Command Palette
Search for a command to run...
Oxford University and Others Have Dug Deep Into the Health Data of 7.46 Million Adults to Develop Early Screening Algorithms, Achieving Early Prediction of 15 Types of Cancer Based on Blood Indicators

In the UK, cancer survival rates have long faced severe challenges, and clinical outcomes are at a low level among developed countries. Behind this situation is the objective reality that a large number of cancer patients are already in the middle or advanced stages when diagnosed, missing the best time for treatment. In 2011, the UK National Health Service (NHS) released a cancer strategy, which clearly proposed the goal of diagnosing 75% of cancer at a curable stage (stage 1 or 2), aiming to improve the status quo by optimizing the diagnostic process. This strategy takes primary care as a breakthrough, improves the effectiveness of early diagnosis through predictive algorithms, and points the way for innovation in cancer diagnosis and treatment models.
In this context, cancer prediction algorithms developed based on large-scale primary care electronic health databases have emerged, such as the QCancer score model.The absolute probability of an individual having undiagnosed cancer is assessed by integrating multiple factors such as age, gender, poverty status, smoking, drinking, family history, and symptoms.National clinical guidelines recommend that when the positive predictive value of cancer exceeds a certain threshold (such as 3%), clinicians should consider further examination or referral. These algorithms are integrated into primary care clinical computer systems to assess cancer risk in real time when patients are seen, providing data support for clinical decision-making.
As of 2020, only slightly more than half of cancers in England are diagnosed at stage 1 or 2, which is still a significant gap from the target of 75% by 2028. In recent years, advances in blood testing technology have provided new directions for breaking through this bottleneck.Many studies have shown that abnormal changes in blood indicators such as hemoglobin, white blood cell count, and platelets may appear several years earlier than clinical symptoms.This suggests its potential as an early warning biomarker for cancer, prompting researchers to explore incorporating blood test data into predictive models to improve the algorithm's ability to identify cancers with no symptoms or atypical symptoms.
Based on this, Queen Mary University of London and the Oxford University research team collaborated to develop two new cancer prediction algorithms based on the anonymous electronic health records of 7.46 million adults in England:The basic algorithm integrates traditional clinical factors and symptom variables, and the advanced algorithm further incorporates blood indicators such as complete blood count and liver function tests.
The study used a multinomial logistic regression model to model the male and female groups separately, not only realizing the prediction of the overall probability of cancer,It also enables for the first time individual risk assessments for 15 cancer types, including liver cancer and oral cancer.In 5 million independent validations, the new algorithm showed superior discrimination, calibration and sensitivity to existing models, providing a scientific basis for optimizing clinical decision-making processes and promoting early diagnosis of cancer. In addition, the team proposed that this method is the first algorithm used in primary care to estimate the probability of liver cancer that has not yet been diagnosed.
The relevant research results have been published in the internationally renowned journal Nature Communications under the title "Development and external validation of prediction algorithms to improve early diagnosis of cancer".

Paper address:
The open source project "awesome-ai4s" brings together more than 100 AI4S paper interpretations and provides massive data sets and tools:
https://github.com/hyperai/awesome-ai4s
Dual database and multi-cohort study: sample size exceeds one million, building data support in all directions
The data for this study were obtained from two electronic medical record databases: QResearch (version 48) and the Clinical Practice Research Datalink (CPRD Gold).The former is based on the EMIS system and covers England, while the latter is based on the Vision system and includes clinic data in Northern Ireland, Scotland and Wales, forming a geographically independent external validation cohort to ensure data diversity and representativeness.
In terms of the study population, as shown in the figure below, the QResearch clinic data in England were randomly divided into a development cohort of 7,464,507 people, including 129,715 new cases of cancer, a validation cohort of 2,637,184 people, including 44,984 new cases of cancer, and a CPRD validation cohort of 2,736,726 people, including 32,328 new cases of cancer.
The sample size of the three cohorts all exceeded one million, covering people aged 18-84.The data include blood system malignancies, breast cancer and common cancer types in the middle-aged and elderly, with a time span of January 1, 2015 to March 31, 2023, and a follow-up period of 2 years. The data focuses on patients who were not diagnosed with cancer at the time of enrollment, and ensures the accuracy of new cancer data by excluding those with "red flag symptoms" within 12 months before enrollment. The data covers age, gender, poverty, smoking, drinking, family history, symptoms, blood tests (complete blood cell count, liver function test) and other dimensions. Except for the slightly higher completeness of the self-reported race, smoking, drinking and BMI data of the England cohort, the baseline characteristics of each cohort are generally consistent, providing a balanced data basis for model development.
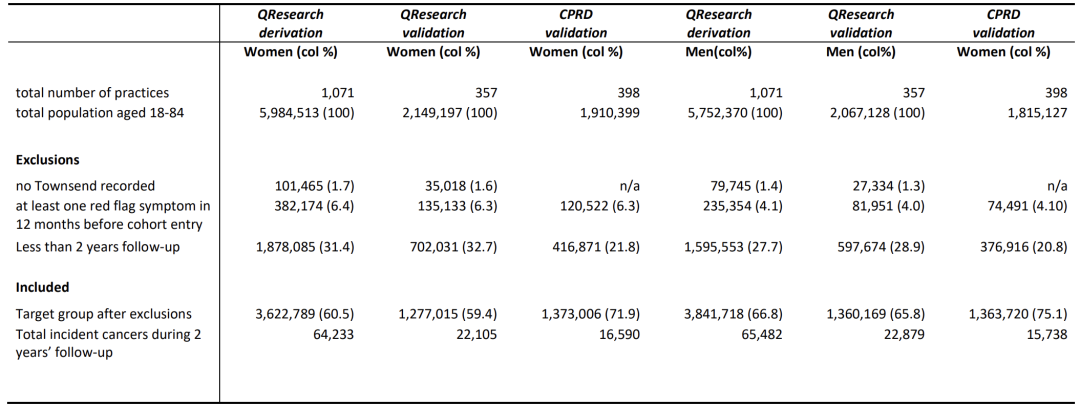
The study is based on four major data sources: general practitioners, hospitals, mortality rates, and cancer registries. It identifies 13 types of cancer already included in QCancer (lung cancer, colorectal cancer, etc.) and newly added liver cancer, oral-pharyngeal cancer, etc., a total of 15 types.Due to data limitations, the CPRD cohort is based only on the diagnosis recorded by general practitioners, forming a hierarchical verification system. These data have the characteristics of large sample size, wide geographical area, long time span, multiple predictive factors and strong clinical relevance. The prediction model is constructed by developing the cohort, and the universality and reliability of the model are evaluated with the help of validation cohorts in different regions and systems (especially the CPRD external cohort), ensuring the effectiveness and stability of the algorithm in real clinical scenarios, and providing data support for early diagnosis of cancer.
Cancer prediction model development: multinomial logistic regression modeling and multidimensional validation
In model development, the study screened candidate predictive variables based on existing algorithms and literature, covering demographic characteristics, smoking and drinking habits, family history of cancer, comorbidities, as well as symptoms and blood test results. Symptoms were subdivided into "red flag symptoms (strong cancer association, basis for urgent referral in clinical guidelines)" and non-specific symptoms, and blood tests included the values recorded in the first 2 years of the cohort to capture potential signals.
In order to ensure the scientificity and accuracy of the model,In the modeling, the researchers used multinomial logistic regression to estimate the coefficients of predictive variables for each cancer type and fitted the models for men and women.Missing values of drinking, smoking status and blood indicators were filled by chain equation multiple imputation (5 imputations for men and women + Rubin rule merging), and binary variables were coded in binary categories according to the general practitioner's diagnosis records. When fitting the model, variables with a significance level ≤ 0.01 were retained, and coefficients with a hazard ratio of 0.80-1.20 and insignificant were set to zero. A concise model was constructed by combining P value and effect size to avoid automatic variable selection based solely on statistical significance and ensure clinical relevance.
The study used fractional polynomials to simulate the nonlinear relationship between continuous variables and tested the interaction between predictive variables and age. When evaluating the optimism of the model, the researchers evaluated the optimism of the model through the heuristic shrinkage factor. The shrinkage values of both models were > 0.99, confirming that there was no overfitting. Finally, Model A (clinical factors + symptoms) and Model B (Model A + blood test results) were derived. The latter aims to improve the prediction accuracy by adding cancer-related signals.
Model evaluation was conducted in two independent validation cohorts. In addition to calculating AUROC to evaluate the discrimination ability,The researchers introduced a multi-category discrimination index (PDI, 12 categories for men/14 categories for women, including a cancer-free category) to measure the overall classification performance (the closer the PDI is to 1, the more accurate the discrimination).The consistency between the predicted probability and the actual value was tested through the calibration curve, slope and intercept. The special analysis of early cancer focused on cases from 2015 to 2020, with stage 1/stage 2 as the early definition, and stratified evaluation of subgroups such as geographic regions, races, and age groups to verify the universality of the model in different populations.
Application of cancer prediction model: liver cancer and oral cancer were included for the first time, and the relationship between blood indicators and cancer risk was analyzed
In the model application and experimental verification phase,This study conducted multi-dimensional verification of the variable association, discrimination ability, calibration effect and clinical value of the new predictive model.Compared with the existing QCancer algorithm, the new model adds four new medical conditions: cirrhosis, hepatitis B, hepatitis C (related to liver cancer) and AIDS (related to blood cancer and kidney cancer), supplements the association with family history of lung cancer/blood cancer, and seven cross-cancer symptoms such as itching, bruising, and abdominal lumps.
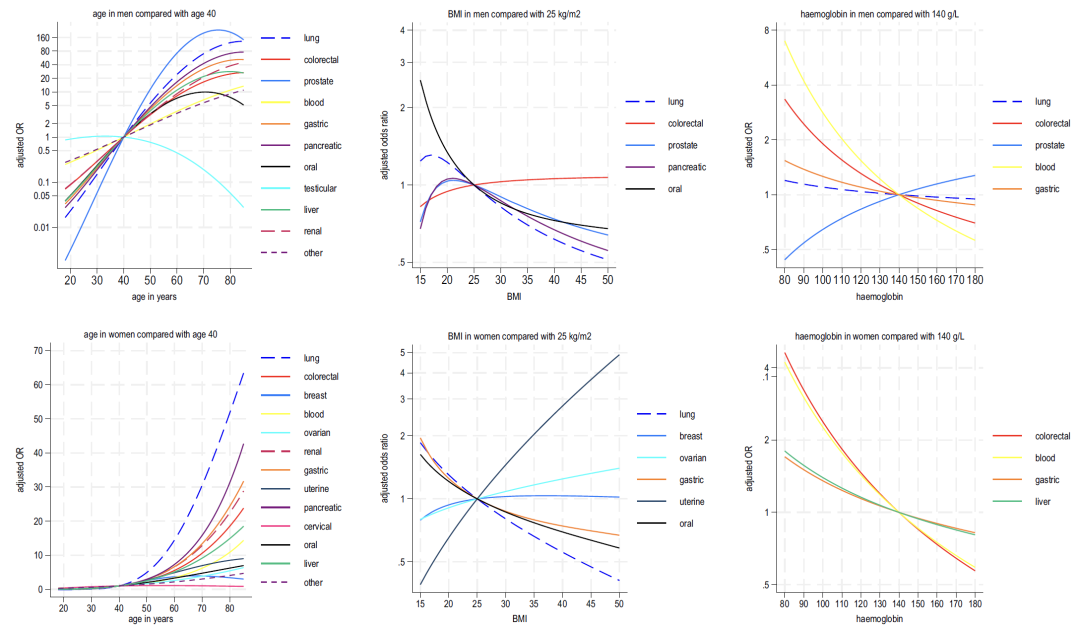
There were gender differences in the interaction between age and symptoms:The risk of most cancers is stronger at a younger age in men, but the opposite is true for women.Analysis of age and BMI showed that, except for testicular cancer and cervical cancer, the risk of all cancer types increased with age; lower BMI was positively correlated with multiple cancer types, and the risk of uterine cancer and ovarian cancer in women increased with higher BMI.
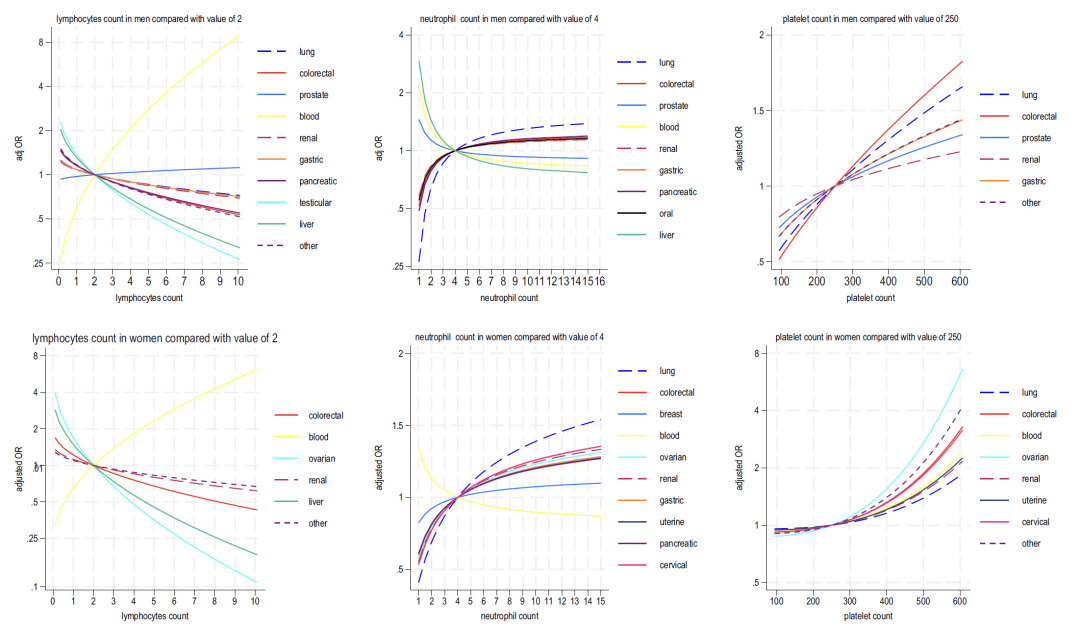
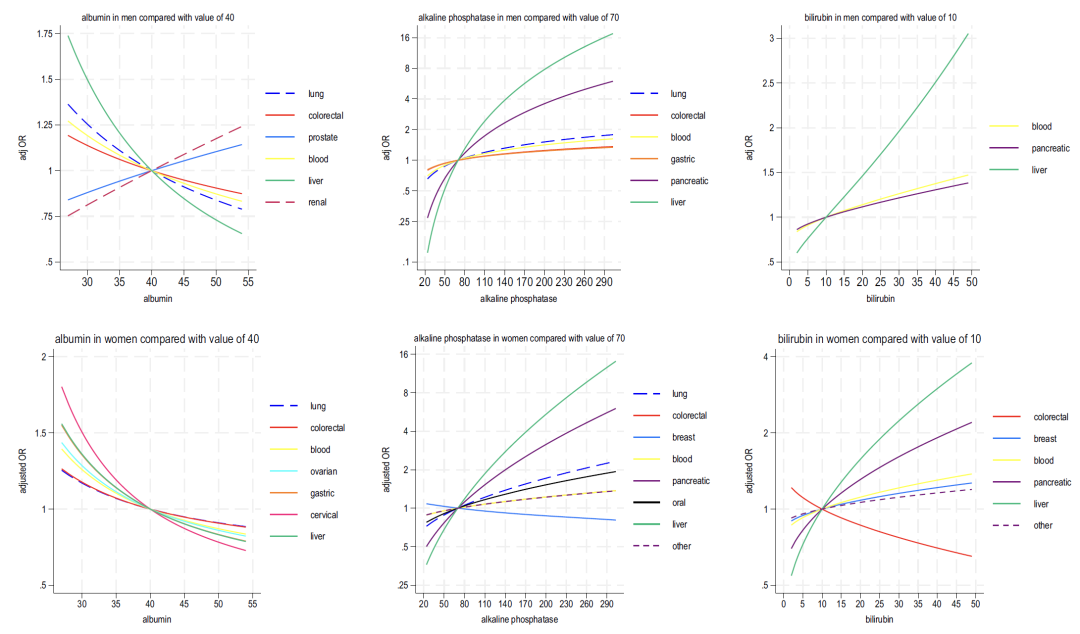
As shown in Figures 2-4 below, analysis of the blood indicators included in Model B shows that:
* Haemoglobin: A decrease in this indicator is associated with lung cancer and colorectal cancer in men, and with colorectal cancer and liver cancer in women;
* Lymphocyte: negatively correlated with most cancers and strongly positively correlated with blood cancers;
* Neutrophil: In women, an increase in this indicator is widely associated with cancer (lung cancer is the most significant), while in men, it is "bidirectionally associated (high values are associated with 6 types of cancer, and low values are associated with liver cancer and prostate cancer)";
* Platelet: Elevated platelet count is positively correlated with multiple cancers in both men and women (colorectal cancer in men and ovarian cancer in women being the strongest), and is synergistically associated with elevated neutrophils and decreased lymphocytes;
* Liver function: Decreased albumin and elevated alkaline phosphatase generally indicate cancer risk, while elevated bilirubin is closely related to liver cancer and blood cancer.
In the evaluation of discrimination ability, as shown in the figure below, the c statistic (AUROC) of model B (including blood test) is better than that of model A overall. The overall discrimination efficiency of men (0.876) is higher than that of women (0.844). Most of the c values of 15 cancers are > 0.8, with only oral cancer (0.747) and cervical cancer (0.694) in women being slightly lower. The multi-category discrimination index (PDI) shows that model B is better than model A in terms of discrimination ability in both men and women (0.323 in men and 0.266 in women), and has outstanding classification efficiency for testicular cancer (PDI 0.641 in men) and uterine cancer (PDI 0.439 in women). Subgroup analysis showed thatThe performance of the model was stable across different races, ages, and geographic regions, with slight fluctuations in rare cancers due to the small number of events.
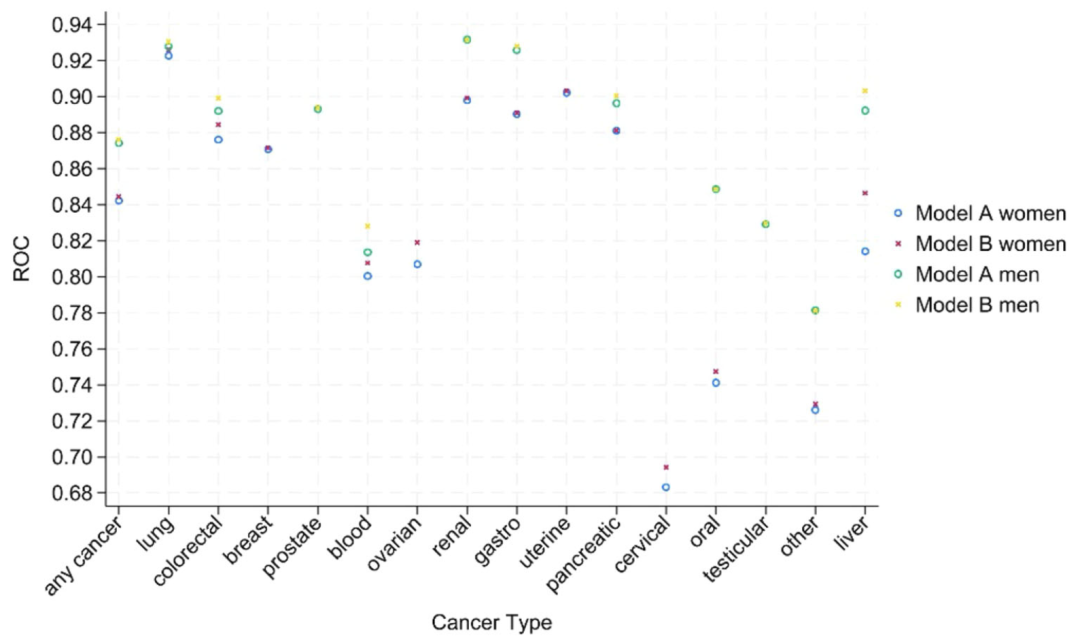
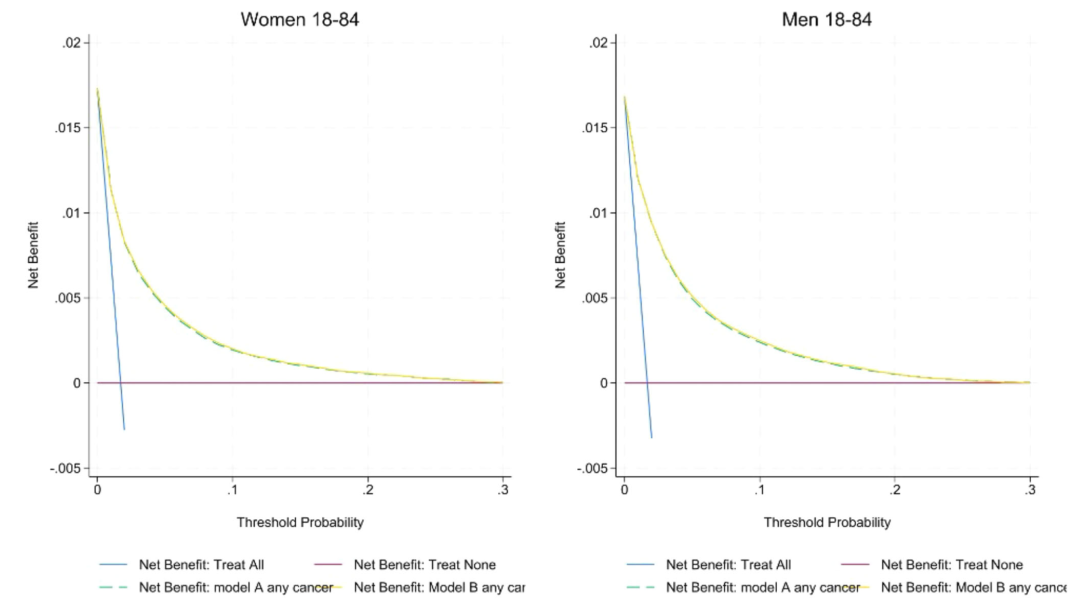
In terms of calibration ability, as shown in the figure below, the calibration slope of model A/B in the England cohort is close to 1 (1.00 for women and 0.99 for men), and the intercept is close to zero; but in the external CPRD cohort, there is a certain overestimation of the cancer probability for men and women. The decision curve shows that the net benefit of model B is higher than that of model A and QCancer, especially at the referral threshold of 3%, the sensitivity of model A/B to male cancer (82.6%) is higher than that of QCancer (78.1%), and the sensitivity of female cancer is increased from 66.0% to more than 77%, and the ability to identify stage 1/2 early cancer is equivalent to that of all stages (75% for women and 81% for men). Reclassification analysis shows thatCompared with QCancer, Model A classifies more elderly people as high-risk and younger people as low-risk, thus optimizing the accuracy of clinical resource allocation.
Global cancer prediction algorithms and early diagnosis: interdisciplinary progress in university research and corporate innovation
In the field of cancer prediction algorithms and early diagnosis, scientific research teams from universities around the world and technology companies are promoting the accelerated transformation of theoretical research into clinical applications through interdisciplinary innovation.
For example, the MuMo model developed by the team of Dong Bin and Shen Lin from Peking University,Integrate imaging, pathology and clinical data of HER2-positive gastric cancer patients to provide accurate predictions for individualized treatment;The Computer Network Information Center of the Chinese Academy of Sciences built the SuRe-Transformer model based on the "Dongfang" supercomputer system using the Transformer architecture.Improve the HRD prediction accuracy of breast cancer pathology images by 21%;Li Shao's research group at Tsinghua University used the weakly supervised learning framework HistoCell.Achieve unsupervised inference of spatial association networks of cells in pathological images.Provide new tools for tumor microenvironment research.
The CHIEF model developed by Harvard Medical School and Stanford University,Diagnosing 19 types of cancer with an accuracy of 94%,It can also predict patient survival rates based on pathological images; the ResNetRS50 deep learning model built by the University of Cambridge predicts blood cancer by analyzing blood data, with higher accuracy, speed and lower error rate than advanced models.
Innovation in the corporate world focuses more on the integration of technology implementation and clinical practice. Microsoft's AI for Health platform integrates genomes and electronic health records to build an individual cancer risk map, with a prediction accuracy of 89% for high-risk breast cancer populations; Google DeepMind's AlphaScan system has an accuracy of 96% in early lung cancer detection; AI medical technology company InferRead's lung imaging AI solution, a deep learning-based lung nodule detection system, has been applied to clinical CT, significantly improving diagnostic efficiency.
Overall, cancer prediction algorithms and early diagnosis are evolving from single cancer screening to pan-cancer early screening for multiple cancers: Grail's Galleri test in the United States screens 50 types of cancer and locates the primary lesion through blood methylation analysis, and the PanSeer® technology of the Chinese company Xunyuan Biotechnology effectively achieves early screening for 5 high-incidence cancers. With the deep integration of artificial intelligence and big data, cancer prediction algorithms are expected to be popularized in primary medical care, promoting the transformation of diagnosis and treatment models from "empirical medicine" to "precision data medicine", and laying the foundation for "early detection and early intervention".
Reference Links:
1.https://bda.pku.edu.cn/info/1003/2824.htm
2.https://www.cas.cn/syky/202505/t20250522_5069507.shtml
3.https://mp.weixin.qq.com/s/s1JyOTPChdoMipmTzBBqvw
4.https://mp.weixin.qq.com/s/4fhMJ25xVAThAFTdmZyt9w








