transformation of LVLMs with the implementation of technology as the core. For example, Microsoft Azure Medical Cloud Platform has achieved deep integration of medical image analysis, electronic medical record automation and other functions by integrating AI tools and clinical data. The intelligent radiology system it has developed in cooperation with many hospitals isAbility to quickly identify abnormal areas in MRI images through LVLMs and generate structured reports.Assist doctors to complete the tasks of lesion grading and anatomical positioning.
Google has launched the open source medical model MedGemma, which is based on the Gemma3 architecture and is designed specifically for the medical and health field. It aims to enhance medical and health applications and improve the efficiency of medical diagnosis and treatment by seamlessly combining the analysis of medical images and text data.
* Click here for detailed report: Google releases MedGemma, built on Gemma 3, specializing in medical text and image understanding
These practices together reveal two major trends in the development of medical LVLMs:First, the deep integration of clinical knowledge and model architecture.For example, the task system constructed through expert annotation in the HIE-Reasoning benchmark described in this article, and the clinical thinking map introduced by the CGoT model;The second is innovation in interdisciplinary collaboration and data governance.For example, GMAI-MMBench integrates global data sets through unified annotation formats and ethical compliance processes, providing a model for solving the scarcity of medical data. In the future, with the further application of technologies such as federated learning and synthetic data generation, academia and the business community are expected to achieve breakthroughs in more complex clinical scenarios (such as multimodal prognosis prediction and real-time surgical navigation), truly promoting the transformation of AI from an auxiliary tool to an intelligent decision-making partner.
Reference articles:
1.https://blog.csdn.net/Python_cocola/article/details/146590017
2.https://mp.weixin.qq.com/s/0SGHeV8OcXu8kFk68f-7Ww








