Command Palette
Search for a command to run...
Say Goodbye to Code Troubles! Seed-Coder Unlocks Efficient Programming; Mixture-of-Thoughts Covers multi-domain Data to Achieve high-quality Reasoning

As the competition for big models becomes increasingly fierce and the trend of "volume technology and scale" continues, how to improve the actual usability and task performance of the model has become a more critical issue. Among them, coding ability is an important indicator to measure the usability and task performance of big models. Based on this, the ByteDance Seed team released a lightweight but powerful open source code big language model - Seed-Coder-8B-Instruct.
This model is a fine-tuned version of the Seed-Coder series, built on the Llama 3 architecture, with 8.2B parameters and supports context processing with a maximum length of 32K tokens.Seed-Coder-8B-Instruct With minimal human input, LLM can efficiently manage code training data by itself, thereby significantly improving coding capabilities. By generating and screening high-quality training data by itself, the model code generation capability can be greatly improved.
Currently, HyperAI Super Neural is online 「vLLM+Open WebUI Deployment Seed-Coder-8B-Instruct", come and try it~
Online use:https://go.hyper.ai/BnO32
Live broadcast appointment
Apple's WWDC25 global conference will be held at 1 a.m. Beijing time on June 10. HyperAI Super Neural Video will broadcast the Keynote meeting in real time. If you don't want to miss it, make an appointment now!

From June 3rd to June 6th, hyper.ai official website updates:
* High-quality public datasets: 10
* High-quality tutorials: 13
* This week's recommended papers: 5
* Community article interpretation: 4 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in June: 2
Visit the official website:hyper.ai
Selected public datasets
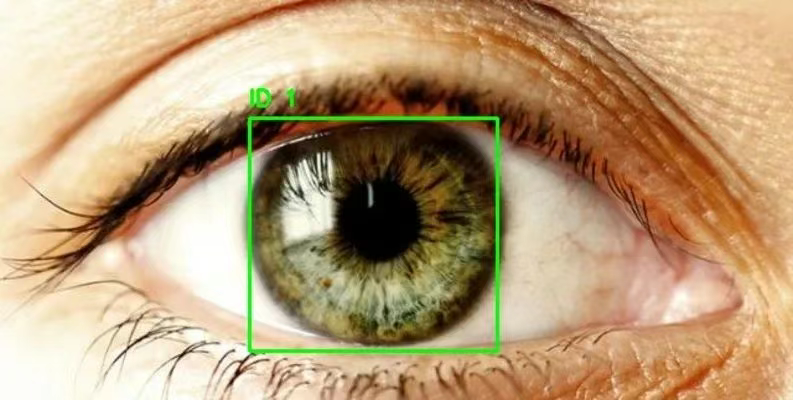
1. Eye Detection glasses detection dataset
Eye Detection is an eye detection dataset that contains nearly 2,000 clearly labeled eye area images, which can be used to train target detection models such as RCNN and YOLO to track and detect eye areas. This dataset can be used to build cataract detection models, eye tracking models, etc.
Direct use:https://go.hyper.ai/5IUPr
2. Yambda music recommendation dataset
Yambda-5B is a large-scale multimodal music analysis dataset that aims to provide training and evaluation resources for large language models (LLMs) such as music recommendation, information retrieval, and sorting. The dataset contains 4.79 billion interactions (including listening, liking, and unliking), covering 1 million users and 9.39 million tracks. It is currently one of the largest public music recommendation datasets.
Direct use:https://go.hyper.ai/VSL3J
3. 4x Satellite satellite imagery dataset
This dataset is a high-resolution satellite image dataset containing pairs of high-resolution (HR) and low-resolution (LR) satellite images, designed for the 4x super-resolution task.
Direct use:https://go.hyper.ai/TyCeW
4. MedXpertQA medical reasoning dataset
The dataset contains 4,460 sample data, integrating text and image data, covering tasks such as medical question answering, clinical diagnosis, treatment plan recommendation, and basic medical knowledge understanding. It supports the research and development of complex medical decision-making capabilities and is suitable for fine-tuning and evaluation of medium-scale models in the medical field.
Direct use:https://go.hyper.ai/YGW7J
5. Animal Sounds Animal Sounds Dataset
The dataset contains about 10,800 samples, covering audio of seven species, including birds (such as long-tailed tits and zebra finches), dogs, Egyptian fruit bats, giant otters, macaques, and killer whales. Each audio is 1-5 seconds long, which is suitable for lightweight model training and fast experiments.
Direct use:https://go.hyper.ai/asUR4
6. GeMS Chemical Mass Spectrometry Dataset
The dataset contains hundreds of millions of mass spectra (such as 2 billion in the GeMS-C1 subset), including structured numerical data (mass-to-charge ratio-intensity pairs of mass spectra) and metadata (such as spectral sources, experimental conditions, etc.). It is one of the largest public mass spectrometry datasets currently available and can support ultra-large-scale model training.
Direct use:https://go.hyper.ai/yXI9M
7. DeepTheorem theorem proving dataset
DeepTheorem is a mathematical reasoning dataset that aims to enhance the mathematical reasoning capabilities of large language models (LLMs) through informal theorem proofs based on natural language. The dataset contains 121,000 IMO-level informal theorems and proofs covering multiple mathematical fields. Each theorem-proof pair is strictly annotated.
Direct use:https://go.hyper.ai/fjnad
8. SynLogic Inference Dataset
SynLogic aims to enhance the logical reasoning capabilities of large language models (LLMs) through reinforcement learning with verifiable rewards. The dataset contains 35 diverse logical reasoning tasks with automatic verification, making it well suited for reinforcement learning training.
Direct use:https://go.hyper.ai/iF5f2
9. Mixture-of-Thoughts Reasoning Dataset
Mixture-of-Thoughts is a multi-domain reasoning dataset that integrates high-quality reasoning tracks in three major fields: mathematics, programming, and science. It aims to train large language models (LLMs) to perform reasoning step by step. Each sample in this dataset contains a messages field that stores the reasoning process in the form of multiple rounds of dialogue, supporting the model to learn step-by-step deduction capabilities.
Direct use:https://go.hyper.ai/7Qo2l
10. Llama-Nemotron Inference Dataset
The dataset contains approximately 22.06 million mathematical data, approximately 10.10 million code data, and the rest is data in fields such as science and instruction following. The data is collaboratively generated by multiple models such as Llama-3.3-70B-Instruct, DeepSeek-R1, and Qwen-2.5, covering diverse reasoning styles and problem-solving paths to meet the diverse needs of large-scale model training.
Direct use:https://go.hyper.ai/4V52g
Selected Public Tutorials
This week we have compiled 4 categories of quality public tutorials:
*AI for Science Tutorials: 4
* Image processing tutorials: 4
*Code Generation Tutorials: 3
*Voice interaction tutorials: 2
AI for Science Tutorial
1. Aurora large-scale atmospheric basic model Demo
Aurora significantly reduces computational costs while outperforming existing operational forecasting systems, promoting widespread access to high-quality climate and weather information. Aurora has been shown to be approximately 5,000 times faster than the most advanced numerical forecasting system, IFS.
This tutorial uses a single-card A6000 as the resource. After starting the container, click the API address to enter the Web interface.
Run online:https://go.hyper.ai/416Xs
2. One-click deployment of MedGemma-4b-it multimodal medical AI model
MedGemma-4b-it is a multimodal medical AI model designed specifically for the medical field. It is an instruction-tuned version of the MedGemma suite. It uses the SigLIP image encoder, which is specially pre-trained and uses data covering de-identified medical images, including chest X-rays, dermatology images, ophthalmology images, and histopathology sections.
This tutorial uses a single RTX 4090 card as the resource. After starting the container, click the API address to enter the web interface.
Run online:https://go.hyper.ai/31RKp
3. One-click deployment of MedGemma-27b-text-it medical reasoning model
This model focuses on the processing of clinical texts, and is particularly good at patient triage and decision-making assistance, providing doctors with rapid and valuable patient condition information to facilitate the formulation of efficient treatment plans.
This tutorial uses dual-SIM A6000 resources. Open the link below to deploy it with one click.
Run online:https://go.hyper.ai/2mDmF
4. vLLM+Open WebUI deployment II-Medical-8B medical reasoning model
The model is based on the Qwen/Qwen3-8B model and optimizes model performance by using SFT (supervised fine-tuning) using a medical-specific inference dataset and training DAPO (a possible optimization method) on a hard inference dataset.
The computing resources used in this tutorial are a single RTX 4090 card.
Run online:https://go.hyper.ai/1Qvwo
Image Processing Tutorial
1. DreamO: a unified image customization framework
Based on the DiT (Diffusion Transformer) architecture, DreamO integrates a variety of image generation tasks, supports complex functions such as costume change (IP), face change (ID), style transfer (Style), multi-subject combination, and realizes multi-condition control through a single model.
This tutorial uses resources for a single card A6000.
Run online:https://go.hyper.ai/zGGbh
2. BAGEL: A unified model for multimodal understanding and generation
BAGEL-7B-MoT is designed to uniformly handle the understanding and generation tasks of multimodal data such as text, images, and videos. BAGEL has demonstrated comprehensive capabilities in multimodal tasks such as multimodal understanding and generation, complex reasoning and editing, world modeling and navigation. Its main functions are visual understanding, text-to-image generation, image editing, etc.
This tutorial uses dual-card A6000 computing resources and provides Image Generation, Image Generation with Think, Image Editing, Image Edit with Think, and Image Understanding for testing.
Run online:https://go.hyper.ai/76cEZ

3. ComfyUI Flex.2-preview workflow online tutorial
Flex.2-preview can generate high-quality images based on input text descriptions, supports text input of up to 512 tokens, and supports understanding complex descriptions to generate corresponding image content. It also supports repairing or replacing specific areas of the image. The user provides the repair image and repair mask, and the model generates new image content in the specified area.
This tutorial uses a single RTX 4090 card as the resource and only supports English prompts.
Run online:https://go.hyper.ai/MH5qY
4. ComfyUI LanPaint Image Restoration Workflow Tutorial
LanPaint is an open-source image local restoration tool that uses an innovative reasoning method to adapt to a variety of stable diffusion models (including custom models) without additional training, thereby achieving high-quality image restoration. Compared with traditional methods, LanPaint provides a lighter-weight solution that significantly reduces the demand for training data and computing resources.
This tutorial uses a single RTX 4090 card. You can quickly clone the model by opening the link below.
Run online:https://go.hyper.ai/QAuag
Code Generation Tutorial
1. vLLM+Open WebUI Deployment Seed-Coder-8B-Instruct
Seed-Coder-8B-Instruct is a lightweight but powerful open source code language model. It is a fine-tuned version of the Seed-Coder series of instructions. With minimal manpower, LLM can effectively manage code training data on its own, greatly enhancing coding capabilities. The model is built on the Llama 3 architecture, has 8.2 B parameters, and supports 32 K tokens long context.
The computing resources used in this tutorial are a single RTX 4090 card.
Run online:https://go.hyper.ai/BnO32
2. Mellum-4b-base is a model designed for code completion
Mellum-4b-base is designed for code understanding, generation, and optimization tasks. The model demonstrates excellent capabilities in the entire software development process and is suitable for scenarios such as AI-enhanced programming, intelligent IDE integration, educational tool development, and code research.
This tutorial uses a single RTX 4090 card as the resource, and the model is only used to optimize the code.
Run online:https://go.hyper.ai/2iEWz
3. One-click deployment of OpenCodeReasoning-Nemotron-32B
This model is a high-performance large language model designed for code reasoning and generation. It is the flagship version of the OpenCodeReasoning (OCR) model suite and supports a context length of 32K tokens.
The computing resources used in this tutorial are dual-card A6000.
Run online:https://go.hyper.ai/jhwYd
Voice Interaction Tutorial
1. VITA-1.5: Multimodal Interaction Model Demo
ITA-1.5 is a multimodal large-scale language model that integrates vision, language, and speech, and is designed to achieve real-time visual and speech interaction at a level similar to GPT-4o. VITA-1.5 significantly reduces interaction latency from 4 seconds to 1.5 seconds, significantly improving user experience.
This tutorial uses a single-card A6000 as the resource. Currently, AI interaction only supports Chinese and English.
Run online:https://go.hyper.ai/WTcdM
2. Kimi-Audio: Let AI understand humans
Kimi-Audio-7B-Instruct is an open source audio infrastructure model that can handle various audio processing tasks within a single unified framework. It can handle various tasks such as automatic speech recognition (ASR), audio question answering (AQA), automatic audio captioning (AAC), speech emotion recognition (SER), sound event/scene classification (SEC/ASC), and end-to-end voice dialogue.
This tutorial uses resources for a single card A6000.
Run online:https://go.hyper.ai/UBRBP
This week's paper recommendation
1. A foundation model for the Earth system
This paper proposes the Aurora model, a large-scale base model trained on more than one million hours of diverse geophysical data, which outperforms existing operational forecasting systems in air quality, ocean waves, tropical cyclone tracks, and high-resolution weather forecasting.
Paper link:https://go.hyper.ai/ibyij
2. Paper2Poster: Towards Multimodal Poster Automation from Scientific Papers
Academic paper poster generation is a critical and challenging task in scientific communication, which requires compressing long interleaved documents into a single page of visually coherent content. To address this challenge, this paper introduces the first benchmark and measurement suite for academic paper poster generation, which is able to transform a 22-page paper into a final editable pptx poster.
Paper link:https://go.hyper.ai/Q4cQG
3. ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
Whether reinforcement learning truly expands the reasoning ability of the model is still controversial. This paper proposes a new training method, ProRL, which combines KL divergence control, reference policy reset and a diverse task suite, providing new insights for a better understanding of the conditions under which reinforcement learning meaningfully expands the reasoning boundaries of language models.
Paper link:https://go.hyper.ai/62DUb
4. Unsupervised Post-Training for Multi-Modal LLM Reasoning via GRPO
This study uses GRPO, a stable and scalable online reinforcement learning algorithm, to achieve continuous self-improvement without external supervision, and proposes MM-UPT, a simple and effective unsupervised post-training framework for multimodal large language models. Experimental results show that MM-UPT significantly improves the reasoning ability of Qwen2.5-VL-7B.
Paper link:https://go.hyper.ai/W5nO5
5. The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
This paper aims to overcome a major obstacle when using large language models (LLMs) for reasoning in large-scale reinforcement learning (RL), namely the collapse of policy entropy. To this end, the researchers proposed two simple and effective methods: Clip-Cov and KL-Cov. The former clips high covariance tokens, while the latter imposes a KL penalty on these tokens. Experimental results show that these methods can promote exploration behavior, thereby helping the policy escape entropy collapse and achieve better downstream performance.
Paper link:https://go.hyper.ai/rFSoq
More AI frontier papers:https://go.hyper.ai/UuE1o
Community article interpretation
Drawing on the breakthroughs made by the GPT series in the field of language, a research team from the Institute of Organic Chemistry and Biochemistry of the Czech Academy of Sciences mined 700 million MS/MS spectra from the Global Natural Products Social Molecular Network (GNPS), successfully constructed the largest mass spectrometry dataset in history, GeMS, and trained a Transformer model DreaMS with 116 million parameters.
View the full report:https://go.hyper.ai/P9qvl
In order to better connect cutting-edge research with application scenarios, HyperAI will hold the 7th Meet AI Compiler Technology Salon in Beijing on July 5. We are fortunate to have invited many senior experts from AMD, Peking University, Muxi Integrated Circuit, etc. to share their best practices and trend analysis for AI compilers.
View the full report:https://go.hyper.ai/FPxw2
Dr. Liang Haojian from the Institute of Space Information Innovation of the Chinese Academy of Sciences gave a speech titled "Research on Optimization Methods of Urban Emergency Fire Facility Configuration Based on Hierarchical Deep Reinforcement Learning" at the 2025 Academic Annual Meeting of the Geographical Model and Geographic Information Analysis Professional Committee of the Chinese Geographical Society. Taking the optimization of urban fire facility layout as the starting point, the classic optimization methods in the field of geospatial optimization were systematically reviewed, and the advantages and potential of optimization methods based on deep reinforcement learning (DRL) were introduced in detail. This article is a transcript of the highlights of Dr. Liang Haojian's sharing.
View the full report:https://go.hyper.ai/xvnAI
The Show Lab of the National University of Singapore released a universal consistency plug-in, OmniConsistency, which uses a large-scale diffusion transformer (DiT) on May 28, 2025. It is a fully plug-and-play design, compatible with LoRA of any style under the Flux framework, and based on a consistency learning mechanism for stylized image pairs to achieve robust generalization.
View the full report:https://go.hyper.ai/etmWQ
Popular Encyclopedia Articles
1. DALL-E
2. Human-machine loop
3. Reverse sort fusion
4. Bidirectional long short-term memory
5. Large-scale Multi-task Language Understanding
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
June deadline for the summit
S&P 2026 June 6 7:59:59
ICDE 2026 June 19 7:59:59
One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week's editor's selection. If you want to include hyper.ai For resources on the official website, you are also welcome to leave a message or contribute to tell us!
See you next week!








