Command Palette
Search for a command to run...
Online Tutorial: Single Card A6000 Easily Deploys Gemma 3 and Accurately Identifies the Real Shot of Huang Renxun's Speech

On the evening of March 12,Google released the "single-card devil" Gemma 3, claiming to be the most powerful model that can run on a single GPU or TPU.The actual results also confirmed what the official blog said - its 27B version beat the 671B full-blooded DeepSeek V3, as well as o3-mini and Llama-405B, second only to DeepSeek R1, but its computing power requirements are far lower than other models. As shown in the following figure:
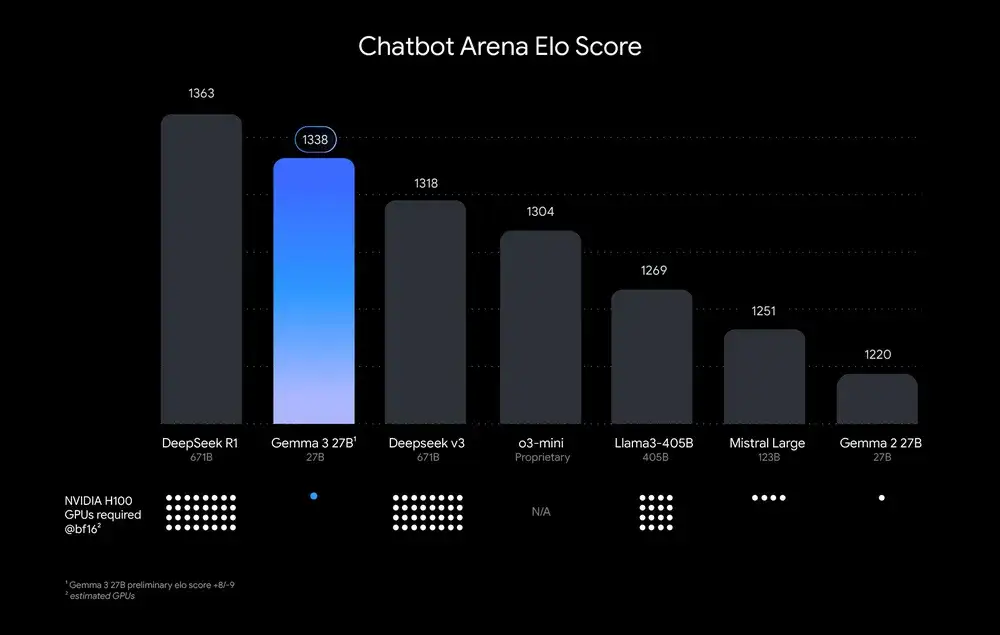
*Models are ranked by Chatbot Arena Elo score; dots represent estimated computing power requirements
Later, Google generously released the technical report of Gemma 3. It introduced that Gemma 3 combines distillation, reinforcement learning and model merging, and the performance of pre-training and instruction fine-tuning versions is better than Gemma 2. At the same time, it also introduced visual understanding capabilities and more extensive language understanding capabilities, supporting more than 140 languages and 128k long context.
In terms of application scenarios, the multimodal large model Gemma 3 can process text and image inputs and generate text outputs, which is suitable for various text generation and image understanding tasks, including question answering, summarization, and reasoning. The four parameter versions of 1B, 4B, 12B, and 27B that are open sourced this time include both pre-trained models and general instruction fine-tuning versions, which can be run quickly directly on devices such as mobile phones, laptops, and workstations.
In order to let everyone better experience this "strongest multimodal model on a single GPU",The tutorial section of HyperAI's official website has launched "Deploying Gemma-3-27B-IT using vLLM", an instruction-optimized version with 27 billion parameters.
Tutorial Link:
In addition, we have prepared a surprise bonus for everyone - 4 hours Single card RTX A6000 Free usage period (resource validity period is 1 month), new users use invitation code Gemma-3Register to get it, only 10 spots available, first come first served!
Demo Run
1. Log in to hyper.ai, on the Tutorial page, select Deploy Gemma-3-27B-IT using vLLM, and click Run this tutorial online.
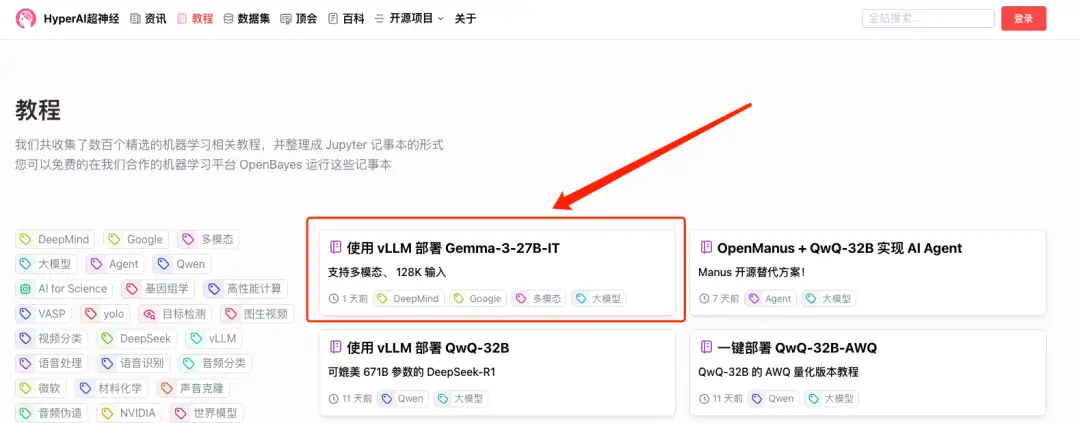
2. After the page jumps, click "Clone" in the upper right corner to clone the tutorial into your own container.
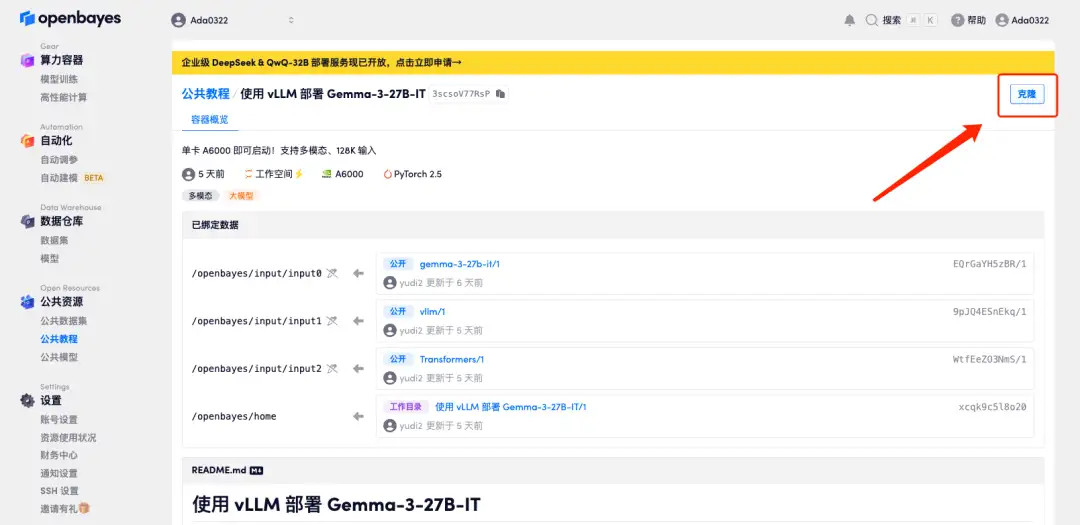
3. Select the NVIDIA A6000 and PyTorch images and click Continue. We have already imported the latest version of vLLM into the container.
The OpenBayes platform has launched a new billing method. You can choose "pay as you go" or "daily/weekly/monthly package" according to your needs. New users can register using the invitation link below to get 4 hours of RTX 4090 + 5 hours of CPU free time!
HyperAI exclusive invitation link (copy and open in browser):
https://openbayes.com/console/signup?r=Ada0322_NR0n
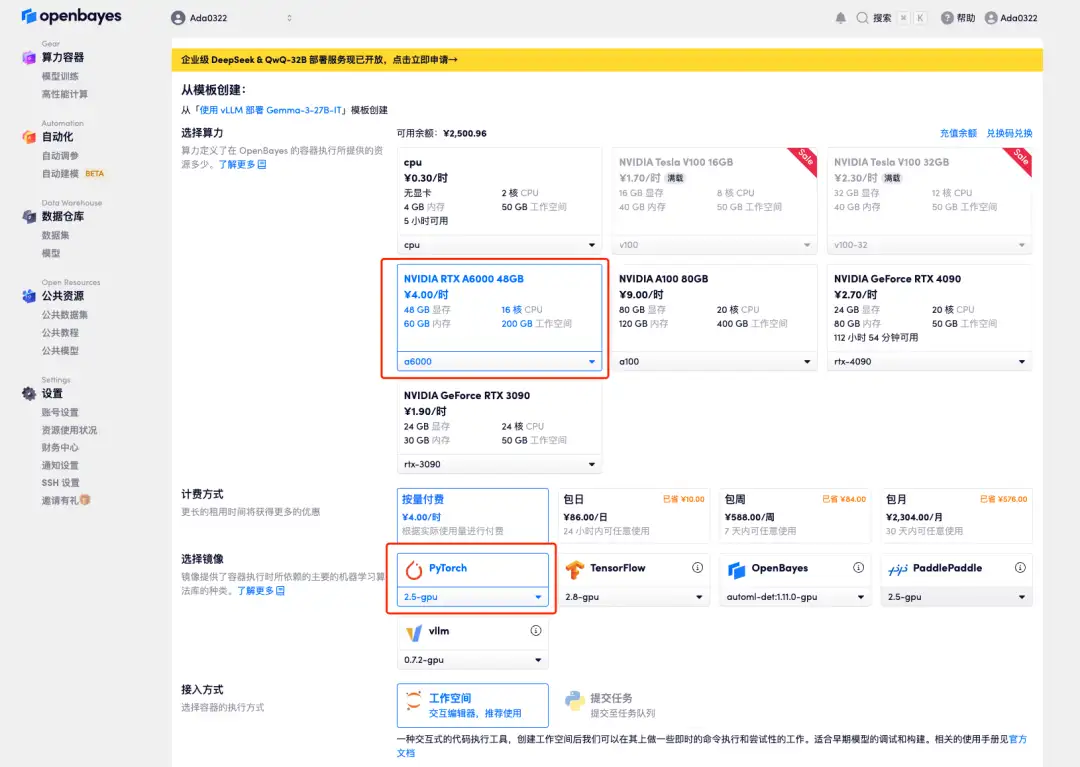
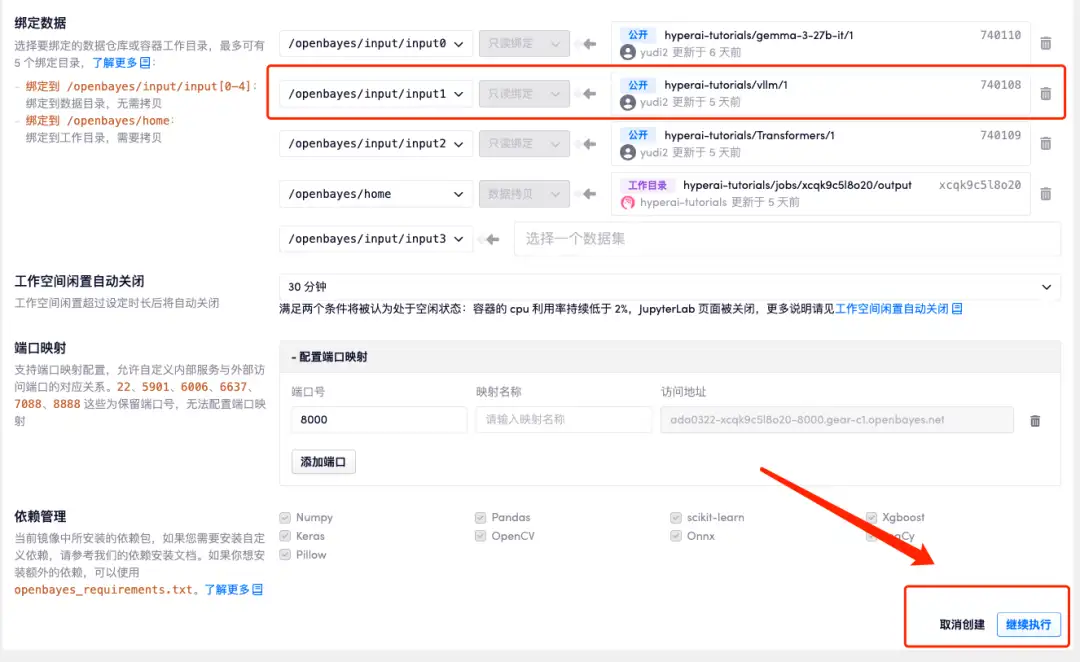
4. Wait for resources to be allocated. The first clone will take about 2 minutes. When the status changes to "Running", click the jump arrow next to "API Address" to jump to the Demo page. Due to the large model, it will take about 3 minutes to display the WebUI interface, otherwise "Bad Gateway" will be displayed. Please note that users must complete real-name authentication before using the API address access function.
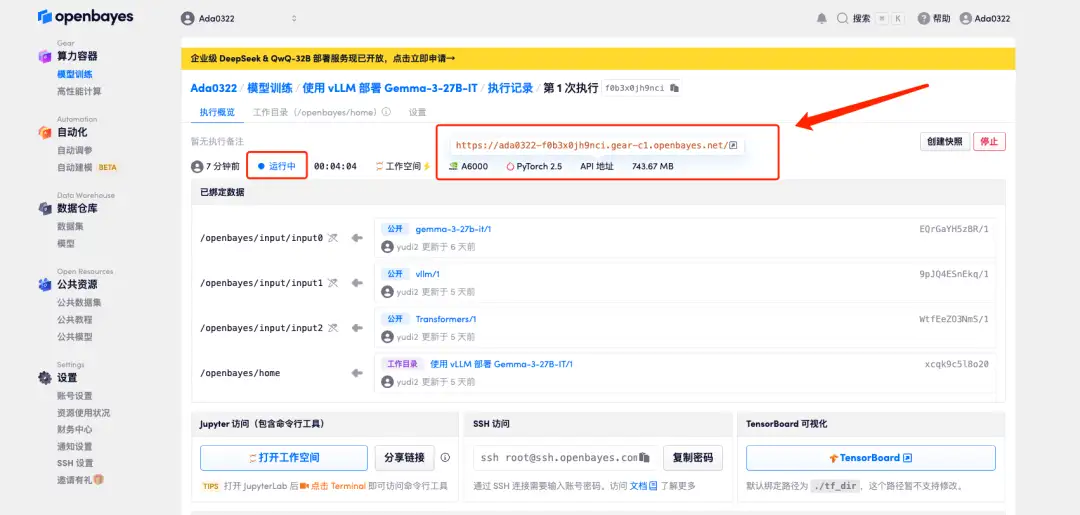
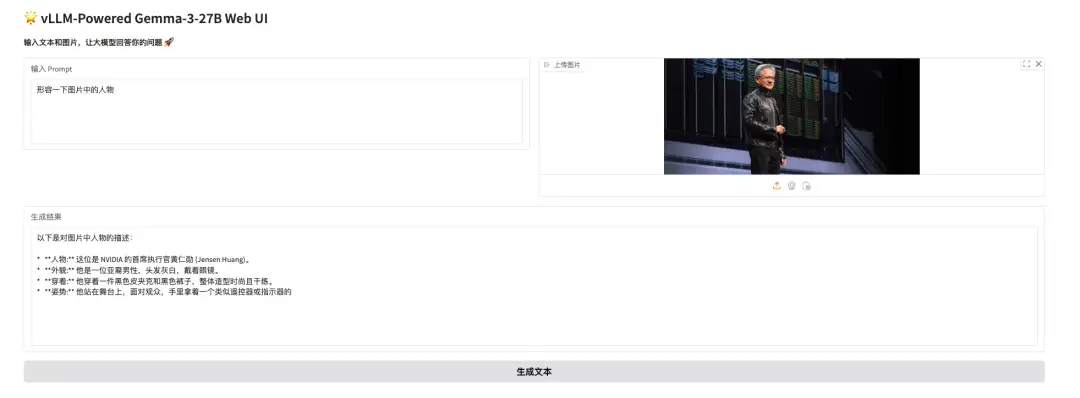
Effect display
Yesterday (March 19) in the early morning, Huang Renxun, the "Leather Swordsman", gave a keynote speech at NVIDIA GTC 2025. I used him to test Gemma 3's understanding of the picture. It not only recognized Huang at a glance, but also recognized that he was holding a remote control and standing on the stage, as shown in the following figure: