Command Palette
Search for a command to run...
Online Tutorial | Supports 19 Languages and Generates Music 15 Times Faster! ACE-Step Music Generation Model Is Now Available

Current music generation models face an inherent trade-off between generation speed, musical coherence, and controllability. For example,LLM-based models (e.g., Yue, SongGen) perform well in lyrics alignment but suffer from slow inference speed and structural artifacts.On the other hand, diffusion models (such as DiffRhythm) can achieve faster synthesis speeds, but they usually lack long-distance structural coherence. In response to this, the artificial intelligence company StepFun and the digital music platform ACE Studio jointly launched a basic music generation model ACE-Step-v1-3.5B, which was open sourced on May 7, 2025.The model can synthesize up to 4 minutes of music in just 20 seconds on an NVIDIA A100 GPU, which is 15 times faster than the LLM-based baseline method.While achieving excellent musical coherence and lyrical alignment in terms of melodic, harmonic, and rhythmic metrics.
Compared with traditional AI music tools, ACE-Step overcomes the key limitations of existing methods and achieves optimal performance through overall architectural design.It has outstanding advantages in four aspects: diverse styles and genres, multi-language support, instrumental expressiveness and vocal expressiveness.Its open source version already supports input in 19 languages and retains fine acoustic details. It supports advanced control mechanisms such as voice cloning, lyrics editing, mixing and track generation. In addition, it also supports all mainstream music styles, multiple singing styles, and cross-genre instrumental generation. It can accurately restore the timbre characteristics of musical instruments and generate multi-track music with complex arrangements.
With the help of ACE-Step-v1-3.5B, you only need to input parameters such as music style and lyrics to quickly generate a 30-second music clip. Come and click to listen~
* tag input: funk, pop, soul, rock, melodic, guitar, drums, bass, keyboard, percussion, 105 BPM, energetic, upbeat, groovy, vibrant, dynamic
at present,"ACE-Step: Basic Model for Music Generation" has been launched in the "Tutorial" section of HyperAI's official website.Click the link below to experience the one-click deployment tutorial ⬇️
Tutorial Link:https://go.hyper.ai/tTmib
Demo Run
1. After entering the hyper.ai homepage, select the "Tutorial" page, select "ACE-Step: Basic Model for Music Generation", and click "Run this tutorial online".
2. After the page jumps, click "Clone" in the upper right corner to clone the tutorial into your own container.
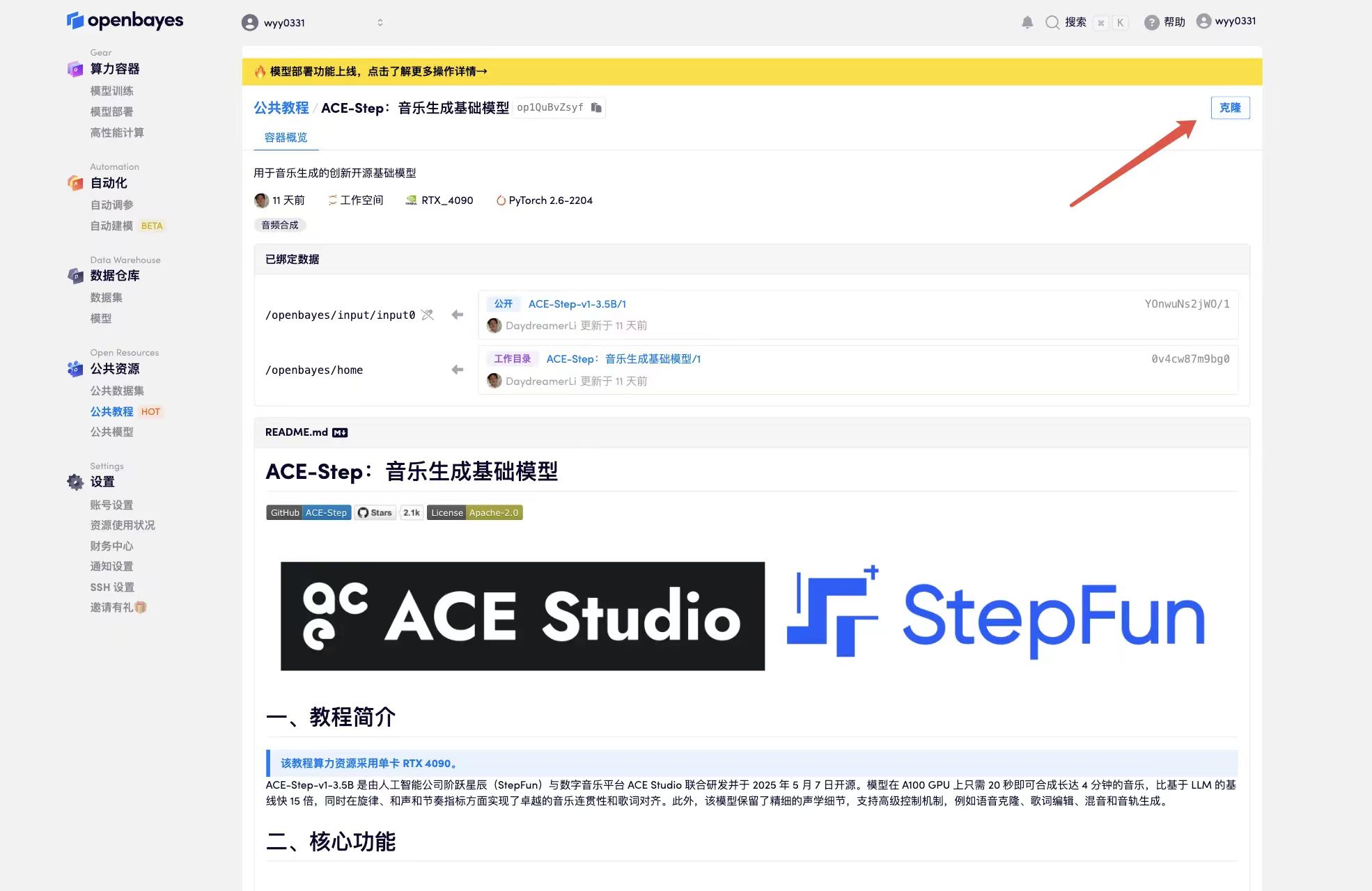
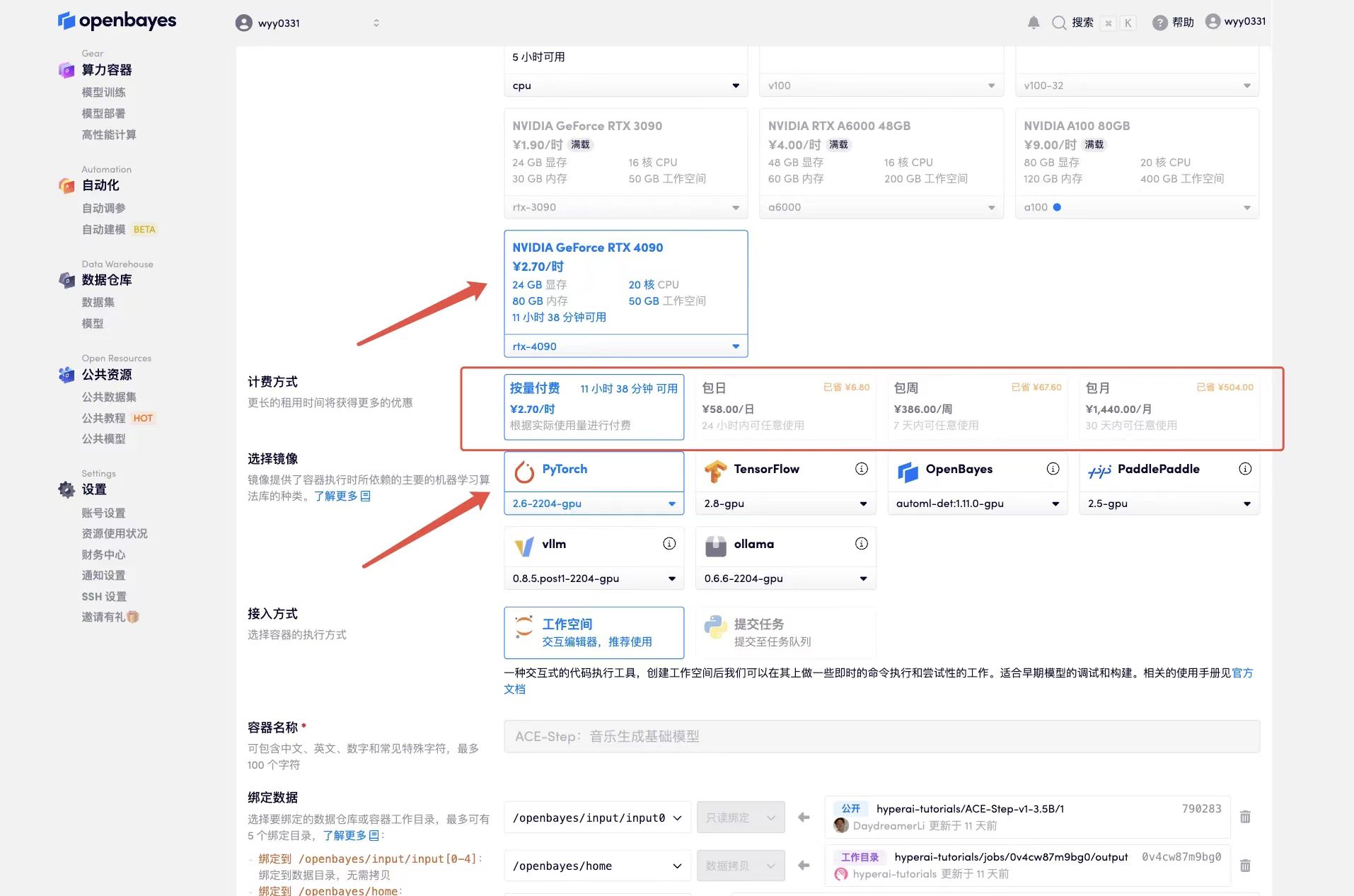
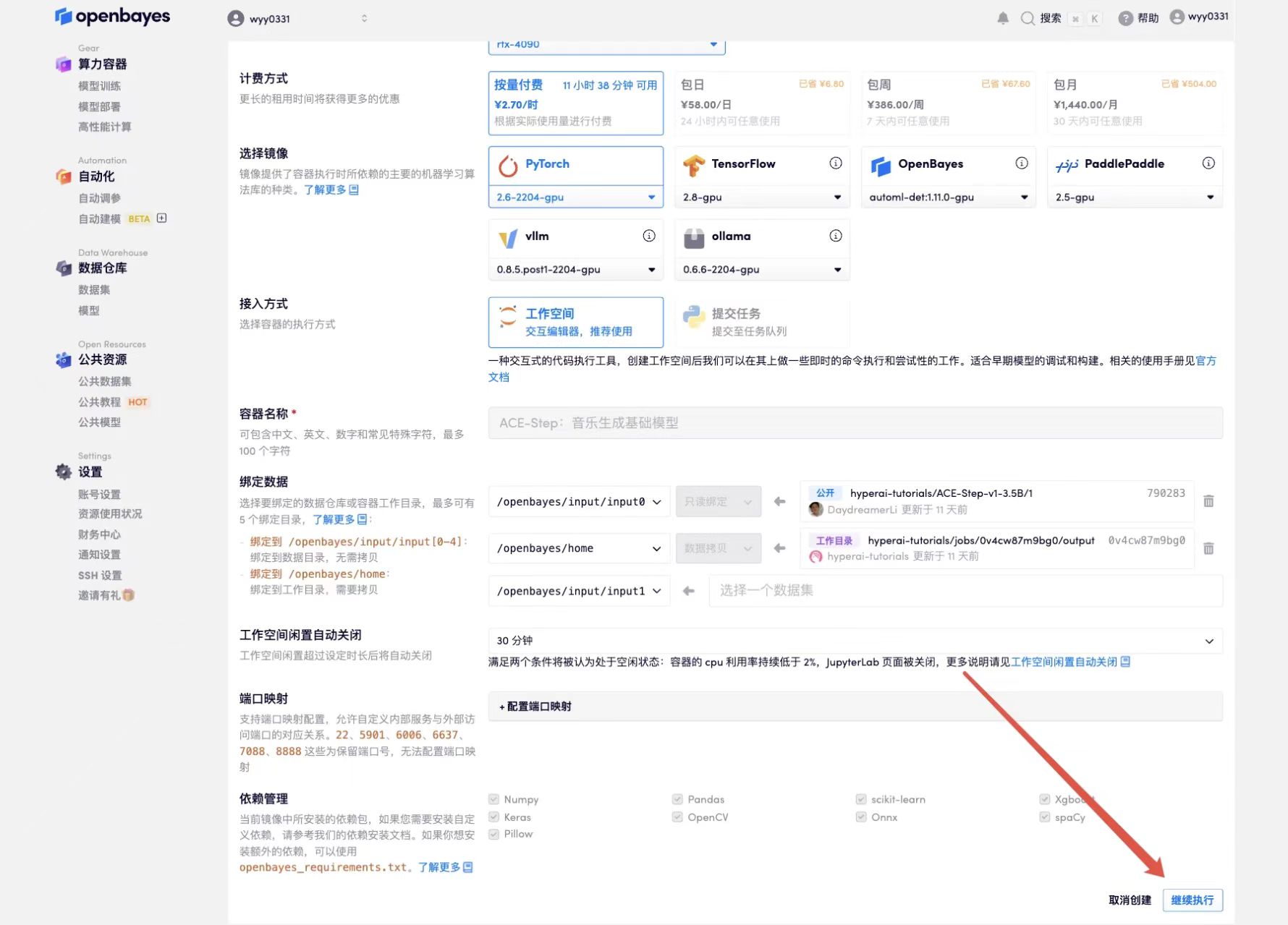
3. Select "NVIDIA GeForce RTX 4090" and "PyTorch" images. The OpenBayes platform provides 4 billing methods. You can choose "Pay as you go" or "Pay per day/week/month" according to your needs. Click "Continue". New users can register using the invitation link below to get 4 hours of RTX 4090 + 5 hours of CPU free time!
HyperAI exclusive invitation link (copy and open in browser):
https://openbayes.com/console/signup?r=Ada0322_NR0n
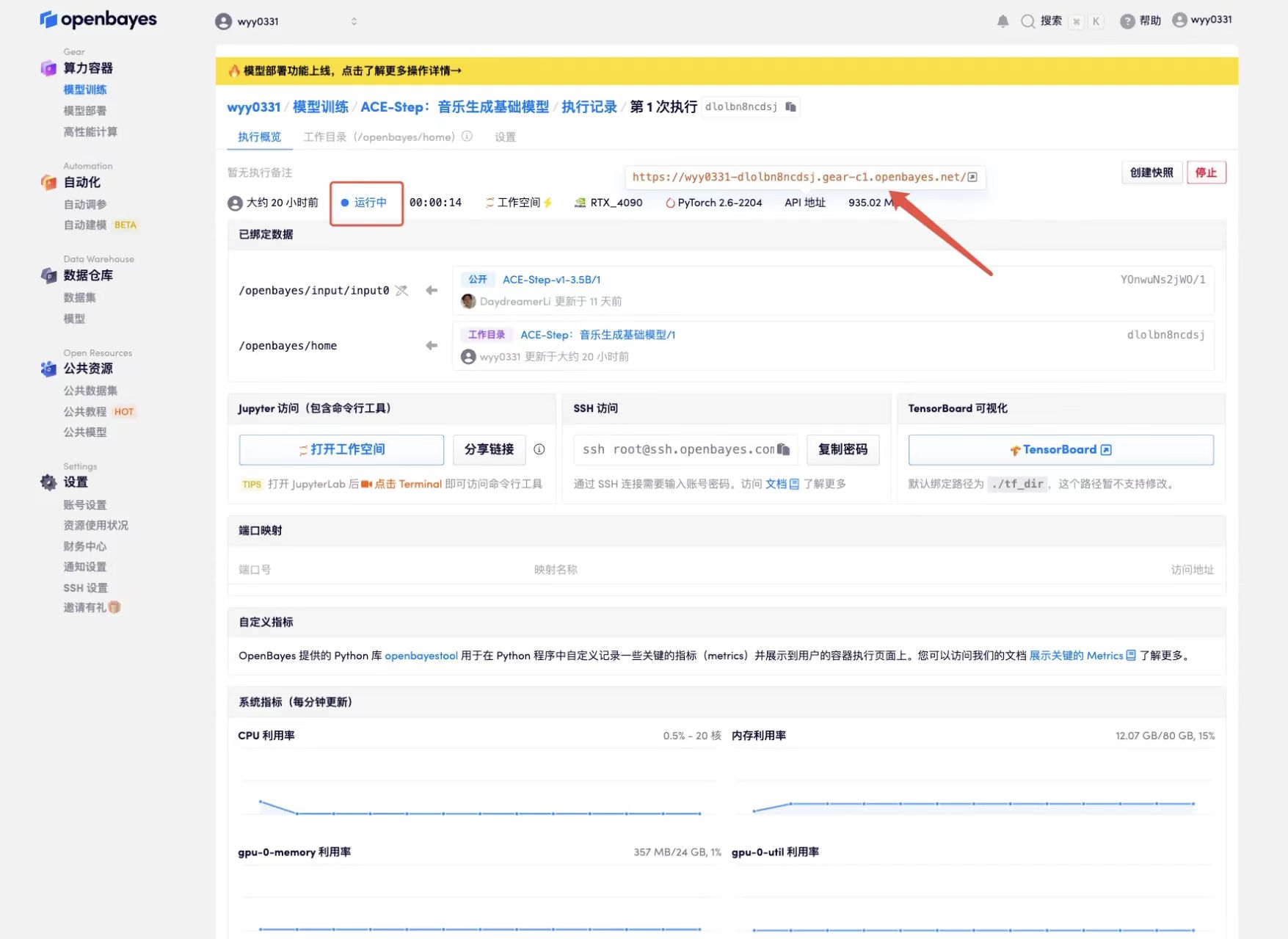
4. Wait for resources to be allocated. The first clone will take about 2 minutes. When the status changes to "Running", click the jump arrow next to "API Address" to jump to the Demo page. Due to the large model, it will take about 3 minutes to display the WebUI interface, otherwise "Bad Gateway" will be displayed. Please note that users must complete real-name authentication before using the API address access function.
Effect Demonstration
The project provides multi-tasking creation panels: Text2Music Tab, Retake Tab, Repainting Tab, Edit Tab and Extend Tab.
The functions and parameter adjustments of each module are briefly introduced as follows:
Text2Music Tab
* Audio Duration: Set the duration of the generated audio (-1 means random generation)
* Tags: Enter descriptive tags, music genres, or scene descriptions, separated by commas
* Lyrics: Enter lyrics with structure tags, such as [verse], [chorus], [bridge]
* Basic Settings: adjust the number of inference steps, guidance ratio and seed value
* Advanced Settings: fine-tune scheduler type, CFG type, ERG settings and other parameters
* Click the "Generate" button to create music based on the input content
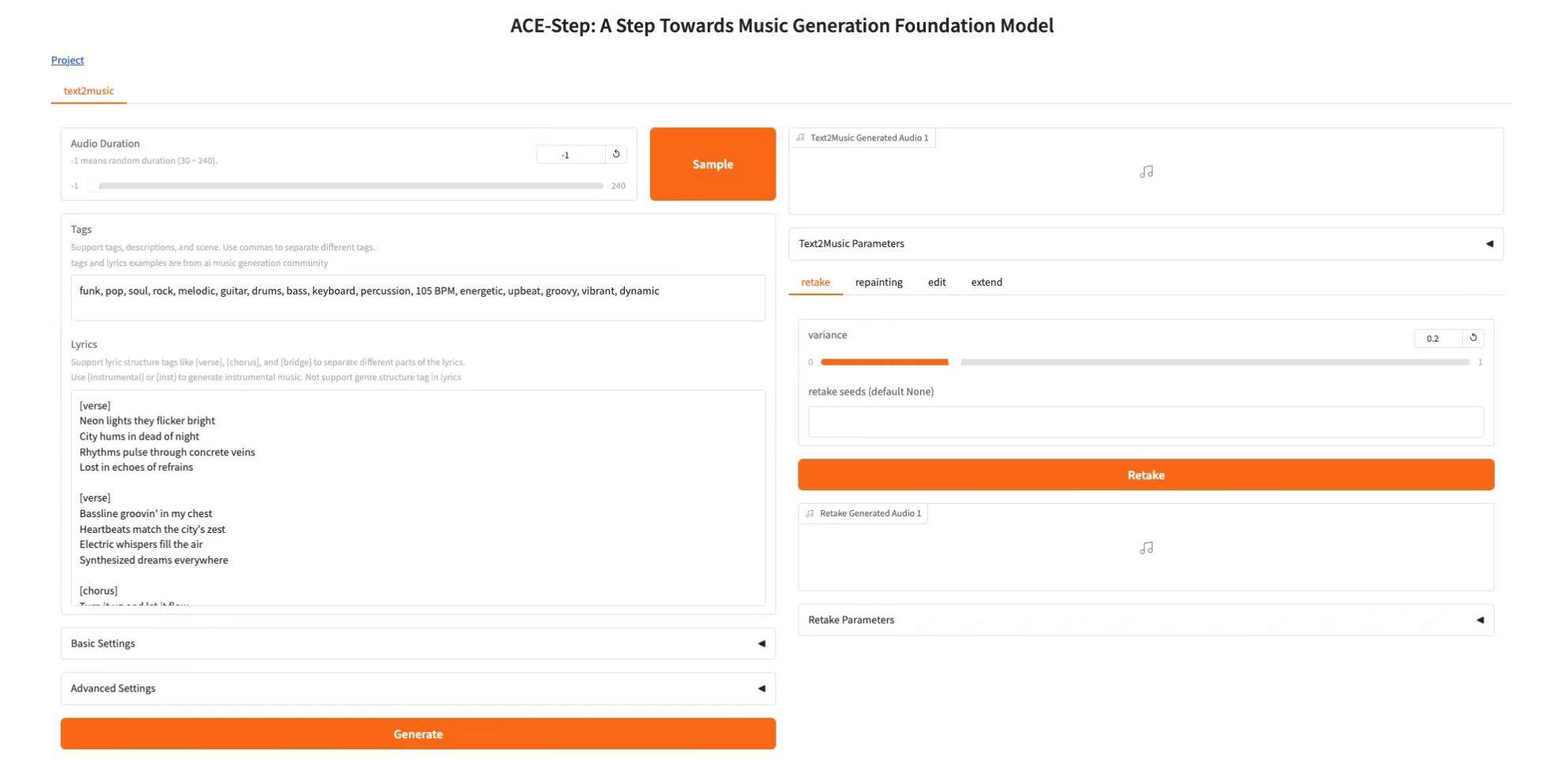
Retake Tab
Function:Regenerate the music with different seed values and produce slight variations, adjusting the variation parameters to control how different the new version is from the original
* variance: fill in the variance
* retake seeds (default None): fill in the random number seed
* Click the "Retake" button to regenerate
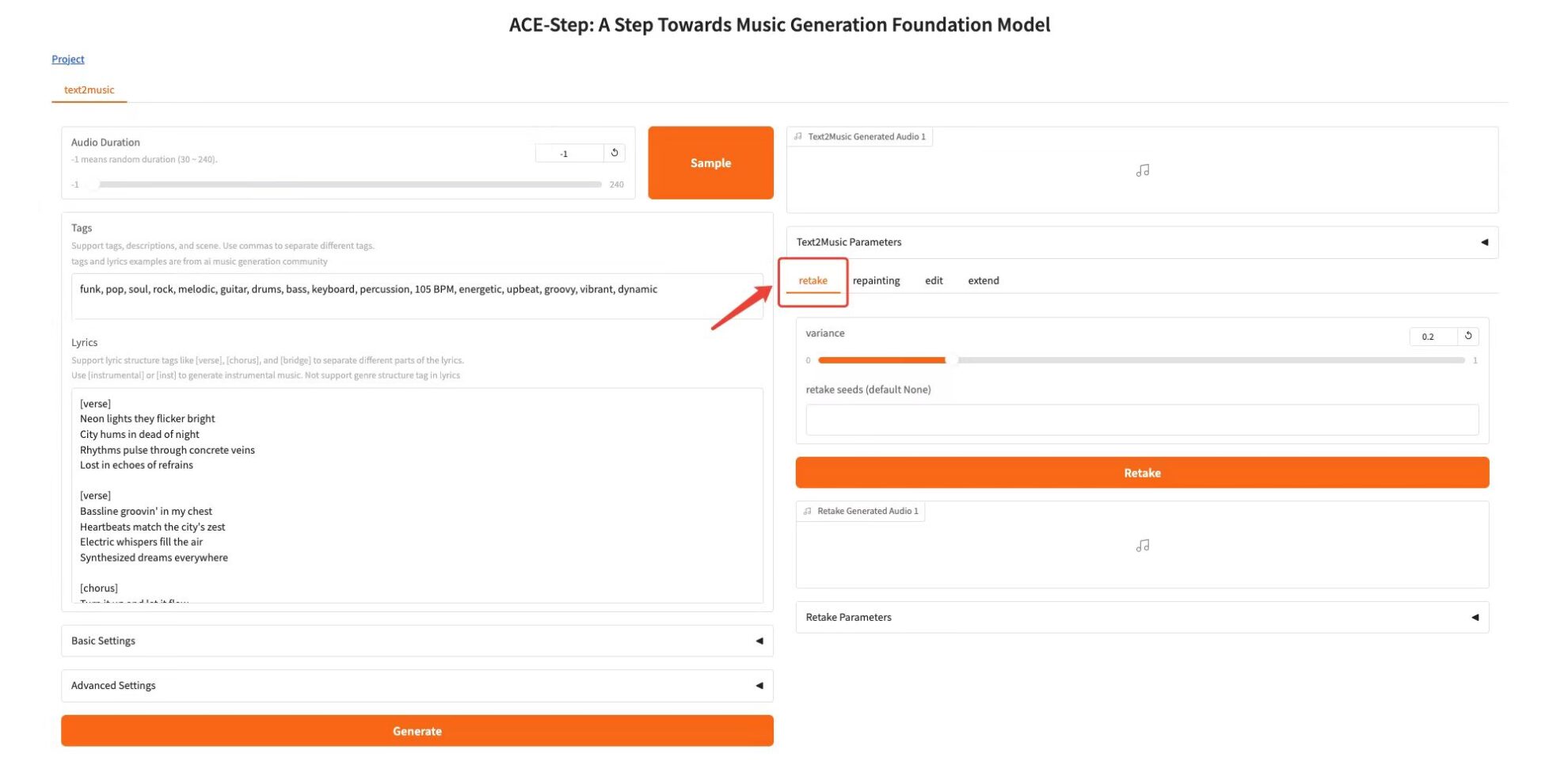
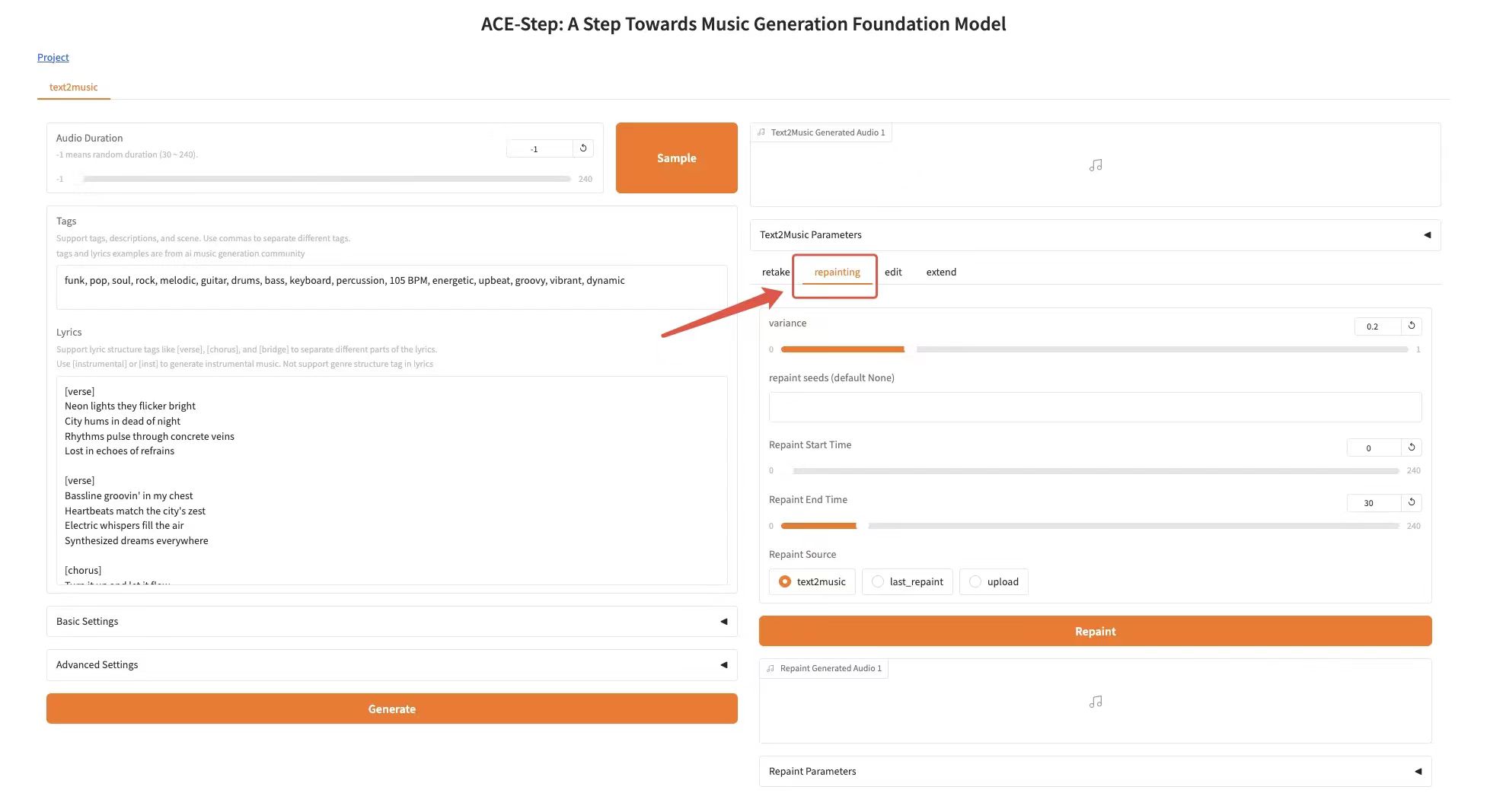
Repainting Tab
Function:Selectively regenerate specific passages of music
* variance: variance
* retake seeds (default None): random seeds
* Repaint Start Time: specifies the start time of the paragraph to be regenerated
* Repaint End Time: specifies the end time of the paragraph that needs to be regenerated
* Repaint Source: Select the source audio (text2music, last_repaint or upload)
* Click the "Repaint" button to regenerate
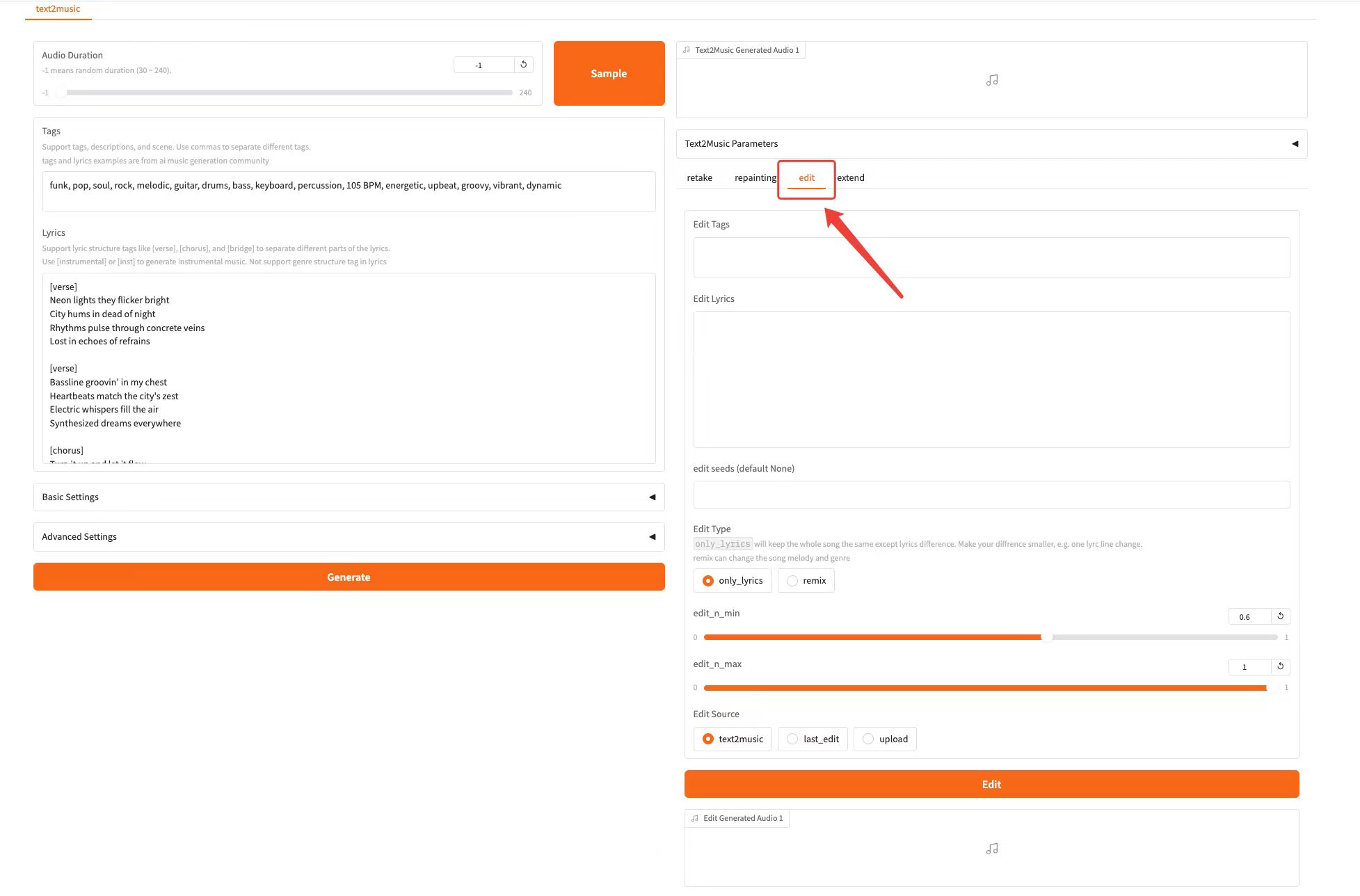
Edit Tab
Function:Control the degree of preservation of the original song by adjusting the editing parameters
* Edit Tags: modify tags to adapt existing music
* Edit Lyrics: modify lyrics to adapt existing music
* edit seeds (default None): Edit random seeds
* Edit Type: Edit type, you can choose "only_lyrics" mode (keep the original melody) or "remix" mode (change the melody)
* Repaint End Time: specifies the end time of the paragraph that needs to be regenerated
* edit_n_min: edit minimum range
* edit_n_max: maximum editing range
* Edit Source: Edit resource
* Click the "Edit" button to edit
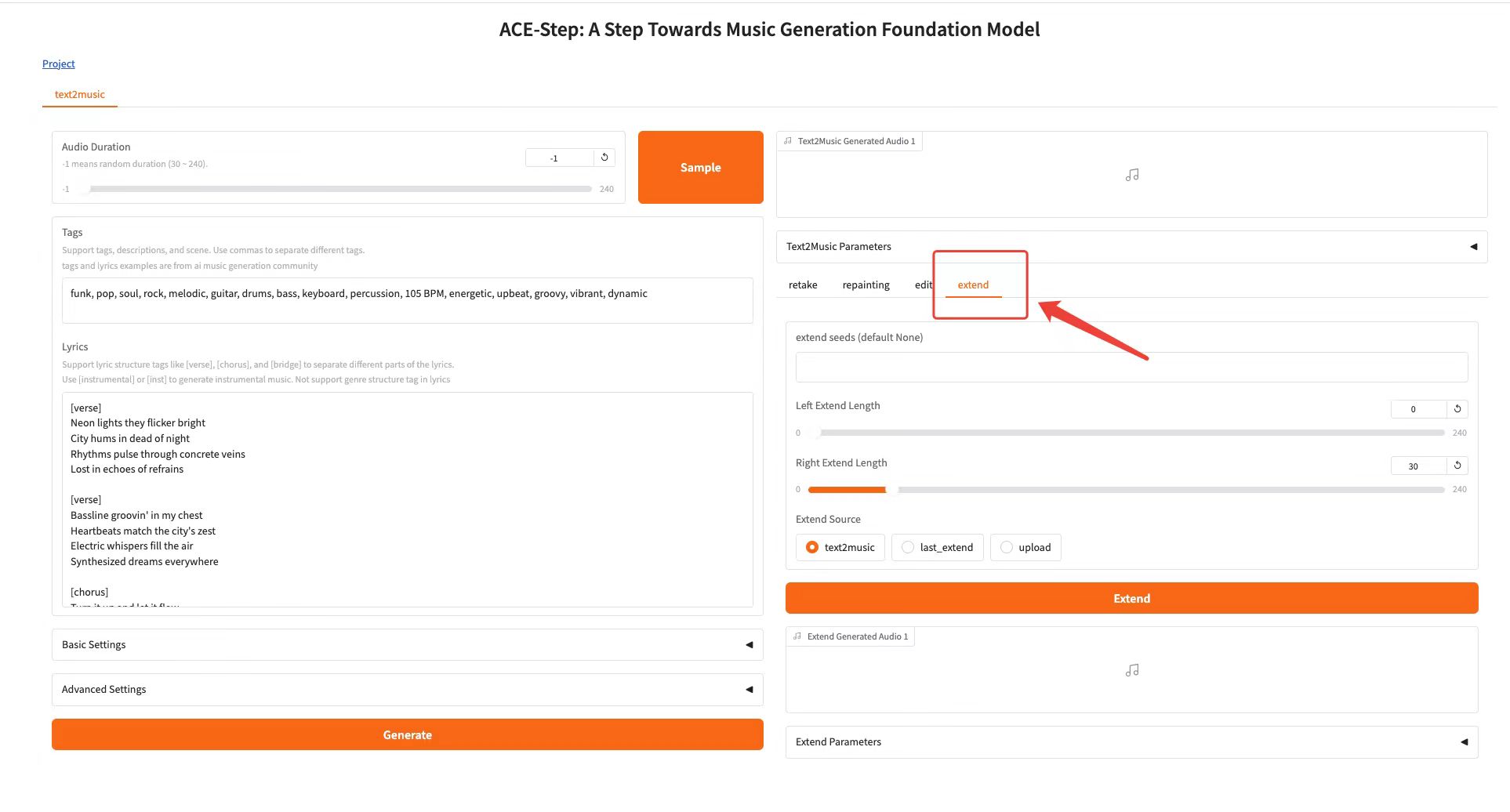
Extend Tab
Function:Add a piece of music at the beginning or end of existing music
* edit seeds (default None): spread random seeds
* Left Extend Length: specifies the left extension length
* Right Extend Length: specifies the right extension length
* Extend Source: Select the source audio that needs to be extended
* Click the "Extend" button to expand