Command Palette
Search for a command to run...
Selected for NeurIPS 2024! The Chinese Academy of Sciences Team Proposed a New Framework for non-invasive Brain Decoding, Laying the Foundation for the Development of brain-computer Interfaces and Cognitive Models
Can you imagine visualizing the images you see, think about, or even dream about? This is not just a wild imagination. As early as 2008, Jack Gallant, a neuroscientist at the University of California, Berkeley, proposed his hypothesis in Nature. They used functional magnetic resonance imaging (fMRI) - a non-invasive brain imaging technology to "read" the activity of the subject's visual cortex, and then visualized the images seen by the subject through visual reconstruction.This sounded the clarion call for scientists around the world to decode the brain.
Compared with invasive brain decoding technology, non-invasive brain decoding technology represented by fMRI is highly valued because it achieves brain decoding in a simpler and safer way. It has great potential application value in many fields such as cognitive neuroscience research, brain-computer interface applications, and clinical medical diagnosis.
However, non-invasive decoding of brain signals is hampered by individual differences and the complexity of neural signal representation, and remains a key challenge in the brain decoding process.On the one hand, traditional methods rely on customized models and a large number of expensive experiments; on the other hand, due to the lack of accurate semantics and interpretability, it is difficult for traditional methods to accurately reproduce an individual's visual experience in visual reconstruction tasks.
In response to this, Professor Zeng Yi's team from the Institute of Automation, Chinese Academy of Sciences, innovatively designed a multimodal integration framework that combines fMRI feature extractors with large language models to solve the problem of visual reconstruction of brain activity..Using Vision Transformer 3D (ViT3D), researchers combined 3D brain structure with visual semantics, aligning fMRI features with multi-level visual embeddings through an efficient unified feature extractor, extracting information from single-experiment data without the need for a specific model. In addition, the extractor incorporates multi-level visual features, simplifying integration with large language models (LLMs), and enabling the development of multimodal large models by augmenting fMRI datasets and text data associated with fMRI images.
The result, titled “Neuro-Vision to Language: Enhancing Brain Recording-based Visual Reconstruction and Language Interaction”, has been accepted by NeurIPS 2024.
Research highlights:
* This study significantly improves the ability to reconstruct visual stimuli through brain signals, deepens the understanding of the relevant neural mechanisms, and opens up new ways to interpret brain activity
* An fMRI feature extractor based on Vision Transformer 3D, which combines 3D brain structure and visual semantics and aligns them at multiple levels, eliminating the need for specific topic models and extracting valid data in just a single experiment, greatly reducing training costs and enhancing usability in real-world scenarios
* By expanding the fMRI image-related text data, a multimodal large model capable of decoding fMRI data was constructed, which not only improved the brain decoding performance, but also expanded its application range, including visual reconstruction, complex reasoning, concept localization and other tasks
Paper address:
https://nips.cc/virtual/2024/poster/93607
Follow the official account and reply "Brain signal decoding" to get the complete PDF
The open source project "awesome-ai4s" brings together more than 100 AI4S paper interpretations and provides massive data sets and tools:
https://github.com/hyperai/awesome-ai4s
Dataset: Based on natural scene dataset, strictly evaluate the test reliability
The datasets used in the experiment include the Natural Scenes Dataset (NSD) dataset and the COCO dataset.The NSD dataset contains high-resolution 7 Tesla fMRI scans collected from 8 healthy adult participants, but in the specific experimental analysis, the researchers mainly analyzed the 4 subjects who completed all data collection.
The researchers also preprocessed the NSD dataset to correct for temporal resampling of slice timing differences, and spatial interpolation to adjust for head motion and spatial distortion. Modifications such as cropping can lead to mismatches between the original captions and instance bounding boxes, as shown in the figure below. To ensure data consistency, the researchers re-annotated the cropped images, generated 8 captions for each image using BLIP2, and generated bounding boxes for these images using DETTR.

Since some images are clipped, there is a mismatch between the original caption and the instance bounding box.
In addition, to ensure compatibility between fMRI data and LLMs and to achieve instruction following and diverse interactions, the team expanded seven types of dialogues when annotating NSD using natural language, namely: brief descriptions, detailed descriptions, continuous dialogues, complex reasoning tasks, instruction reconstruction, and concept localization.
Finally, to ensure the standardization of the data, the researchers used trilinear interpolation to adjust the data to a uniform dimension, set the fMRI normalization to 83 × 104 × 81, and divided the data into 14 × 14 × 14 patches after applying zero padding to the edges to preserve local information.
Model architecture: a multimodal integration framework integrating fMRI feature extraction and LLMs
In order to solve the visual reconstruction of brain activity and eliminate the fusion problem of LLMs and multimodal data, the research team innovatively designed a multimodal integration framework that integrates fMRI feature extraction and large language models.As shown in the following figure:
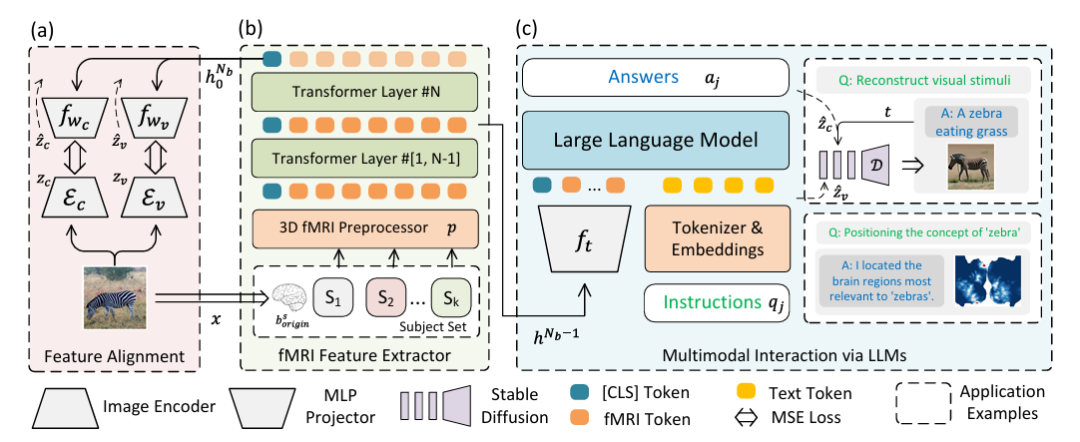
Specifically,Part (a) of the figure above describes the two-stream path for feature alignment using Variational Autoencoder (VAE) and CLIP embedding.In the experimental setting, CLIP ViT-L/14 and AutocoderKL are integrated as image feature extractors, and two two-layer perceptrons fwc and fwv with hidden dimension of 1024 are used to align with VAE (zv = Ev) and CLIP (zc = Ec) features, respectively.
Part (b) of the above figure describes a 3D fMRI preprocessor p and an fMRI feature extractor (fMRl Feature Extractor).For fMRI data, a 16-layer Transform Encoder with a hidden size of 768 is used to extract features, and the class label of the last layer is used as the output. Then it is aligned back to Figure (a) to achieve high-quality visual reconstruction.
Part (c) of the figure above describes multimodal LLMs integrated with fMRI.That is, multimodal interaction via LLMs is achieved. The main thing is to input the extracted features into LLMs to process natural language instructions and generate responses or visual reconstruction. This part uses the penultimate hidden state of the network hᴺᵇ⁻¹ as the multimodal marker of fMRI data, fₜ is a two-layer perceptron, "Instruction" represents natural language instructions, and "Answer" represents the response generated by LLMs.
After instruction-based fine-tuning, the model can communicate directly through natural language and support visual reconstruction and position recognition of concepts expressed in natural language, using UnCLIP for visual reconstruction and GradCAM for concept localization, respectively. In the figure, D represents frozen UnCLIP.
Experimental results: Three major experiments and multiple comparisons show that the new framework performs well in decoding brain signals
To evaluate the performance of the proposed framework, the researchers conducted various types of experiments such as captioning and question answering, visual reconstruction, and concept localization, and compared them with other different methods to verify the feasibility and efficiency of the framework.
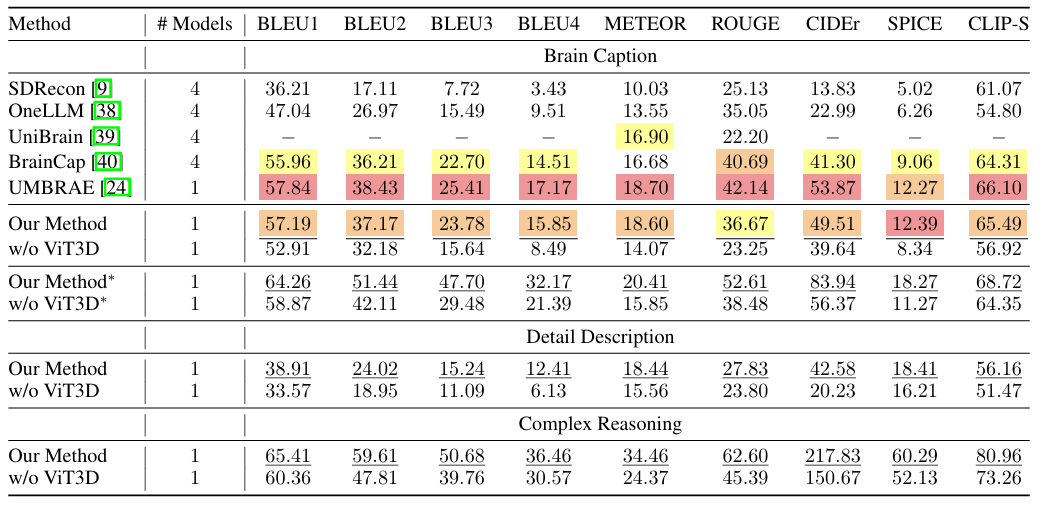
As shown in the figure below, the proposed framework shows excellent performance on most metrics of the brain caption task. In addition, the framework has good generalization ability without having to train a separate model for each subject or introduce subject-specific parameters.The researchers also combined tasks for detailed description and complex reasoning, and the framework also achieved state-of-the-art performance on these two tasks, demonstrating that it can not only generate simple captions but also achieve detailed descriptions and perform complex reasoning.
In the visual reconstruction experiment, as shown in the figure below, the proposed method performs well in high-level feature matching, demonstrating the ability of the model to effectively use LLMs to interpret complex visual data.The robustness across a wide range of visual stimuli confirms the comprehensive understanding of fMRI data by the proposed method. Experiments without key components such as LLM and VAE features show a drop in scores, highlighting the importance of each element of the proposed method, which is crucial to achieving state-of-the-art results.
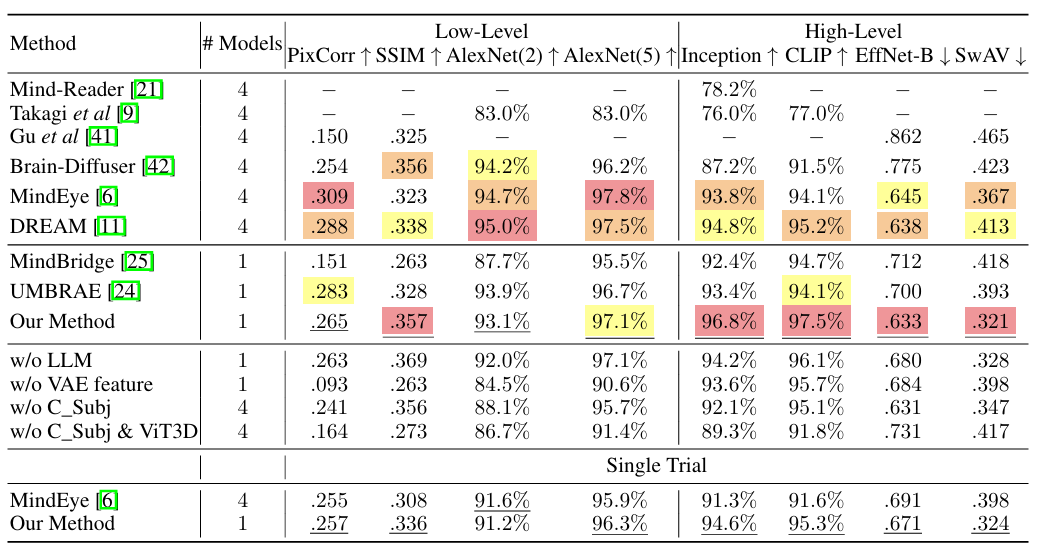
In addition, the researchers conducted a single-trial validation, choosing to use only the first visual stimulus, similar to the MindEye approach. The results showed that even under more stringent conditions, the proposed method showed only a slight decrease in performance.It proves its feasibility in practical application.
In the concept localization experiment, the researchers first fine-tuned LLMs to extract target concepts from natural language, which, once encoded by the CLIP text encoder, become the targets of GradCAM. To improve localization accuracy, the researchers trained 3 models with different patch sizes (14, 12, 10) and used the penultimate layer of all models to extract semantic features. As shown in the figure below, this shows thatThe proposed method is able to distinguish the locations of various semantics in brain signals of the same visual stimulus.

To verify the effectiveness of this method, the researchers conducted an ablation study on semantic concepts. After locating the concepts in the original brain signals, the signals in the identified voxels were set to zero, and then the modified brain signals were used for feature extraction and visual reconstruction. As shown in the figure below, removing the neural activity in specific brain areas related to certain semantic concepts will cause the corresponding semantics to be ignored in the visual reconstruction.This confirms the validity of the approach for concept localization in brain signals and demonstrates the ability of the method to extract and modify semantic information in brain activity, which is crucial for understanding semantic information processing in the brain.

In general, the framework leverages the capabilities of Vision Transformer 3D with fMRI data, enhanced by the integration of LLMs, to significantly improve the reconstruction of visual stimuli from brain signals and provide a more precise and interpretable understanding of the underlying neural mechanisms. This achievement provides a new research path for decoding and interpreting brain activity, and is of great significance in neuroscience and brain-computer interfaces.
Decoding the truth about how the human brain works and exploring nature's most mysterious instrument
The brain is the most important biological organ of human beings and the most sophisticated instrument in nature. It has hundreds of billions of nerve cells and trillions of connected synapses, forming neural networks and neural circuits that dominate various brain functions. With the continuous development of life science technology and artificial intelligence, the truth about how the brain works is becoming clearer and clearer.
It is worth mentioning that the Institute of Automation of the Chinese Academy of Sciences, where this paper was published, is a leader in the development of artificial intelligence in my country and has long been involved in research in the field of brain science, especially in the encoding and decoding of visual information in the human brain. In addition to the team of Professor Zeng Yi mentioned above, the institute has published many high-level papers related to brain science, which have been included in internationally renowned journals.
For example, at the end of 2008, the research results published by the team led by Professor He Huiguang of the school, entitled "Reconstructing Perceived Images from Human Brain Activities with Bayesian Deep Multiview Learning", were included in the IEEE Transactions on Neural Networks and Learning Systems, an internationally renowned journal in the field of neural networks and machine learning.
In this study, the research team established the relationship between visual images and brain responses in a scientifically sound way.The problem of visual image reconstruction is transformed into a Bayesian inference problem of missing views in a multi-view latent variable model. This research not only provides a powerful tool for exploring the visual information processing mechanism of the brain, but also promotes the development of brain-computer interfaces and brain-like intelligence.
In addition to the Institute of Automation of the Chinese Academy of Sciences, the research team of the National University of Singapore is also studying the use of fMRI to record the images seen by the subjects, and then using machine learning algorithms to restore them into images. The relevant results were published on arXiv under the title "Seeing Beyond the Brain: Conditional Diffusion Model with Sparse Masked Modeling for Vision Decoding".

In addition, many commercial companies are also rushing to explore the "brain world".Not long ago, Elon Musk also shared his insights on his brain-computer interface company Neuralink and brain-computer interface technology at the 2024 Neurosurgeons Conference.Some even suggested that the cost of brain-computer interfaces should not be too high.
In short, brain decoding technology can be said to be a continuous and rapid development process. Whether it is driven by scientific research institutions or commercial companies, they are riding on the east wind of artificial intelligence and machine learning to accelerate the arrival of the era of intelligent brains. It is also worth believing that scientific progress will also be reflected in applications, such as the development of brain-computer interfaces, using machines to benefit patients with damaged nervous systems, and so on.









