Command Palette
Search for a command to run...
The First vLLM Chinese Documentation Is Online! The Latest Version Increases Throughput by 2.7 Times and Reduces Latency by 5 Times, Making Large Language Model Inference Faster!

Today, the development of large language models (LLMs) is expanding from iterative upgrades of scale parameters to adaptation and innovation of application scenarios. In this process, a series of problems have also been exposed. For example, the efficiency of the reasoning link is low, it takes a long time to process complex tasks, and it is difficult to meet the needs of scenarios with high real-time requirements; in terms of resource utilization, due to the large scale of the model, the consumption of computing resources and storage resources is huge, and there is a certain degree of waste.
In view of this,A research team from the University of California, Berkeley (UC Berkeley) open-sourced vLLM (Virtual Large Language Model) in 2023.This is a framework designed specifically for accelerating the reasoning of large language models. It has attracted widespread attention around the world due to its excellent reasoning efficiency and resource optimization capabilities.
In order to help domestic developers more easily learn about vLLM version updates and cutting-edge developments,HyperAI Super Neural Network has now launched the first vLLM Chinese document.From technical knowledge to practical tutorials, from cutting-edge trends to major updates, both beginners and experienced experts can find the essential content they need.
vLLM Chinese Documentation:
Tracing vLLM: Open Source History and Technological Evolution
The prototype of vLLM was born at the end of 2022. When the research team of the University of California, Berkeley deployed an automated parallel reasoning project called "alpa", they found that it ran very slowly and had low GPU utilization. The researchers were keenly aware that there was a huge room for optimization in large language model reasoning. However, there was no open source system specifically optimized for large language model reasoning on the market, so they decided to create a large language model reasoning framework by themselves.
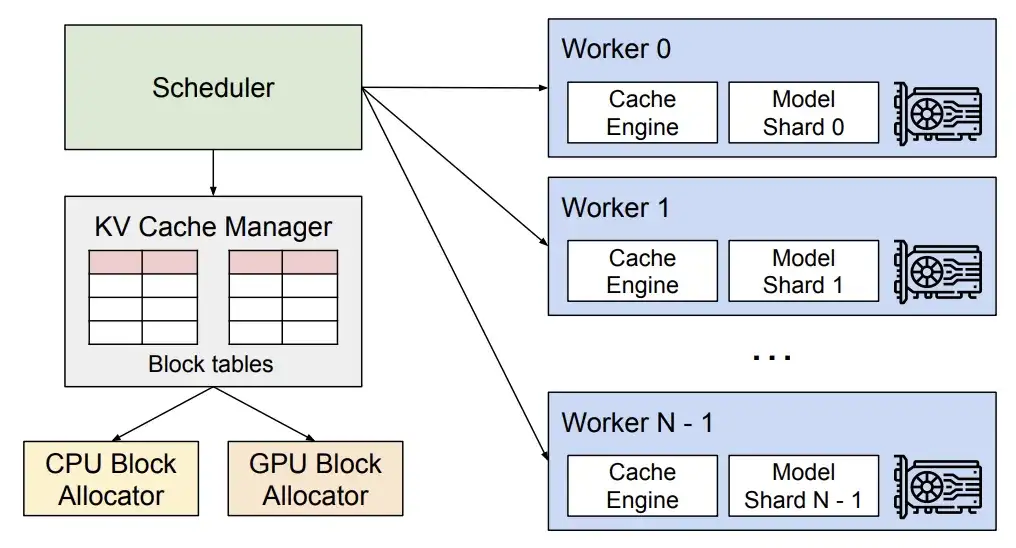
After numerous experiments and debugging, they paid attention to the virtual memory and paging technology in the operating system, and based on this, they proposed the groundbreaking attention algorithm PagedAttention in 2023, which can effectively manage attention keys and values. On this basis, the researchers built a high-throughput distributed LLM service engine vLLM, achieving almost zero waste of KV cache memory.Solved the memory management bottleneck problem in large language model reasoning.Compared to Hugging Face Transformers, it achieves 24x higher throughput, and this performance improvement does not require any changes to the model architecture.
What's more worth mentioning is that vLLM is not limited to hardware. It is not limited to Nvidia GPUs, but also to many hardware architectures on the market, such as AMD GPUs, Intel GPUs, AWS Neuron, and Google TPUs. It truly promotes the efficient reasoning and application of large language models in different hardware environments. Today, vLLM can support more than 40 model architectures and has received support and sponsorship from more than 20 companies including Anyscale, AMD, NVIDIA, and Google Cloud.
In June 2023, the open source code of vLLM was officially released. In just one year, the number of stars of vLLM on Github exceeded 21.8k.As of now, the project has 31k stars.
In September of the same year, the research team published a paper titled "Efficient Memory Management for Large Language Model Serving with PagedAttention", which further elaborated on the technical details and advantages of vLLM. The team has not stopped its research on vLLM, and is still iterating and upgrading around compatibility and ease of use. For example, in terms of hardware adaptation, in addition to Nvidia GPUs, how can vLLM run on more hardware; in scientific research, how to further improve system efficiency and reasoning speed. These are also reflected in the version updates of vLLM.
Paper address:
https://dl.acm.org/doi/10.1145/3600006.3613165
vLLM v0.6.4 Update
2.7 times higher throughput and 5 times lower latency
Just last month, vLLM was updated to version 0.6.4, which has made important progress in performance improvement, model support, and multimodal processing.
In terms of performance, the new version introduces multi-step scheduling and asynchronous output processing.Optimized GPU utilization and increased processing efficiency, thereby improving overall throughput.
vLLM Technical Analysis
* Multi-step scheduling allows vLLM to complete the scheduling and input preparation of multiple steps at once, so that the GPU can process multiple steps continuously without having to wait for CPU instructions for each step, thus dispersing the CPU workload and reducing the GPU's idle time.
* Asynchronous output processing allows output processing to be performed in parallel with model execution. Specifically, vLLM no longer processes outputs immediately, but instead delays processing, processing the output of step n while executing step n+1. Although this may result in executing one extra step per request, the significant improvement in GPU utilization more than makes up for this cost.
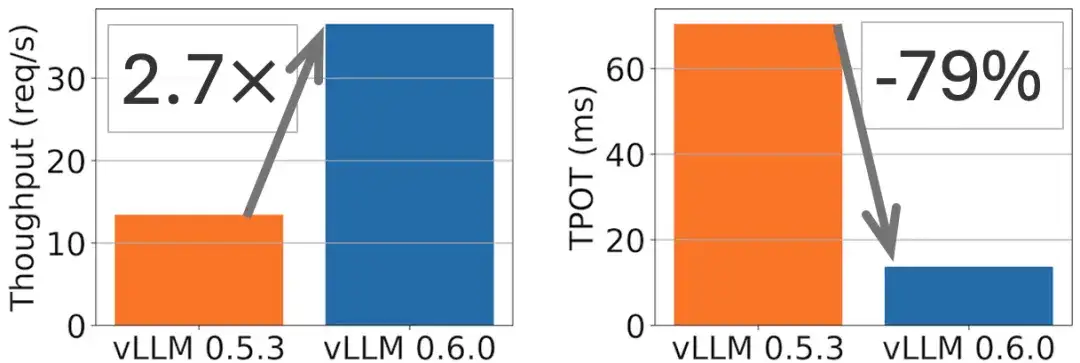
For example, a 2.7x throughput improvement and a 5x TPOT (per output token time) reduction can be achieved on the Llama 8B model, as shown in the following figure.
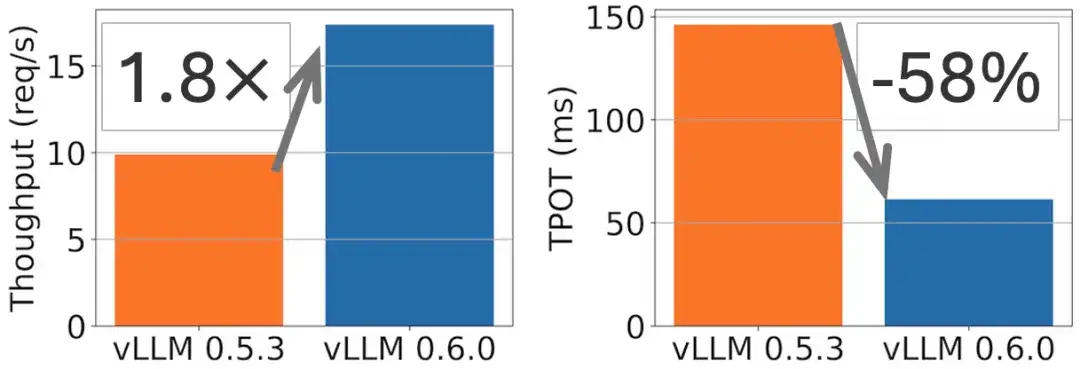
On the Llama 70B model, a 1.8-fold throughput improvement and a 2-fold TPOT reduction were achieved, as shown in the following figure.
In terms of model support, vLLM has newly incorporated adaptations for cutting-edge large language models such as Exaone, Granite, and Phi-3.5-MoE. In the multimodal field, the function of multi-image input has been added (the Phi-3-vision model is used as an example in the official documentation), as well as the ability to process multiple audio blocks of Ultravox, further expanding the application scope of vLLM in multimodal tasks.
The first complete version of vLLM Chinese documentation is online
There is no doubt that vLLM, as an important technological innovation in the field of large models, represents the current development direction of efficient reasoning. In order to enable domestic developers to understand the advanced technical principles behind it more conveniently and accurately, vLLM is introduced into the development of domestic large models, thereby promoting the development of this field. HyperAI community volunteers successfully completed the first vLLM Chinese document through open cooperation and double review of translation and proofreading.Now fully launched on hyper.ai.
vLLM Chinese Documentation:
vLLM This document provides you with:
* Basic concepts from scratch
* Quick start one-click cloning tutorial
* Timely updated vLLM knowledge base
* Friendly and open Chinese community ecology
Building open source bridges:
TVM, Triton and vLLM community co-building journey
In 2022, HyperAI launched the first Apache TVM Chinese documentation in China (Click to view the original text: TVM Chinese website is officially launched! The most comprehensive machine learning model deployment "reference book" is here)As domestic chips are developing rapidly, we provide domestic compiler engineers with the infrastructure to understand and learn TVM.At the same time, we have also joined hands with Apache TVM PMC Dr. Feng Siyuan and others to form the most active TVM Chinese community in China.Through online and offline activities, we have attracted the participation and support of mainstream domestic chip manufacturers, covering more than a thousand chip developers and compiler engineers.

TVM Chinese Documentation Address:
In October 2024, we launched the Triton Chinese website (Click to view the original text: The first complete Triton Chinese document is online! Opening a new era of GPU inference acceleration), further expanding the technical boundaries and content scope of the AI compiler community.
Triton Chinese Documentation Address:
In the journey of building the AI compiler community, we have been listening to everyone's voice and keeping an eye on industry trends. The launch of the vLLM Chinese documentation is based on our observation that with the rapid development of large models, everyone's attention to and demand for vLLM is increasing. We hope to provide a platform for learning, communication and cooperation for developers, and jointly promote the popularization and development of cutting-edge technologies in the Chinese context.
The update and maintenance of TVM, Triton, and vLLM Chinese documents are the foundation of our Chinese community. In the future, we look forward to more partners joining us to build a more open, diverse, and inclusive AI open source community!
View the complete vLLM Chinese documentation:
On GitHub vLLM Chinese:
https://github.com/hyperai/vllm-cn
This month, HyperAI will hold an offline technical exchange meeting called Meet AI Compiler in Shanghai. Please scan the QR code and remark "AI Compiler" to join the event group and get relevant information about the event as soon as possible.

References:
1.https://blog.vllm.ai/2024/09/05/perf-update.html








