Command Palette
Search for a command to run...
Online Tutorials | YOLO Series Has Updated 11 Versions in 10 Years, and the Latest Model Has Reached SOTA in Multiple Target Detection Tasks
YOLO (You Only Look Once) is one of the most influential real-time object detection algorithms in the field of computer vision.It is favored by the industry for its high precision and efficiency, and is widely used in autonomous driving, security monitoring, medical imaging and other fields.
The model was first released in 2015 by Joseph Redmon, a graduate student at the University of Washington. It pioneered the concept of treating object detection as a single regression problem, achieved end-to-end object detection, and quickly gained wide recognition among developers. Subsequently, Alexey Bochkovskiy, Glenn Jocher (Ultralytics team), and Meituan Visual Intelligence Department and other teams launched several important versions.
As of now, the number of stars of the YOLO series models on GitHub has reached hundreds of thousands, demonstrating its influence in the field of computer vision.

The YOLO series of models is characterized by its one-stage detection architecture, which does not require complex region candidate box generation and can complete target detection in a single forward propagation, greatly improving the detection speed. Compared with traditional two-stage detectors (such as Faster R-CNN),YOLO has faster inference speed, can realize real-time processing of high frame rate images, and optimizes hardware adaptability,Widely used in embedded devices and edge computing scenarios.
at present,The "Tutorial" section of HyperAI's official website has launched multiple versions of the YOLO series, which can be deployed with one click to experience~
At the end of this article, we will use the latest version of YOLOv11 as an example to explain the one-click deployment tutorial.
1. YOLOv2
Release time:2017
Important Update:Anchor Boxes were proposed, and Darknet-19 was used as the backbone network to improve speed and accuracy.
Compile YOLO-V2 in DarkNet model with TVM:
2. YOLOv3
Release time:2018
Important Update:Using Darknet-53 as the backbone network, the accuracy is significantly improved while maintaining real-time speed, and multi-scale prediction (FPN structure) is proposed, which has achieved significant improvements in detecting objects of different sizes and processing complex images.
Compile YOLO-V3 in DarkNet model with TVM:
3 , YOLOv5
Release time:2020
Important Update:The introduction of an automatic anchor box adjustment mechanism maintains real-time detection capabilities and improves accuracy. A more lightweight PyTorch implementation is adopted, making it easier to train and deploy.
One-click deployment:https://go.hyper.ai/jxqfm
4 , YOLOv7
Release time:2022
Important Update:Based on the Expanded Efficient Layer Aggregation Network, the parameter utilization and computational efficiency are improved, achieving better performance with fewer computing resources. Additional tasks have been added, such as pose estimation of the COCO keypoint dataset.
One-click deployment:https://go.hyper.ai/d1Ooq
5 , YOLOv8
Release time:2023
Important Update:
It adopts a new backbone network and introduces a new anchor-free detection head and loss function, which outperforms previous versions in terms of average accuracy, size, and latency.
One-click deployment:https://go.hyper.ai/Cxcnj
6 , YOLOv10
Release time:May 2024
Important Update:Eliminated the non-maximum suppression (NMS) requirement to reduce inference latency. Incorporated large kernel convolution and partial self-attention modules to improve performance without adding significant computational cost. Comprehensively optimized various components to improve efficiency and accuracy.
One-click deployment of YOLOv10 target detection:
One-click deployment of YOLOv10 object detection:
7 , YOLOv11
Release time:September 2024
Important Update:Delivering state-of-the-art (SOTA) performance in multiple tasks including detection, segmentation, pose estimation, tracking, and classification, it leverages capabilities from a wide range of AI applications and domains.
One-click deployment:https://go.hyper.ai/Nztnq
YOLOv11 one-click deployment tutorial
The HyperAI HyperNeural Tutorial section has now launched "One-click Deployment of YOLOv11". The tutorial has set up the environment for everyone. You don’t need to enter any commands. Just click Clone to quickly experience the powerful functions of YOLOv11!
Tutorial address:https://go.hyper.ai/Nztnq
Demo Run
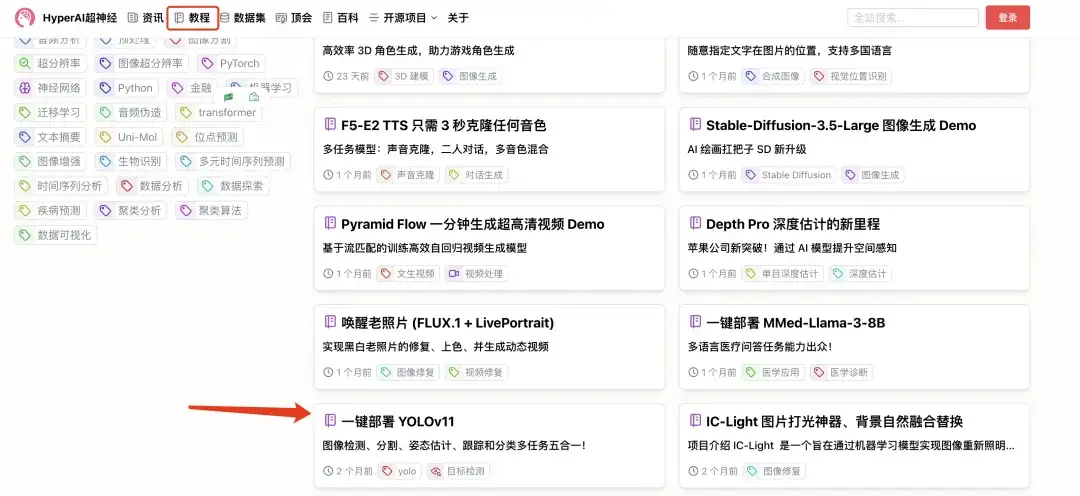
1. Log in to hyper.ai, on the Tutorial page, select One-click deployment of YOLOv11, and click Run this tutorial online.
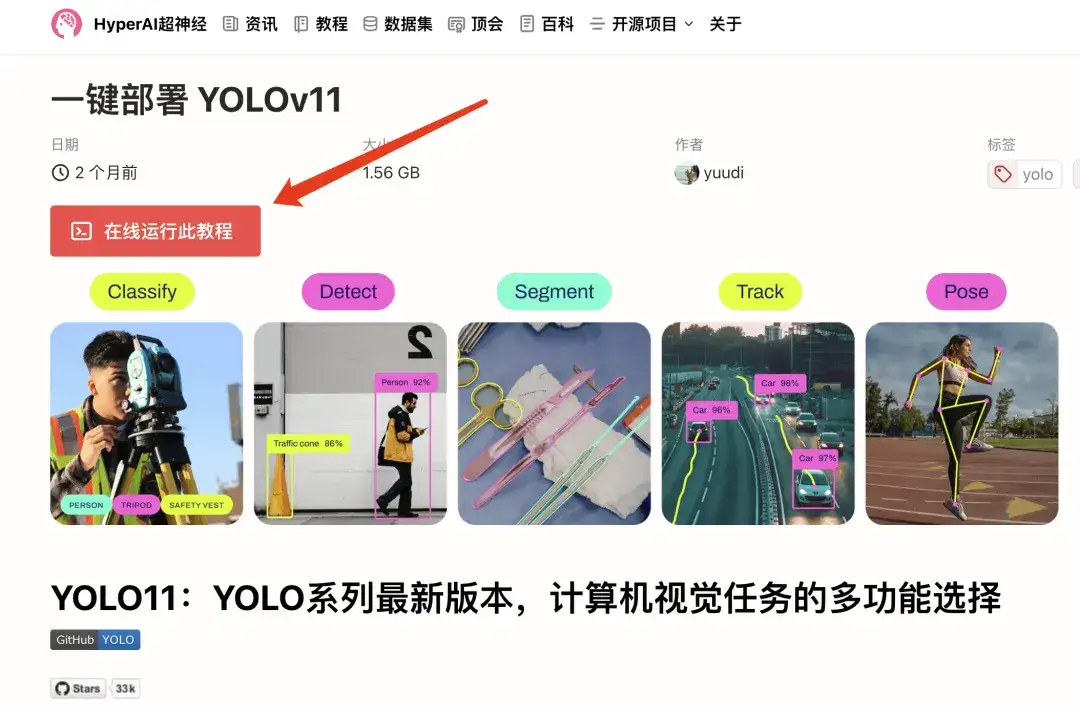
2. After the page jumps, click "Clone" in the upper right corner to clone the tutorial into your own container.
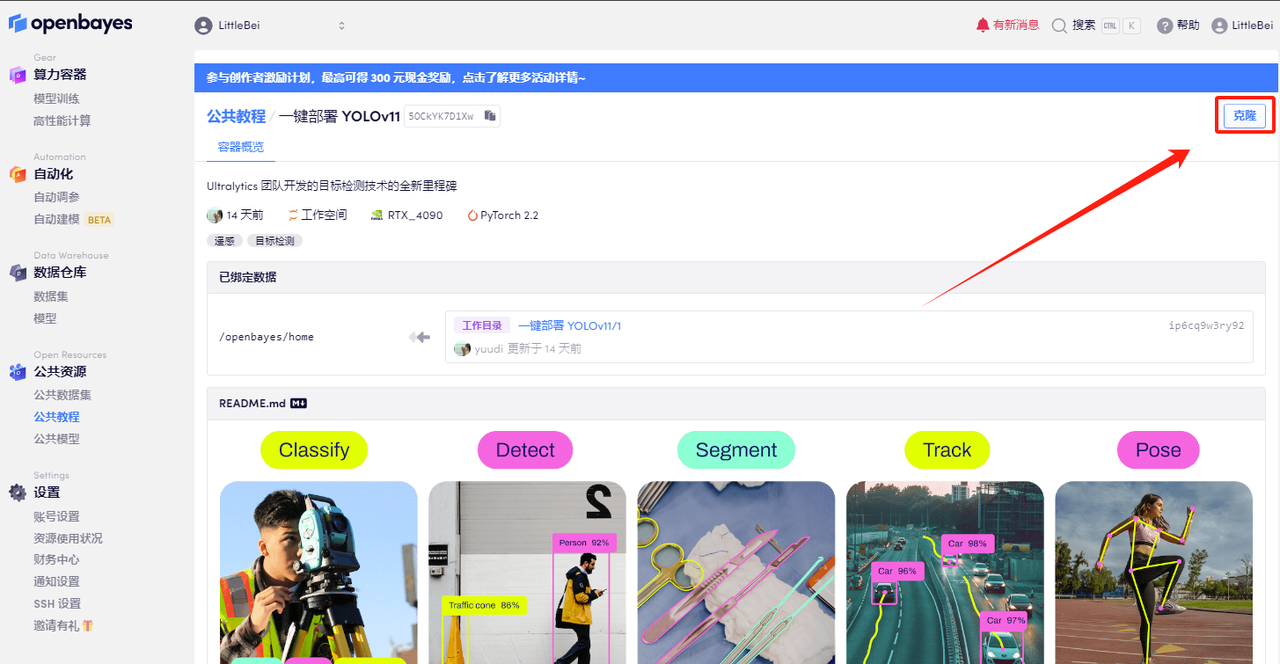
3. Click "Next: Select Hashrate" in the lower right corner.
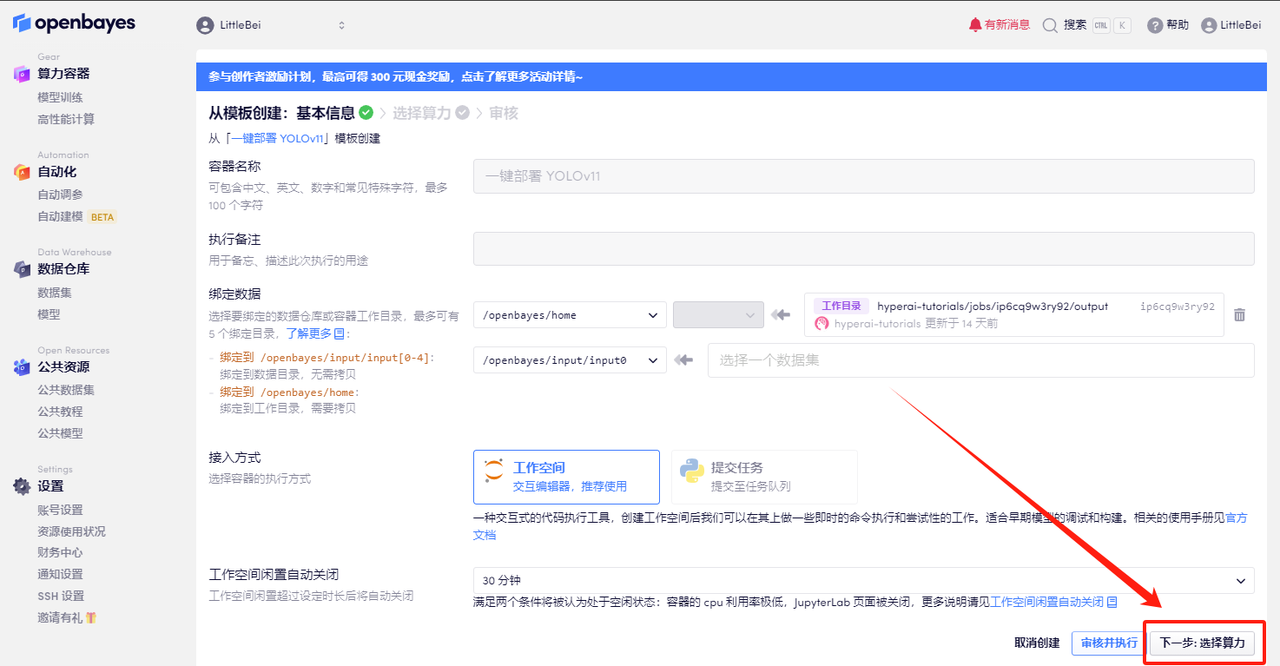
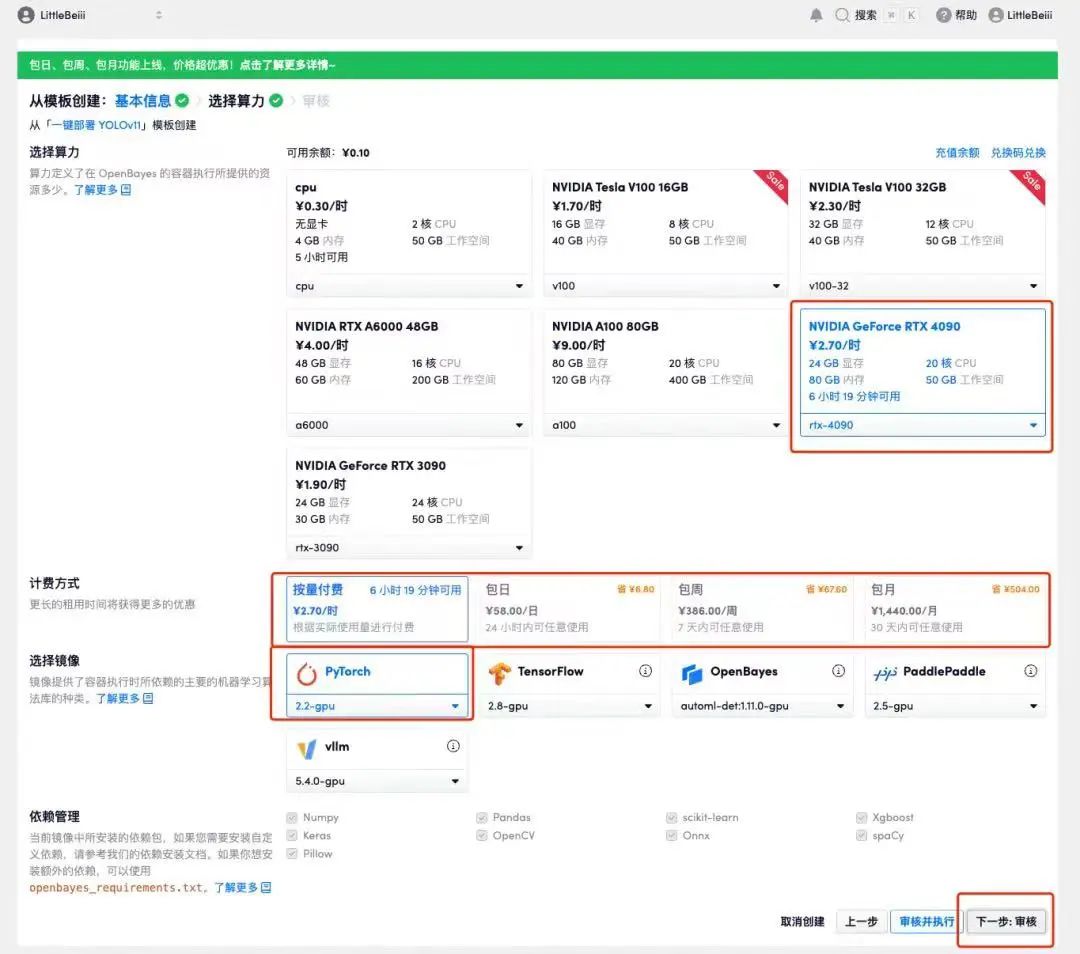
4. After the page jumps, select "NVIDIA RTX 4090" and "PyTorch" images. Users can choose "Pay as you go" or "Daily/Weekly/Monthly Package" according to their needs. After completing the selection, click "Next: Review".New users can register using the invitation link below to get 4 hours of RTX 4090 + 5 hours of CPU free time!
HyperAI exclusive invitation link (copy and open in browser):
https://openbayes.com/console/signup?r=Ada0322_QZy7
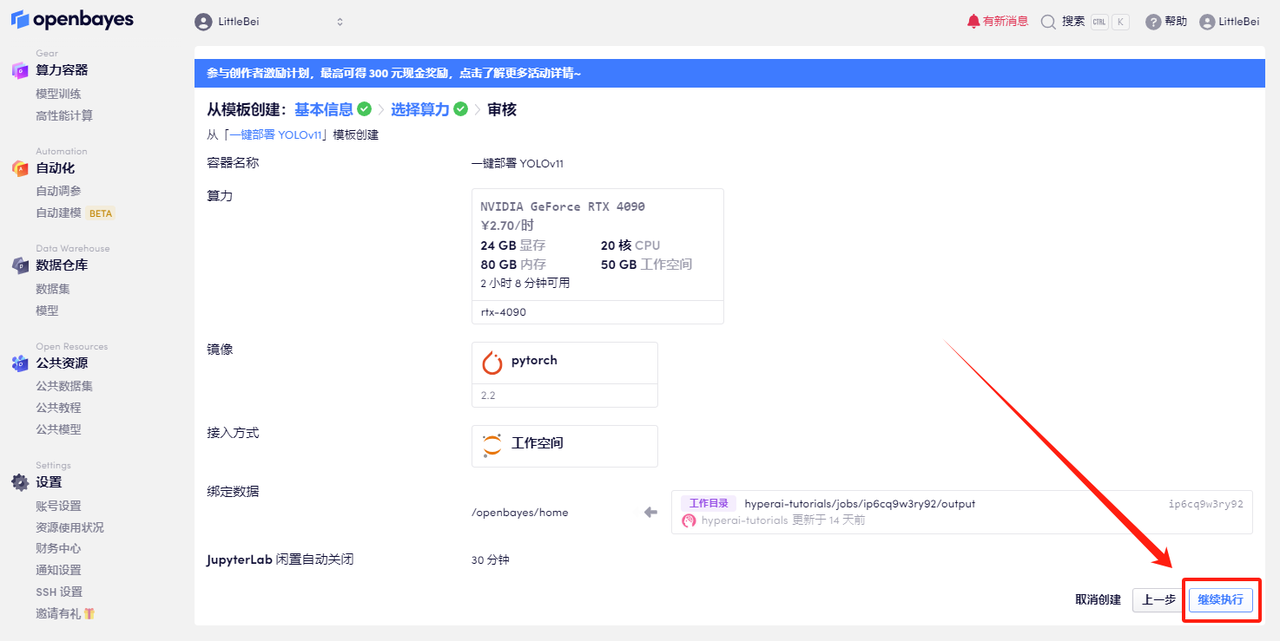
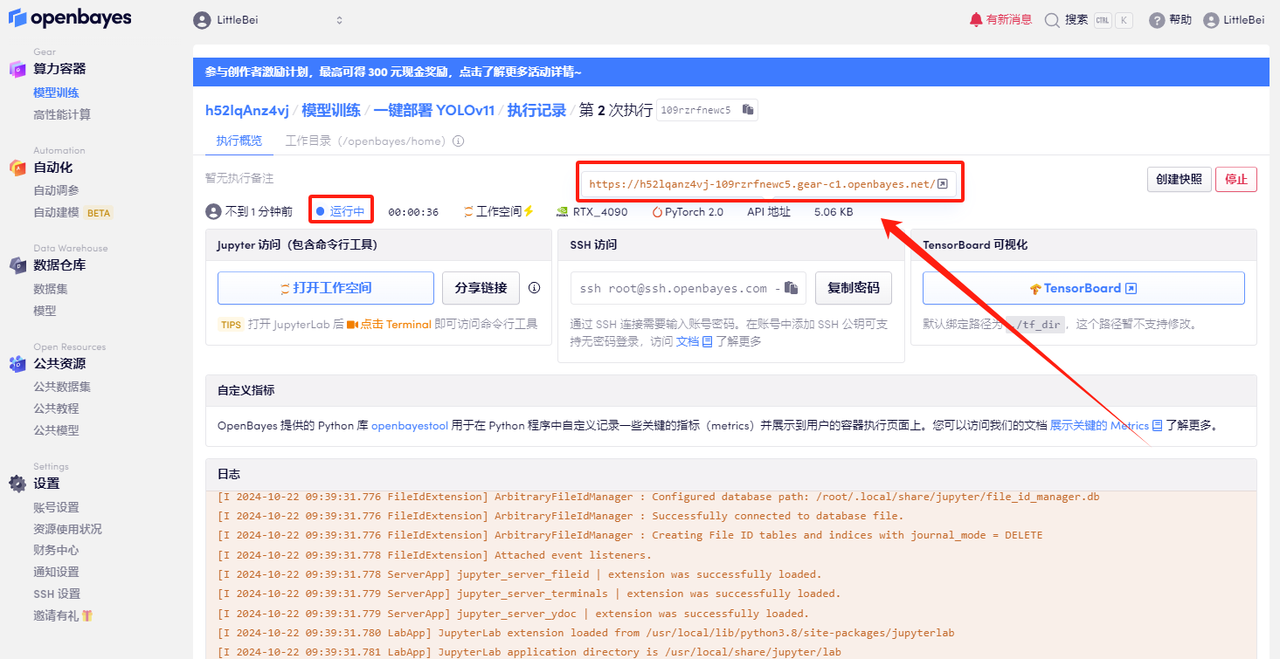
5. After confirmation, click "Continue" and wait for resources to be allocated. The first clone will take about 2 minutes. When the status changes to "Running", click the jump arrow next to "API Address" to jump to the Demo page. Please note that users must complete real-name authentication before using the API address access function.
Effect Demonstration
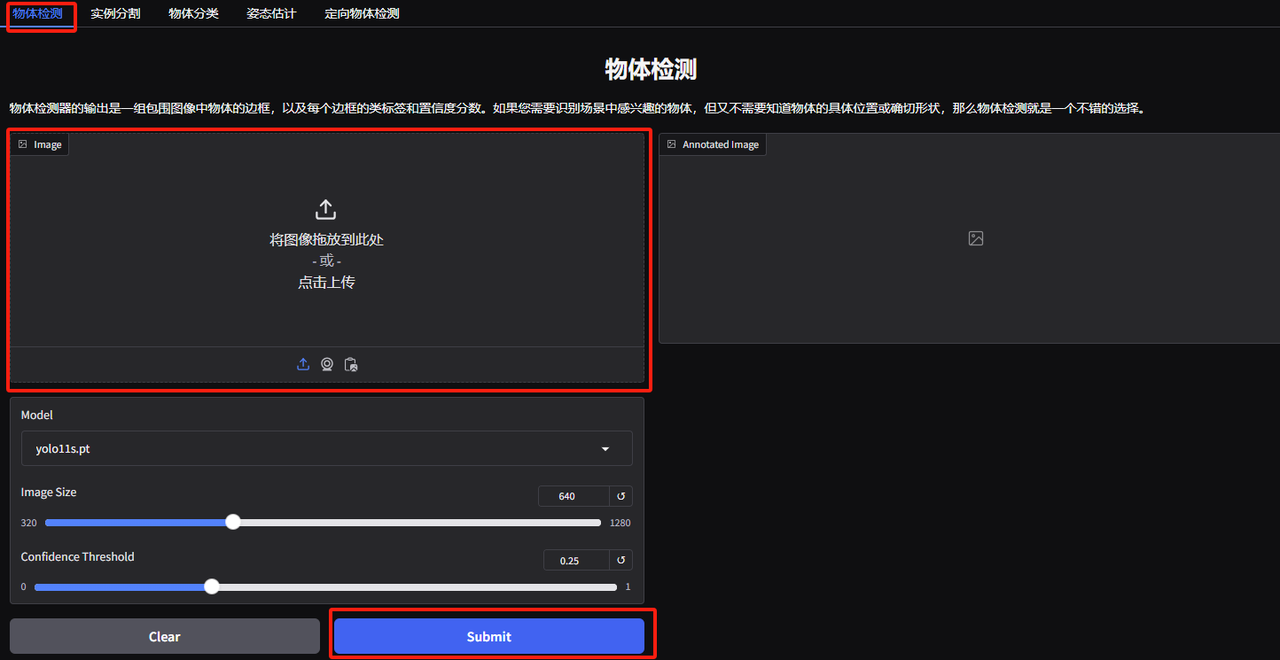
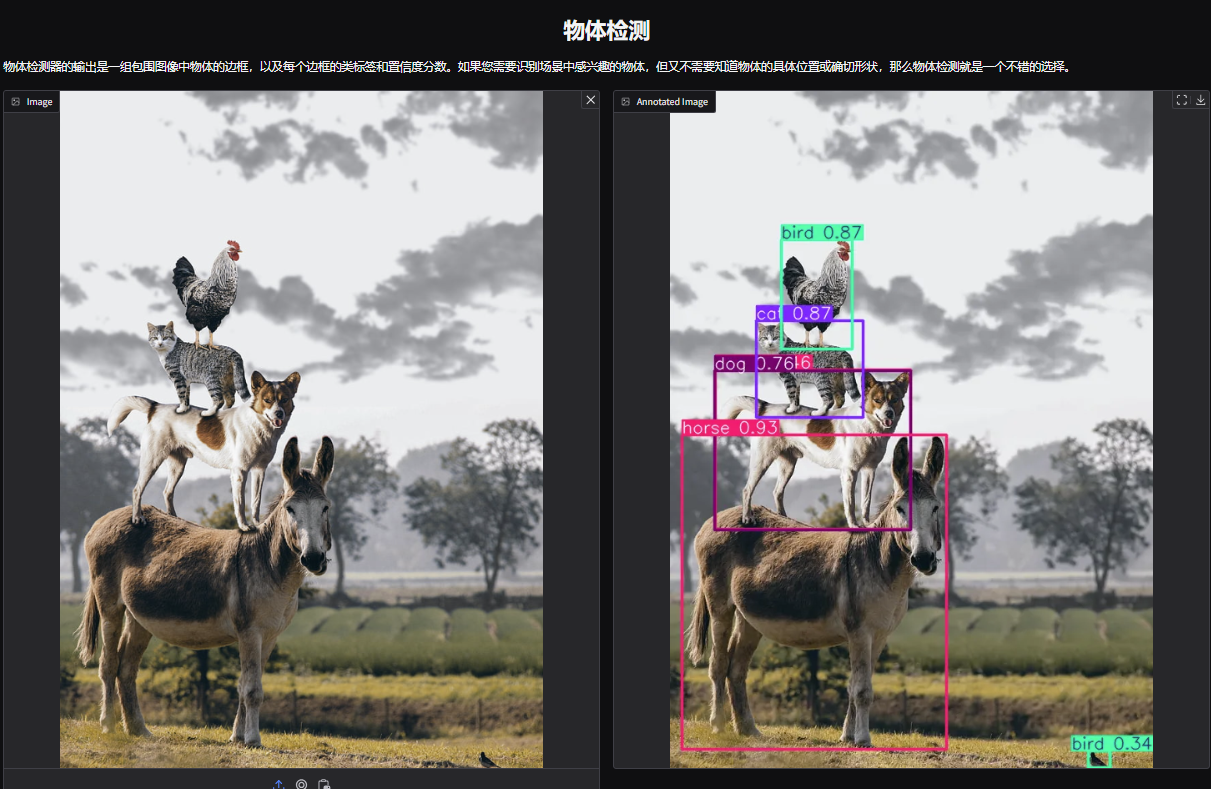
1. Open the YOLOv11 object detection demo page. I uploaded a picture of animals stacked up in a circle, adjusted the parameters, and clicked "Submit". You can see that YOLOv11 has accurately detected all the animals in the picture. There is a bird hidden in the lower right corner! Did you notice it?
The following parameters represent:
* Model:Refers to the YOLO model version selected for use.
* Image Size:The size of the input image. The model will resize the image to this size during detection.
* Confidence Threshold:The confidence threshold means that when the model performs target detection, only the detection results with a confidence level exceeding this set value will be considered as valid targets.
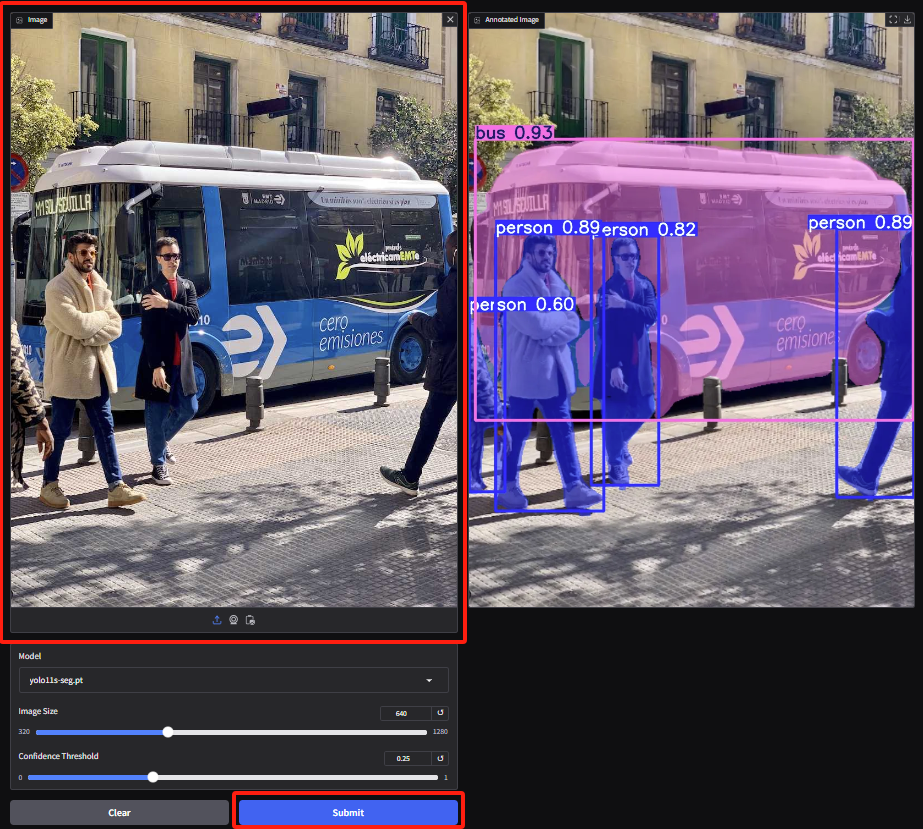
2. Enter the instance segmentation demo page, upload the image and adjust the parameters, then click "Submit" to complete the segmentation operation. Even with occlusion, YOLOv11 can do an excellent job of accurately segmenting the person and outlining the outline of the bus.
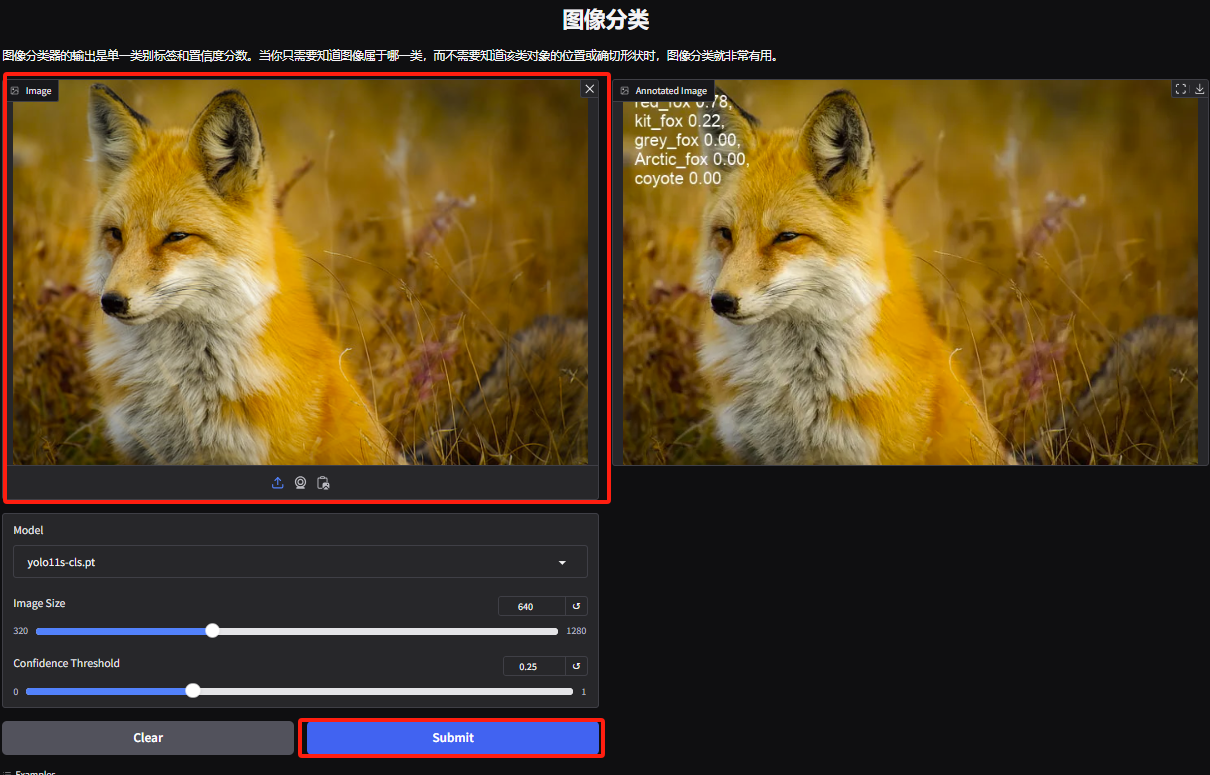
3. Enter the object classification demo page. The editor uploaded a picture of a fox. YOLOv11 can accurately detect that the specific species of the fox in the picture is a red fox.
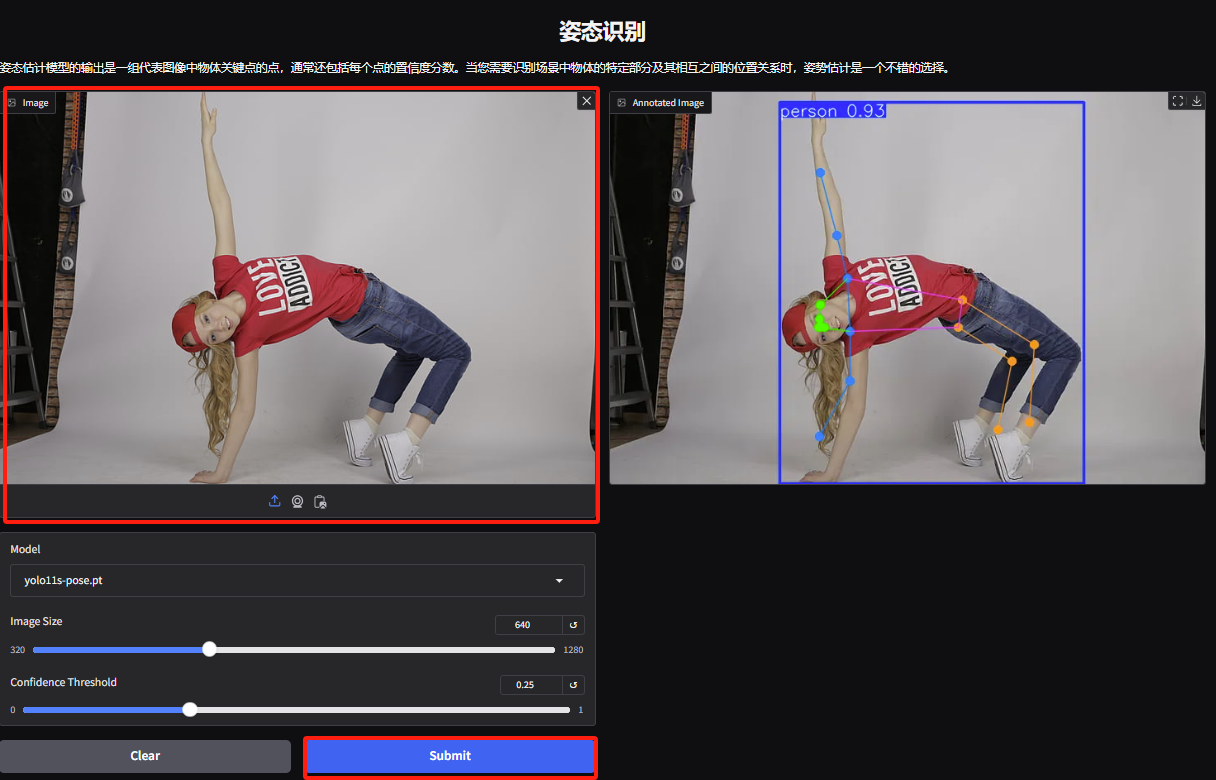
4. Enter the gesture recognition demo page, upload a picture, adjust the parameters according to the picture, and click "Submit" to complete the gesture analysis. You can see that it accurately analyzes the exaggerated body movements of the characters.
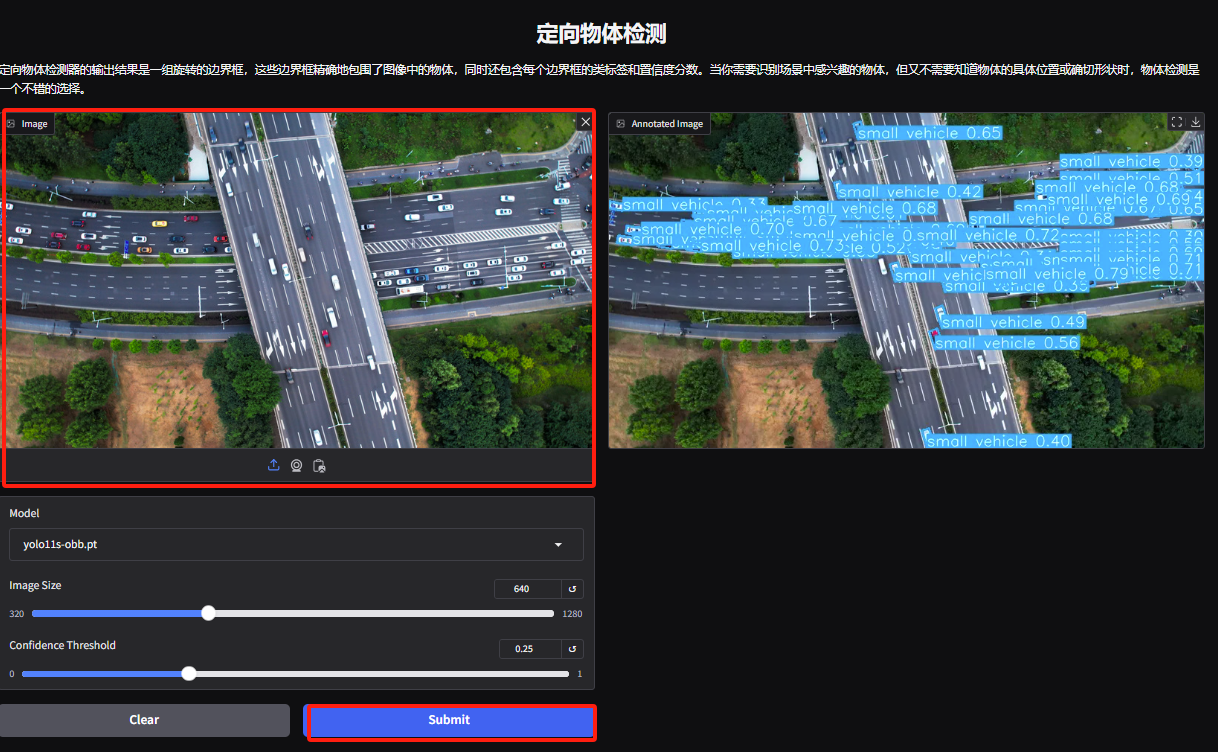
5. On the Directed Object Detection Demo page, upload an image and adjust the parameters, then click “Submit” to identify the specific location and classification of the object.