Command Palette
Search for a command to run...
Published in Nature Sub-journal! Huazhong University of Science and Technology Proposed a Fusion Strategy AI Model to Achieve Accurate Prediction of Mortality Risk of Septic Shock in Multiple Centers and Across Specialties

Septic shock (also known as septic shock) refers to a syndrome of severe circulatory disorders and cellular metabolic disorders caused by sepsis, which can be regarded as the "terminal stage" of sepsis development in clinical manifestations. Septic shock has an extremely high mortality rate and is currently one of the most deadly diseases in intensive care units.According to a research report based on the UK national intensive care database, the in-hospital mortality rate of patients with septic shock can be as high as 55.5%.
Faced with this progressive disease with a high mortality rate, the clinical emphasis on septic shock is “time is life”, advocating early detection, early intervention, and early treatment to reduce the mortality rate. However,Due to the complexity of the condition of septic shock patients and the scarcity of clinical medical data, it is very difficult to provide early warning of the progression of septic shock patients., which is also the key bottleneck for effectively intervening the deterioration of sepsis to septic shock.
At present, with the deepening of the informatization of critical care medicine, the cross-integration of artificial intelligence and critical care medicine has made early warning of sepsis no longer difficult, but research on septic shock has lagged behind. This is because most research samples are small, rely on a single machine learning algorithm, and fail to pass multi-center verification, making it difficult to promote them to the clinical practice of early risk prediction of patients with septic shock.
In view of this, Professor Ye Qing from Tongji Hospital affiliated to Tongji Medical College of Huazhong University of Science and Technology and Professor Wu Hong from the School of Medical and Health Management have pioneered a classification fusion (TCF) model based on TOPSIS (Technique for Order Preference by Similarity to an Ideal Solution) to predict the risk of death within 28 days in patients with septic shock in the ICU.The model integrates 7 machine learning models and has high stability and accuracy in cross-professional and multi-center validation.It provides clinicians with a reliable auxiliary tool for early warning of the risk of death from septic shock.
The research results were published in Nature's subsidiary journal npj Digital Medicine under the title "Artificial intelligence based multispecialty mortality prediction models for septic shock in a multicenter retrospective study".
Research highlights:
* The study adopted an efficient fusion strategy to build a fusion model with high generalization ability and robustness based on multiple basic classification models, overcoming the problem of poor performance of small sample cohorts and single classification models in clinical scenarios
* The research results have made a breakthrough in the difficulty of predicting the risk of early death in septic shock, providing clinicians with an efficient, stable and reliable clinical decision-making tool that helps doctors closely monitor the progression of patients' conditions earlier and take more active treatment measures

Paper address:
https://go.hyper.ai/faMLL
The open source project "awesome-ai4s" brings together more than 100 AI4S paper interpretations and provides massive data sets and tools:
https://github.com/hyperai/awesome-ai4s
Datasets: Extensive data, precise processing
In order to construct a septic shock prediction model with wide applicability,The research team integrated the clinical data of 4,872 ICU septic shock patients from three hospitals from February 2003 to November 2023.The participants have complex and diverse backgrounds, which helps the research team conduct multi-center, cross-specialty validation to prove the effectiveness and applicability of the model. As shown in the figure below:
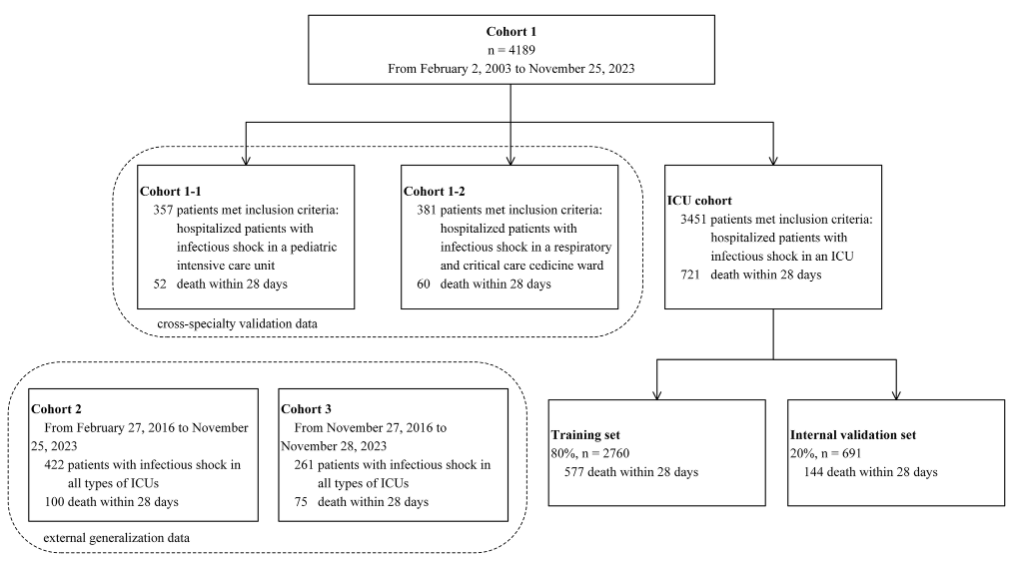
Specifically,Cohort 1 included 4,189 participants.Among them, there were 3,451 patients in the general ICU (721 positive and 2,730 negative); 357 patients in the pediatric ICU (cohort 1-1) (52 positive); and 381 patients in the respiratory ICU (cohort 1-2) (60 positive).
* Positive results are participants who experienced all-cause death within 28 days of ICU hospitalization, and participants who did not experience all-cause death are marked as negative results (the same below)
Among them, the general ICU patient dataset was used as the main research population and for model construction and internal validation.The training data and validation data were split 8:2, with 2,760 subjects (577 positive) and 691 subjects (144 positive), respectively.The pediatric ICU patient and respiratory ICU patient datasets further evaluated the applicability and stability of the model in different specialized intensive care units.
Cohort 2 and cohort 3 included patients with septic shock from different ICUs, with 422 participants (100 positive, 322 negative) and 261 participants (75 positive, 186 negative), respectively.These two parts of the dataset are mainly used for external validation to evaluate its generalization ability and effectiveness in different centers.
In addition, in order to obtain accurate experimental results,The research team extracted 93 common clinical characteristics.Including demographic information, disease and treatment history, vital signs information, etc., it was finally optimized to 34 items for the experiment.
Specifically,Data preprocessing consists of 5 parts:In the first step, the research team first calculated the missing rate and deleted 23 variables with a missing rate higher than 30%; in the second step, the variance of Boolean Features was calculated according to Bernoulli's variance formula, and the discrete random variables with consistency exceeding 90% were removed again; in the third step, the missing value interpolation method (Logistic regression multiple interpolation) was used to further optimize to 61 variables; in the fourth step, high correlation features were screened again (Pearson correlation coefficient ≥ 0.7), and 50 variables were left at this time. As shown in the figure below:
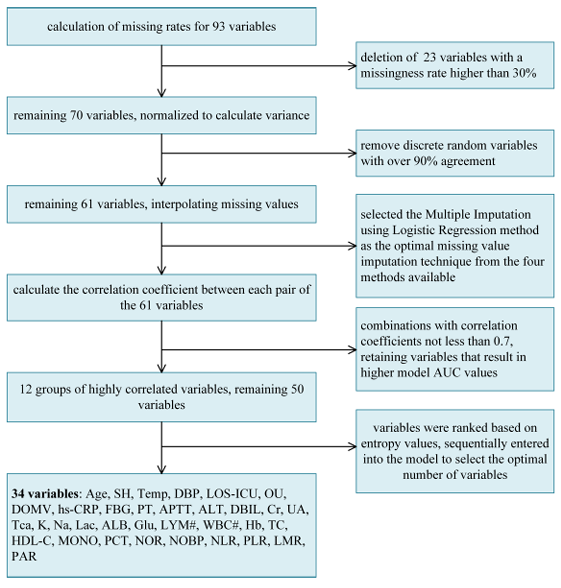
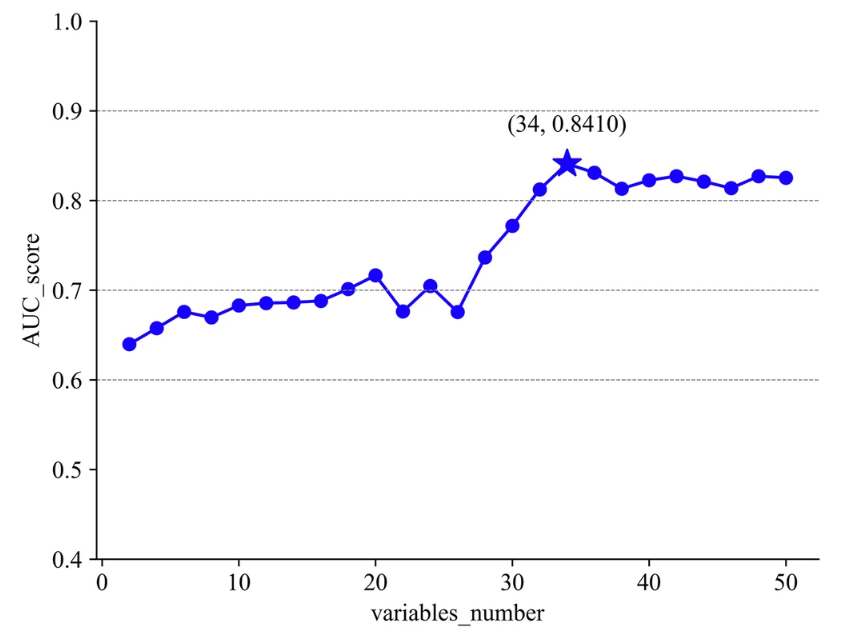
In the fifth step, the researchers sorted the variables according to information entropy (from high to low) and finally selected 34 key variables for the experiment, including important factors such as age, surgical history, body temperature, and diastolic blood pressure.
It should be noted that in order to protect the privacy of participants, all data were de-identified before analysis.
Model architecture: Fusion model, accurate prediction
The research of TCF model is mainly divided into three steps:The first step is to establish 7 sub-models using the hospitalization data of patients with septic shock, each of which produces results for 6 evaluation indicators; the second step is to integrate the sub-models into a fusion model based on the fusion strategy and verify that the model is superior to other models; the third step involves testing across various data sets to verify the performance of the model and perform interpretability analysis on the model (explained in the experimental results section).
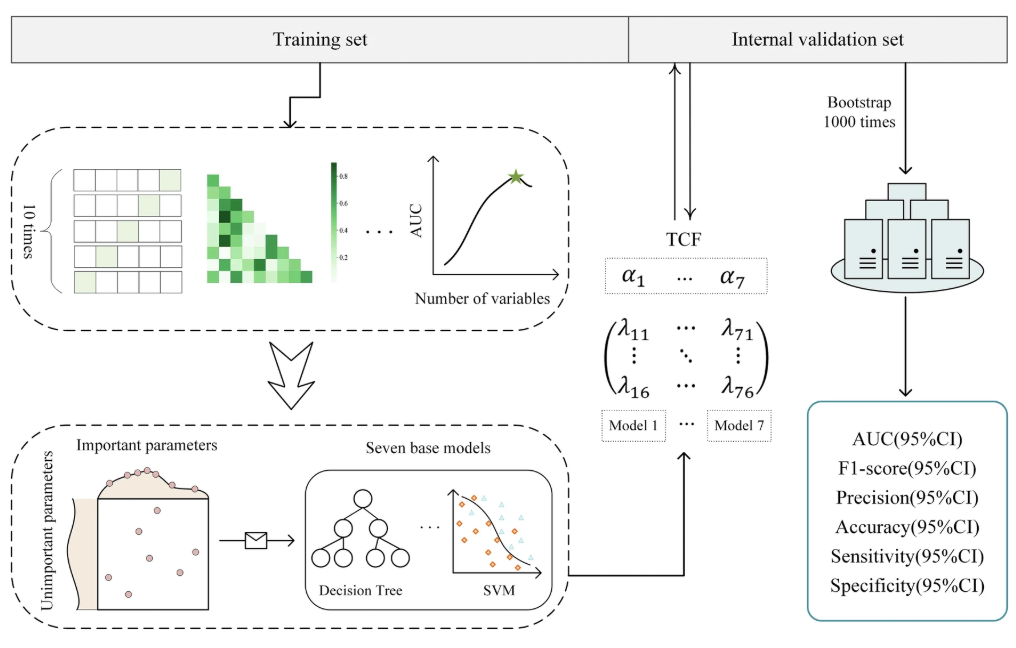
Specifically,In the first step, the research team first trained and tested 7 sub-models using the feature-processed common ICU dataset.The Synthetic Minority Over-sampling Technique (SMOTE) was applied to the training set according to the 1:1 rule to alleviate the negative impact of class imbalance. After min-max normalization, the optimal parameter combination was determined through five-fold cross validation and random search, and 7 sub-models were trained on the training set, namely Decision Tree (DT), Random Forest (RF), XGBoost (XGB), LightGBM (LGBM), Naive Bayes (NB), Support Vector Machine (SVM) and Gradient Boosted Decision Tree (GBDT).
Finally, the research team used internal validation data to verify the test results.The performance of the model is evaluated using 6 evaluation indicators.They are area under ROC curve (AUC), F1-score, precision (PRE), accuracy (ACC), sensitivity (SEN) and specificity (SPE).
In the second step, the research team integrated these seven sub-models, each with its own advantages and disadvantages.A TOPSIS-based classification fusion model TCF was designed to combine the evaluation results of the seven models to provide a comprehensive prediction result for the diagnosis of septic shock. The weights of the sub-models were calculated by TOPSIS-score, and the weighted prediction probability was the prediction probability of TCF. The classification results of TCF were derived with 0.5 as the critical value.
The specific TCF model fusion algorithm is as follows:
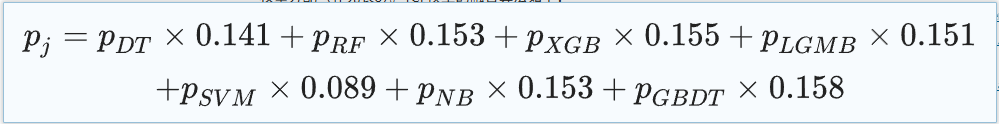
In terms of statistical analysis, for continuous features, the median, upper quartile, and lower quartile statistics are given; for discrete features, the proportion of each category is reported.In this study, the smallest dataset is cohort 3, and according to the central limit theorem, the mean distribution of continuous features can be considered to be a normal distribution.
Then,The study used Levene's test to determine the homogeneity of characteristics between two sets of data.The Chi-square test was used to compare the differences in discrete features between other data and the internal validation set, and the differences in continuous features were tested using the independent sample t-test or Welch's t-test, and 1,000 bootstrap samples were used to calculate the 95% confidence intervals of the evaluation indicators.
In order to better understand the reasoning process of the model, the research team also visualized the feature importance by drawing a SHAP feature importance heat map. Take the GBDT model with the best AUC performance as an example, as shown in the figure below:
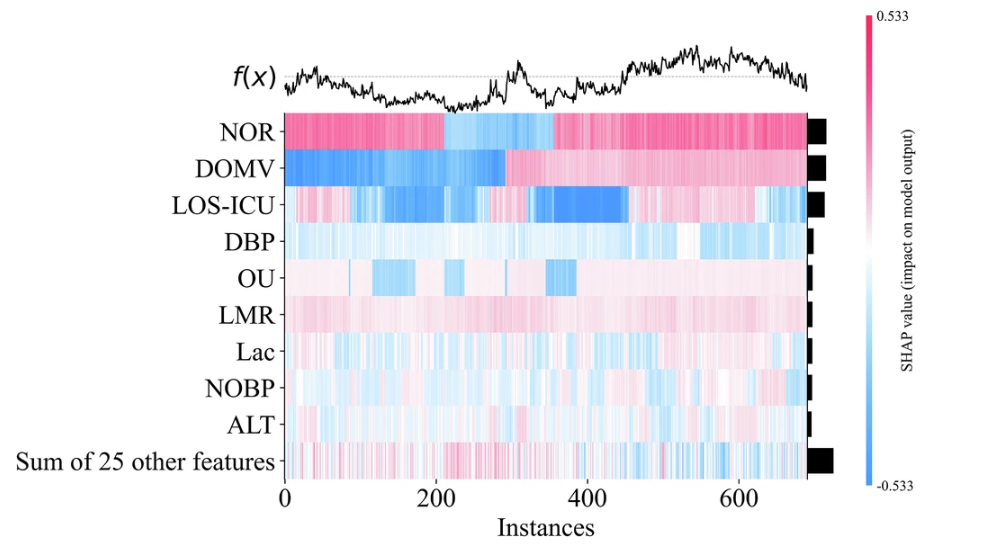
Feature importance ranking can not only improve the transparency and credibility of clinical prediction models, but also provide valuable reference for medical practice.The model not only meets the doctors’ demand for model transparency, but also quantifies the clinical net benefit.It achieves both clinical interpretability and practicality, laying the foundation for the application of the model in clinical practice.
Experimental results: multi-dimensional verification, reliable and easy to use
To verify the performance of the fusion model (TCF), the research team first compared it with the sub-models. The results are shown in the figure below:
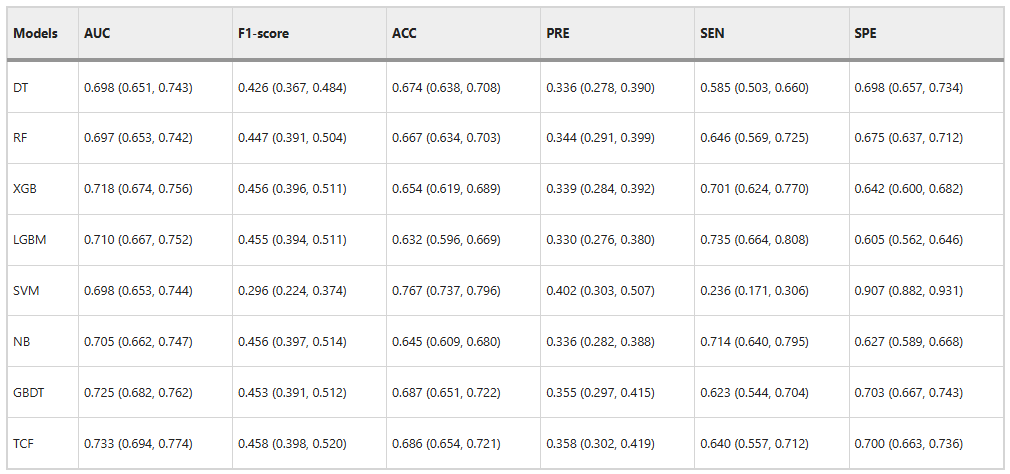
TCF outperforms the sub-models in both comprehensive evaluation indicators on the internal validation set.The AUC is 0.733 and the F1-score is 0.458. In addition, the ACC is 0.686 and the PRE is 0.358, which are also higher than most sub-models. This shows that it has excellent classification ability.
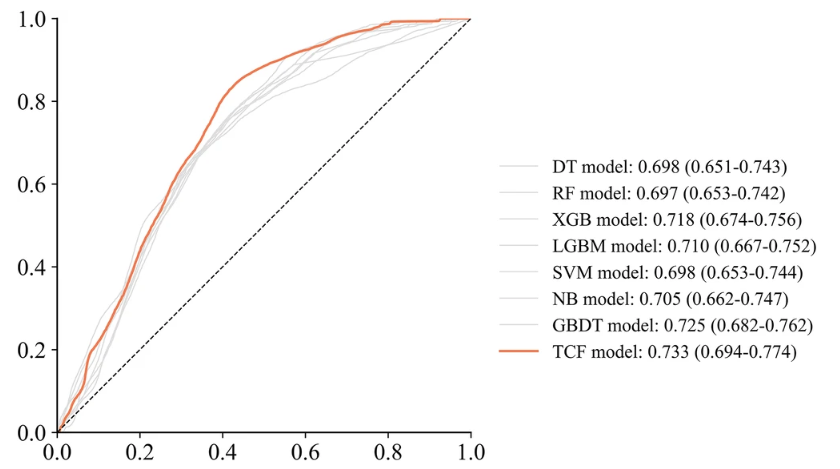
Although the scores of the TCF model on SEN and SPE are not as good as the best performance, which are 0.640 and 0.700 respectively,But it can identify the effect through the deviation of the entire sub-model, thus achieving the best overall performance.As shown in the figure below.
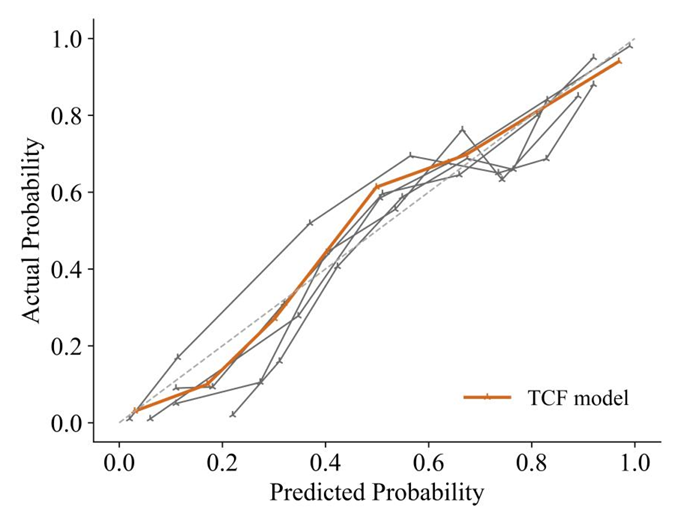
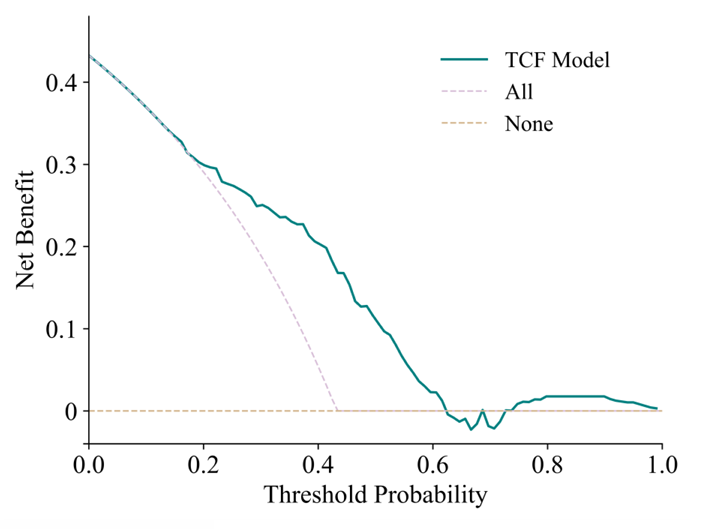
The calibration curve and decision curve analysis (DCA) curve show that the predicted results of the TCF model are consistent with the actual results.First, the calibration curve of the TCF model is closest to the diagonal line, which indicates that it has the best calibration performance among all models. Second, the curve of the TCF model is always better than the "All" and "None" strategies under most threshold probabilities, especially in the probability range of 0.1 to 0.5, showing a higher net benefit. This shows that the TCF model has potential clinical application value within a certain range and can help clinicians make more favorable decisions.
The research team then conducted a multicenter validation, which can more accurately demonstrate the predictive performance of the TCF model and the heterogeneity between different data sets. As shown in the figure below:
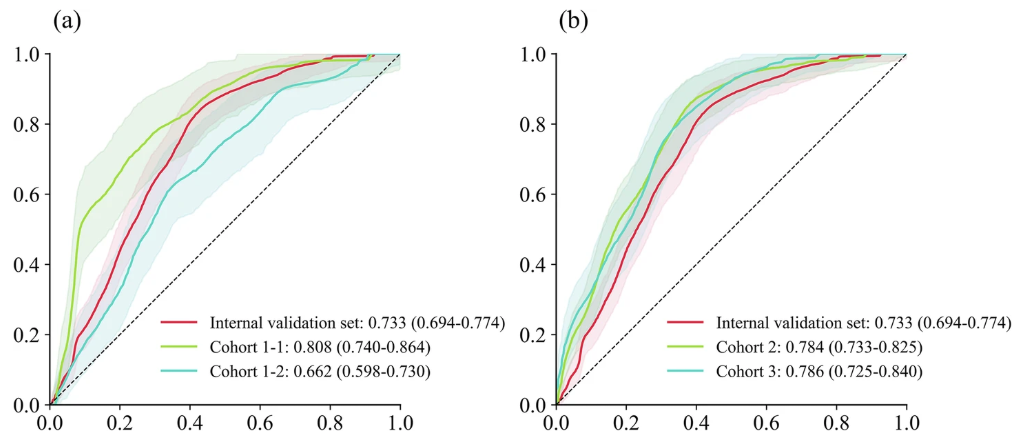
It can be seen that unlike most studies where the multicenter prediction effect is slightly lower than that of the training set and the internal validation set, in this study, except for a slight decrease in the AUC (0.662) of cohort 1-2 (respiratory ICU patient dataset),The AUCs of cohort 1-1 (pediatric ICU patient dataset), cohort 2, and cohort 3 all improved.They are 0.808, 0.784 and 0.786 respectively.
In addition, due to the limited number of multi-center samples,The research team specifically combined 4 external validation data sets for prediction (1,421 patient data, including 287 positive cases).Its AUC was 0.7705, which indicated that the TCF model could effectively distinguish patients with low risk factors for septic shock and had good calibration ability.
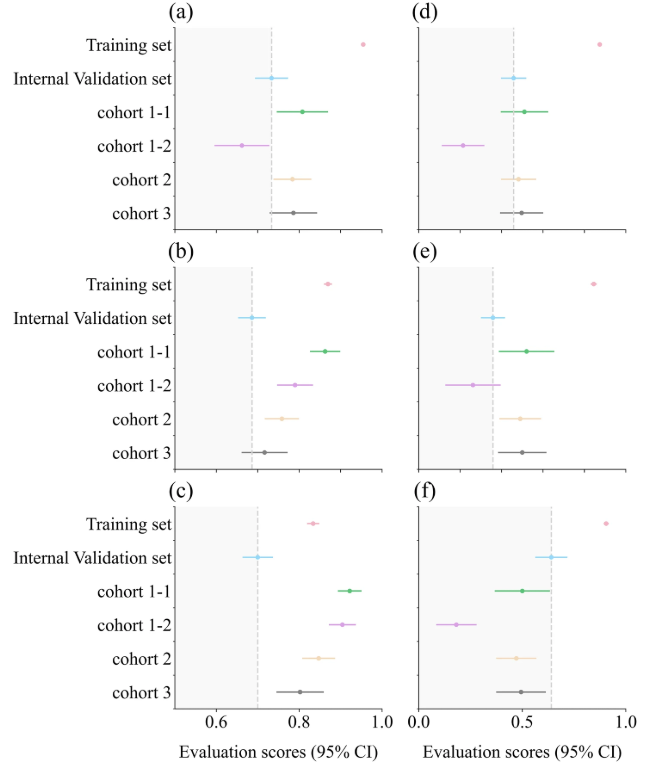
Among them, a is the AUC box plot; b is the ACC box plot; c is the SPE box plot; d is the F1-score box plot; e is the PRE box plot; f is the SEN box plot. The gray dotted line represents the results of the internal validation set, and the evaluation scores of other datasets fall within the dark gray area, indicating that the performance is reduced compared with the internal validation set.
In summary, the TCF model achieved consistent and good performance on both the internal dataset and the external validation set, showing superior performance over single models in predicting the risk of mortality within 28 days in patients with septic shock.This model provides ICU clinicians with a reliable and easy-to-use prediction tool, especially in the critical early stages of a patient's condition deteriorating. It can effectively help doctors provide effective and personalized treatment interventions for different patients and improve patient prognosis.
Artificial intelligence plays a big role in the treatment of sepsis/septic shock
With the continuous development of science and technology, the cross-integration of artificial intelligence and critical care medicine has long become a field of great concern to relevant researchers. This study is undoubtedly an exploration with groundbreaking value. As mentioned above, sepsis/septic shock is a global public health crisis with high mortality and morbidity, and early detection and intervention are urgently needed to improve the survival rate of patients.
In the past, research on early warning models for sepsis has already blossomed, and many laboratories have put forward relevant research results.
For example, a study titled "Machine learning for early detection of sepsis: an internal and temporal validation study" published by Armando D Bedoya et al. from Duke University in the United States.It introduces and verifies a prediction model MGP-RNN based on deep learning (multi-output Gaussian process and recurrent neural network).In comparison with three machine learning methods including random forest, Cox regression and penalized logistic regression, as well as three clinical scores, the model outperformed other models and clinical scores in all indicators and can detect sepsis 5 hours in advance.
Paper address:
https://pmc.ncbi.nlm.nih.gov/articles/PMC7382639
In addition, a team from a California company called Dascena also gave their insights in a study using a retrospective research method.Using data from 32,000 patients in the MIMIC II clinical database, an early warning algorithm for sepsis called InSight was developed by correlating nine common vital sign measurements.The results showed that the algorithm had a sensitivity of 0.90 and a specificity of 0.81 in predicting sepsis 3 hours before the onset of sustained Systemic Inflammatory Response Syndrome (SIRS), outperforming existing biomarker detection methods. The study was published under the title "A computational approach to early sepsis detection."
Paper address:
https://www.sciencedirect.com/science/article/abs/pii/S0010482516301123?via%3Dihub
The integration of artificial intelligence and critical care medicine has made early warning of sepsis no longer difficult, and this study undoubtedly fills the gap of no timely warning when sepsis develops to the critical stage, which is an exploration with greater medical value. Of course, more importantly, the integration strategy mentioned in this study improves the overall performance of the entire model by balancing the sensitivity and specificity advantages of the sub-models. This paves the way for solving related problems through multi-model integration in the future, and inspires more research to solve practical difficulties in medical scenarios through similar methods.








