Command Palette
Search for a command to run...
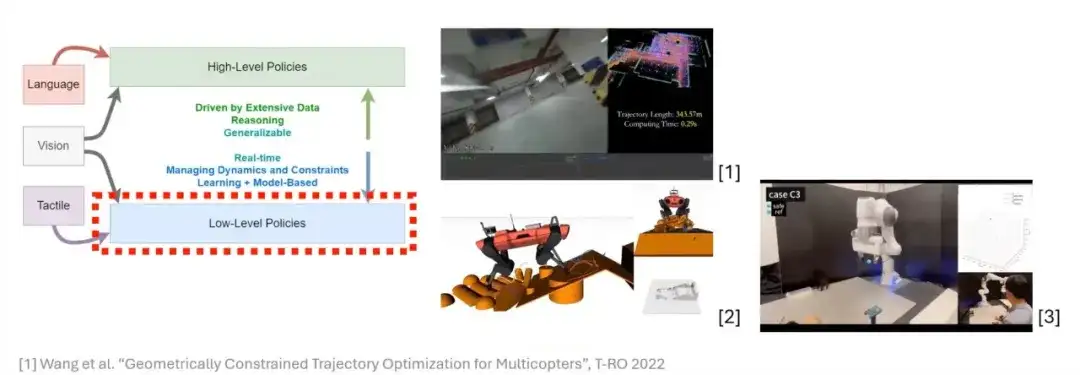
Purdue University Team Achieves data-efficient Tactile Representation for Robot Learning by Simulating Human Reactive Grasping

Touch is an indispensable part of the robot's journey of autonomous learning, giving machines the ability to perceive details of the physical world. However, the training of traditional tactile perception systems often relies on massive data collection, which is costly and inefficient. As the limitations of data-driven methods gradually become apparent,How to improve the performance of tactile learning through efficient data representation has become one of the focuses of current robotics research.
In recent years, innovative technologies based on self-supervised learning, sparse representation, and cross-modal perception have emerged rapidly, providing new ideas for the simplification and optimization of tactile representation.

Breakthroughs in this area will not only enable robots to quickly adapt to complex tasks with limited data, but will also significantly improve their ability to interact with humans and the environment.In this revolutionary change, data-efficient tactile representation technology is opening new doors for robot perception and learning.
On December 18, at the fourth online sharing event of "Newcomers on the Frontier" hosted by the Embodied Touch Community and co-organized by HyperAI,Xu Zhengtong, a third-year doctoral student at Purdue University, shared the two major scientific research results of LeTac-MPC and UniT and their research technical routes with everyone under the topic of "Data-Efficient Tactile Representation for Robot Learning".
HyperAI has compiled and summarized Dr. Xu Zhengtong's in-depth sharing without violating the original intention.
Differentiable optimization is a powerful tool in robot learning
Optimization is a very important and efficient tool in the field of robotics, and has demonstrated many excellent results in trajectory planning and human-computer interaction.Before discussing optimization,First, we need to introduce a concept: Differentiable Optimization.To explain this concept, we start with the general formulation of optimization problems.
The core idea of optimization is to construct an objective function (Cost Function) for specific application scenarios.These objective functions usually contain a lot of prior knowledge and may be subject to a series of constraints. Therefore, when constructing optimization problems, it is often necessary to add these constraints to the objective function.
Next,We will focus on a basic form of optimization - Quadratic Programming (QP).It is one of the simplest forms in the field of optimization and still has a wide range of scenarios in practical applications.

On this basis, we introduce the concept of "differentiable". Differentiable means that in a neural network, the output of a layer can calculate the partial derivative of its internal parameters.The significance of introducing Differentiable Quadratic Programming (Differentiable QP) is thatWhen we want to add an optimization layer to a neural network, we must ensure that the layer is differentiable. Only in this way can the parameters of the optimization layer be naturally updated and flowed through gradient information during network training and inference. Therefore, if we can make the quadratic programming problem differentiable, we can incorporate it into the neural network and make it part of the network.
Furthermore, optimization problems in robot learning often rely on prior knowledge in specific scenarios, such as the design of objective functions and constraints. By constructing a differentiable optimization problem, we can make full use of this prior knowledge and effectively integrate it into model design. However, in some cases, we may not be able to describe the problem using a model-based approach (i.e., we cannot construct a model-based expression).We can try to use data-driven methods to let the model learn the rules of these parts by itself. This is the core idea of differentiable optimization problems.
In summary, the quadratic programming problem has the property of being differentiable, so we can introduce it as part of the neural network.This approach not only provides new tools for network design, but also injects more flexibility and possibilities into model design in robot learning.
LeTac-MPC: Research on reactive grasping and model control methods based on tactile signals
We propose a concept called reactive-grasping.By observing the process of humans grasping objects, we found that humans usually perceive the properties and states of objects through their fingers and adjust the movements of their fingers based on the feedback. For example:
* When grasping an egg, we perceive it as hard but fragile, so we use the right amount of force to avoid damage. When the finger feedback pressure increases, we weaken the grasping force.
* When grabbing a piece of bread, since the bread is soft, the movement of your fingers will be adjusted accordingly to prevent it from being squeezed and deformed.
* When grabbing a bottle of milk, if you shake the bottle, the shaking of the milk will change the inertia of the object. The fingers will sense these changes and dynamically adjust the grabbing action to prevent the bottle from slipping due to inertia.

Implementation of a Reactive Grasping Robot
Drawing on the human grasping process, we explore how to simulate this process through a model-based approach.With vision-based tactile sensors such as GelSight,We can extract key features from the original image, generate a depth image or a difference image through simple processing, and calculate the contact area through thresholding. The contact area can reflect the magnitude of the applied force. The greater the force, the larger the contact area; the smaller the force, the smaller the contact area.
In addition, by using optical flow technology to track the movement of markers, another important quantity can be obtained: displacement.This quantity is related to the lateral force. Combining these signals, we can construct a control method based on a proportional-derivative (PD) controller to achieve tactile-reactive grasping.
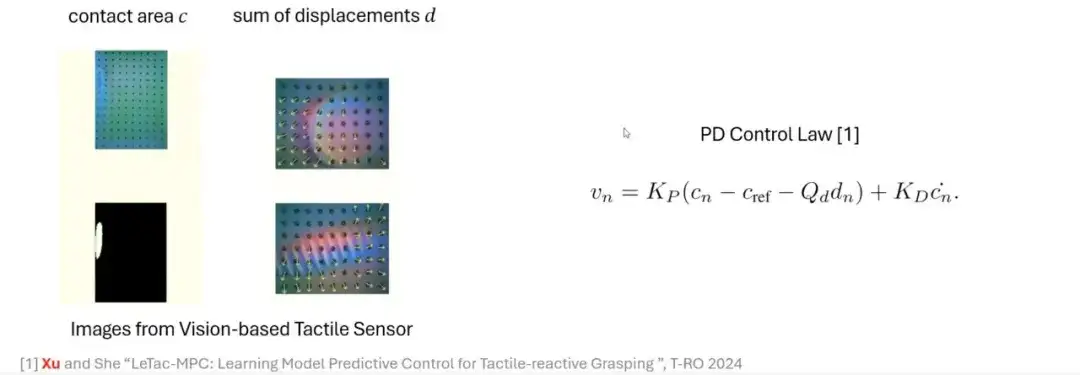
From PD Controller to MPC Controller
In addition to the PD controller, we also designed a grasping method based on a model predictive controller (MPC). The control objective of MPC is similar to that of PD controller, but its characteristics are based on linear assumption and gripper model. For example, linear assumption and single degree of freedom gripper motion model are first introduced, and then the two are unified to finally construct the control law based on MPC.
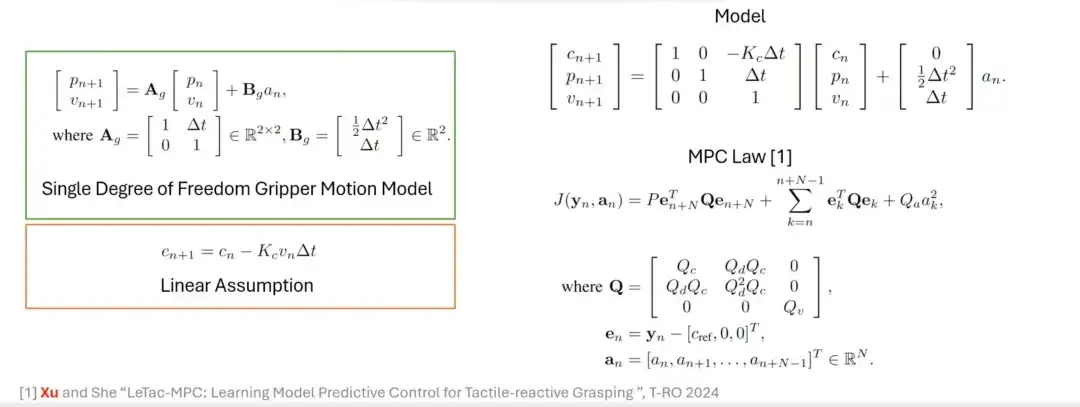
Applications and limitations of MPC controllers
The MPC controller model performs well in many scenarios.Here I list two applications.The first application is,When dragging the banana, the gripper can adjust its force based on the banana's dynamic feedback to ensure a stable grip. When the external force is removed (for example, the human hand lets go of the banana), the controller will gradually converge to a stable state.
Paper address:
https://ieeexplore.ieee.org/document/10684081
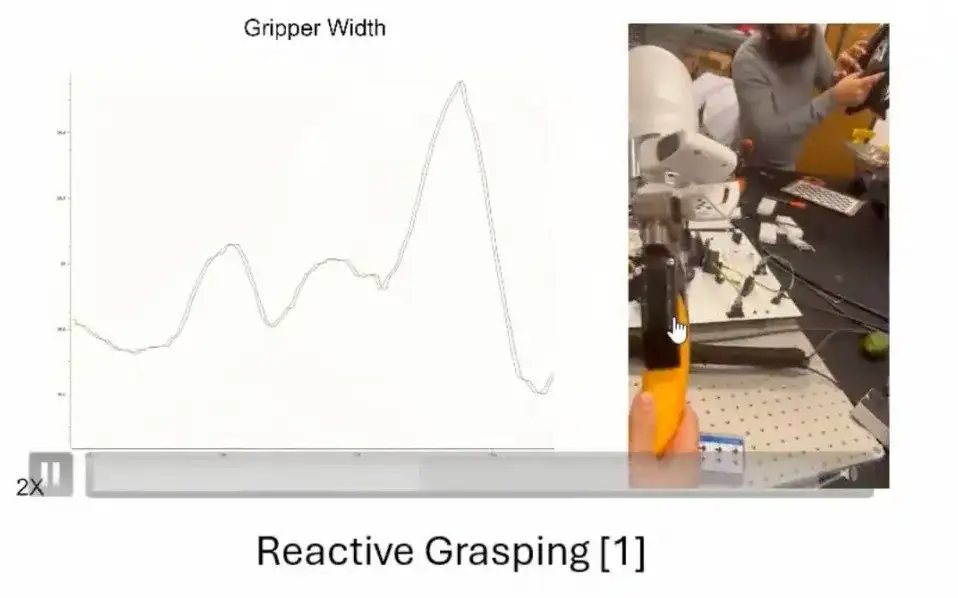
The second application is the result proposed by another member of our group at IROS.That is, a multi-degree-of-freedom gripper is used to realize complex operation tasks, and the MPC controller we proposed is adopted.
Paper address:
https://arxiv.org/abs/2408.00610

However, model-based controllers have certain limitations and are difficult to generalize to most everyday objects in real life.This is mainly due to the simplified assumptions in the modeling process, which often do not work for some real objects. As shown in the figure below, for soft objects or objects with complex shapes, it is difficult to accurately extract the contact area by simply setting a threshold; while for harder objects such as avocados and biscuits, their tactile signals (tactile images) are stronger, so the contact area can be accurately extracted.
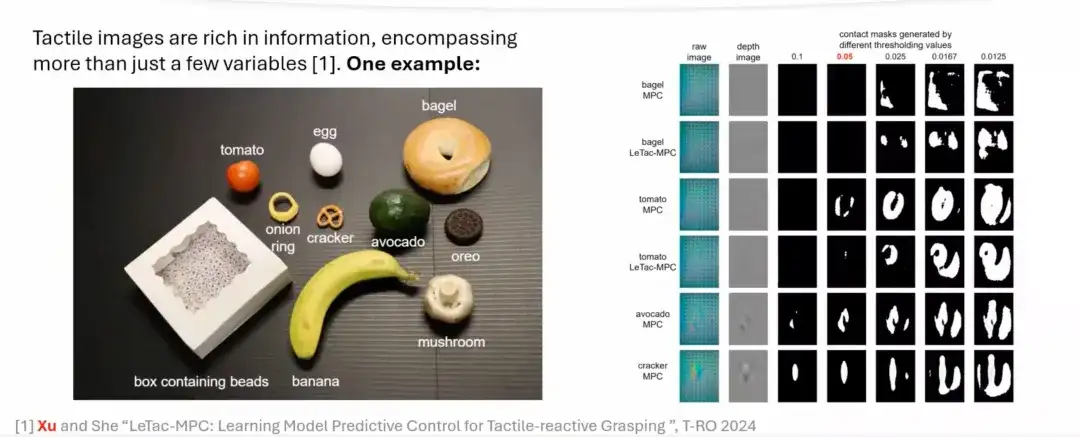
Three major advantages of LeTac-MPC controller
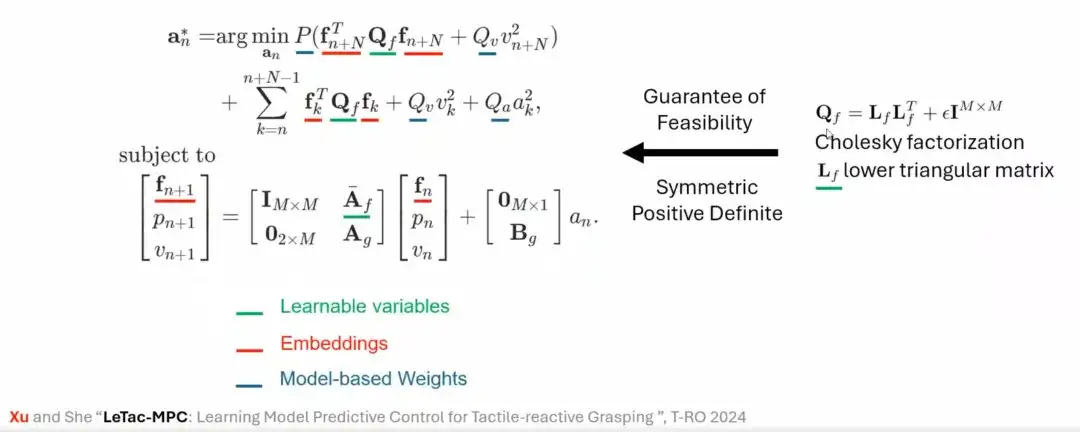
To solve this problem, we use mathematical methods (such as Cholesky factorization) to ensure the solvability of the optimization problem, thereby stabilizing the training process of the controller, and finally proposed LeTac-MPC.
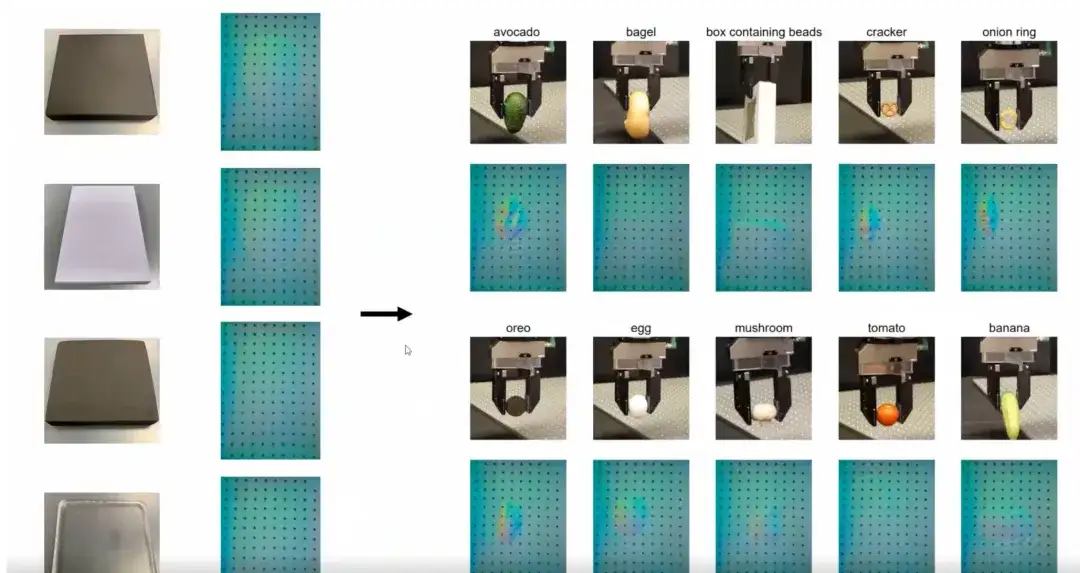
The following figure shows the most intuitive training results. We train on a dataset containing only 4 objects with different hardness. Despite the limited training data, the controller we train can be generalized to everyday objects with different sizes, shapes, materials, and textures.This generalization ability based on small sample training is a major advantage of the controller.
Second, we train the controller to be robust to interference with the grasped object.The grasping method and strength can be adjusted in real time so that the grasped object will not fall due to external interference.
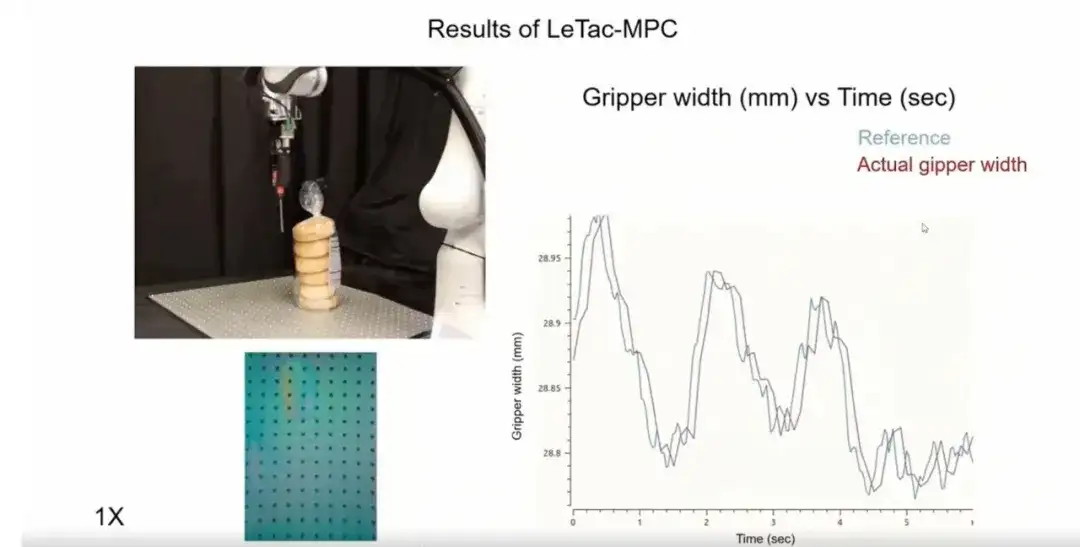
Third, the controller we train is very responsive.As shown in the figure below, in scenarios with intense motion or inertia changes (such as a box filled with debris), the controller can quickly respond to the dynamic changes of the object.
UniT: Unified Tactile Representation for Robot Learning
In the above research, we have achieved the generalization ability of the controller. But can we use a single simple object to learn a unified tactile representation?
As shown in the figure below, a single simple object can be a geometrically simple object such as a small ball or a wrench (such as an Allen Key). Since the tactile images of these objects are relatively simple, our method is also relatively simple.

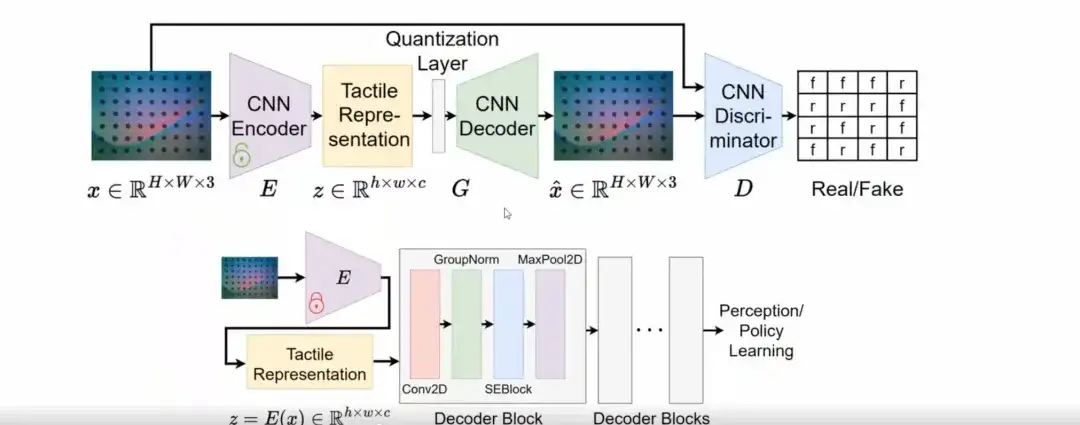
Specifically, instead of designing a completely new network structure, we found that VQGAN can effectively learn tactile representations with generalization capabilities.
In the training phase, we use the VQGAN model to learn tactile representations. In the inference phase, the latent space of VQGAN is decoded through a simple convolutional layer to connect to downstream tasks such as perception or policy learning.
Paper address:
https://arxiv.org/abs/2408.06481
Reconstruction experiment
To verify the effectiveness of the representation, we conducted reconstruction experiments on Allen Key and Small Ball.
The first is the Allen Key experiment.As shown in the figure below, although the training data only comes from Allen Key, we can still reconstruct the original image of the unseen object through the latent space, indicating that the latent space contains most of the useful information of the original image. When compared with MAE, we found that MAE is difficult to accurately reconstruct the original image, which indicates that MAE may have information loss during the decoding process.

The second is the Small Ball experiment.As shown in the figure below, although the training data only comes from Small Ball and the reconstruction effect is not as good as Allen Key, the model can still reconstruct the original signal of complex objects to a certain extent.

In addition, the latent space not only captures tactile geometric information (such as shape and contact configuration), but also implicitly contains the movement information of the markers. For example, by tracking the markers of the original image and the reconstructed image, we found that the performance of the two in marker tracking is very similar.

Downstream tasks and benchmarks
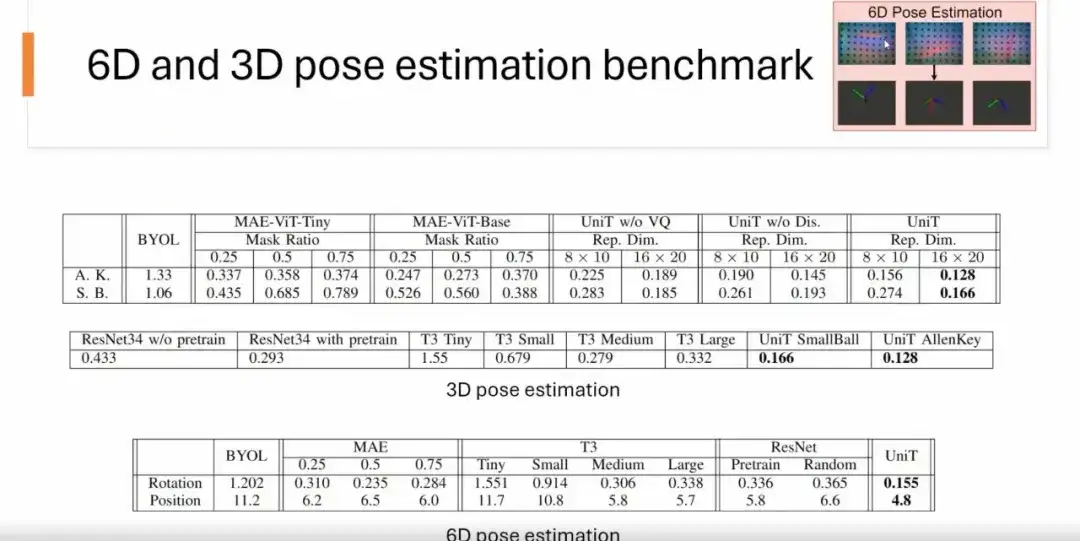
We tested the representation capabilities of the UniT method on multiple benchmarks, including 6D pose estimation, 3D pose estimation, and classification benchmarks.
For 6D pose estimation,We input a tactile raw image (such as a tactile image of a USB plug) to predict its position and rotation. The results show that the UniT model outperforms other methods in terms of accuracy compared to MAE, BYOL, ResNet, and T3 methods.
For 3D pose estimation,We only predict the rotation of the object. As shown in the figure below, UniT performs better than other methods.
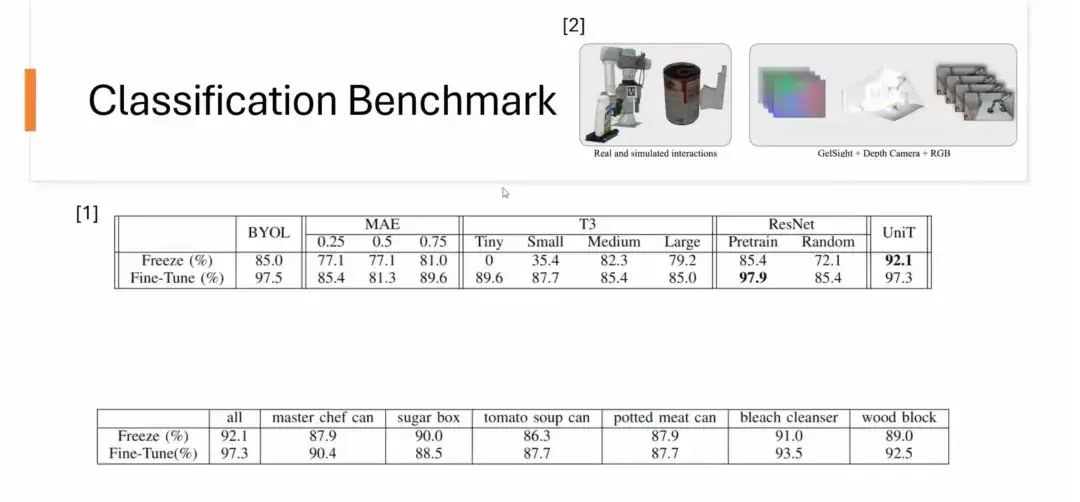
Secondly, we also did a classification benchmark.The dataset comes from CMU's YCBSight-Sim. Although the dataset is small, UniT shows good performance in classification tasks. In particular, after learning tactile representations on a single object, it can naturally generalize to classification tasks of other unseen objects. For example, the representation trained only on the master chef can can be successfully applied to the classification of 6 different objects and achieve excellent results. Some representations trained on a single object even exceed the performance of representations trained on a large number of objects.
Strategy Learning Experiment
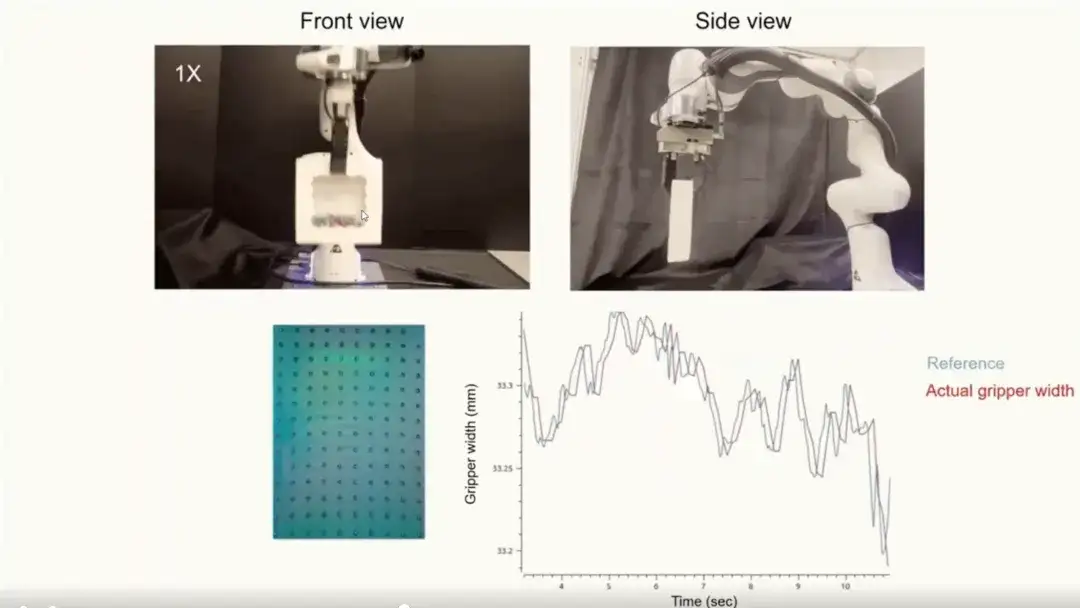
We further applied tactile representation to policy learning experiments.Verify its performance in complex tasks. The experiment used Allen Key data for training and evaluated the following three tasks:
* Allen Key Insertion (see left): Precision insertion task, requiring extremely high accuracy.
* Chips Grasping (see picture): handling delicate grasping tasks of fragile objects.
Chicken Legs Hanging (see right): a dual-arm task involving long-term dynamic grasping and control.

We benchmarked three different methods:The three methods are: Vision-Only (relying only on visual signals), Visual-Tactile from Scratch (joint training of vision and touch), and Visual-Tactile with UniT (using tactile representation extracted by UniT for policy learning). As shown in the figure below, the policy learning method using UniT representation performed best in all tasks.

In the future, HyperAI will also assist the embodied touch community to continue to hold online sharing activities, inviting experts and scholars from home and abroad to share cutting-edge results and insights. Stay tuned!








