Command Palette
Search for a command to run...
Online Tutorials | Qwen3 Has Nearly 20k Stars, and Netizens Test It: It Can Solve More Difficult Problems Faster Than Llama

In the early morning of April 29,The Qwen3 model "family" has finally been officially unveiled, with a total of 8 hybrid inference models all open source.In just one day, it has gained nearly 20k stars on GitHub. In addition to its extremely high discussion popularity, Qwen3 has become the king of open source large models with its improved performance and reduced deployment costs.
* The open source version includes 2 MoE models: Qwen3-235B-A22B and Qwen3-30B-A3B; 6 Dense models: Qwen3-32B, Qwen3-14B, Qwen3-8B, Qwen3-4B, Qwen3-1.7B and Qwen3-0.6B.
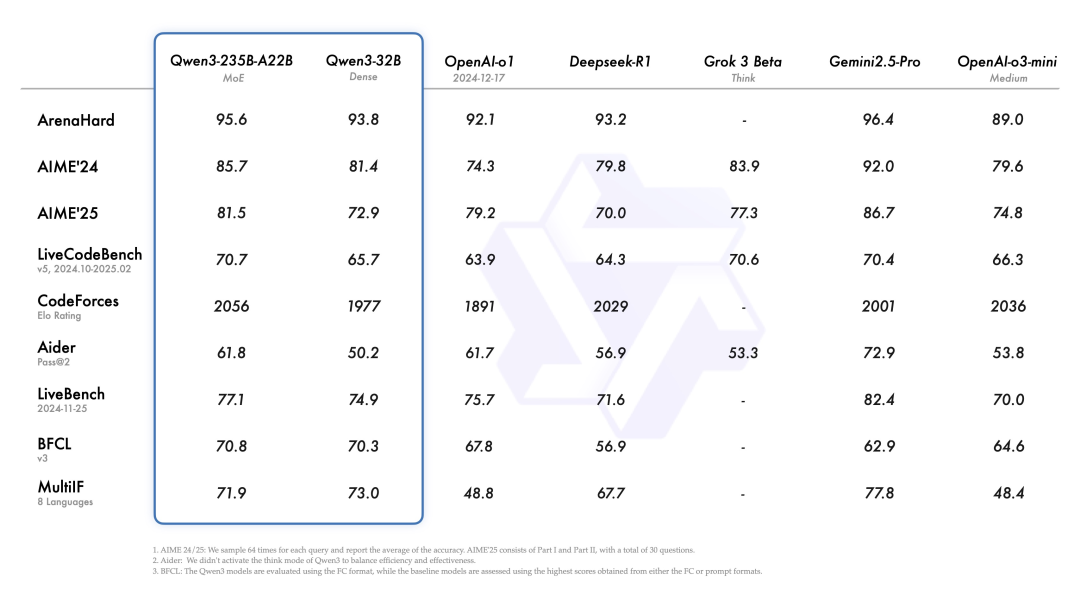
According to official data,The flagship model, Qwen3-235B-A22B, showed comparable capabilities to DeepSeek-R1, o1, o3-mini, Grok-3, and Gemini-2.5-Pro in benchmarks such as code, math, and general capabilities.It is worth mentioning that the number of activated parameters of Qwen3-30B-A3B is only 10% of QwQ-32B, but its performance is better. Even a small model like Qwen3-4B can match the performance of Qwen2.5-72B-Instruct.
Faced with Qwen3, whose performance surpasses the two top OpenAI-o1 and DeepSeek-R1, developers around the world are eager to try it out. Many have already released first-hand test reviews, which can be described as "rave reviews."

Without further ado, in order to allow more developers to conveniently experience the superb performance of Qwen3,The tutorial section of HyperAI's official website has launched "Using vLLM+Open-webUI to deploy Qwen3-30B-A3B".One-click deployment allows you to quickly experience the demo.
In addition, we have prepared surprise computing resource benefits for readers.Register with the invitation code "Qwen3-30B" to get 2 hours of dual-SIM A6000 usage time (resource validity period is 1 month).The quantity is limited, don’t miss it!
Tutorial address:
Didn’t get the invitation code?
HyperAI also provides 4 hours of RTX 4090 computing power benefits for new users, and also provides a one-click deployment tutorial for using RTX 4090 to start other Qwen 3 series models. HyperAI's official website has launched "vLLM+Open-webUI deployment of Qwen3 series models", which provides 4 types of models:
* Qwen3-8B (default)
* Qwen3-4B
* Qwen3-1.7B
* Qwen3-0.6B
HyperAI exclusive invitation link (copy and open in browser):https://go.hyper.ai/oaTGv
Tutorial address:https://go.hyper.ai/qRLDz
Demo Run
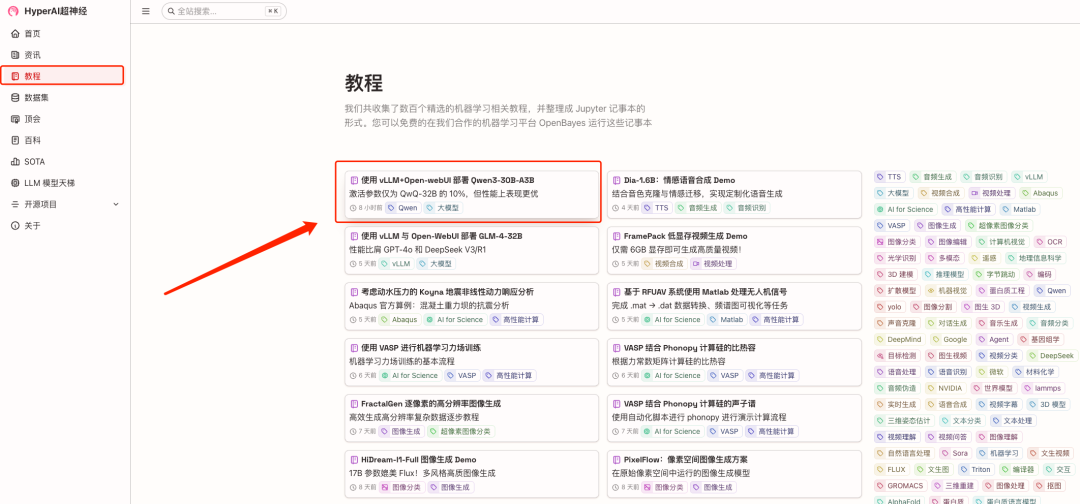
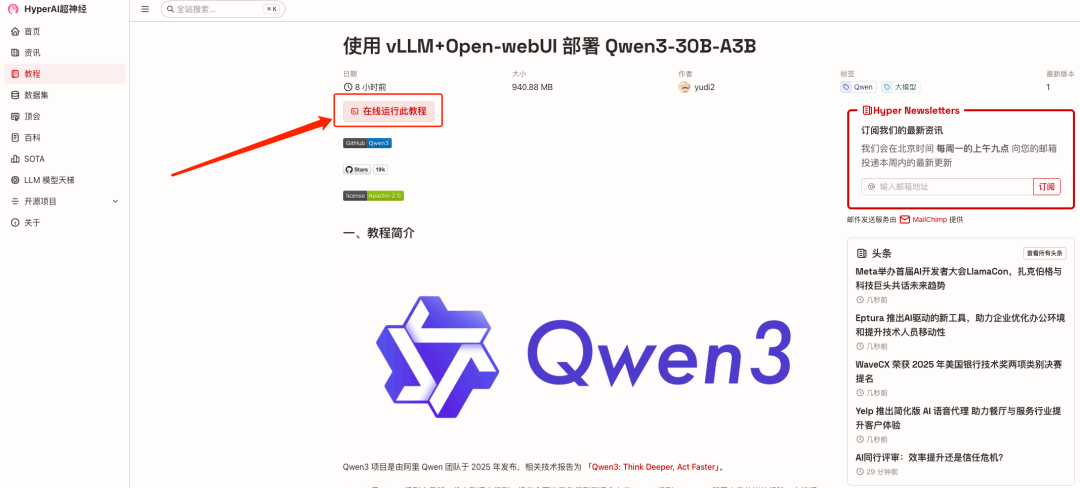
1. After entering the hyper.ai homepage, click the "Tutorial" section. After entering the page, select "Deploy Qwen3-30B-A3B using vLLM+Open-webUI" and click "Run this tutorial online".
2. After the page jumps, click "Clone" in the upper right corner to clone the tutorial into your own container.

3. Select "NVIDIA RTX A6000-2" and "vllm" image. The OpenBayes platform provides 4 billing methods. You can choose "pay as you go" or "daily/weekly/monthly" according to your needs, and click "continue". New users can register using the invitation link below to get 4 hours of RTX 4090 + 5 hours of CPU free time!
HyperAI exclusive invitation link (copy and open in browser):
https://openbayes.com/console/signup?r=Ada0322_NR0n
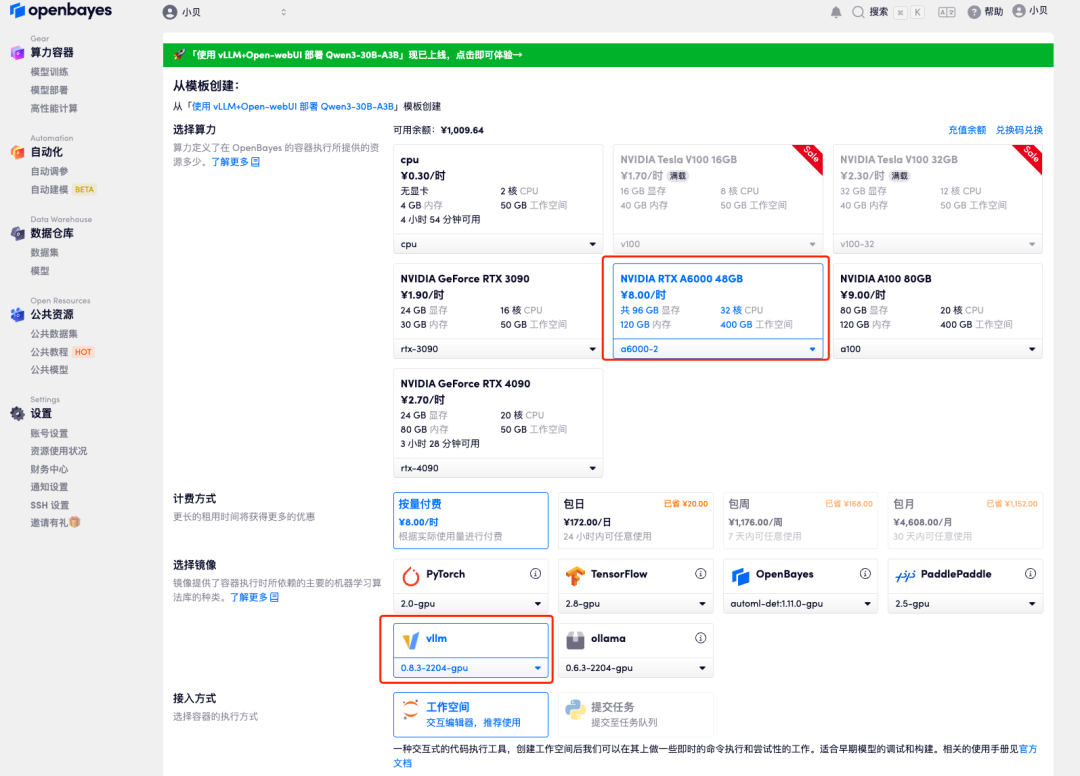
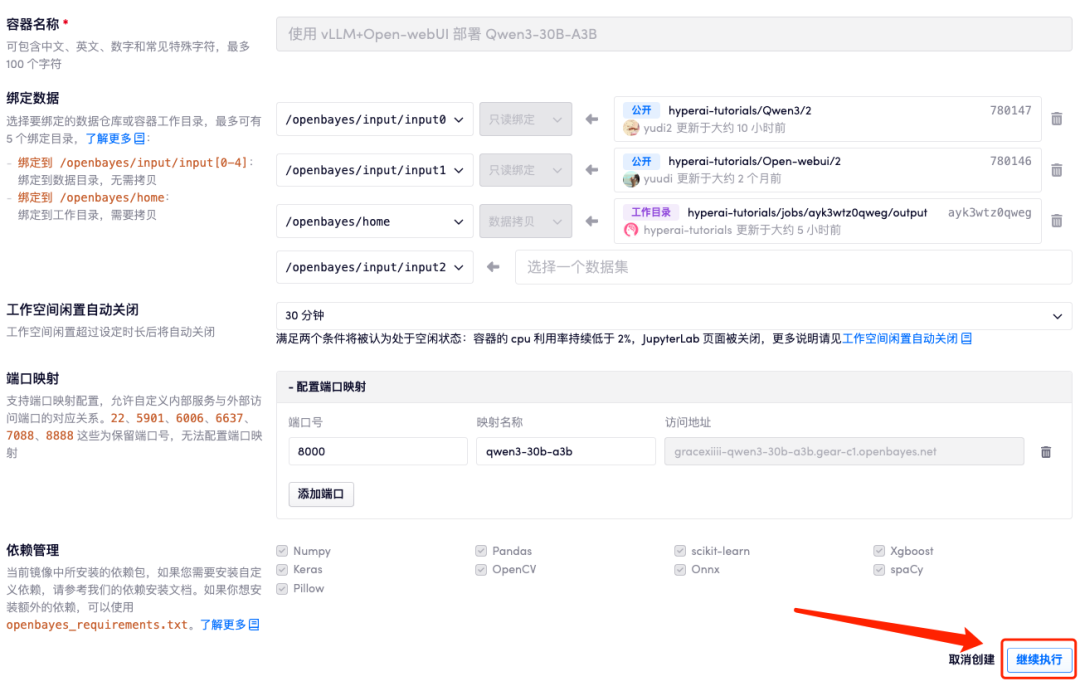
4. Wait for resources to be allocated. The first clone will take about 2 minutes. When the status changes to "Running", open the access address under "Port Mapping" to jump to the Demo page. Please note that users must complete real-name authentication before using the API address access function.
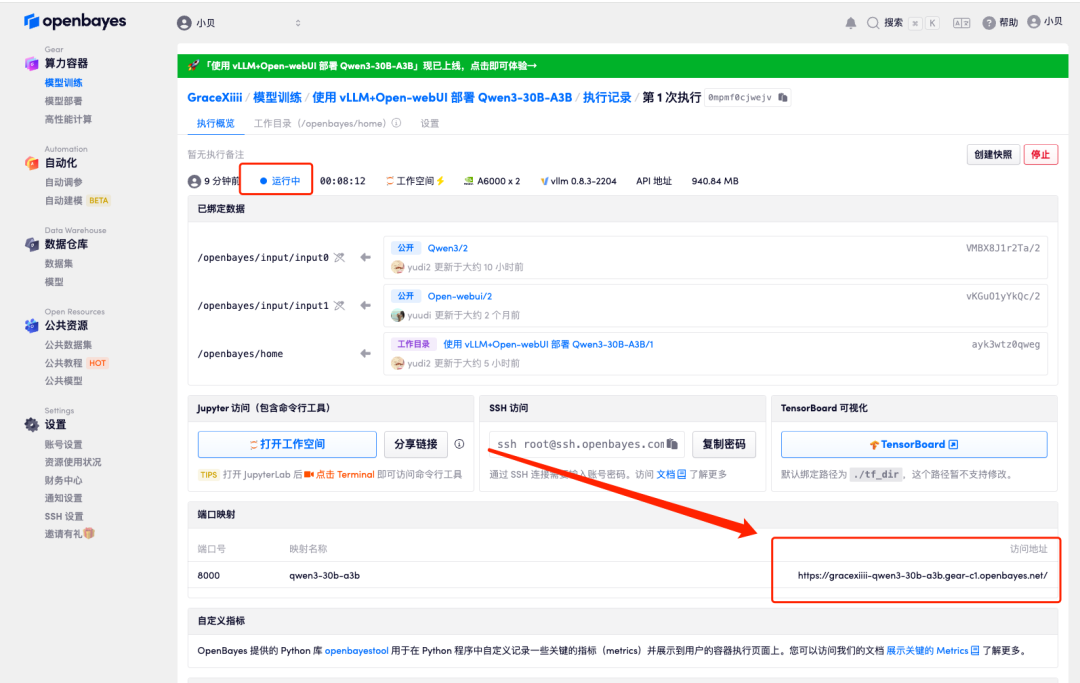

Effect display
The May Day holiday is coming soon. Type in the prompt "Help me make a travel guide to Beijing for the May Day holiday."

You can see that it has made a detailed itinerary.


The above is the tutorial recommended by HyperAI this time. Come and try it out for yourself!
Tutorial address :








