Command Palette
Search for a command to run...
Simulating Doctor Consultation, a Team From West China Hospital of Sichuan University Developed a multi-agent Dialogue Framework to Assist in Disease Diagnosis

Rare diseases have a low prevalence, lack of relevant expertise, and complex and variable individual symptoms, leading to frequent misdiagnosis and delayed diagnosis. In recent years, large language models (LLMs) such as GPT-4 have performed well in medical question answering and common disease diagnosis, but still face challenges in complex clinical tasks such as rare diseases.In order to improve the practical application capabilities of LLMs in the medical field, some researchers have begun to explore the application of multi-agent systems (MAS).
An agent is a system that can receive input and perform specific operations in order to achieve a certain goal. For example, when we communicate with ChatGPT about our condition, we are actually talking to a single agent.In contrast, the multi-agent system achieves a more dynamic and interactive diagnosis through multi-agent dialogue (MAC). This model simulates the multidisciplinary team (MDT) discussion mechanism in clinical practice, allowing multiple agents to discuss and analyze the same case, and output the diagnosis results after reaching a consensus.
Recently, teams from West China Hospital of Sichuan University, West China Biomedical Big Data Center, Zhejiang University School of Medicine, Beijing University of Posts and Telecommunications, etc.A multi-agent dialogue (MAC) framework was developed based on GPT-3.5 and GPT-4 respectively.The framework consists of Admin Agent, Supervisor Agent and multiple Doctor Agents, which jointly participate in the analysis of patient conditions. The optimal configuration of MAC is to use GPT-4 as the basic model and consist of 4 Doctor Agents and 1 Supervisor Agent.
Evaluation of the performance of GPT-3.5, GPT-4, and MAC in clinical reasoning and medical knowledge generation for 302 rare diseases is available.MAC outperformed the single-agent model in both the initial and follow-up phases.In addition, the diagnostic capabilities of MAC go beyond methods such as Chain of Thought (CoT) prompts, Self-Refine, and Self-Consistency.Can output richer diagnostic content.For example, GPT-3.5 and GPT-4 can identify pericarditis and epilepsy based on clinical presentation, but MAC, through a more in-depth analysis of the joint dialogue, can determine that the pericarditis in a specific case is caused by Bardet-Biedl syndrome.
In conclusion, MAC significantly improves the diagnostic ability of LLMs, bridges the gap between theoretical knowledge and clinical practice, and is expected to become an important auxiliary tool for doctors.The study, titled "Enhancing diagnostic capability with multi-agents conversational large language models," was published in npj Digital Medicine, a Nature journal.

Paper address:
https://www.nature.com/articles/s41746-025-01550-0#Tab6
The open source project "awesome-ai4s" brings together more than 200 AI4S paper interpretations and provides massive data sets and tools:
https://github.com/hyperai/awesome-ai4s
Dataset: Screening 302 rare diseases
This study screened 302 rare diseases from the Orphanet database as research objects. The Orphanet database is a comprehensive rare disease database co-funded by the European Commission, covering more than 7,000 diseases of 33 types.
Download the dataset of 302 rare disease cases:
https://go.hyper.ai/EETet
After determining the target disease, the research team searched the Medline database for clinical case reports published after January 2022. By extracting structured data from these case reports, the team collected detailed information on patient demographics, clinical manifestations, medical history, physical examination results, and various auxiliary examination results (including genetic testing, pathological biopsy, and radiological examinations), and recorded the final diagnosis information.
To comprehensively evaluate the application value of large language models (LLM) in clinical settings, the research team designed a two-stage clinical consultation simulation experiment, in which each case was tested in primary consultation and follow-up consultation settings:
* The first stage simulates the initial consultation scenario (first visit),The main purpose is to investigate the performance of LLM in patients who present for the first time and have limited clinical information. The task of LLMs is to come up with a most likely diagnosis, several possible diagnoses, and further diagnoses.
* The second stage simulates the follow-up consultation scenario (re-examination).To evaluate the diagnostic ability of LLMs after obtaining complete patient information (including various test results). The task of LLMs is to come up with 1 most likely diagnosis and several possible diagnoses.
This phased study design can not only test the initial judgment ability of LLM under incomplete information conditions, but also systematically evaluate its medical reasoning and final diagnostic accuracy after fully mastering the clinical data, thus comprehensively reflecting the practical application potential of LLM in clinical decision support.

The MAC framework based on GPT-4 and with 4 Doctor Agents performed best
The research team used the structure provided by Autogen to develop two multi-agent conversation frameworks (MAC) based on GPT-3.5-turbo and GPT-4 to simulate doctor consultations. As shown in the figure below,The Admin Agent provides patient information, the Supervisor Agent initiates and supervises the joint conversation, and the three Doctor Agents discuss the patient's condition together.The dialogue will continue until the agents reach a consensus or the preset maximum number of dialogue rounds (set to 13 rounds in this study) is reached, and the final diagnosis result is output.
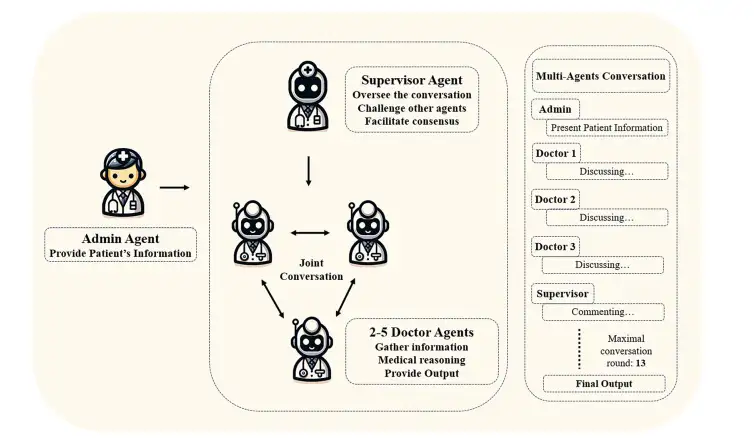
Supervisor Agent plays the role of quality control and process optimization.Its responsibilities include: (1) supervising and evaluating the recommendations and decisions made by Doctor Agents; (2) reviewing diagnostic plans and proposed examination items to identify key points that may be missed; (3) coordinating discussions among Doctor Agents to promote the improvement of diagnostic plans; (4) promoting Doctor Agents to reach a consensus on the final diagnosis and examination plan; and (5) terminating the dialogue process in a timely manner after consensus is reached.
Doctor Agents’ responsibilities include:(1) Provide diagnostic reasoning and clinical advice based on professional medical knowledge; (2) Systematically evaluate and comment on the opinions of other agents, and put forward scientific and reasonable arguments and evidence; (3) Integrate and optimize the feedback from other agents to continuously improve diagnostic output.
Using real clinical case reports from the Medline database, the researchers evaluated the knowledge and diagnostic capabilities of GPT-3.5, GPT-4, and MAC for 302 rare diseases. In addition, they studied the impact of different settings on MAC performance.
For example, the research team compared the performance differences when the MAC framework used GPT-4 and GPT-3.5 as the base model.The results show that MAC using GPT-3.5 or GPT-4 as the base model performs significantly better than their respective independent versions. In other words, the diagnostic ability of MAC is greatly enhanced compared with the single-agent model.Furthermore, when used as a base model for MAC, GPT-4 is shown to outperform GPT-3.5, implying that a more powerful base model may lead to better overall performance.
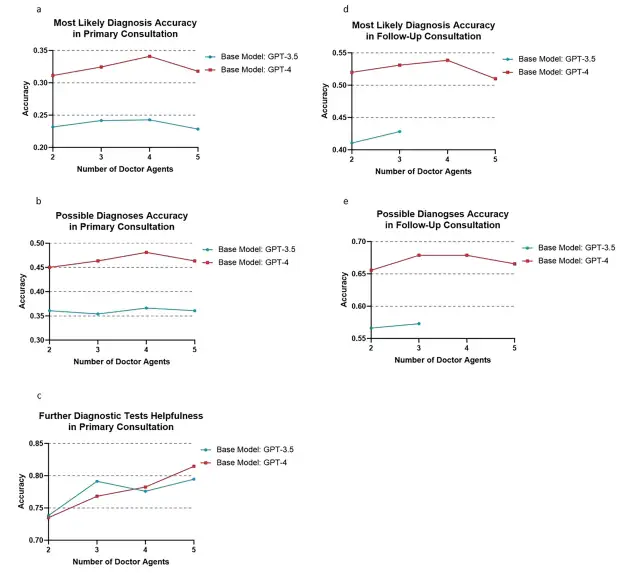
also,The researchers also studied the impact of the number of Doctor Agents on the performance of the multi-agent framework.The experimental results based on the GPT-4 model show that in terms of the most likely diagnosis accuracy, the peak value reached 34.11% with 4 agents, while it dropped slightly to 31.79% with 5 agents. Similar patterns were observed in the accuracy of possible diagnoses, with 2, 3, 4, and 5 agents having accuracies of 51.99%, 53.31%, 53.86%, and 50.99%, respectively. In the experiment based on the GPT-3.5 model, 4 Doctor Agents also showed the best performance. However, overall, the performance produced by 3 of the agents was not much different from that of 4 agents.
Furthermore, in a simulated preliminary consultation scenario involving four Doctor Agents,The GPT-4-based MAC framework achieved better performance in many key indicators: the accuracy of the most likely diagnosis reached 34.11% (GPT-3.5 was 24.28%), the accuracy of the possible diagnosis reached 48.12% (GPT-3.5 was 36.64%), and the helpfulness of further diagnostic tests reached 78.26% (GPT-3.5 was 77.37%). In terms of diagnostic performance in follow-up consultations, the GPT-4-based MAC framework with 4 Doctor Agents also performed best.
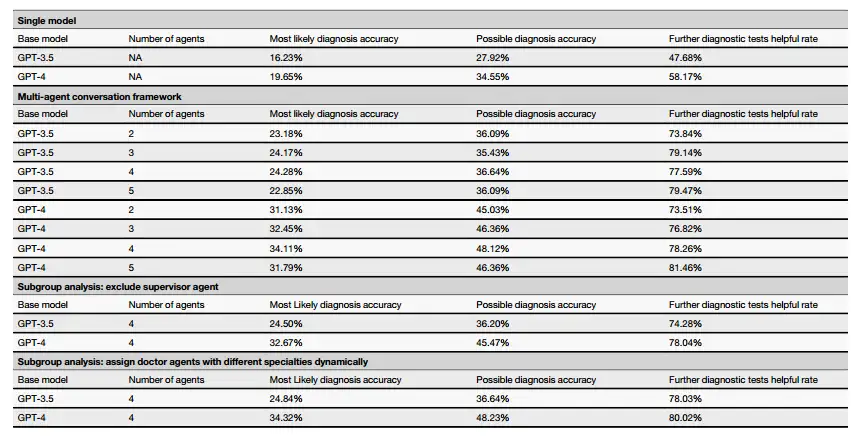
The researchers also evaluated the potential impact of removing the Supervisor Agent on the overall performance of MAC. The results showed that when the Supervisor Agent was removed, in a simulated initial consultation scenario involving four Doctor Agents,The data of the MAC framework based on GPT-4 in terms of the most likely diagnostic accuracy, possible diagnostic accuracy, and helpfulness of further diagnostic tests were 32.67%, 45.47%, and 78.04%, respectively, which are all lower than when not removed.In the follow-up consultation scenario, the MAC framework with the Supervisor Agent removed had lower most likely diagnosis accuracy and possible diagnosis accuracy than when it was not removed.This shows that Supervisor Agent improves the effectiveness of the framework.
Experimental conclusion: MAC can directly identify the root cause of the disease and has stronger diagnostic capabilities
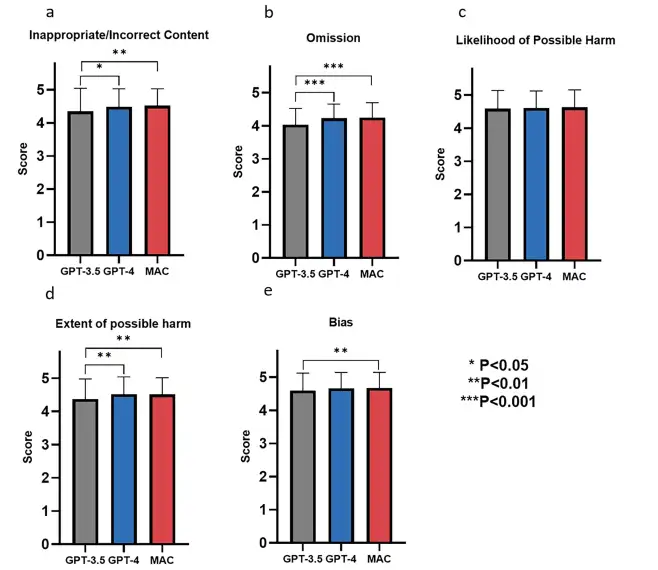
The research team evaluated the performance of GPT-3.5, GPT-4 and MAC frameworks in generating knowledge about rare diseases, including disease definition, epidemiology, clinical features, etiology, diagnostic methods, differential diagnosis, prenatal diagnosis, genetic counseling, treatment management and prognosis. The results show that, as shown in the figure below, these models performed well in all evaluation dimensions, with scores of more than 4 points for each indicator. In addition,They demonstrated high levels of content accuracy (inappropriate/incorrect content), information completeness (omissions), safety (likelihood and magnitude of possible harm), and objectivity (bias).
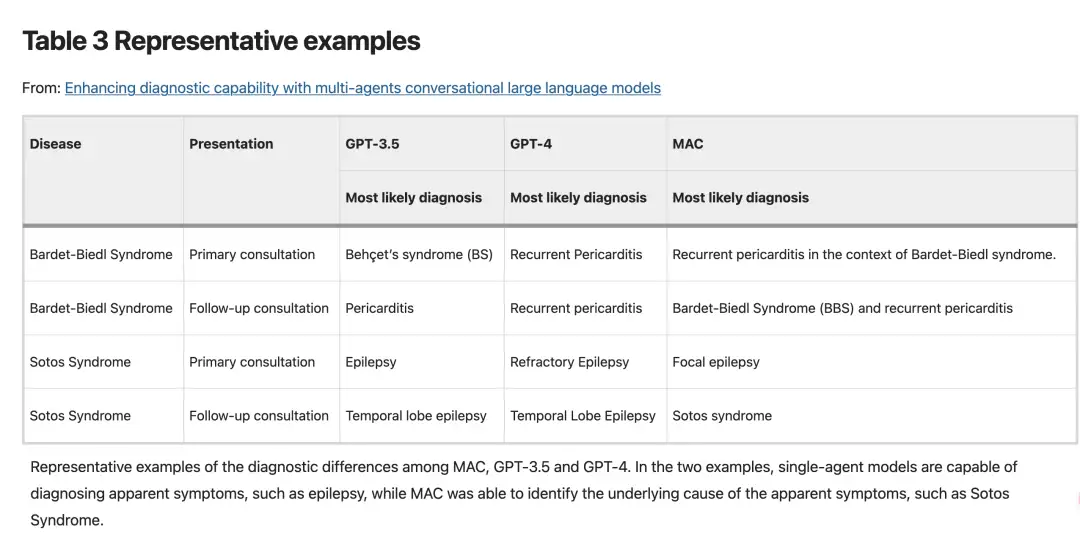
In specific case disease diagnosis, as shown in the figure below, the researchers found that GPT-3.5 and GPT-4 were able to diagnose diseases based on obvious symptoms, such as identifying pericarditis and epilepsy through clinical manifestations, however, they were insufficient in exploring the root causes of the disease.In contrast, the MAC framework provides a more in-depth analysis through joint dialogue, which can determine that the pericarditis in a particular case is caused by Bardet-Biedl syndrome.
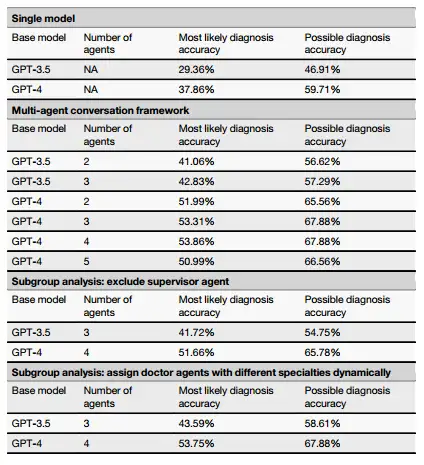
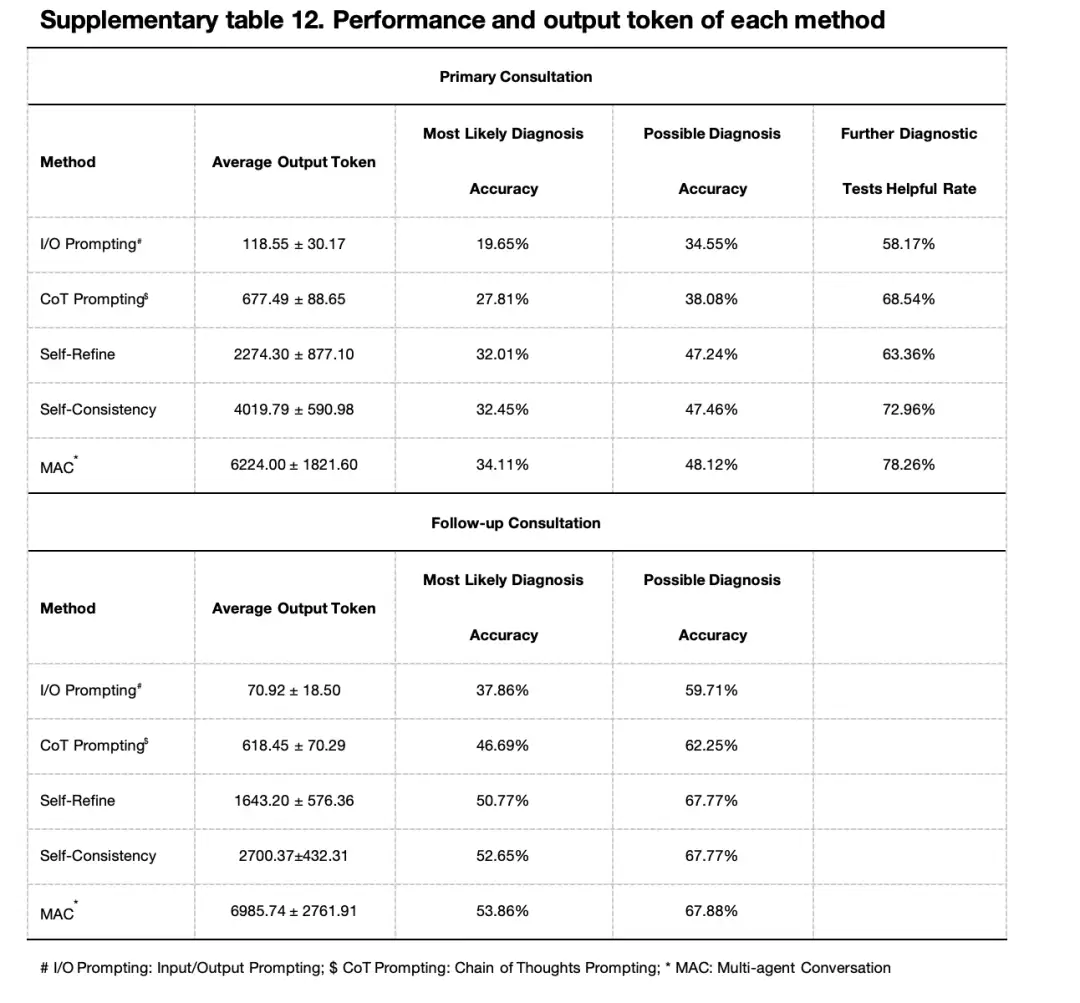
The researchers compared MAC with input/output (I/O) cues, chain of thought cues (CoT), self-optimization, and self-consistency methods.At both the initial and follow-up consultations, MAC performed best in terms of most likely diagnosis, possible diagnosis, and effectiveness of further diagnostic testing.
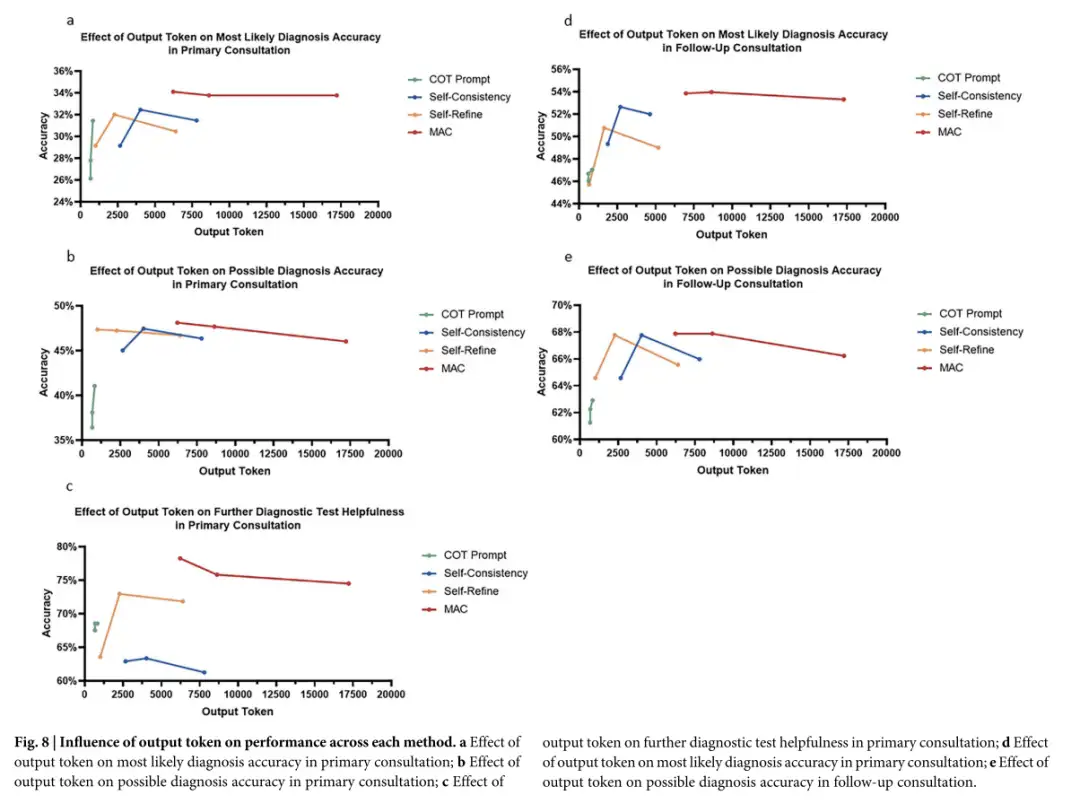
In addition, MAC outputs more tokens. The increased output not only helps explore different reasoning paths, but also makes it possible to reflect on and correct previous outputs, which can increase the depth of analysis and improve the ability to identify the root causes of neglected diseases. However, the study also showed thatAlthough increasing the number of LLM calls and thus generating more tokens can improve MAC performance, the magnitude of this improvement is limited by the type of task and the refinement method used.
In summary, this study successfully developed a multi-agent dialogue framework (MAC) for disease diagnosis, which can provide valuable diagnostic suggestions and recommend further diagnosis at different stages of clinical consultation, and is applicable to all types of rare diseases. In addition, compared with existing methods such as chain of thoughts (CoT), self-optimization and self-consistency,MAC not only has higher diagnostic accuracy, but also generates richer and more comprehensive diagnostic content.This framework significantly improves the clinical diagnostic capabilities of large language models.
Multi-agent systems have great application potential in the medical field
In recent years, multi-agent systems have shown promising progress in the field of medical decision-making and diagnosis. Several important frameworks have emerged and adopted different strategies to use large language models to perform clinical tasks. For example, Shanghai Jiao Tong University proposed MedAgents, a multidisciplinary collaboration framework for the medical field. This framework allows LLM-based agents to conduct multiple rounds of collaborative discussions in a role-playing environment, significantly enhancing the performance of LLM in zero-shot medical question answering. The research was published on arXiv under the title "MedAgents: Large Language Models as Collaborators for Zero-shot Medical Reasoning".
Paper address:
https://arxiv.org/abs/2311.10537
Different from MedAgents and other platforms that focus on medical questions and answers,The MAC framework focuses on diagnostic tasks, prompting multiple agents to analyze, interactively discuss, and provide open-ended diagnostic suggestions in the same clinical context.In terms of the architecture design of the intelligent agent, MAC includes multiple Doctor Agents and a Supervisor Agent, while other frameworks use different settings, such as creating separate Agents for questions and answers. The frameworks also differ in the way they reach consensus. For example, MedAgents continuously optimizes answers through iterative revisions until all experts reach a consensus, while MAC relies on the Supervisor Agent to determine when the Doctor Agents have reached sufficient consensus.
Although these multi-agent systems have their own characteristics in configuration and goals, they have great potential for application in the medical field, and further research is still needed in the future to fully explore and optimize their actual role in clinical environments.
The research team of the multi-agent dialogue framework mentioned above focuses on cutting-edge exploration in the intersection of generative artificial intelligence and clinical medicine.It has rich clinical data resources and advanced computing hardware facilities, and its research results have been published in high-level international academic journals.
The team is committed to applying artificial intelligence technology to effectively transform clinical medical diagnosis and treatment models and ecosystems. We sincerely invite academic institutions and enterprises to carry out project cooperation. We welcome outstanding graduate students who are interested in this field to apply. We are also recruiting passionate research assistants to join the team. Interested parties can contact [email protected].








