Command Palette
Search for a command to run...
Reasoning Speed Increased by 1.7 Times, vLLM v1 Version Released! More Than 4k Annotation Steps, the First multi-modal step-by-step Reasoning Benchmark VRC-Bench Is Online

Last month, with the demand for large model reasoning surging, the AI large model reasoning framework vLLM officially ushered in version v1.0. Compared with previous versions, the computing efficiency is significantly optimized, the API design is more stable, the hardware potential is fully released, and the reasoning speed is increased by 1.7 times! It provides more powerful support for the efficient deployment of models with tens of billions of parameters.
at present,The hyper.ai official website has launched an introductory tutorial on vLLM, which will take you from installation to operation, so you can quickly master vLLM!
vLLM Getting Started Tutorial:https://go.hyper.ai/qHl62
For more vLLM Chinese documents and tutorials, please visit → https://vllm.hyper.ai
From February 5 to February 14, hyper.ai official website updates:
* High-quality public datasets: 10
* High-quality tutorial selection: 6
* Community article selection: 5 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in February: 3
Visit the official website:hyper.ai
Selected public datasets
1. VRC-Bench Visual Reasoning Benchmark Dataset
The dataset covers challenges in eight different fields, including visual reasoning, mathematical and logical reasoning, scientific reasoning, cultural and social understanding, etc. It contains more than 4k manually verified reasoning steps, which can comprehensively evaluate the accuracy and logical coherence of the model in multi-step reasoning.
Direct use:https://go.hyper.ai/AV43N

2. Terra multimodal spatiotemporal dataset
Terra is a multimodal spatiotemporal dataset with global coverage, providing 45 years of spatiotemporal data worldwide, covering 6.48 million high-resolution grid points, and aims to promote future research in spatiotemporal data mining and promote the realization of broader spatiotemporal intelligence.
Direct use:https://go.hyper.ai/9eev3

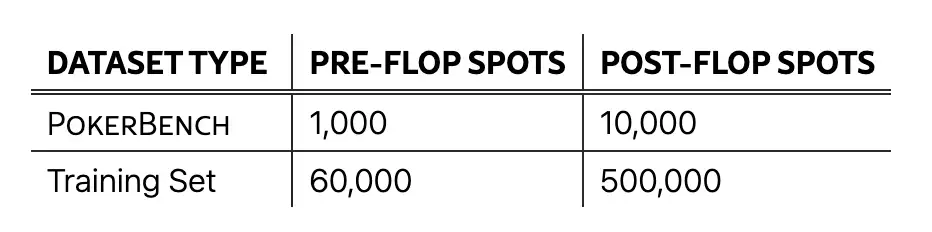
3. PokerBench poker game evaluation dataset
The dataset contains 11k key scenes, divided into 1k pre-flop and 10k post-flop scenes, covering a wide range of game situations and is designed to evaluate the performance of Large Language Models (LLMs) in complex, strategic poker games.
Direct use:https://go.hyper.ai/HK73H
4. China City Attraction Details Chinese city tourist attractions information dataset
This dataset contains tourist attraction data from 352 cities in China. The csv file for each city contains 100 locations. The data includes location name, website, address, attraction introduction, opening hours, image website, rating, recommended visit duration, recommended visit season, ticket information, tips, and other information.
Direct use:https://go.hyper.ai/uZ5Wh
5. GF-Minecraft Game Video Dataset
The dataset collects 70 hours of game videos and annotates them by executing predefined random action sequences. The dataset is preconfigured with 3 biomes (forest, plains, desert), 3 weather conditions (clear, rainy, thunderstorm), and 6 time periods (e.g. sunrise, noon, midnight), generating more than 2k video clips.
Direct use:https://go.hyper.ai/25DAe
6. NCIFD National Culture Fine-tuning Dataset
This dataset is a national culture fine-tuning dataset for large models, containing 151,159 data items, covering seven major areas: architecture, clothing, crafts, food, etiquette, language, and customs.
Direct use:https://go.hyper.ai/Vd6ZP
7. AceMath Instruct Training Data Mathematical Reasoning Dataset
This dataset is a dataset released by NVIDIA in 2025 for training the AceMath model, aiming to improve the model's performance in mathematical reasoning tasks.
Direct use:https://go.hyper.ai/pT5Tr
8. ComplexFuncBench Complex function call evaluation dataset
The dataset covers 1k complex function call samples in 5 real-world scenarios, including 600 single-domain samples, 150 each for hotels, flights, car rentals, and attractions, and 400 cross-domain samples. The taxi domain has only 2 functions, so it is only used for cross-domain.
Direct use:https://go.hyper.ai/v0p4c
9. TravelPlanner travel planning dataset
The dataset contains 1,225 carefully curated planning intentions and reference plans. The dataset is in the context of travel planning and requires a language agent to generate a comprehensive travel plan based on a given query, including transportation, daily meals, attractions, and accommodation.
Direct use:https://go.hyper.ai/22AhZ
10. Aqueous Solubility Data Inorganic Compound Dataset
This dataset contains experimental water solubility data for hundreds of inorganic compounds, collected from multiple references, suitable for the field of materials informatics. All solubility data are expressed in grams of solute per 100 grams of water.
Direct use:https://go.hyper.ai/dqL1y
Selected Public Tutorials
1. vLLM Getting Started Tutorial: A Step-by-Step Guide for Beginners
vLLM is a framework designed for accelerating the reasoning of large language models. It has attracted widespread attention worldwide due to its excellent reasoning efficiency and resource optimization capabilities. Researchers have built a high-throughput distributed LLM service engine vLLM, which achieves almost zero waste of KV cache memory and solves the memory management bottleneck problem in large language model reasoning.
This tutorial will show you step by step how to configure and run vLLM, providing a complete guide from installation to startup. Click the link below and follow the tutorial to deploy vLLM.
Run online:https://go.hyper.ai/qHl62
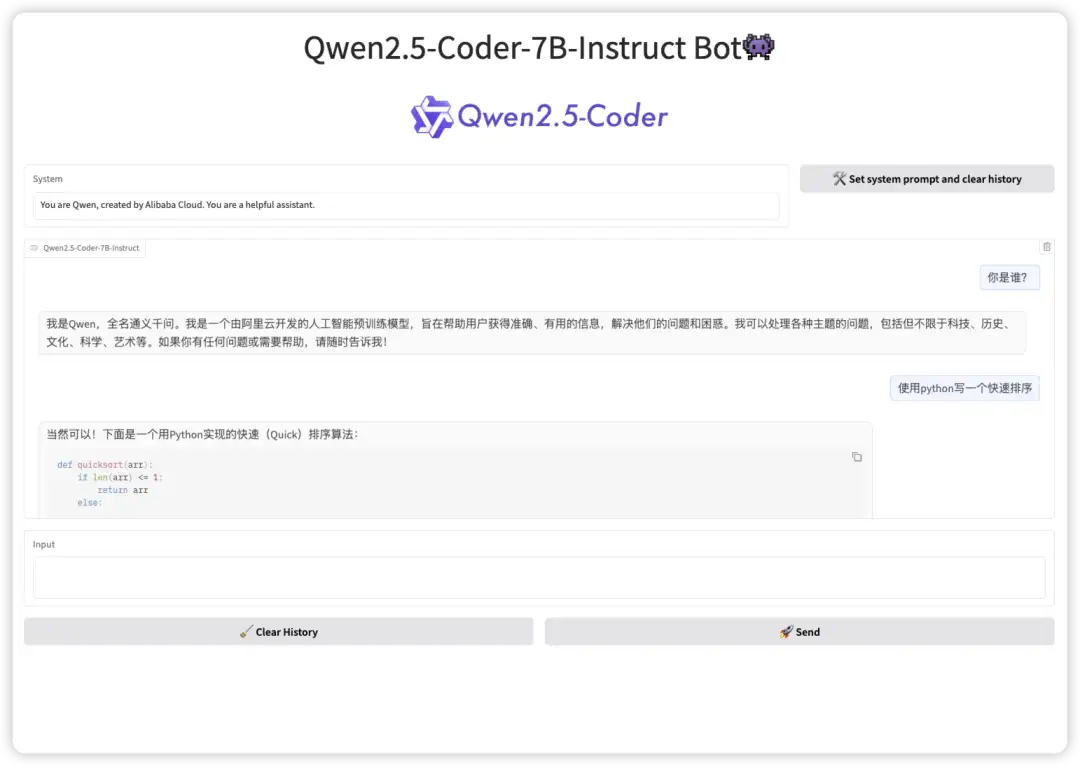
2. One-click deployment of Qwen2.5-Coder
Qwen2.5-Coder is an AI assistant with powerful code generation capabilities. It supports logically clear and grammatically standardized code output, and provides the Artifacts function to help users quickly build and implement various visual projects. In terms of mini-game development, Qwen2.5-Coder can generate game code based on game rules, graphics style, and user experience requirements. Developers can customize and optimize on this basis and quickly launch their own game works.
This project can generate a front-end interactive interface through the Gradio interface. The relevant models and dependencies have been deployed. You can start it with one click to input instructions to the model and generate the required code.
Run online:https://go.hyper.ai/JVOTN
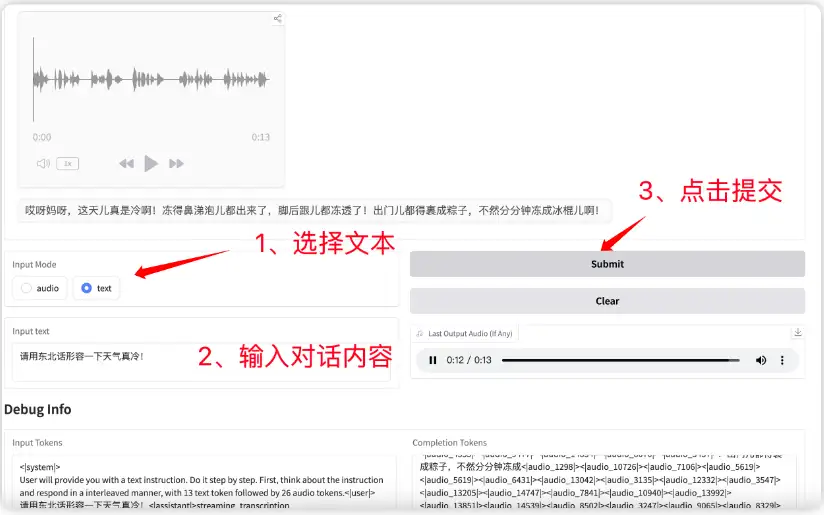
3. GLM-4-Voice End-to-end Chinese-English Conversation Model
GLM-4-Voice is an end-to-end speech model that can directly understand and generate Chinese and English speech, conduct real-time voice conversations, and follow user instructions to change speech attributes such as emotion, intonation, speaking speed, and dialect.
Go to the official website to clone and start the container, directly copy the API address, and you can communicate with the model.
Run online:https://go.hyper.ai/s4MId
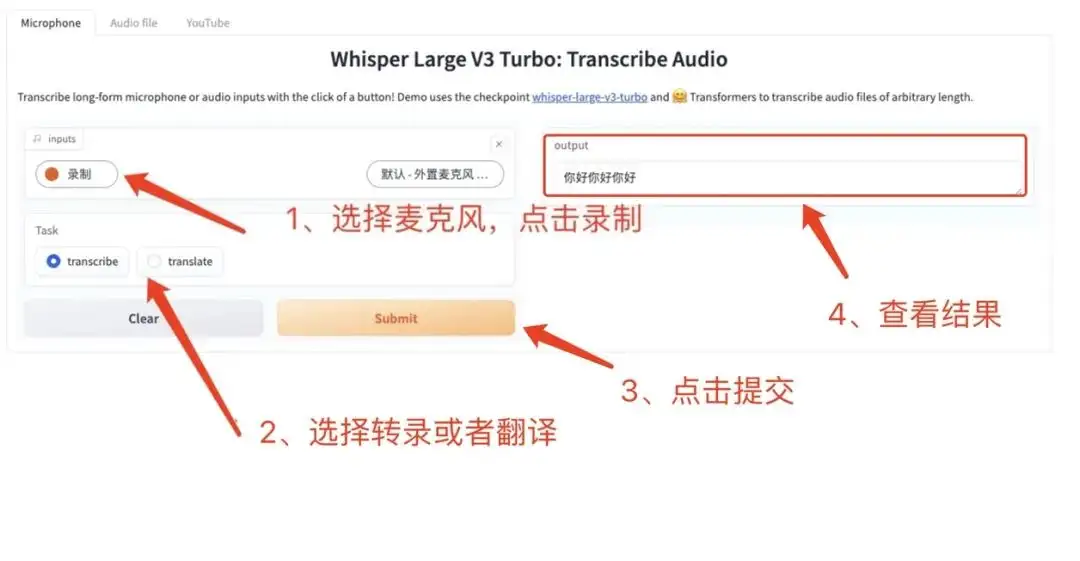
4. Linly-Dubbing One-click video download + translation + dubbing + subtitles
Linly-Dubbing is an intelligent video multilingual AI dubbing and translation tool that can automatically translate video content into multiple languages and generate subtitles.
Click the link below to start your creative journey immediately and realize multi-language AI dubbing and translation of videos.
Run online:https://go.hyper.ai/xEAzn
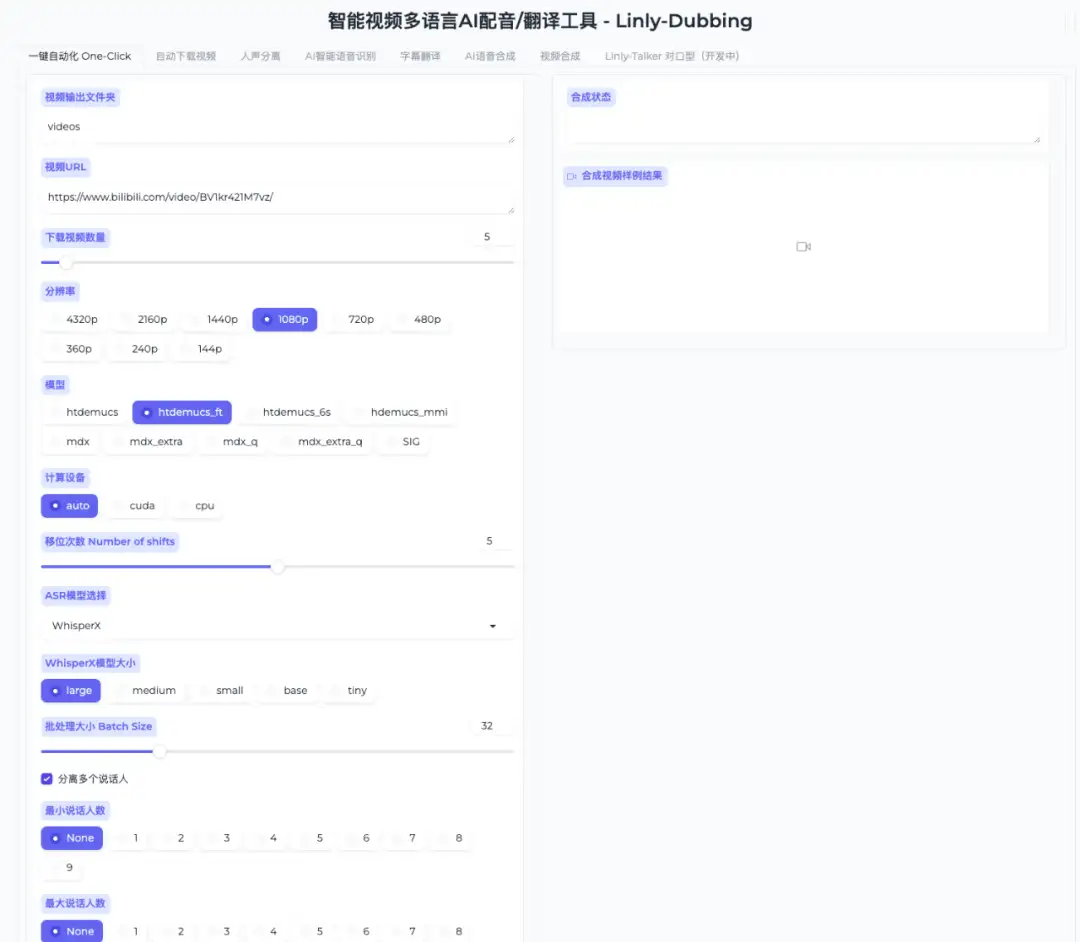
5. DrawingSpinUp: 2D character drawing → 3D animation
DrawingSpinUp is an innovative 3D animation generation technology that transforms flat character drawings into dynamic animations with 3D effects, while carefully preserving the style and characteristics of the original artwork.
Follow the tutorial steps to create realistic and detailed 3D animations.
Run online:https://go.hyper.ai/H9fV1
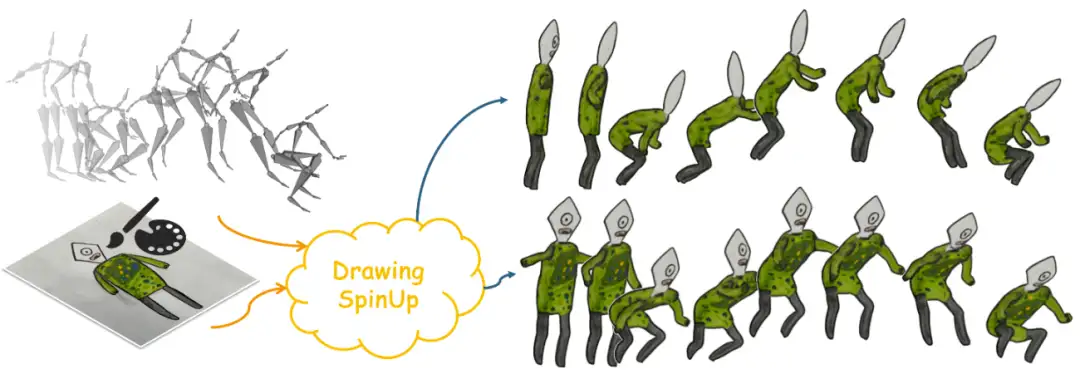
6. Whisper-large-v3-turbo speech recognition and translation demo
Whisper is a general-purpose speech recognition model. It is trained on a large and diverse audio dataset and can perform multiple tasks such as multilingual speech recognition and speech translation.
This tutorial is a one-click deployment tutorial for whisper-large-v3-turbo. It is 8 times faster than whisper-large-v3 with almost no quality loss. The relevant environment and dependencies have been installed. You can experience it by cloning and starting with one click.
Run online:https://go.hyper.ai/3P9nk
Community Articles
AI biopharmaceutical company Generate: Biomedicines, with its unique programmable biology platform, not only deeply integrates artificial intelligence into protein engineering, but also helps scientists design more efficient solutions for targets that are traditionally difficult to drug. Recently, Generate announced that it has received a strategic investment from Samsung Science Life Science Fund, and the significance behind it is self-evident. This article is a detailed report on the company, click to read it quickly.
View event recap:https://go.hyper.ai/fVtKK
In recent years, AI has been gradually applied more deeply in the field of ancient text research. In June 2024, Anyang Normal University, in collaboration with Huazhong University of Science and Technology, South China University of Technology, etc., proposed a conditional diffusion model optimized for oracle bone inscriptions deciphering. The results were not only selected for ACL 2024, but also successfully won the best paper award. It can be seen that AI is accelerating the work efficiency of researchers. More details on how AI interprets oracle bone inscriptions are as follows.
View the full report:https://go.hyper.ai/xzw4c
The rapid development of medical artificial intelligence is inseparable from the support of high-quality data sets. From disease diagnosis to drug development to personalized medicine, data sets play an indispensable role in promoting the application of machine vision, large models, etc. in the medical field. This article organizes 10 data sets in the medical field, covering Shennong Chinese medicine, ancient Chinese medicine books, medical reasoning, medical question and answer, etc. You can click to download directly.
View the full report:https://go.hyper.ai/NHlJ0
The rapid development of artificial intelligence has brought new possibilities to drug discovery. Recently, researchers from the life science company Cellarity and NVIDIA jointly proposed a novel targeted molecule optimization method based on latent reinforcement learning, MOLRL, which showed superior performance in drug discovery-related tasks, especially in targeted molecule generation and multi-parameter optimization. This article is a detailed interpretation and sharing of the paper.
View the full report:https://go.hyper.ai/YBhnM
In the sixth episode of the "Meet AI4S" live series, Professor Zheng Wei from the School of Statistics and Data Science at Nankai University shared with everyone the limitations of AlphaFold and future optimization directions, as well as other algorithms and research topics worth exploring in academia. See below for more details.
View the full report:https://go.hyper.ai/YgCip
Popular Encyclopedia Articles
1. Reciprocal sorting fusion RRF
2. Model Parameters
3. Kolmogorov-Arnold Representation Theorem
4. Large-scale Multi-task Language Understanding (MMLU)
5. Contrastive Learning
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:

One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!








