Command Palette
Search for a command to run...
Orpheus TTS Says Goodbye to Mechanical Feeling, real-time Conversation Is As Natural As Friends; OpenCodeReasoning Massive Data Open Source, Unlocking a New Level of Programming Reasoning

Text-to-speech models have made significant progress in recent years, but existing models still have many limitations in practical applications. Most models can only generate single-tone speech and cannot generate emotional speech. To meet this challenge, Canopy Labs has open-sourced the text-to-speech model Orpheus-TTS.
Orpheus-TTS can generate natural, emotional and close to human-level speech.It has zero-sample voice cloning capabilities and can imitate specific voices without pre-training.Users can control the emotional expression of voice through tags to enhance the realism of voice. The model has a latency as low as about 200 milliseconds, which helps users to carry out real-time applications.
at present,HyperAI is now online「Orpheus TTS: A multilingual text-to-speech model",Come and try it~
Online use:https://go.hyper.ai/FGexv
From May 26 to May 29, hyper.ai official website updates:
* High-quality public datasets: 10
* High-quality tutorials: 12
* Community article selection: 3 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in June: 3
Visit the official website:hyper.ai
Selected public datasets
1. EMMA Multimodal Reasoning Benchmark Dataset
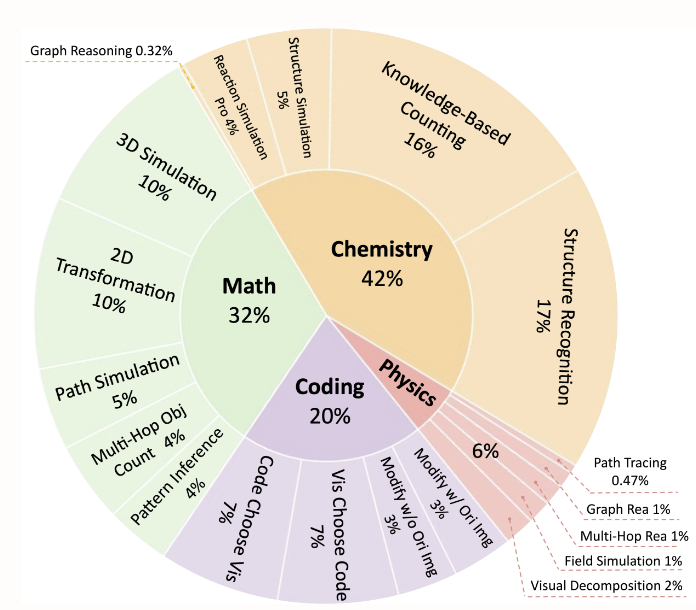
The dataset focuses on multimodal reasoning tasks in the fields of organic chemistry (42%), mathematics (32%), physics (6%), and programming (20%). It contains 2,788 questions, of which 1,796 are newly constructed samples. It supports fine-grained task division and aims to promote the joint understanding of images and texts. The data task types include chemical reaction simulation, mathematical graphic reasoning, physical path tracing, programming visualization, etc.
Direct use:https://go.hyper.ai/HtL1N
2. Facial Expressions Facial expression YOLO format detection dataset
This dataset is a YOLO format dataset for emotion recognition, designed for the training and evaluation of target detection and classification models. The dataset contains about 70,000 images, covering 9 facial expression categories, taking into account both basic and complex emotions, and is suitable for application scenarios such as emotion recognition in computer vision, human-computer interaction, mental health analysis, and intelligent monitoring.
Direct use:https://go.hyper.ai/K6iIH

3. GeneralThought-430K Large-Scale Reasoning Dataset
The dataset contains 430,000 samples, covering problems in the fields of mathematics, code, physics, chemistry, natural sciences, humanities and social sciences, engineering technology, etc., including questions from multiple reasoning models, reference answers, reasoning trajectories, final answers and other metadata.
Direct use:https://go.hyper.ai/xdSzd
4. S1k-1.1 Mathematical Reasoning Dataset
This dataset is a mathematical problem reasoning dataset, containing 1,000 samples. It focuses on mathematical problems and reasoning trajectories, covering multiple mathematical fields such as algebra, geometry, probability, etc. Each sample contains a problem description, problem-solving steps, answers, and reasoning trajectories generated by DeepSeek r1.
Direct use:https://go.hyper.ai/MtvcV
5. HPA Human Protein Atlas Dataset
This dataset is composed of data from the Human Protein Atlas (HPA) database, which contains a large number of high-resolution confocal microscopy images, covering the spatial distribution of thousands of human proteins in different organelles. It is an important public resource for protein subcellular localization research.
Direct use:https://go.hyper.ai/Dhuwt
6. ZeroSearch Question Answering Dataset
The dataset contains about 170,000 samples, covering scientific knowledge, historical events, film and television entertainment, geography and humanities, etc. It also covers factual questions, definition questions, true and false questions, etc., which are suitable for training small and medium-sized question-answering models. Through carefully designed question-answer pairs, it aims to evaluate the model's common sense reasoning, fact memory and logical inference capabilities, and provides standardized training and testing resources for the field of natural language processing.
Direct use:https://go.hyper.ai/OkvBx
7. SocialMaze logical reasoning benchmark dataset
This dataset is a social reasoning benchmark dataset that focuses on hidden role reasoning tasks in multi-agent interaction scenarios. It aims to evaluate the logical reasoning, deception detection and multi-round dialogue understanding capabilities of large language models (LLMs) in complex social environments, and provides a standardized testing platform for studying the social reasoning capabilities of LLMs.
Direct use:https://go.hyper.ai/Cch64
8. OpenCodeReasoning Programming Reasoning Dataset
The dataset aims to provide high-quality programming reasoning training data for large language models (LLMs) to promote the improvement of code generation and logical reasoning capabilities. The dataset contains 735,255 samples, covering 28,319 unique programming questions, and is one of the largest reasoning programming datasets currently.
Direct use:https://go.hyper.ai/ofjBJ
9. MLDR Multilingual Document Retrieval Dataset
The dataset covers 13 different languages. It is a multilingual long document retrieval dataset built based on Wikipedia, Wudao and mC4 multilingual corpus. It aims to support the research and development of cross-language long text retrieval tasks.
Direct use:https://go.hyper.ai/Le0G8
10. MP-20-PXRD Atomic Materials Benchmark Dataset
The dataset consists of materials sampled from the Materials Project database, with a maximum of 20 atoms in the unit cell. It contains 45,229 materials, which are used for training, validation, and testing in the ratio of 90%, 7.5%, and 2.5%.
Direct use:https://go.hyper.ai/bUKbv
Selected Public Tutorials
This week we have compiled 4 categories of quality public tutorials:
* Audio Synthesis Tutorials: 5
* Image generation tutorials: 3
* Video synthesis tutorials: 2
* Mathematical Reasoning Tutorials: 2
Audio Synthesis Tutorial
1. Orpheus TTS: A multilingual text-to-speech model
Orpheus-TTS can generate natural, emotional, and near-human speech, with zero-sample voice cloning capabilities, and can imitate specific voices without pre-training. Users can control the emotional expression of the voice through labels to enhance the realism of the voice. The latency of Orpheus TTS is as low as about 200 milliseconds, making it suitable for real-time applications.
This tutorial uses a single RTX 4090 card as the resource. After starting the container, click the API address to enter the web interface.
Run online:https://go.hyper.ai/FGexv
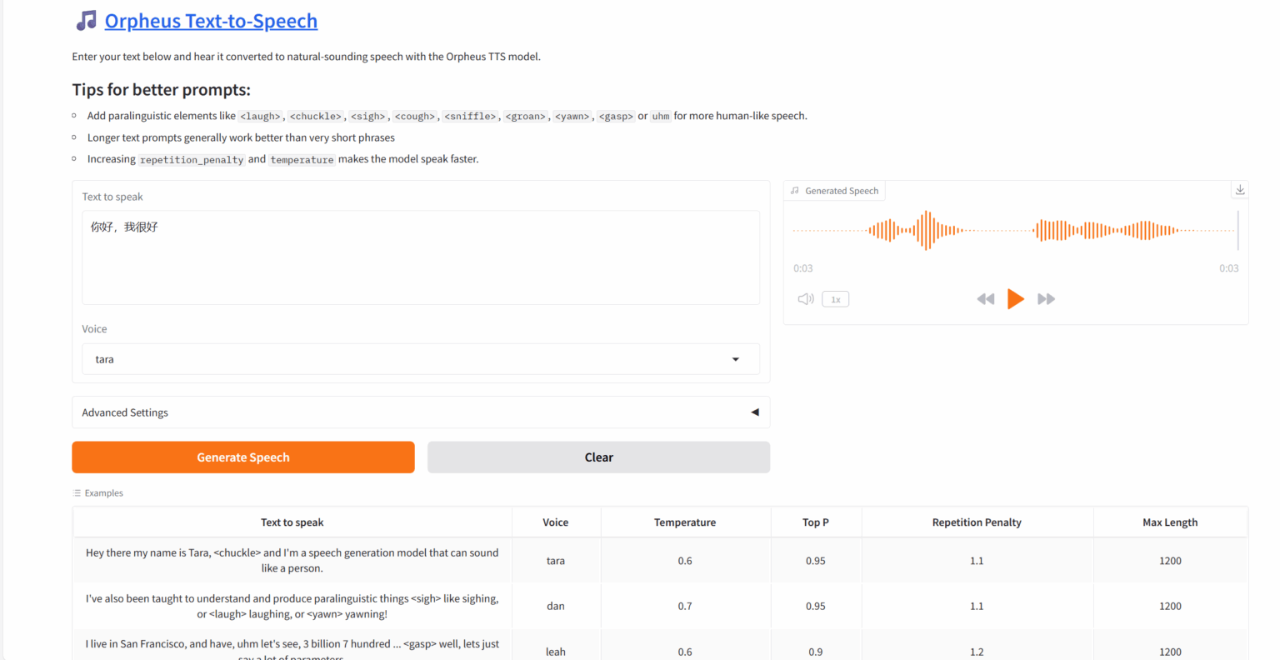
2. ACE-Step: Basic model for music generation
ACE-Step-v1-3.5B synthesizes up to 4 minutes of music in just 20 seconds on an A100 GPU, 15 times faster than the LLM-based baseline, while achieving excellent musical coherence and lyric alignment in terms of melody, harmony, and rhythm metrics. In addition, the model preserves fine acoustic details and supports advanced control mechanisms such as voice cloning, lyric editing, remixing, and track generation.
The computing resources used in this tutorial are a single RTX 4090 card. After starting the container, click the API address to enter the web interface.
Run online:https://go.hyper.ai/Qjxmu
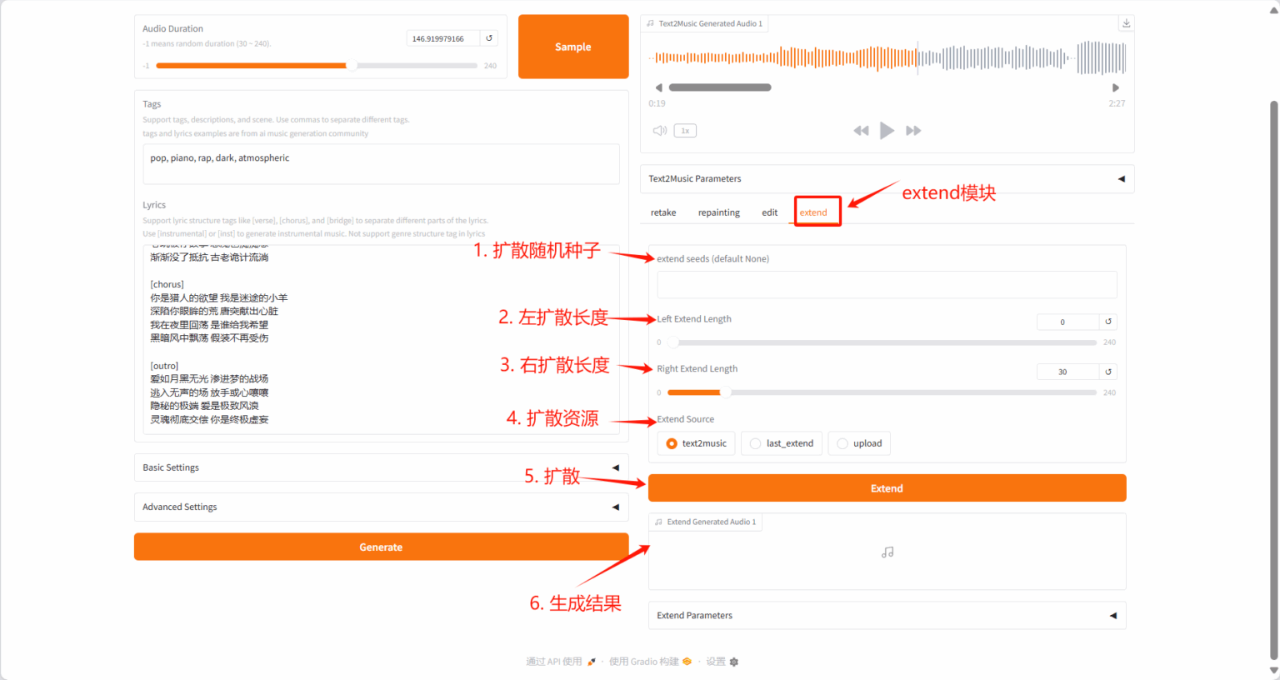
3. One-click deployment of MegaTTS3
MegaTTS 3 is a TTS system with an innovative sparsely aligned guided latent diffuse transformer (DiT) algorithm that achieves state-of-the-art zero-shot TTS voice quality and supports highly flexible control of accent strength. It is mainly used to convert input text into high-quality, natural and fluent speech output.
This tutorial uses a single RTX 4090 card. You can deploy it with one click using the link below.
Run online:https://go.hyper.ai/rujKs
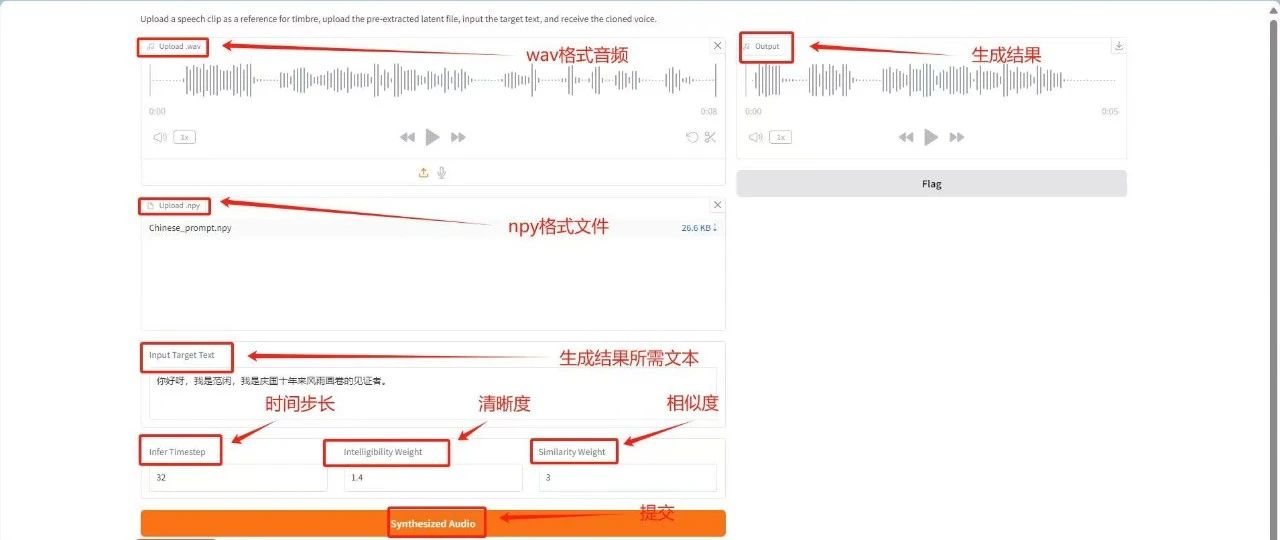
4. Parakeet-tdt-0.6b-v2 speech recognition
Parakeet-tdt-0.6b-v2 is based on the FastConformer encoder architecture and TDT decoder, and can efficiently transcribe up to 24 minutes of English audio clips at a time. This model focuses on high-precision, low-latency English speech transcription tasks and is suitable for real-time English speech-to-text scenarios (such as customer service conversations, meeting records, voice assistants, etc.).
This tutorial uses a single RTX 4090 computing resource, and the model only supports English speech recognition.
Run online:https://go.hyper.ai/pWmfu
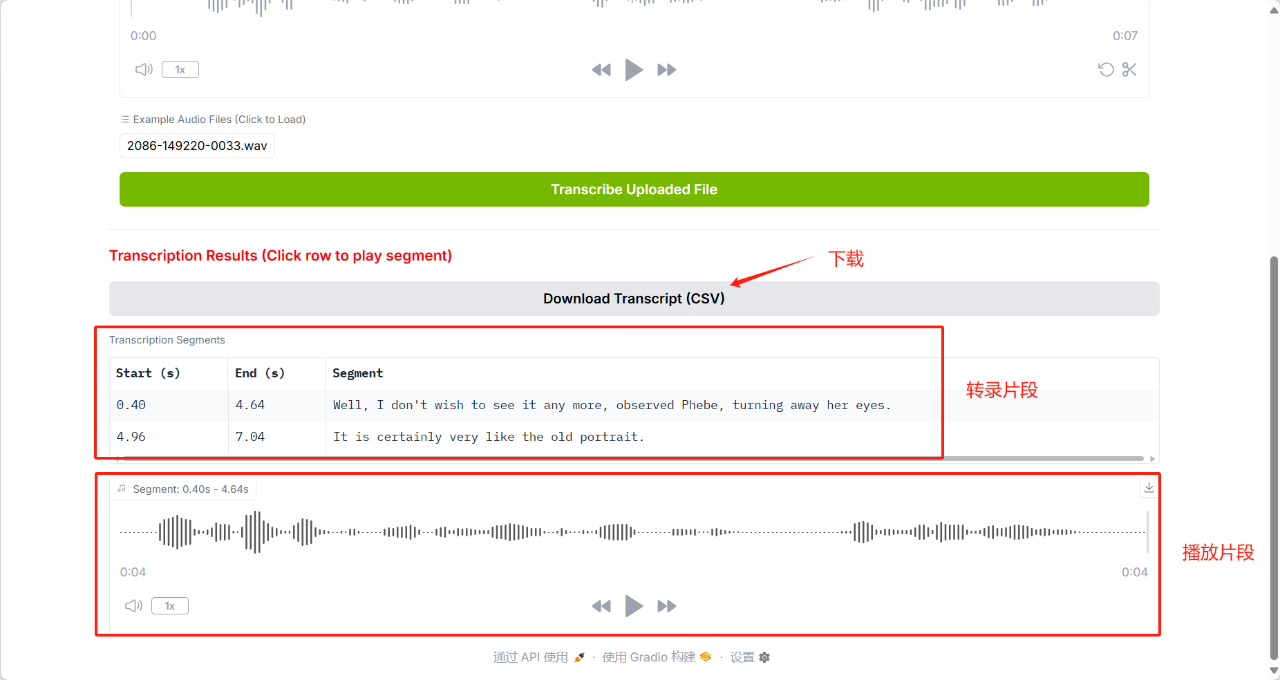
5. Dia-1.6B: Emotional Speech Synthesis Demo
Dia-1.6B can generate highly realistic conversations directly from text scripts, and supports audio-based emotion and tone control. It can also generate non-verbal communication sounds such as laughter, coughing, throat clearing, etc., making the conversation more natural and vivid. This project also supports uploading your own audio samples, and the model will generate similar voices based on the samples to achieve zero-sample voiceprint cloning.
This tutorial uses resources for a single RTX 4090 card and currently only supports English generation.
Run online:https://go.hyper.ai/5J3lp
Image Generation Tutorial
1. KV-Edit background consistency image editing
KV-Edit is a training-free image editing method that strictly maintains background consistency between the original and edited images, and achieves impressive performance on various editing tasks including object addition, removal, and replacement.
This tutorial uses a single RTX A6000 card. Click the link below to quickly clone the model.
Run online:https://go.hyper.ai/wo2xJ

2. Sana High Resolution Image Synthesis
Sana is a text-to-image framework that can efficiently generate images with resolutions up to 4096 × 4096. Sana can synthesize high-resolution, high-quality images at a very fast speed with strong text-image alignment capabilities.
This tutorial uses the Sana-1600M-1024px model for demonstration, and the computing power resource uses a single RTX 4090 card.
Run online:https://go.hyper.ai/tiP36

3. In-Context Edit: Command-driven image generation and editing
In-Context Edit is an efficient framework for instruction-based image editing. Compared with previous methods, ICEdit has only 1% of trainable parameters (200M) and 0.1% of training data (50k), showing strong generalization ability and capable of handling various editing tasks. Compared with commercial models such as Gemini and GPT4o, it is more open source, lower cost, faster and more powerful.
This tutorial uses a single RTX 4090 card as a resource. If you want to achieve the official mentioned 9 seconds to generate images, you will need a graphics card with higher configuration. Currently, only English text descriptions are supported.
Run online:https://go.hyper.ai/Ytv6C

Video Generation Tutorial
1. TransPixeler: Generating RGBA Video from Text
TransPixeler retains the advantages of the original RGB model and achieves strong alignment between RGB and alpha channels with limited training data, which can effectively generate diverse and consistent RGBA videos, thus promoting the possibility of visual effects and interactive content creation.
This tutorial uses a single RTX A6000 card as the resource, and the text description currently only supports English.
Run online:https://go.hyper.ai/1OFP9

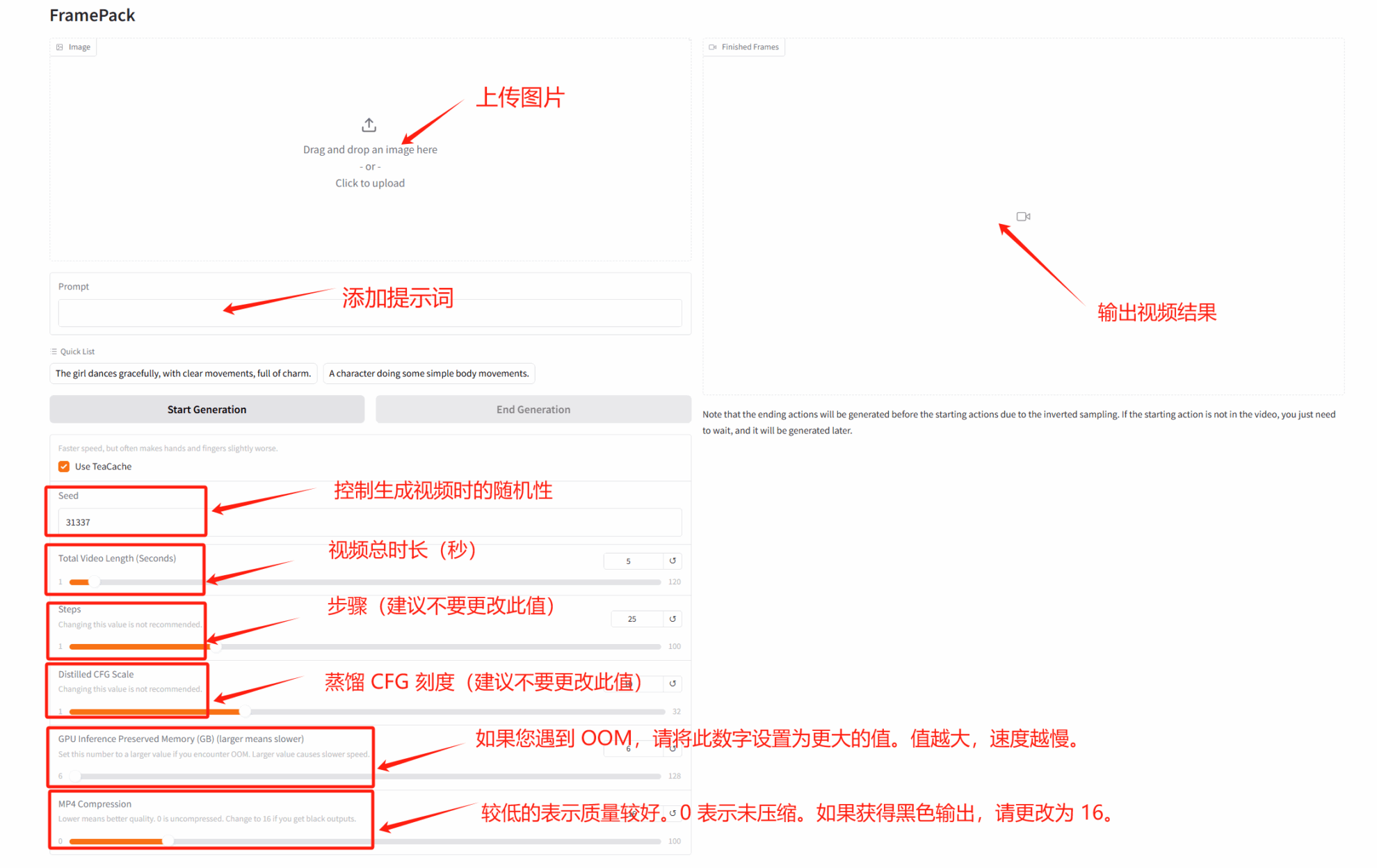
2. FramePack low video memory video generation demo
FramePack uses an innovative neural network architecture to effectively solve problems such as high video memory usage, drift, and forgetting in traditional video generation, and significantly reduces hardware requirements.
This tutorial uses RTX 4090 as the computing resource. After starting the container, click the API address to enter the web interface.
Run online:https://go.hyper.ai/rYELB
Mathematical Reasoning Tutorial
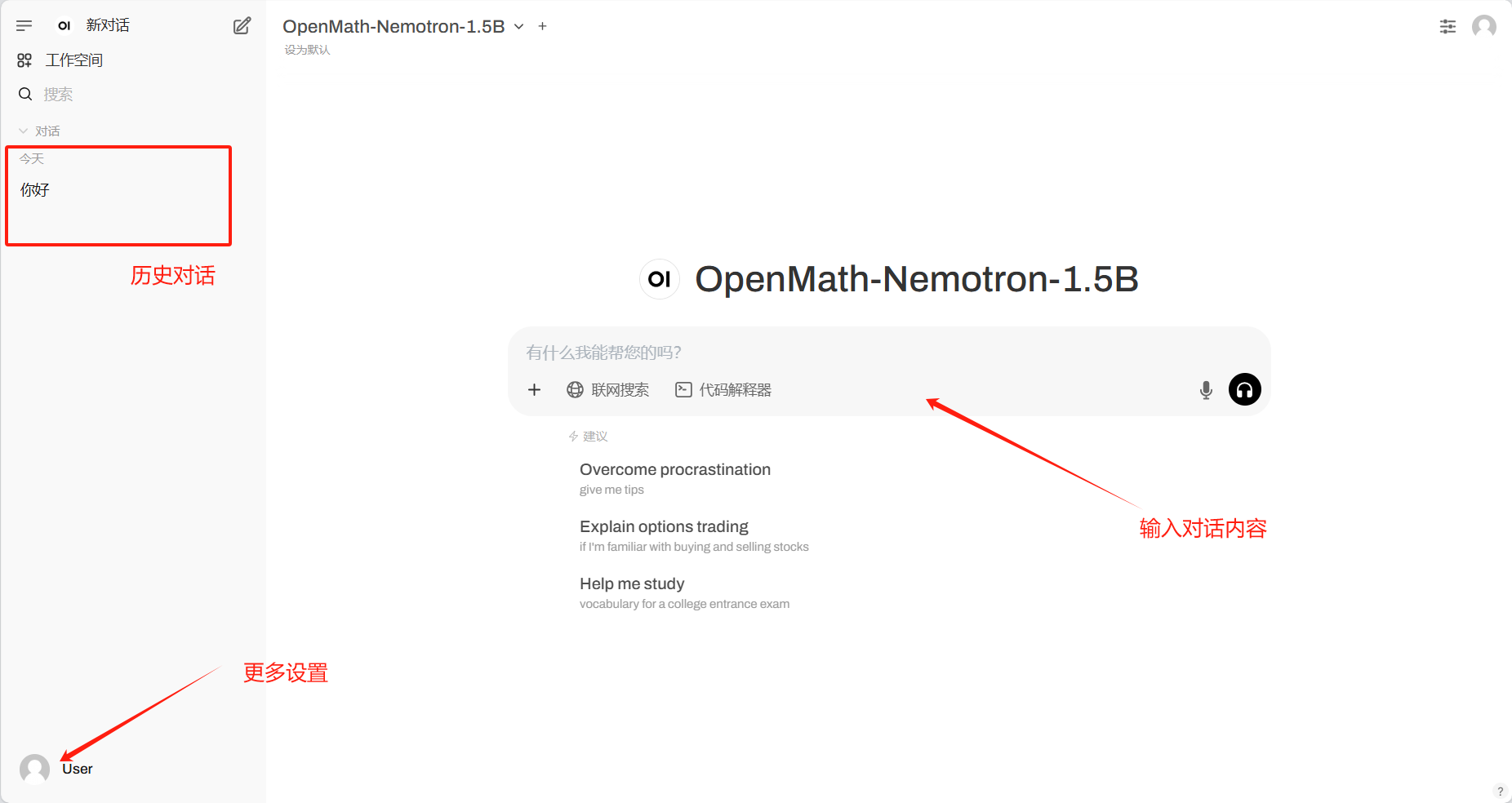
1. Deploy OpenMath-Nemotron-1.5B using vLLM+Open WebUI
The model was created by fine-tuning Qwen/Qwen2.5-Math-1.5B on the OpenMathReasoning dataset. The model achieves state-of-the-art results on popular math benchmarks and is now licensed for commercial use.
The computing resources of this tutorial use a single RTX 4090 card, only support calculating mathematical problems, and the answers are in English.
Run online:https://go.hyper.ai/rasEm
2. Deploy DeepSeek-Prover-V2-7B using vLLM+Open WebUI
The most significant feature of DeepSeek-Prover-V2-7B is its ability to seamlessly combine informal mathematical reasoning (i.e., the reasoning method commonly used by humans) with rigorous formal proofs, allowing the model to think as flexibly as humans and to demonstrate as rigorously as computers, thus achieving an integrated fusion of mathematical reasoning.
This tutorial uses a single RTX A6000 card as the resource. This model only supports mathematical reasoning problems.
Run online:https://go.hyper.ai/JYCI2
Community Articles
1. Published in Nature sub-journal! Huazhong University of Science and Technology proposed a fusion strategy AI model to achieve accurate prediction of mortality risk of septic shock in multiple centers and across specialties
The research team of Tongji Hospital and School of Medical and Health Management affiliated to Tongji Medical College of Huazhong University of Science and Technology has innovatively proposed a TOPSIS-based classification fusion (TCF) model to predict the risk of death within 28 days for patients with septic shock in the ICU. The model integrates 7 machine learning models and has high stability and accuracy in cross-professional and multi-center validation.
View the full report:https://go.hyper.ai/K42Fp
2. Oxford University and others have dug deep into the health data of 7.46 million adults to develop early screening algorithms, and achieved early prediction of 15 types of cancer based on blood indicators
Queen Mary University of London and Oxford University research teams have collaborated to develop two new cancer prediction algorithms based on anonymous electronic health records of 7.46 million adults in England: the basic algorithm integrates traditional clinical factors and symptom variables, and the advanced algorithm further incorporates blood indicators such as complete blood cell count and liver function tests. This article is a detailed interpretation and sharing of the research paper.
View the full report:https://go.hyper.ai/12a8Z
3. Selected for ICML 2025, Tsinghua/Renmin University/Byte proposed the first cross-molecule unified generation framework UniMoMo to achieve multi-type drug molecule design
Professor Liu Yang's team from Tsinghua University, together with the Renmin University and ByteDance team, jointly proposed a cross-molecule unified generation framework UniMoMo. This framework uniformly represents different types of molecules based on molecular fragments, and realizes the design of different binding molecules for the same target. This article is a detailed interpretation and sharing of the research.
View the full report:https://go.hyper.ai/e96ci
Popular Encyclopedia Articles
1. Gated Recurrent Unit
2. Reverse sort fusion
3. Three-dimensional Gaussian scattering
4. Case-Based Reasoning
5. Bidirectional long short-term memory
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:https://go.hyper.ai/wiki
June deadline for the summit
VLDB 2026 June 2 7:59:59
S&P 2026 June 6 7:59:59
ICDE 2026 June 19 7:59:59
One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!








