Command Palette
Search for a command to run...
Summary of vLLM Practical Tutorials, From Environment Configuration to Large Model Deployment, Chinese Documentation Tracking Major Updates

As large language models (LLMs) gradually move towards engineering and large-scale deployment, their reasoning efficiency, resource utilization, and hardware adaptability are becoming core issues that affect the implementation of applications. In 2023, the research team at the University of California, Berkeley, open-sourced vLLM, which introduced the PagedAttention mechanism to efficiently manage the KV cache, significantly improving the model throughput and response speed, and quickly became popular in the open source community. As of now, vLLM has exceeded 46k stars on GitHub, making it a star project in the large model reasoning framework.
January 27, 2025vLLM team released v1 alpha version,The core architecture has been systematically restructured based on the development work done over the past two years.The core of this updated version v1 is a comprehensive reconstruction of the execution architecture.The isolated EngineCore is introduced to focus on the model execution logic, adopt multi-process deep integration, realize CPU task parallelization and multi-process deep integration through ZeroMQ, and explicitly separate the API layer from the inference core, which greatly improves the system stability.
At the same time, the Unified Scheduler is introduced, which has the features of fine scheduling granularity, support for speculative decoding, chunked prefill, etc.Improve latency control capabilities while maintaining high throughput.
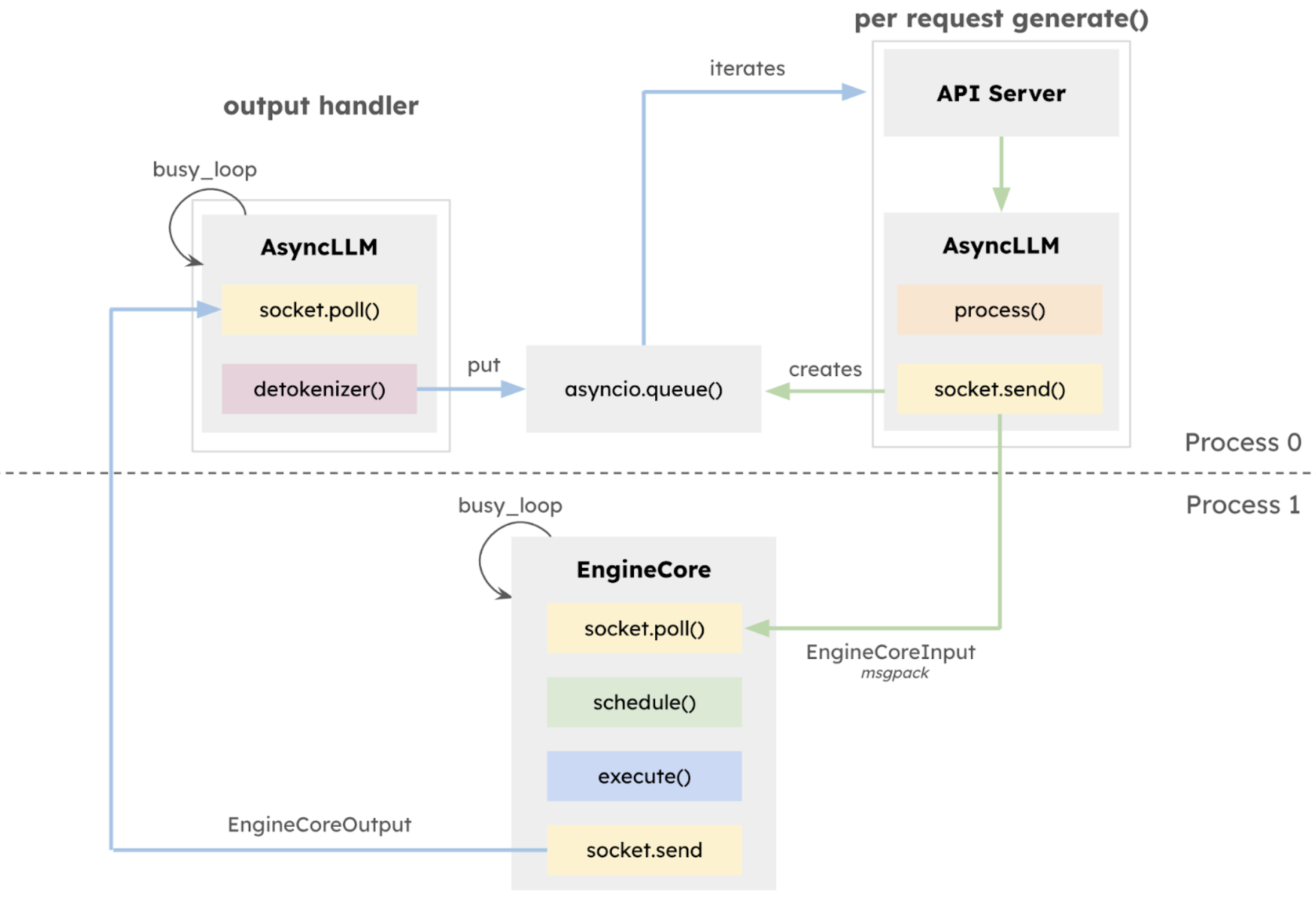
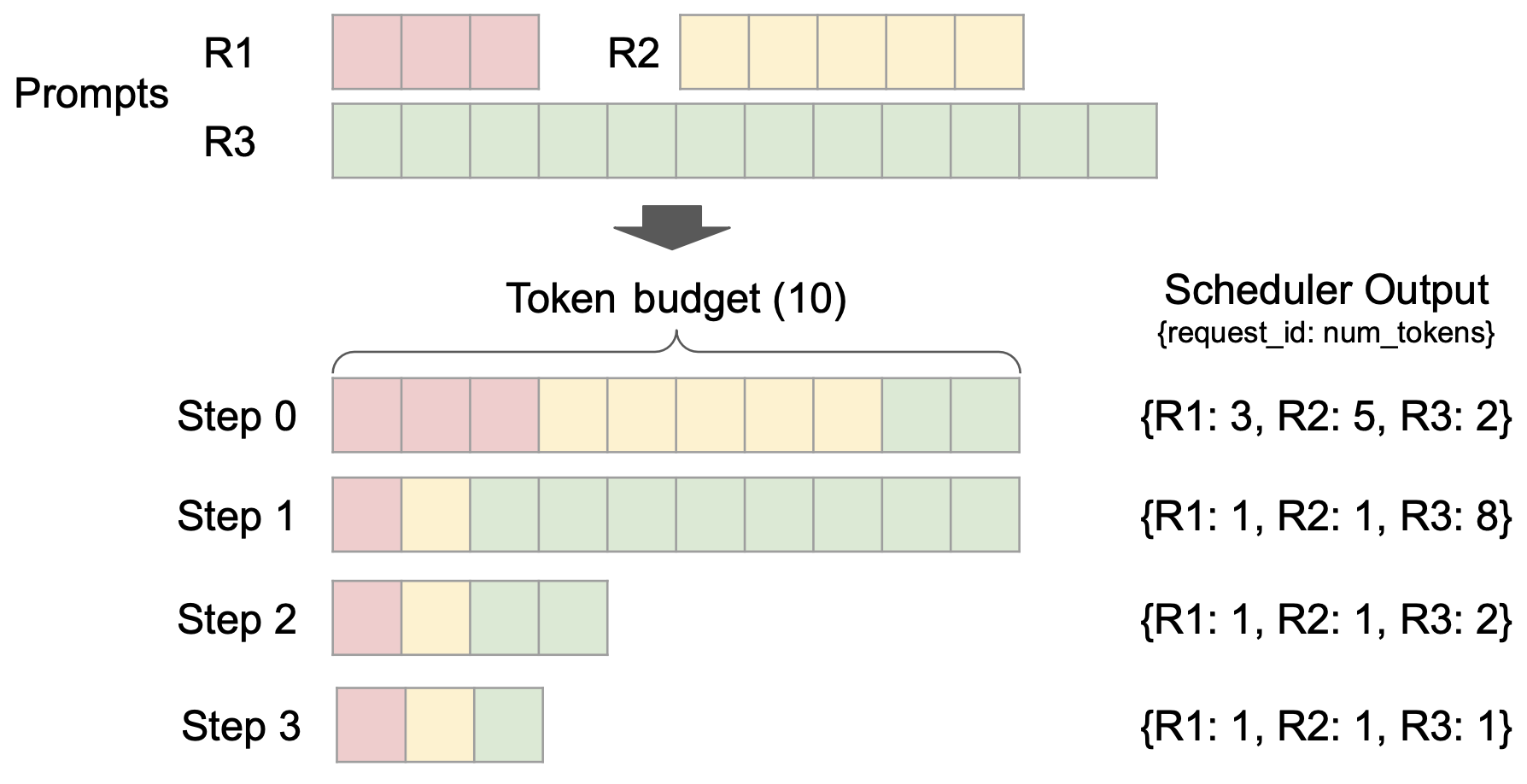
also,vLLM v1 adopts a breakthrough stage-free scheduling design.The processing of user input and model output tokens has been optimized, and the scheduling logic has been simplified. The scheduler not only supports chunked prefill and prefix caching, but also performs speculative decoding, effectively improving inference efficiency.
The optimization of the cache mechanism is another highlight. vLLM v1 implements zero-overhead prefix caching.Even in long text reasoning scenarios with extremely low cache hit rates, it can effectively avoid repeated calculations and improve reasoning consistency and efficiency.
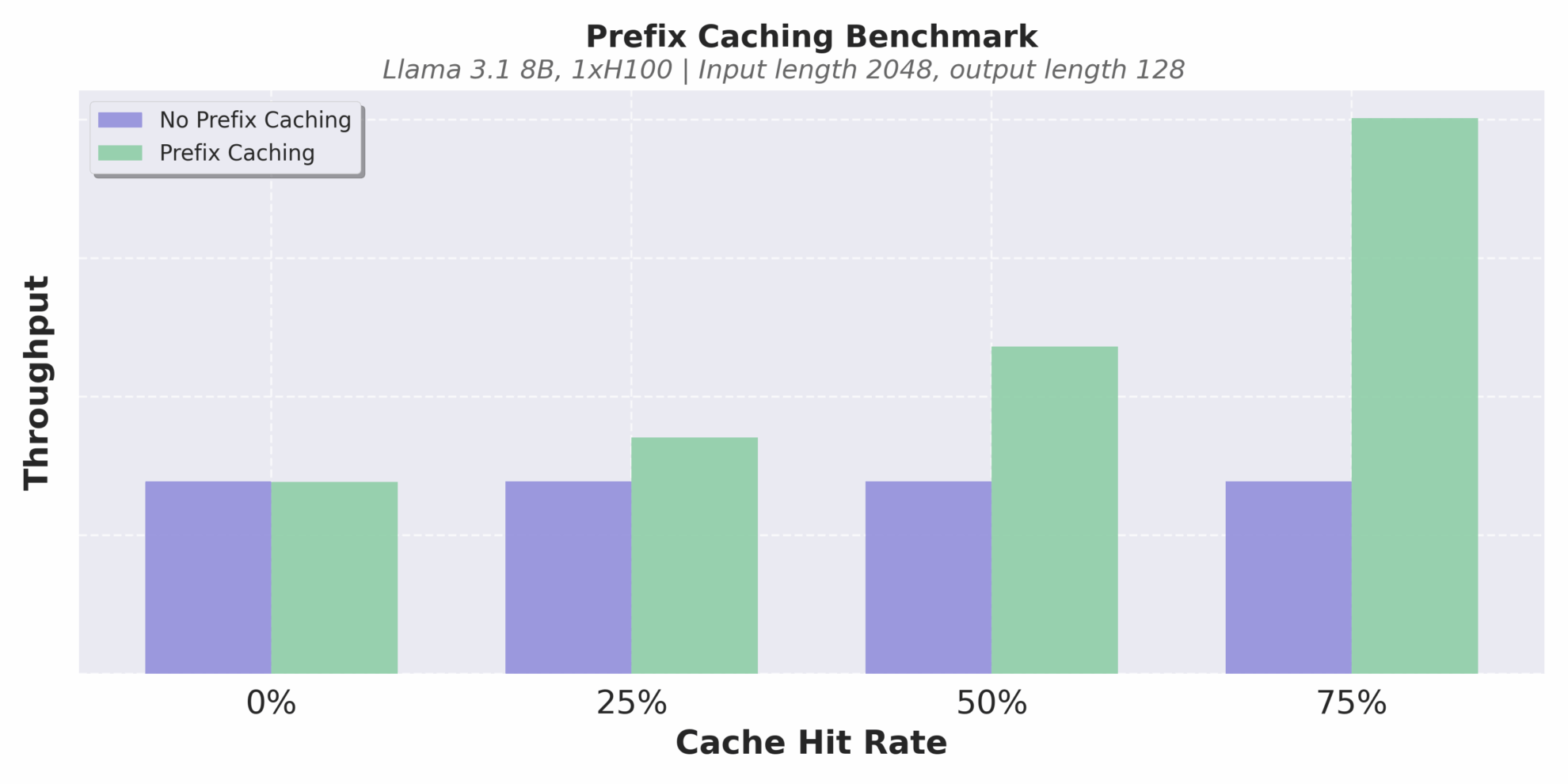
Throughput at different cache hit rates
As shown in the figure below, the throughput of vLLM v1 is increased by up to 1.7 times compared to v0, especially in high QPS conditions, the performance improvement is more significant. It should be noted that as an alpha version, vLLM v1 is still under active development and may have stability and compatibility issues, but its architecture evolution direction has clearly pointed to high performance, high maintainability and high modularity, laying a solid foundation for the subsequent team to quickly develop new features.
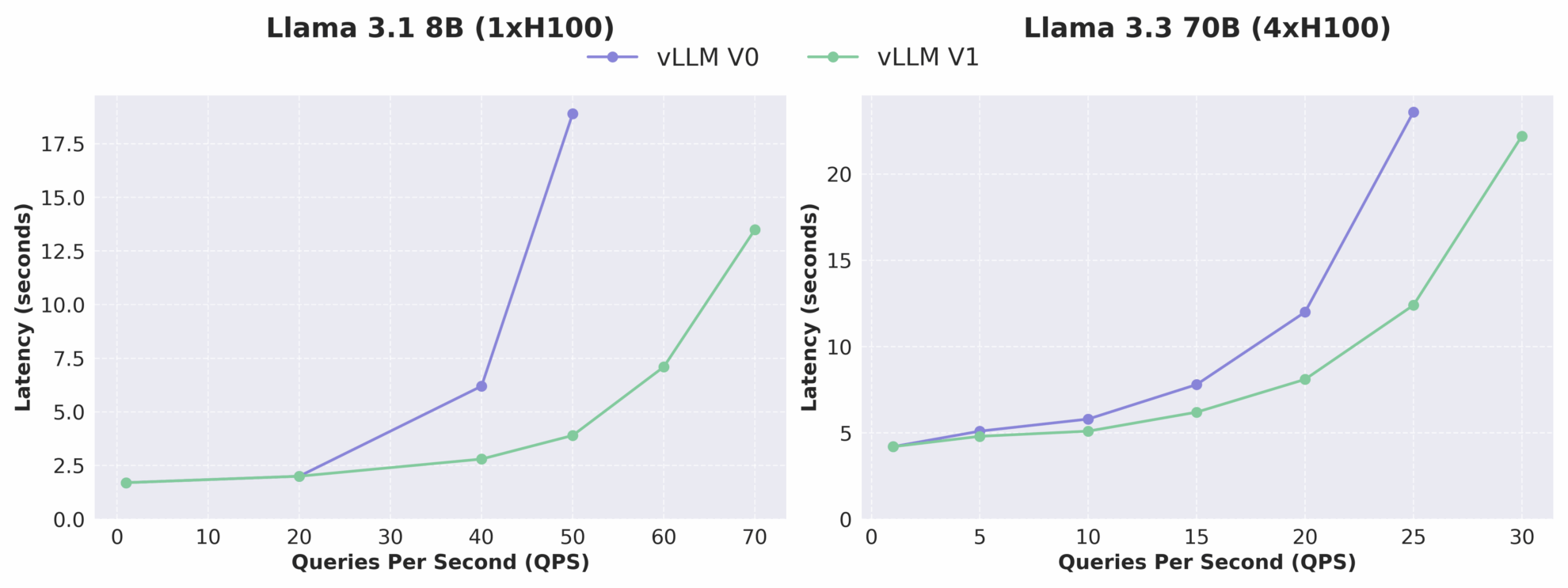
Comparison of latency-QPS relationship between vLLM V0 and V1
Just last month, the vLLM team also made a minor version update, focusing on improving model compatibility and inference stability. The updated vLLM v0.8.5 version introduced first-day support for Qwen3 and Qwen3MoE models, added fusion FP8_W8A8 MoE kernel configuration, fixed key errors in multimodal scenarios, and further enhanced performance robustness in production environments.
In order to help you get started with vLLM more efficiently, the editor has compiled a series of practical tutorials and model cases, covering the complete process from basic installation to inference deployment.Help everyone get started quickly and gain in-depth understanding. Interested friends, come and experience it!
More vLLM Chinese documents and tutorials can be found at:
Basic Tutorial
1 . vLLM Getting Started Tutorial: A Step-by-Step Guide for Beginners
* Online operation:https://go.hyper.ai/Jy22B
This tutorial shows step-by-step how to configure and run vLLM, providing a complete getting started guide for installing vLLM, model inference, starting the vLLM server, and how to make requests.
2 . Using vLLM to reason about Qwen2.5
* Online operation:https://go.hyper.ai/SwVEa
This tutorial shows in detail how to perform reasoning tasks on a large language model with 3B parameters, including model loading, data preparation, reasoning process optimization, and result extraction and evaluation.
3 . Loading large models using vLLM , Perform few-shot learning
* Online operation:https://go.hyper.ai/OmVjM
This tutorial uses vLLM to load the Qwen2.5-3B-Instruct-AWQ model for few-shot learning. It explains in detail how to retrieve training data to obtain similar questions to build dialogues, use the model to generate different outputs, infer misunderstandings and combine related methods for integrated ranking, etc., to achieve a complete process from data preparation to result submission.
4 . Combining LangChain with vLLM , Tutorial
* Online operation:https://go.hyper.ai/Y1EbK
This tutorial focuses on using LangChain with vLLM, aiming to simplify and accelerate smart LLM application development, covering a wide range of content from basic settings to advanced functional applications.
Large model deployment
1 . Deploy Qwen3-30B-A3B using vLLM
* Issuing Agency:Alibaba Qwen Team
* Online operation:https://go.hyper.ai/6Ttdh
Qwen3-235B-A22B showed comparable capabilities to DeepSeek-R1, o1, o3-mini, Grok-3, and Gemini-2.5-Pro in benchmarks such as code, mathematics, and general capabilities. It is worth mentioning that Qwen3-30B-A3B has only 10% of the number of activation parameters of QwQ-32B, but it performs better, and even a small model like Qwen3-4B can match the performance of Qwen2.5-72B-Instruct.
2 . Deploy GLM-4-32B using vLLM
* Issuing Agency:Zhipu AI, Tsinghua University
* Online operation:https://go.hyper.ai/HJqqO
GLM-4-32B-0414 has achieved good results in code engineering, artifact generation, function calling, search-based question answering, and report generation. In particular, in several benchmarks such as code generation or specific question answering tasks, GLM-4-32B-Base-0414 achieves comparable performance to larger models such as GPT-4o and DeepSeek-V3-0324 (671B).
3 . Deployment using vLLM , DeepCoder-14B-Preview
* Issuing Agency:Agentica Team, Together AI
* Online operation:https://go.hyper.ai/sYwfO
The model is based on DeepSeek-R1-Distilled-Qwen-14B and is fine-tuned through distributed reinforcement learning (RL). It has 14 billion parameters and achieved a Pass@1 accuracy of 60.6% in the LiveCodeBench v5 test, which is comparable to OpenAI's o3-mini.
4 . Deployment using vLLM , Gemma-3-27B-IT
* Issuing Agency:MetaGPT Team
* Online operation:https://go.hyper.ai/0rZ7j
Gemma 3 is a multimodal large model that can process text and image inputs and generate text outputs. Both its pre-trained variants and instruction-tuned variants provide open weights for a variety of text generation and image understanding tasks, including question answering, summarization, and reasoning. Its relatively small size enables them to be deployed in resource-limited environments. This tutorial uses gemma-3-27b-it as a demonstration for model reasoning.
More Applications
1 .OpenManus + QwQ-32B , Implementing AI Agent
* Issuing Agency:MetaGPT Team
* Online operation:https://go.hyper.ai/RqNME
OpenManus is an open source project launched by the MetaGPT team in March 2025. It aims to replicate the core functions of Manus and provide users with an agent solution that does not require an invitation code and can be deployed locally. QwQ is a reasoning model of the Qwen series. Compared with traditional instruction tuning models, QwQ has thinking and reasoning capabilities, and can achieve significant performance improvements in downstream tasks, especially difficult problems. This tutorial provides reasoning services for OpenManus based on the QwQ-32B model and gpt-4o.
2 .RolmOCR Cross-scenario ultra-fast OCR , New open source identification benchmark
* Issuing Agency:Reducto AI
* Online operation:https://go.hyper.ai/U3HRH
RolmOCR is an open source OCR tool developed based on the Qwen2.5-VL-7B visual language model. It can extract text from images and PDFs quickly and with low memory usage, outperforming similar tools such as olmOCR. RolmOCR does not rely on PDF metadata, simplifies the process and supports multiple document types, such as handwritten notes and academic papers.
The above is the vLLM-related tutorial prepared by the editor. If you are interested, come and experience it yourself!
In order to help domestic users better understand and apply vLLM,HyperAI community volunteers have collaborated to complete the first vLLM Chinese document, which is now fully available on hyper.ai.The content covers model principles, deployment tutorials and version interpretations, providing Chinese developers with a systematic learning path and practical resources.
More vLLM Chinese documents and tutorials can be found at:https://vllm.hyper.ai








