Command Palette
Search for a command to run...
Online Tutorial: Refreshing the TTS Model SOTA, OpenAudio S1 Is Trained Based on 2 Million Hours of Audio Data, Deeply Understanding Emotions and Speech Details

In recent years, the TTS (Text-to-Speech) model has undergone iterations from concatenated speech synthesis to statistical parameter synthesis, and then to neural network TTS (Neural TTS). It has shown an end-to-end and module fusion trend at the technical level, and has shown an upgraded effect of multi-language, high naturalness, and rich emotional changes at the application level.
As TTS models are widely used in virtual voice assistants, digital humans, AI dubbing, intelligent customer service and other fields, the industry's demand for real-time feedback is gradually increasing.Then comes the trade-off between inference speed and model parameters.The latter, to some extent, limits the deployment cost and application scenarios of the TTS model.
In view of this,Fish Audio has launched a new open source TTS model, OpenAudio S1.It includes two versions: OpenAudio-S1 and OpenAudio-S1-mini. According to the official documentation, OpenAudio S1 is trained on a large-scale dataset of more than 2 million hours of audio. The team expanded the model parameters to 4 billion and introduced a self-developed reward modeling mechanism. At the same time, it also applied reinforcement learning based on human feedback (RLHF, using the GRPO method) training.
Based on this, OpenAudio S1 successfully eliminates the artifacts and incorrect vocabulary caused by information loss when most other models use semantic-only models, thus far surpassing previous models in terms of audio quality, emotional expression, and speaker similarity.High-quality TTS output can be generated with only 10 to 30 seconds of speech sample input.It has currently topped the HuggingFace TTS-Arena-V2 human subjective evaluation rankings, achieving a low CER (character error rate) of about 0.4% and a WER (word error rate) of about 0.8% on Seed-TTS Eval.
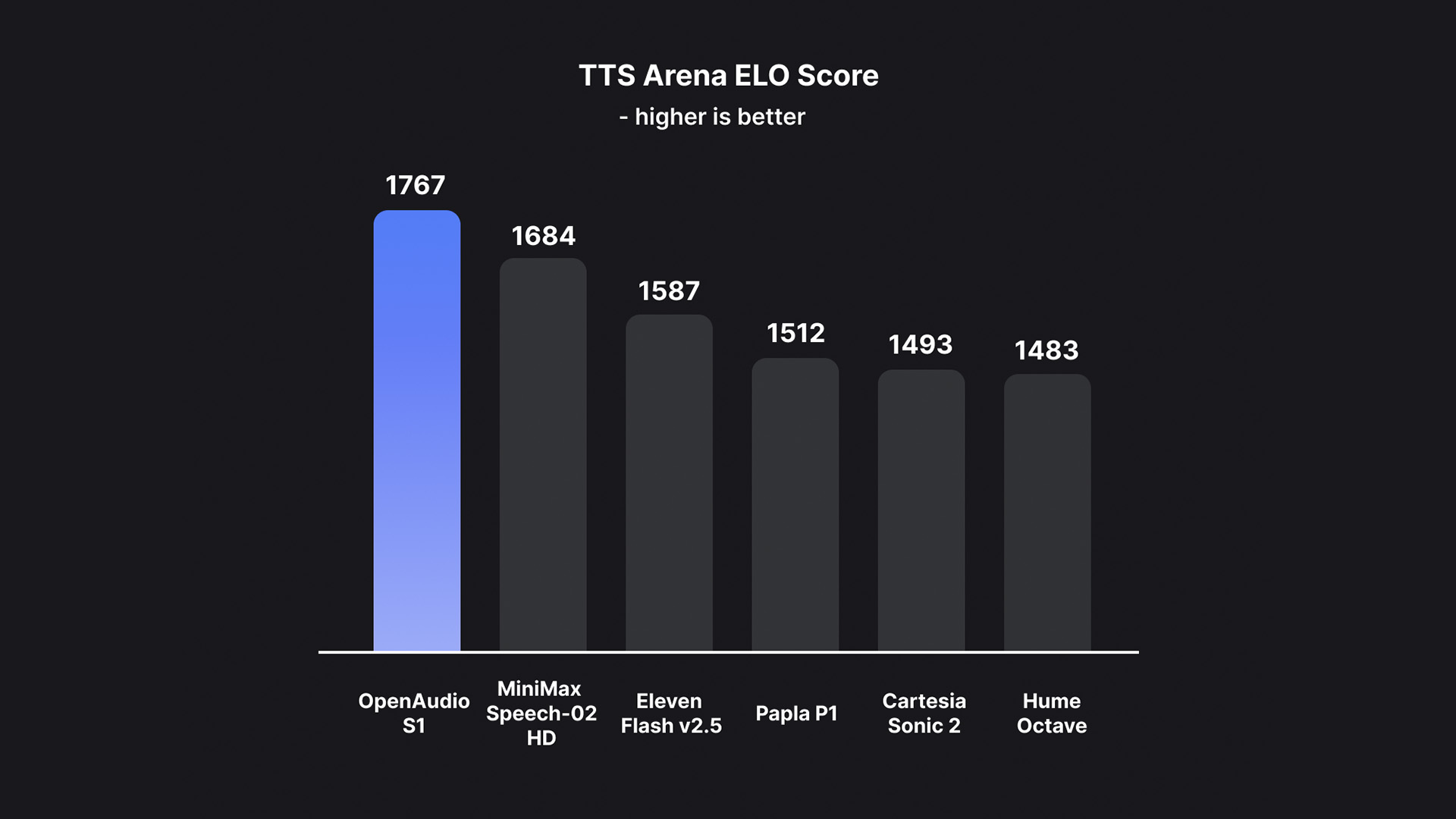
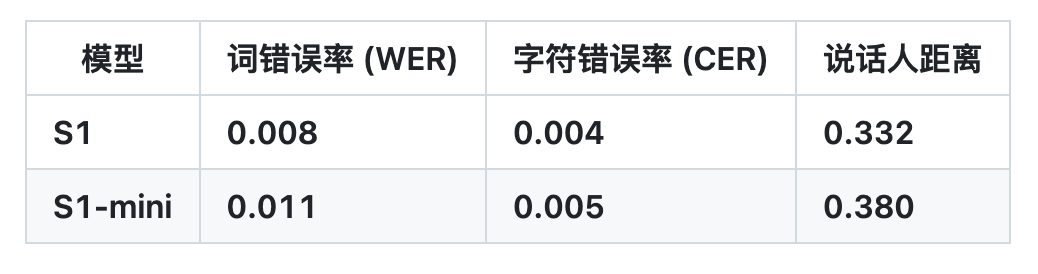
According to the team,What makes OpenAudio S1 truly unique is its ability to deeply understand and express human emotions and speech details.It supports a rich set of tags for precise control of synthesized speech. In order to train the TTS model to follow instructions, the team also built a speech-to-text model (to be released soon) that can generate subtitles for audio containing emotions, intonation, speaker information, etc. Over 100,000 hours of audio were randomly annotated based on this model to train OpenAudio S1.
For this reason, OpenAudio S1 supports multiple emotions, intonations, and special markers to enhance speech synthesis. In addition to basic emotions such as anger, surprise, and happiness, it also supports advanced emotions such as contempt, sarcasm, and hesitation. In terms of intonation, it supports whispering, screaming, sobbing, etc. In terms of language, English, Chinese, and Japanese are currently supported.
What is more worth mentioning is that in terms of the balance between performance and deployment cost,The team claims this is the first SOTA model that costs just $15 per million bytes ($15/million bytes, about $0.8/hour).
In order to let everyone experience the powerful performance of OpenAudio S1 more quickly,The tutorial section of HyperAI's official website (hyper.ai) has now launched "OpenAudio-s1-mini: Efficient Text-to-Speech Generation Tool".
Tutorial Link:https://go.hyper.ai/rVvkS
We have also prepared free use benefits of RTX 4090 resources for newly registered users. Use the invitation code below to register and have the opportunity to experience high-quality TTS models at no cost.
HyperAI exclusive invitation link (copy and open in browser):
https://openbayes.com/console/signup?r=Ada0322_NR0n
Demo Run
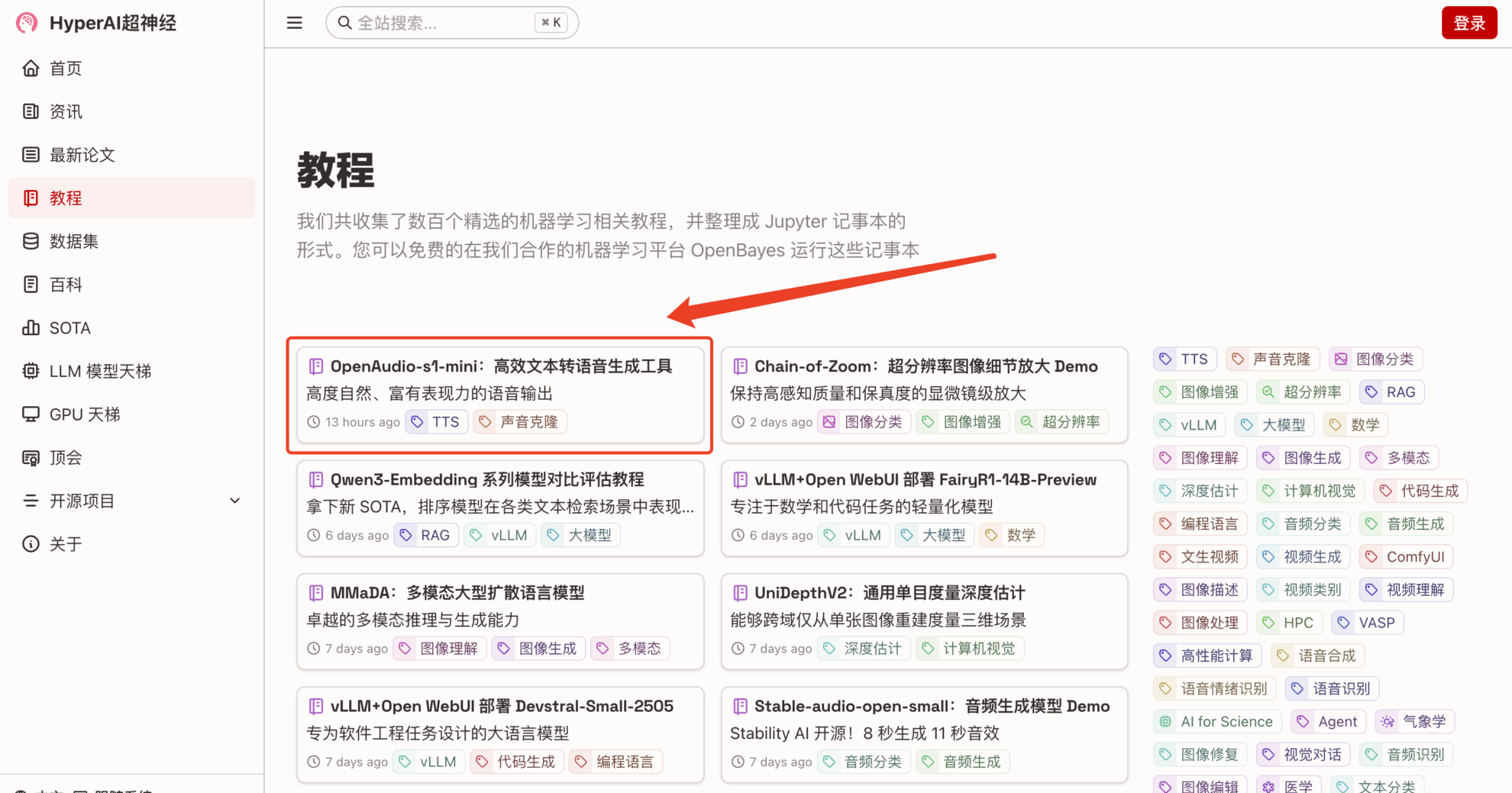
1. After entering the hyper.ai homepage, select the "Tutorial" page, select "OpenAudio-s1-mini: Efficient Text-to-Speech Generation Tool", and click "Run this tutorial online".
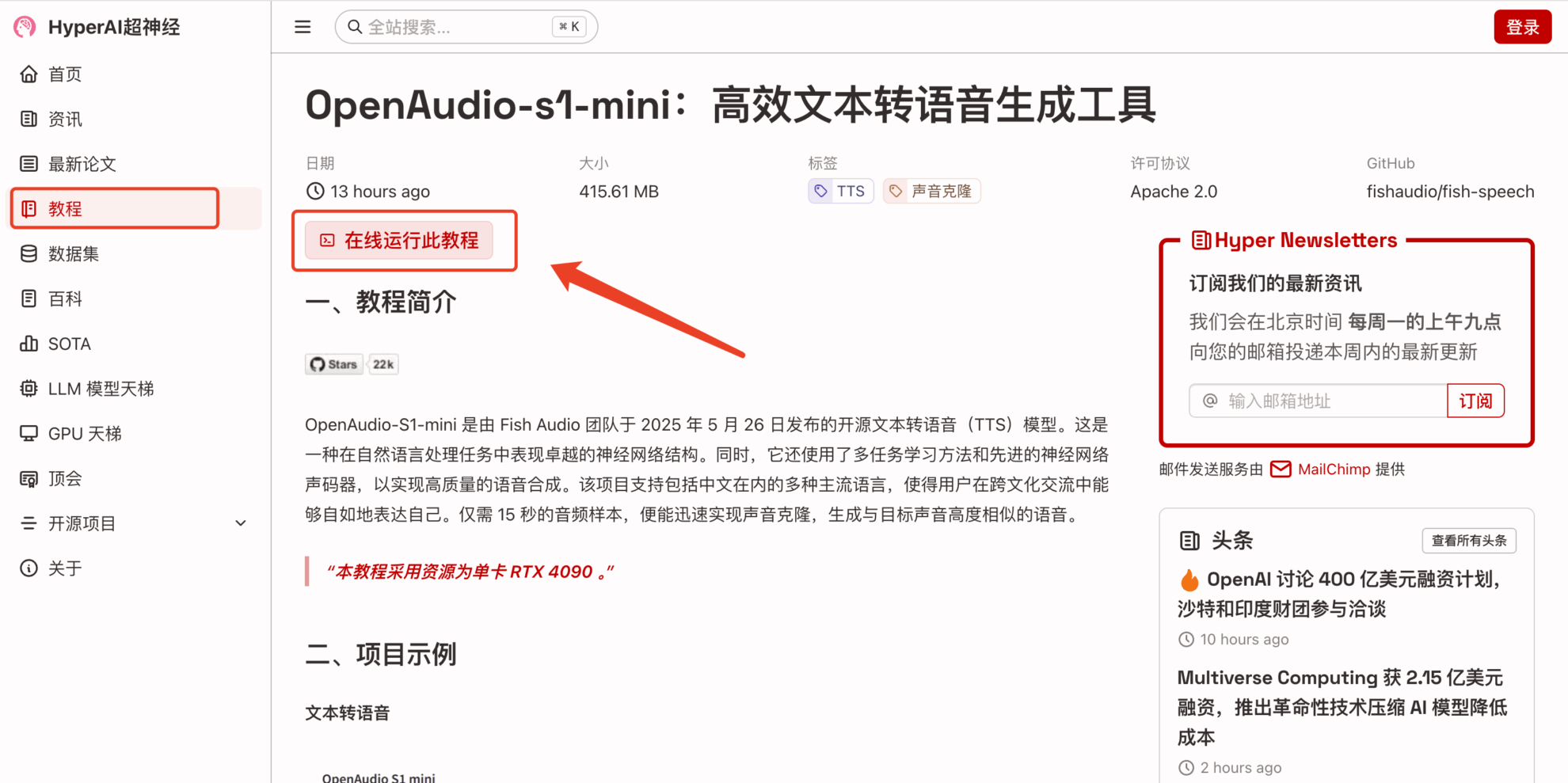
2. After the page jumps, click "Clone" in the upper right corner to clone the tutorial into your own container.
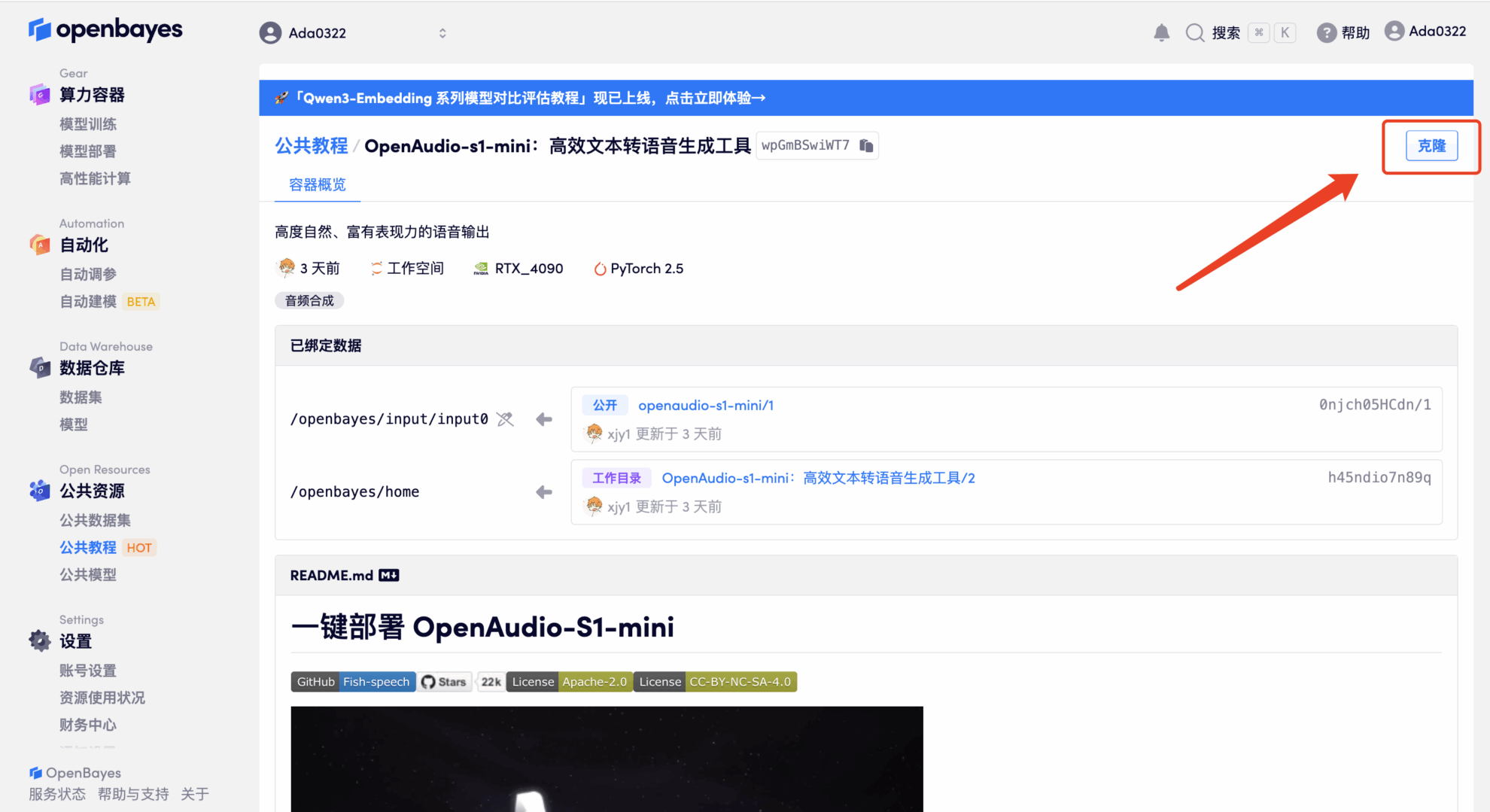
3. Select "NVIDIA RTX 4090" and "PyTorch" images. The OpenBayes platform provides 4 billing methods. You can choose "Pay as you go" or "Pay per day/week/month" according to your needs. Click "Continue". New users can register using the invitation link below to get 4 hours of RTX 4090 + 5 hours of CPU free time!
HyperAI exclusive invitation link (copy and open in browser):
https://openbayes.com/console/signup?r=Ada0322_NR0n
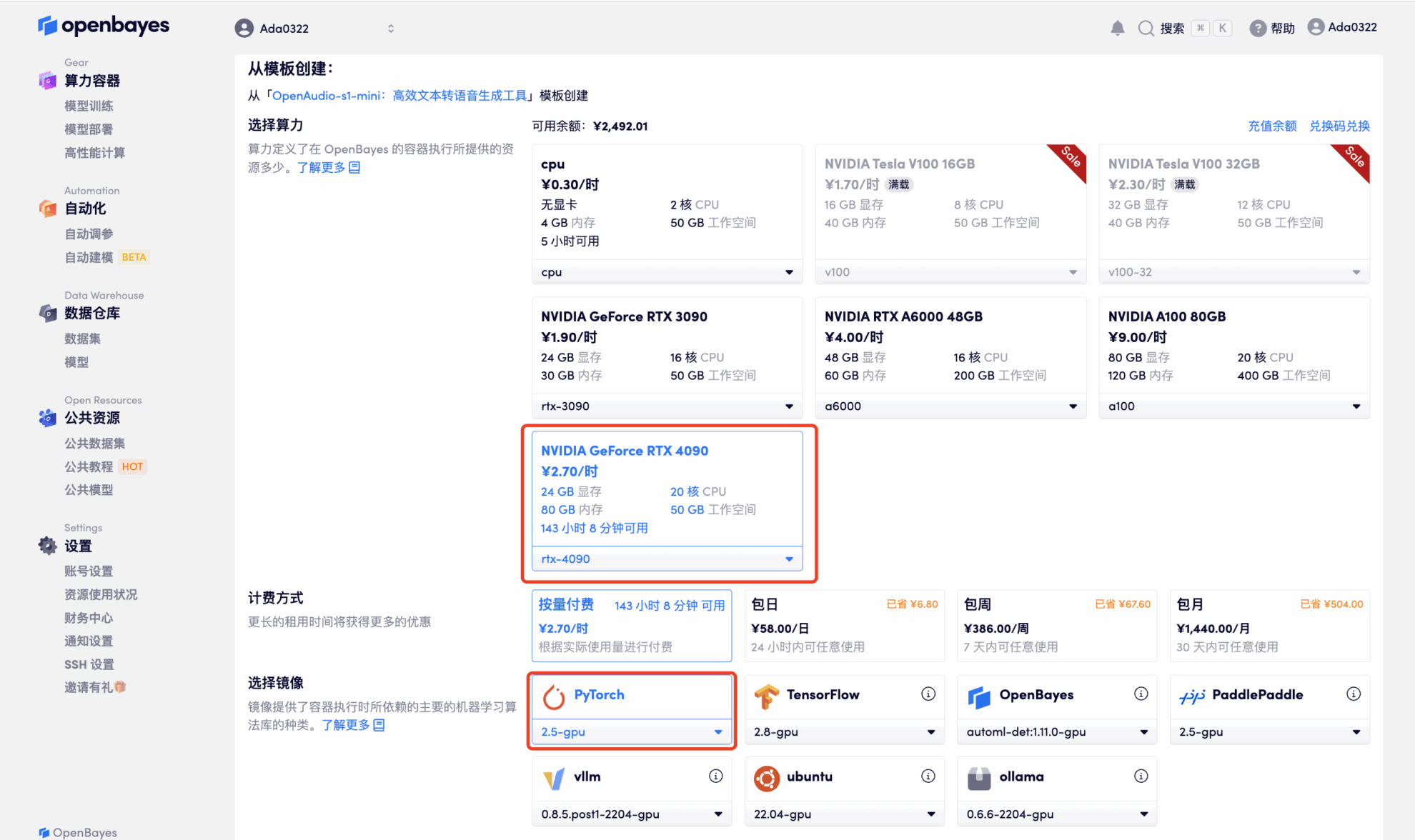
4. Wait for resources to be allocated. The first clone will take about 2 minutes. When the status changes to "Running", click the jump arrow next to "API Address" to jump to the Demo page. Due to the large model, it will take about 3 minutes to display the WebUI interface, otherwise "Bad Gateway" will be displayed. Please note that users must complete real-name authentication before using the API address access function.
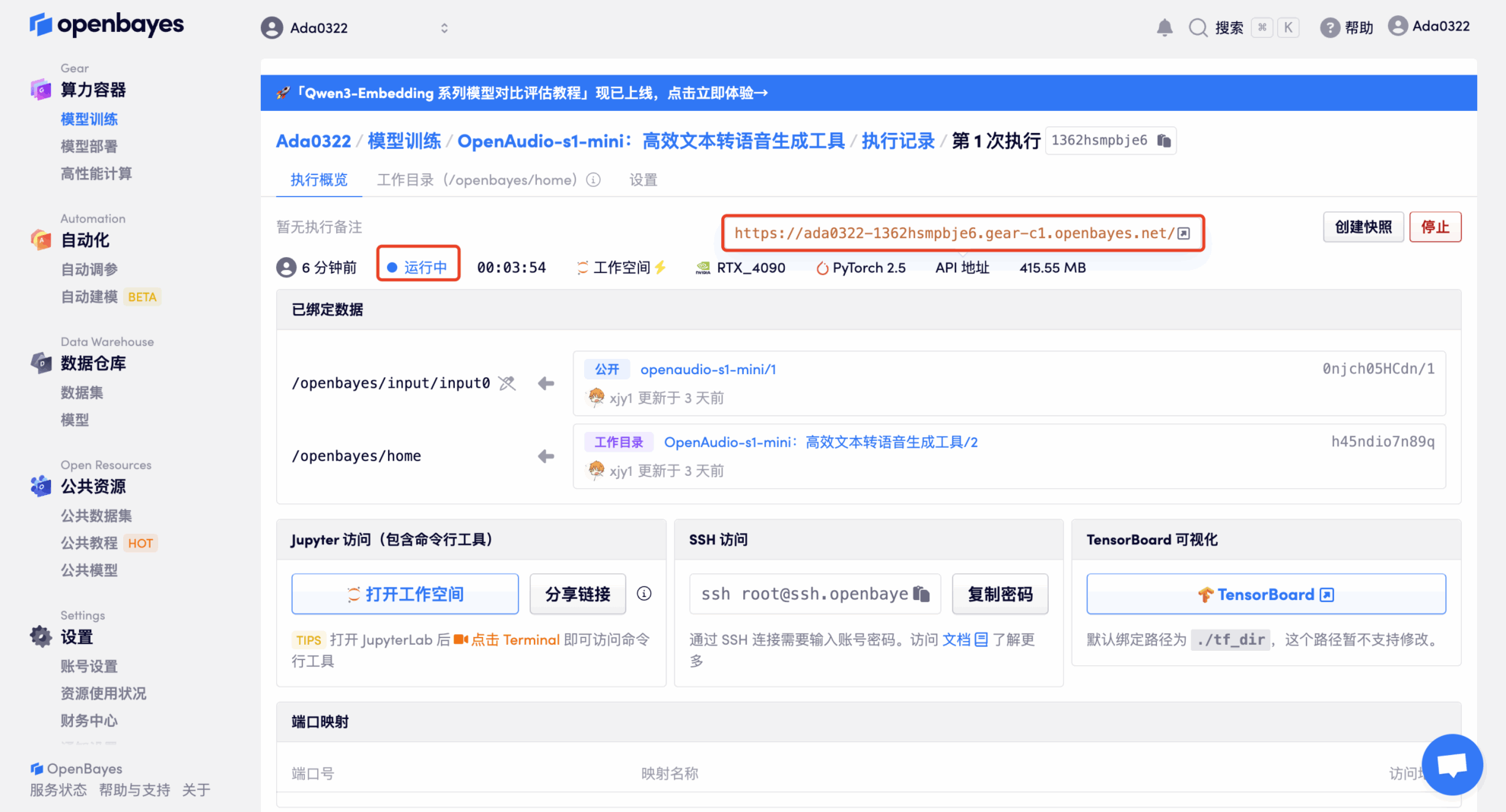
Effect Demonstration
Click "API Address" to experience the model. I uploaded an audio clip of "Paimon", a character in Genshin Impact. The input text is as follows:
I was originally a support, but I came to play jungle tonight. It’s only 30,000 days, so what’s the harm in giving it a try?
Then, click Generate on the right to generate the audio:
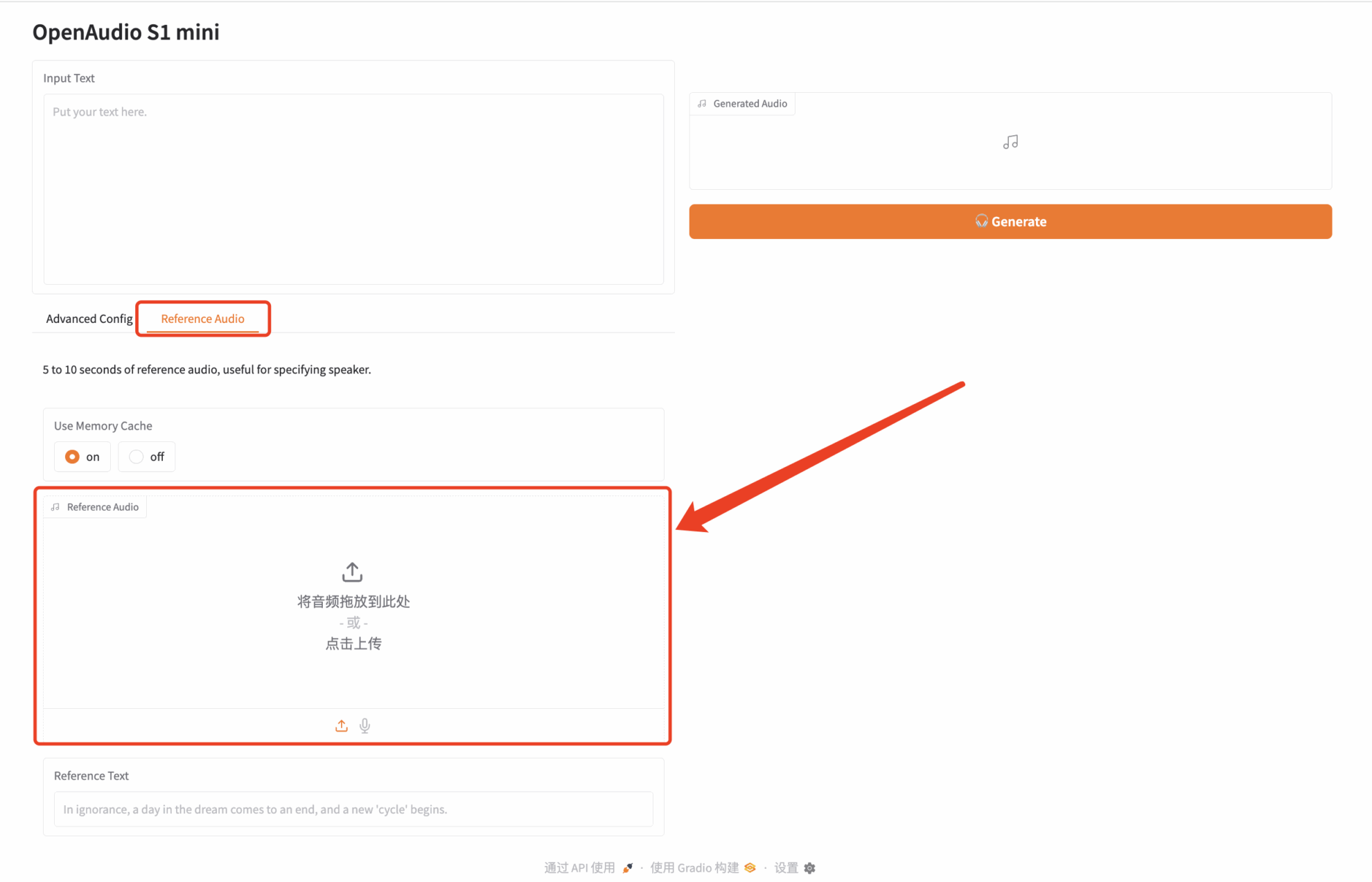
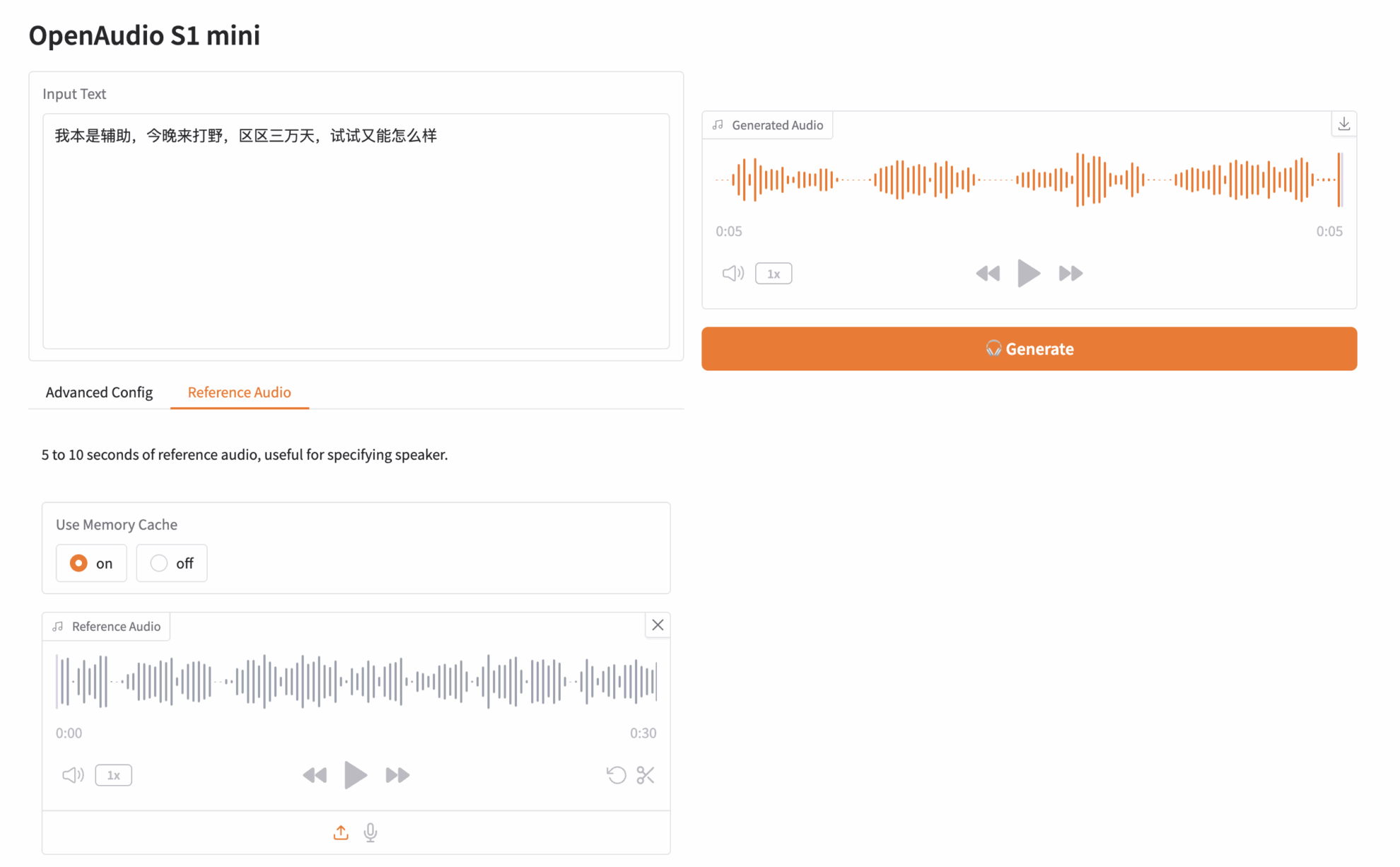
The above is the tutorial recommended by HyperAI this time. Welcome to experience it online:








