Command Palette
Search for a command to run...
Top Open Source Developers Gather! QwQ-32B Unlocks Multiple Gameplays, OpenManus Builds AI Agents at Low Cost! vLLM v1 Enables Efficient Model Reasoning

In the wave of continuous breakthroughs in the field of artificial intelligence, the Qwen team's latest model QwQ-32B, with a scale of 32 billion parameters, once again refreshed the industry's understanding of open source large models. The model has shown excellent performance in tasks such as code generation and multi-round dialogue, and its reasoning ability is comparable to the full-blooded version of DeepSeek-R1.
Not long ago,The vLLM core architecture designed specifically for accelerating reasoning on large models has undergone a major update.By optimizing execution loops, unified schedulers, and zero-overhead prefix caches, it achieves up to 1.7 times performance improvement in throughput and latency, allowing QwQ-32B to be efficiently deployed on dual-card A6000 graphics cards.
In the field of AI Agent, OpenManus has been gaining momentum since its launch. This open source project, known as the "Manus alternative",Not only does it respond to outside doubts about the closed ecosystem through technology reproduction, but it also provides developers with a "master key" to build intelligent entities at low cost through modular design and tool chain integration.
At present, HyperAI has launched two tutorials: "Using vLLM to deploy QwQ-32B" and "OpenManus + QwQ-32B to implement AI Agent". Come and try it~
Deploy QwQ-32B using vLLM
Online use:https://go.hyper.ai/8nPfC
OpenManus + QwQ-32B implements AI Agent
Online use:https://go.hyper.ai/GIX1H
From March 10th to March 15th, hyper.ai official website updated quickly:
* High-quality public datasets: 10
* High-quality tutorial selection: 4
* Community Article Selection: 6 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in March: 4
Visit the official website:hyper.ai
Selected public datasets
1. Big-Math Reinforcement Learning Mathematics Dataset
Big-Math is a large-scale, high-quality mathematics dataset designed for the application of reinforcement learning (RL) in language models. The dataset contains more than 250k high-quality math problems, each with a verifiable answer.
Direct use:https://go.hyper.ai/qtlbQ
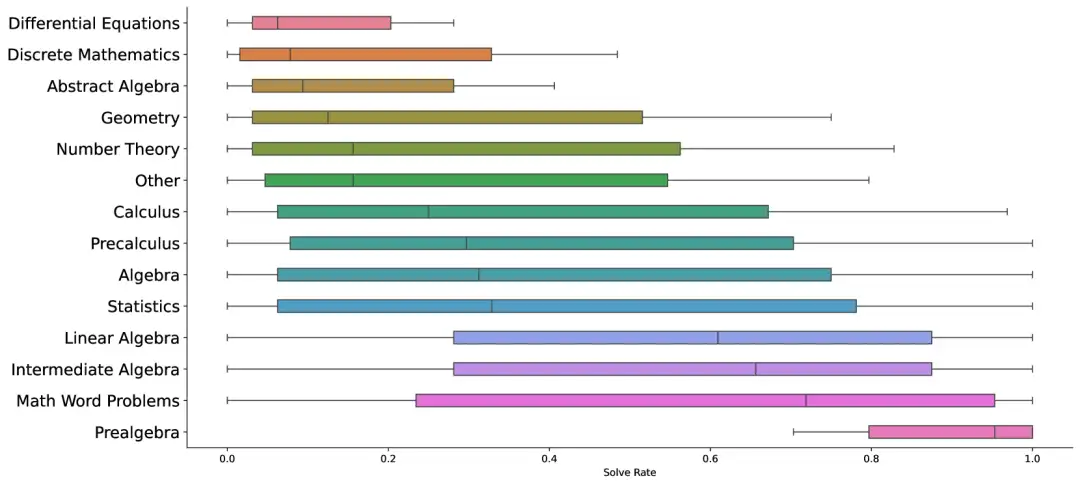
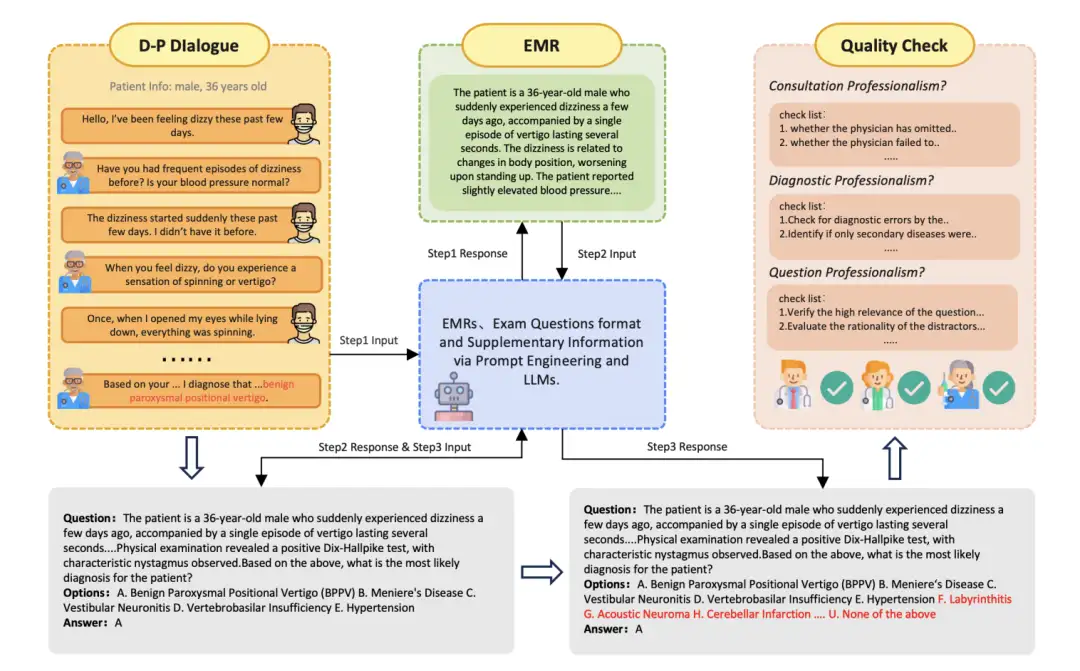
2. JMED Chinese real medical data dataset
The JMED dataset is a new dataset based on the distribution of real-world medical data. The dataset is derived from anonymous doctor-patient conversations in JD Health Internet Hospital and is filtered to retain consultations that follow a standardized diagnostic workflow.
Direct use:https://go.hyper.ai/FjZsa
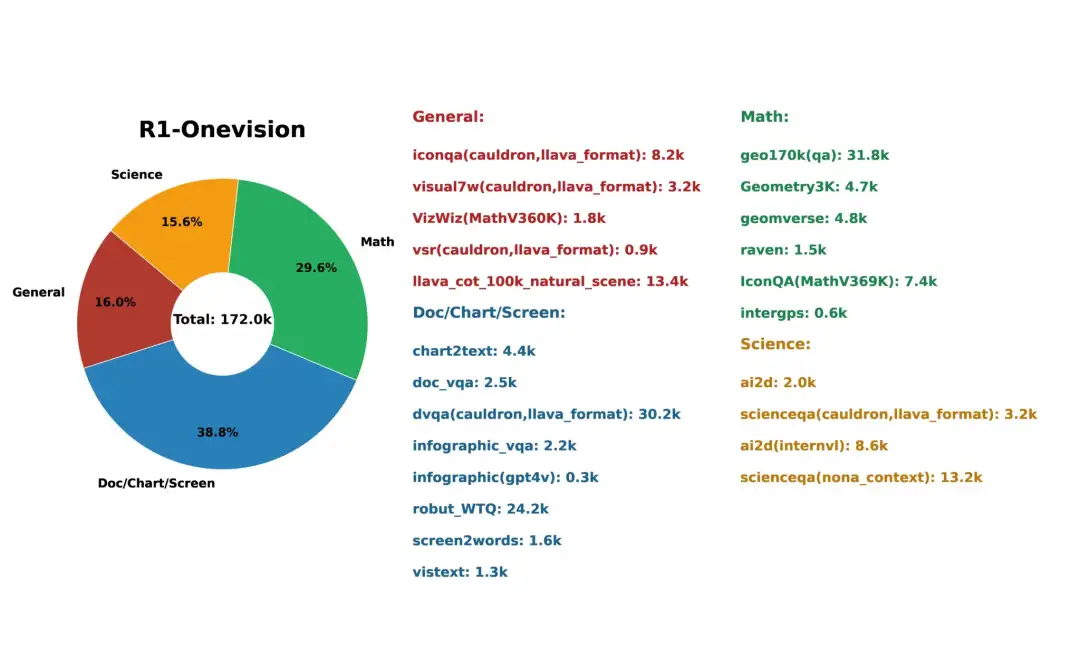
3. R1-Onevision Multimodal Reasoning Dataset
The R1-Onevision dataset is designed to endow models with advanced multimodal reasoning capabilities. It bridges the gap between visual and textual understanding through rich, context-aware reasoning tasks in multiple domains such as natural scenes, science, mathematical problems, OCR-based content, and complex diagrams.
Direct use:https://go.hyper.ai/jLbSI
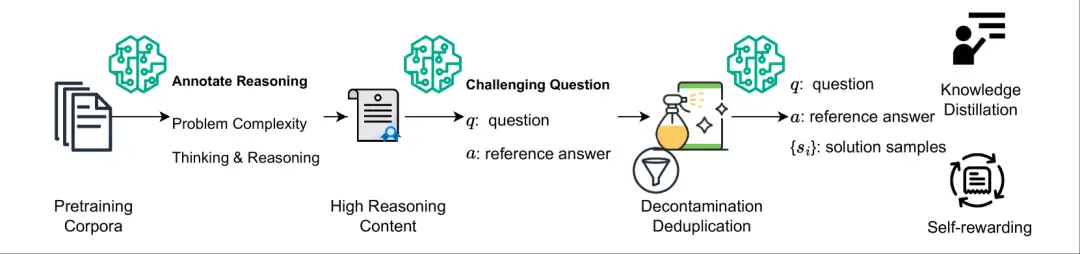
4. NaturalReasoning Natural Reasoning Dataset
The NaturalReasoning dataset is a large-scale, high-quality reasoning dataset that contains 2.8 million challenging questions covering multiple fields such as STEM fields (e.g., physics, computer science), economics, social sciences, etc. The dataset aims to generate diverse and challenging reasoning questions and their reference answers by leveraging pre-trained corpora and large language models (LLMs) without the need for additional manual annotation.
Direct use:https://go.hyper.ai/Mb6Cd
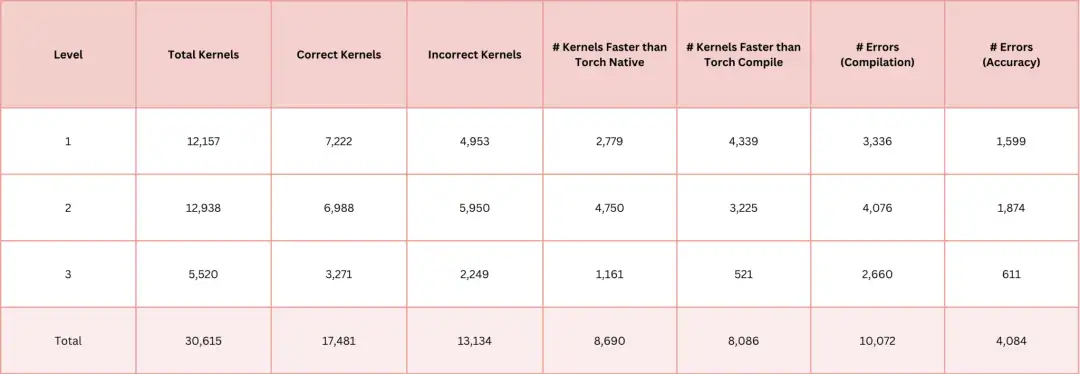
5. AI-CUDA-Engineer-Archive Kernel Collection Dataset
The AI-CUDA-Engineer-Archive dataset is a collection of CUDA kernels generated by AI, designed to facilitate subsequent training of open source models and the development of better CUDA function modules. The dataset contains more than 30,000 CUDA kernels, all of which are generated by AI-driven CUDA engineers, of which more than 17,000 kernels have been verified to be correct, and about 50% of kernel performance is better than the native runtime of PyTorch.
Direct use:https://go.hyper.ai/3lPrI
6. QM9 Quantum Chemistry Dataset
QM9 dataset is a widely used quantum chemistry dataset, which contains quantum chemistry calculation results of about 134k small organic molecules. These molecules are composed of carbon, hydrogen, nitrogen, oxygen and fluorine elements, and their molecular weight does not exceed 900 Daltons.
Direct use:https://go.hyper.ai/PZdz7
7. GEOM-Drugs 3D Molecular Conformation Dataset
The GEOM-Drugs dataset is a large 3D molecular conformation dataset containing 430,000 molecules, each of which has an average of 44 atoms. After data processing, each molecule can contain up to 181 atoms. In the experiment, the researchers collected the 30 lowest energy conformations corresponding to each molecule and required each baseline method to generate the 3D positions and types of constituent atoms of these molecules.
Direct use:https://go.hyper.ai/5B3U8
8. Fortune Telling Chinese Feng Shui Divination Dataset
The data set contains 207 questions about Feng Shui, Bazi, etc., and each question has a unique corresponding answer.
Direct use:https://go.hyper.ai/31k1P
9.SuperGPQA Subject Area Assessment Benchmark Dataset
SuperGPQA is a benchmark dataset for evaluating the performance of advanced question answering systems. It focuses on natural language processing and machine learning evaluation, and aims to test the reasoning ability and knowledge level of the model through complex cross-disciplinary questions. The dataset covers 285 graduate-level subject areas, with a variety of question types, including biology, physics, chemistry and other scientific fields.
Direct use:https://go.hyper.ai/oP1pb
10. olmOCR-mix-0225 Large-scale PDF document dataset
olmOCR-mix-0225 is a large-scale, high-quality PDF document dataset designed for training and optimizing optical character recognition (OCR) models. The dataset contains about 250k pages of PDF content, covering a variety of types such as academic papers, legal documents, manuals, etc. The dataset not only contains text content, but also extracts the coordinate information of significant elements (such as text blocks and images) in each page. This information is dynamically injected into the model prompt, which significantly reduces the model's hallucinations.
Direct use:https://go.hyper.ai/dXNkk
Selected Public Tutorials
1. One-click deployment of QwQ-32B-AWQ
QwQ-32B is the inference model of the Qwen series. Compared with traditional instruction tuning models, QwQ has thinking and reasoning capabilities, and can achieve significant performance improvements in downstream tasks, especially difficult problems. It is comparable to advanced inference models such as DeepSeek-R1 and o1-mini.
The relevant models and dependencies of this project have been deployed. After starting the container, click the API address to enter the Web interface.
Run online:https://go.hyper.ai/Q8HmJ

vLLM is an open source reasoning framework designed for efficient deployment of large language models. Its core technology significantly reduces the hardware threshold for model reasoning by optimizing memory management and computing efficiency. This tutorial uses vLLM to deploy the QwQ-32B model to further reduce deployment costs and meet the needs of more interactive scenarios.
The relevant models and dependencies of this project have been deployed. After starting the container, click the API address to enter the Web interface.
Run online:https://go.hyper.ai/8nPfC
3.OpenManus + QwQ-32B implements Al Agent
OpenManus is an open source project launched by the MetaGPT team. It aims to replicate the core functions of Manus and provide users with an intelligent agent solution that can be deployed locally without an invitation code.
Go to the official website to clone and start the container, enter the workspace, and enter the corresponding commands to experience the model.
Run online:https://go.hyper.ai/GIX1H
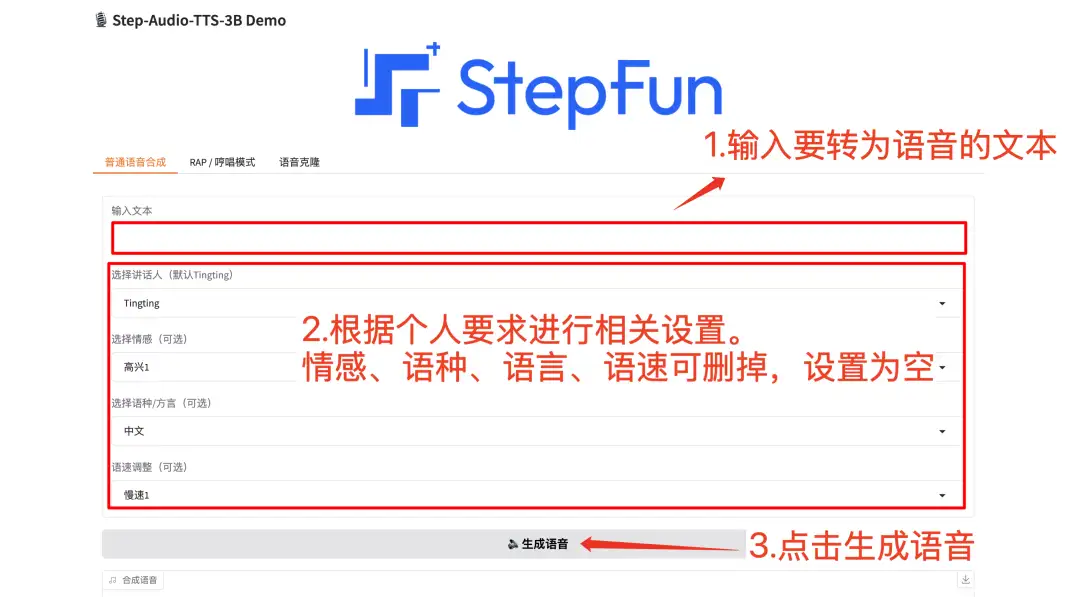
4. Step-Audio-TTS-3B Production-level dialect speech generation model
Step-Audio is the industry's first product-level open source real-time voice dialogue system that integrates speech understanding and generation control. It was open sourced by the Stepfun-AI team in 2025. It supports multi-language generation (such as Chinese, English, and Japanese), voice emotions (such as happiness and sadness), and dialects (such as Cantonese and Sichuan dialect). It can control speech speed and rhythmic style, and supports RAP and humming, etc.
Go to the official website to clone and start the container, directly copy the API address, and you can perform multi-functional speech synthesis.
Run online:https://go.hyper.ai/WiyVK
Community Articles
The team from the University of Western Australia and other institutions proposed an automated framework based on deep learning. The study used 200 skull CT scans from a hospital in Indonesia to train and test three deep learning-based network configurations. The most accurate deep learning framework was able to combine gender and skull features for judgment, with a classification accuracy of 97%, significantly higher than the 82% of human observers. This article is a detailed interpretation and sharing of the paper.
View the full report:https://go.hyper.ai/0rfjM
Researchers from Zhejiang Provincial GIS Key Laboratory proposed a deep learning model CatGWR based on attention mechanism. The model combines the spatial distance and contextual similarity between samples by introducing the attention mechanism, thereby more accurately estimating spatial non-stationarity. This provides a new perspective for geospatial modeling, especially when dealing with complex geographical phenomena, and can better capture spatial heterogeneity and contextual influences. This article is a detailed interpretation and sharing of the research.
View the full report:https://go.hyper.ai/irDAo
HyperAI has carefully compiled the most popular reasoning datasets, covering mathematics, code, science, puzzles and other fields. For practitioners and researchers who hope to effectively improve the reasoning capabilities of large models, these datasets are undoubtedly an excellent starting point. This article is the dataset download address.
View the full report:https://go.hyper.ai/XGIi8
Zhejiang University and others proposed a technique called Boltzmann alignment, which transferred knowledge from the pre-trained inverse folding model to the prediction of binding free energy. This method showed superior performance and was included in ICLR 2025, the top international academic conference in the field of artificial intelligence. This article is a detailed interpretation and sharing of the paper.
View the full report:https://go.hyper.ai/MsUDj
NVIDIA, in collaboration with MIT and others, has developed a new type of large-scale streaming protein backbone generator, Proteina. Proteina has five times the number of parameters of the RFdiffusion model, and has expanded the training data to 21 million synthetic protein structures. It has achieved SOTA performance in de novo protein backbone design, and has generated diverse and designable proteins with an unprecedented length of up to 800 residues. The results have been selected for ICLR 2025 Oral. This article is a detailed interpretation and sharing of the research.
View the full report:https://go.hyper.ai/n4fWv
Lei Jun, Zhou Hongyi, Liu Qingfeng and other industry leaders closely followed the pulse of the times and actively proposed proposals and suggestions in many key areas such as new energy vehicles, large model illusions, AI medical care, AI face replacement, and AI education. See below for more details.
View the full report:https://go.hyper.ai/EazuY
Popular Encyclopedia Articles
1. DALL-E
2. Reciprocal sorting fusion RRF
3. Pareto Front
4. Large-scale Multi-task Language Understanding (MMLU)
5. Contrastive Learning
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
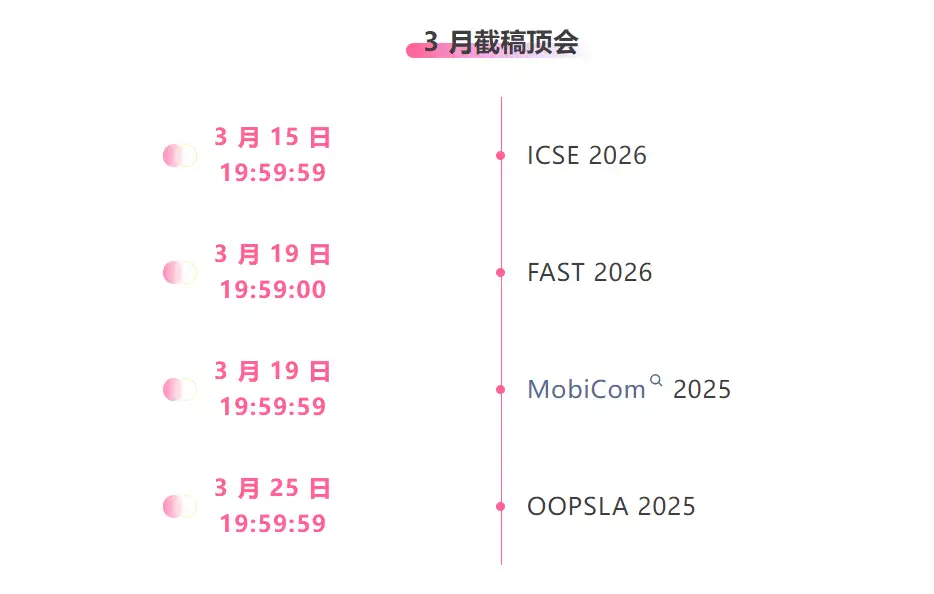
One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!








