Command Palette
Search for a command to run...
Online Tutorial | Beat GPT-4V? The Powerful Open Source Multimodal Large Model LLaVA-OneVision Is Officially Launched!

Large Language Model (LLM) and Large Multimodal Model (LMM) are two core development directions in the field of artificial intelligence. LLM is mainly dedicated to processing and generating text data, while LMM goes a step further and aims to integrate and understand multiple data types including text, images, and videos. Today, LLM is relatively mature, and ChatGPT and other tools are already "fluent" in text understanding. People are beginning to shift their attention to the understanding of multimodal data, enabling models to "read images and watch videos."
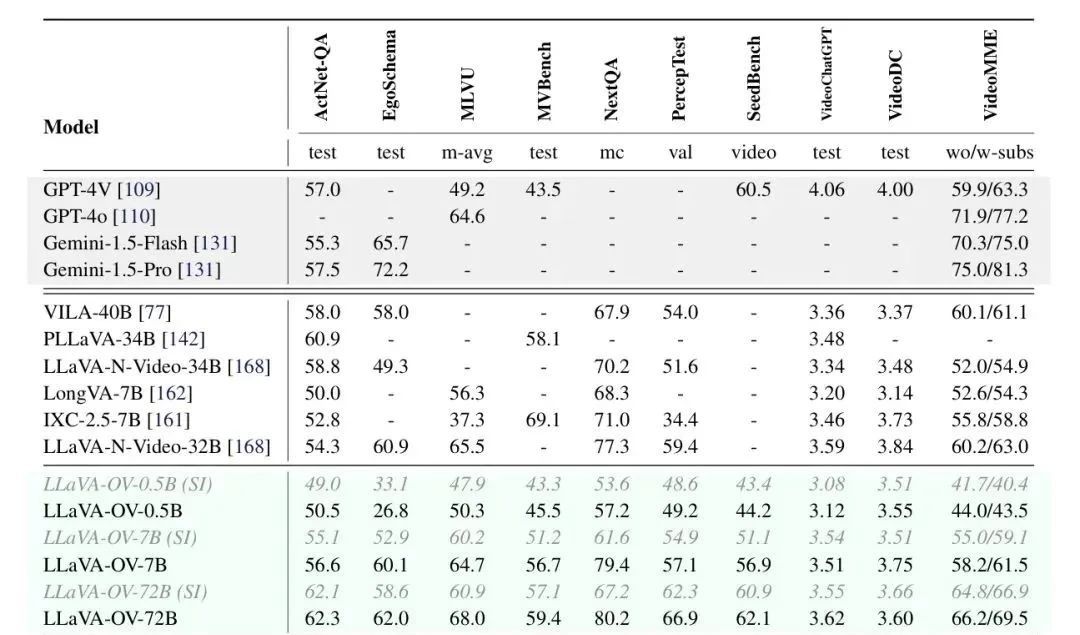
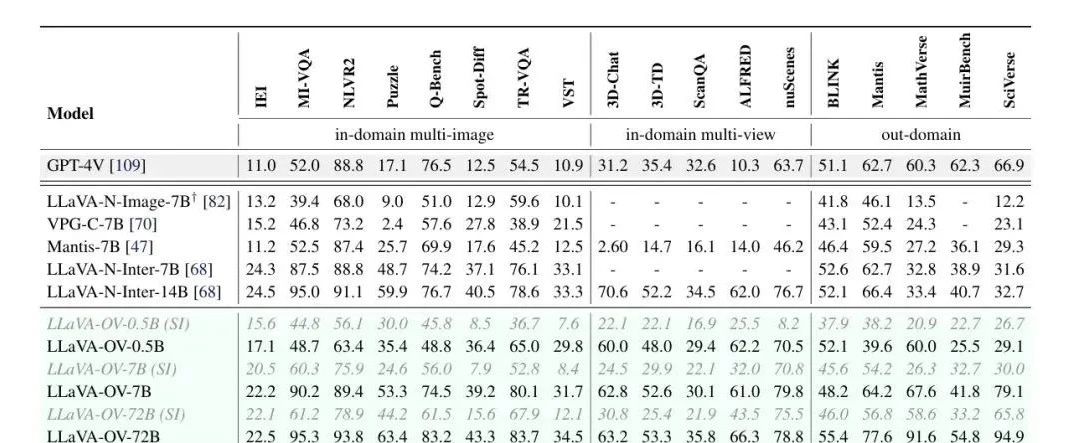
Recently, researchers from ByteDance, Nanyang Technological University, the Chinese University of Hong Kong, and the Hong Kong University of Science and Technology jointly open-sourced the LLaVA-OneVision multimodal large model, which has demonstrated excellent performance in single-image, multi-image, and video tasks. LMMs-Eval, an evaluation framework designed specifically for multimodal large models, shows that LLaVA-OneVision-72B outperforms GPT-4V and GPT-4o on most benchmarks, as shown in the following figure:
HyperAI Hyperneuron Tutorial is now available"LLaVA-OneVision Multimodal All-Round Vision Model Demo"Users can easily handle a variety of visual tasks by simply cloning and starting with one click. Whether it is the analysis of static images or the parsing of dynamic videos, it can provide high-quality output.
Tutorial address:
Demo Run
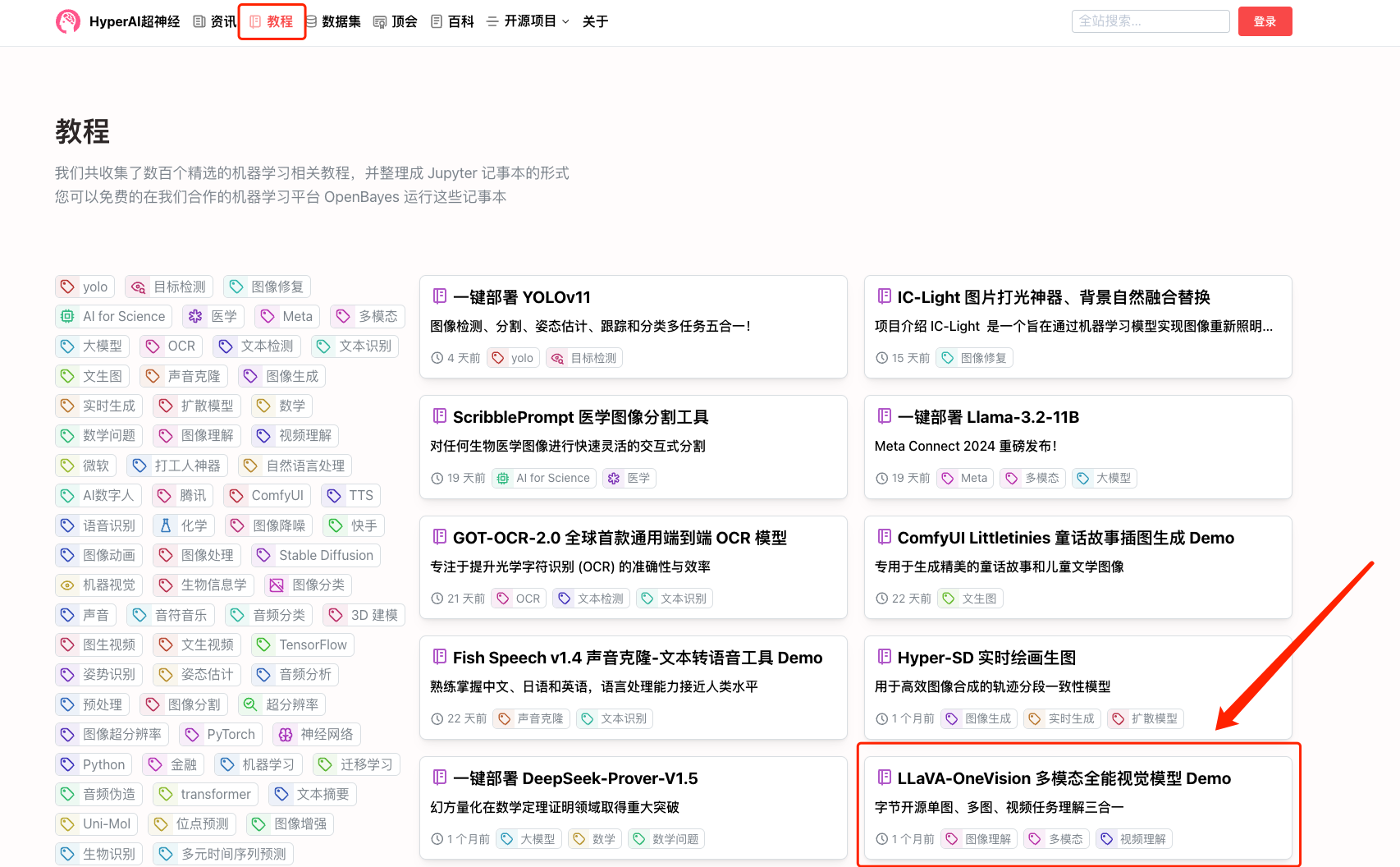
1. Log in to hyper.ai, on the Tutorial page, select LLaVA-OneVision Multimodal Universal Vision Model Demo, and click Run this tutorial online.
2. After the page jumps, click "Clone" in the upper right corner to clone the tutorial into your own container.
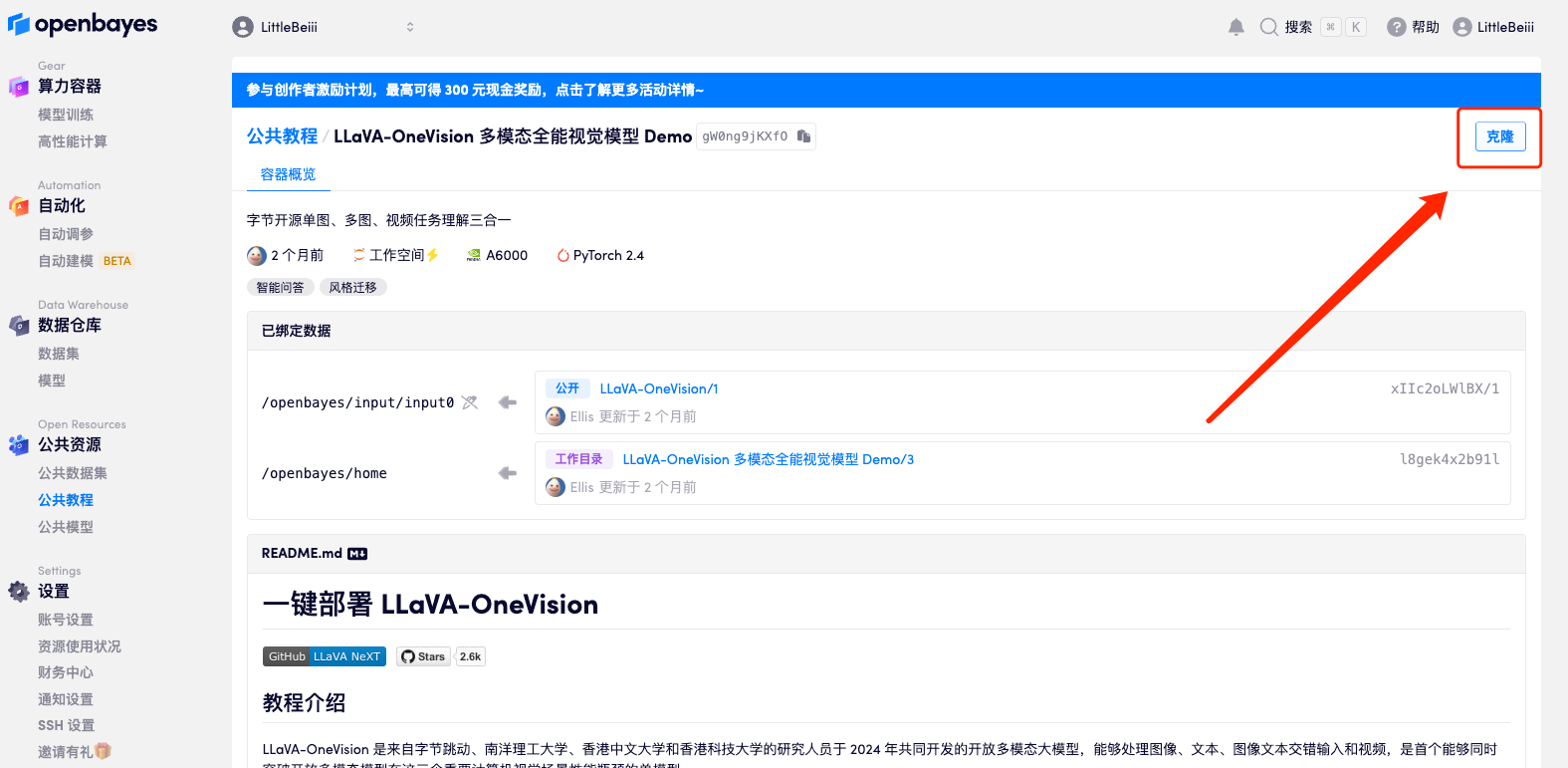
3. Click "Next: Select Hashrate" in the lower right corner.
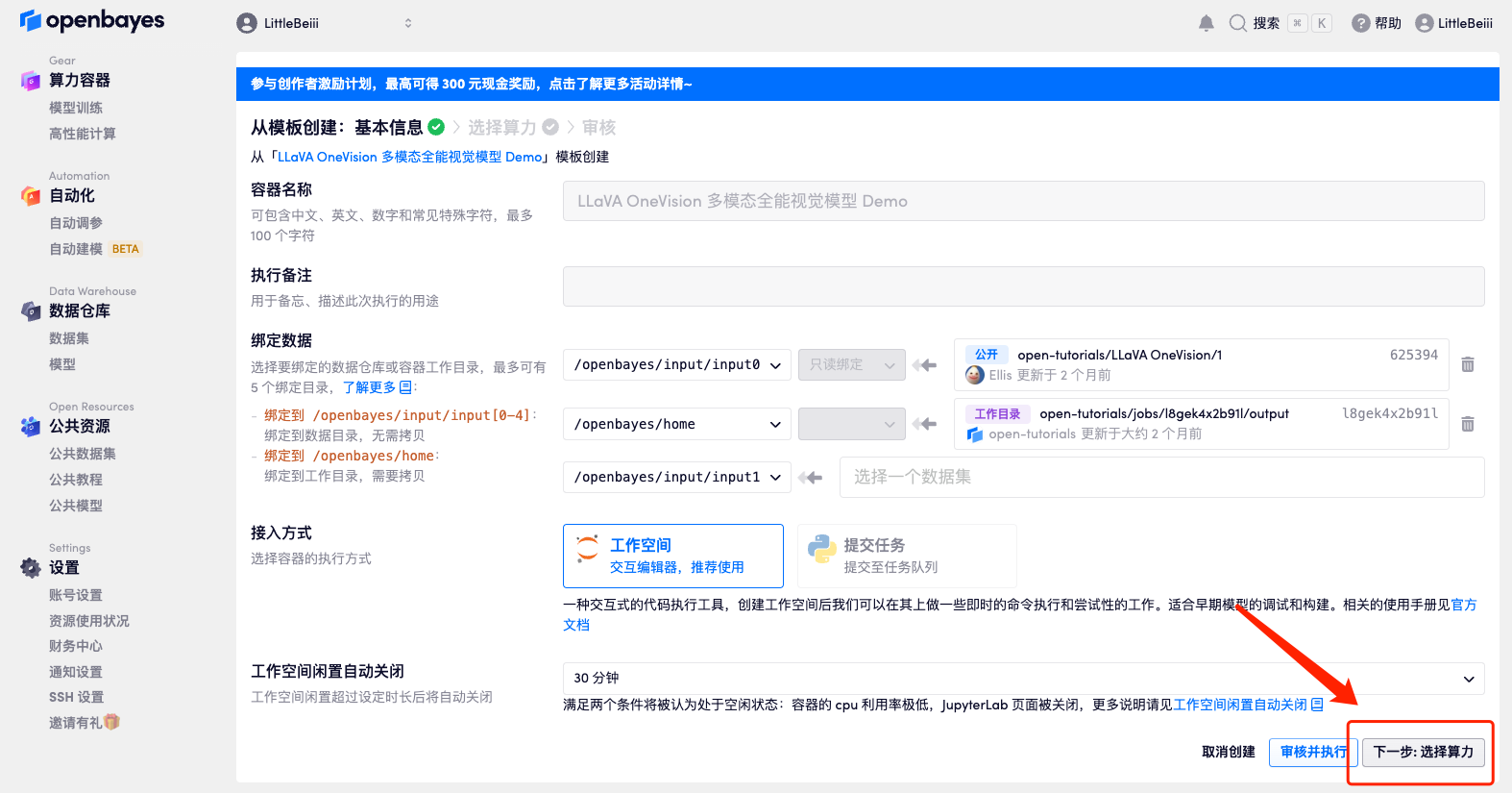
4. After the page jumps, select "NVIDIA RTX A6000" and "PyTorch" image, and click "Next: Review".New users can register using the invitation link below to get 4 hours of RTX 4090 + 5 hours of CPU free time!
HyperAI exclusive invitation link (copy and open in browser):
https://openbayes.com/console/signup?r=Ada0322_QZy7
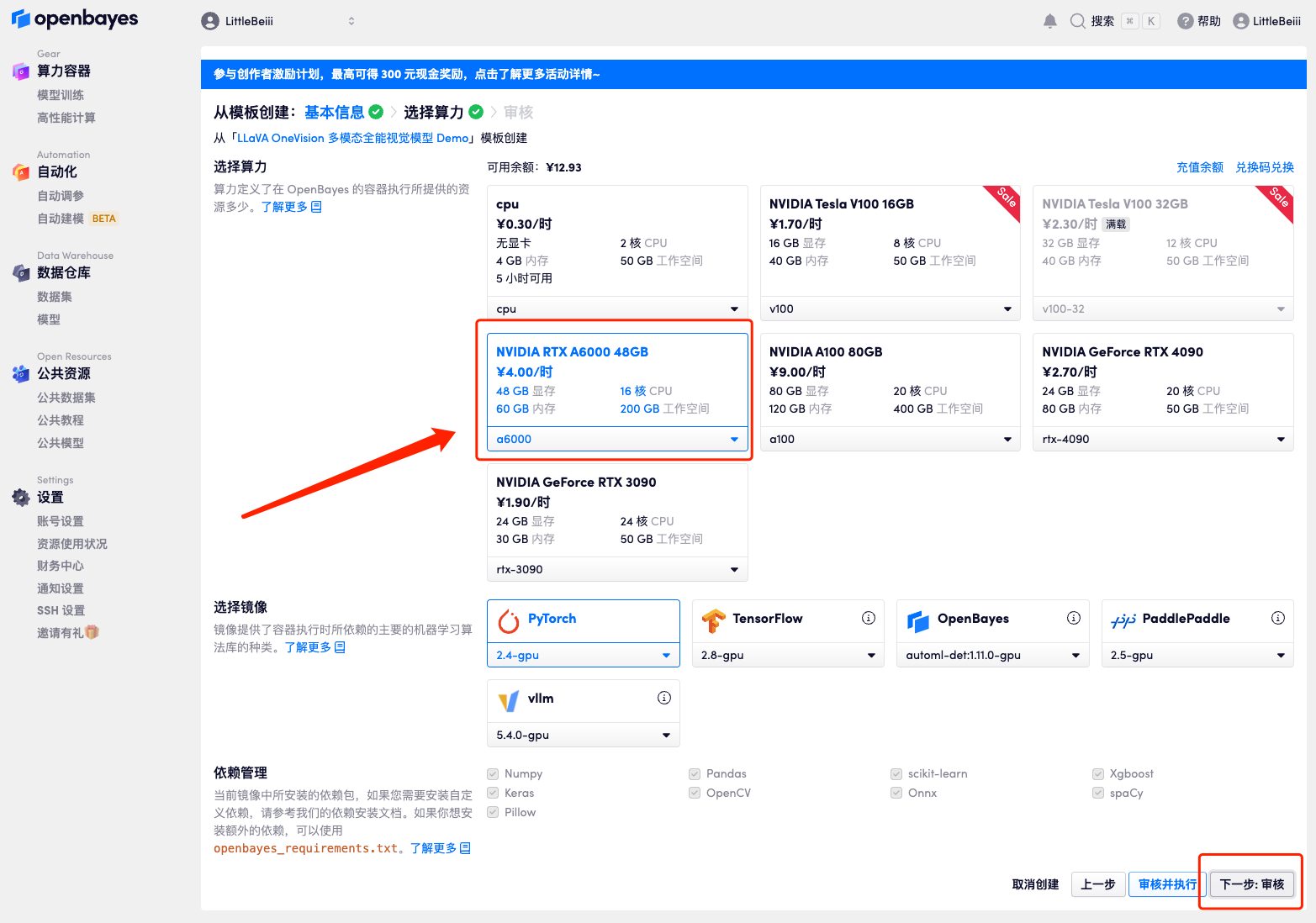
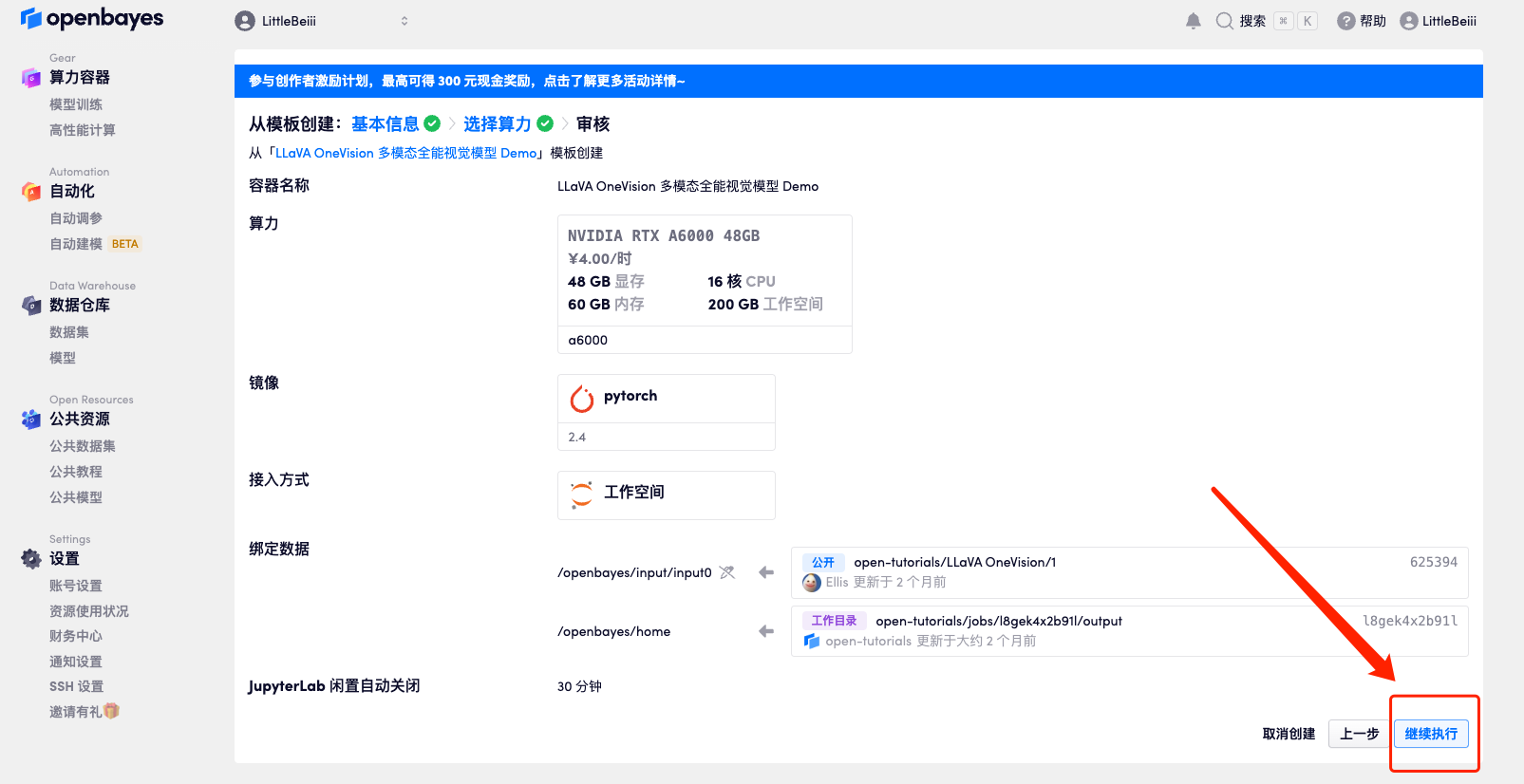
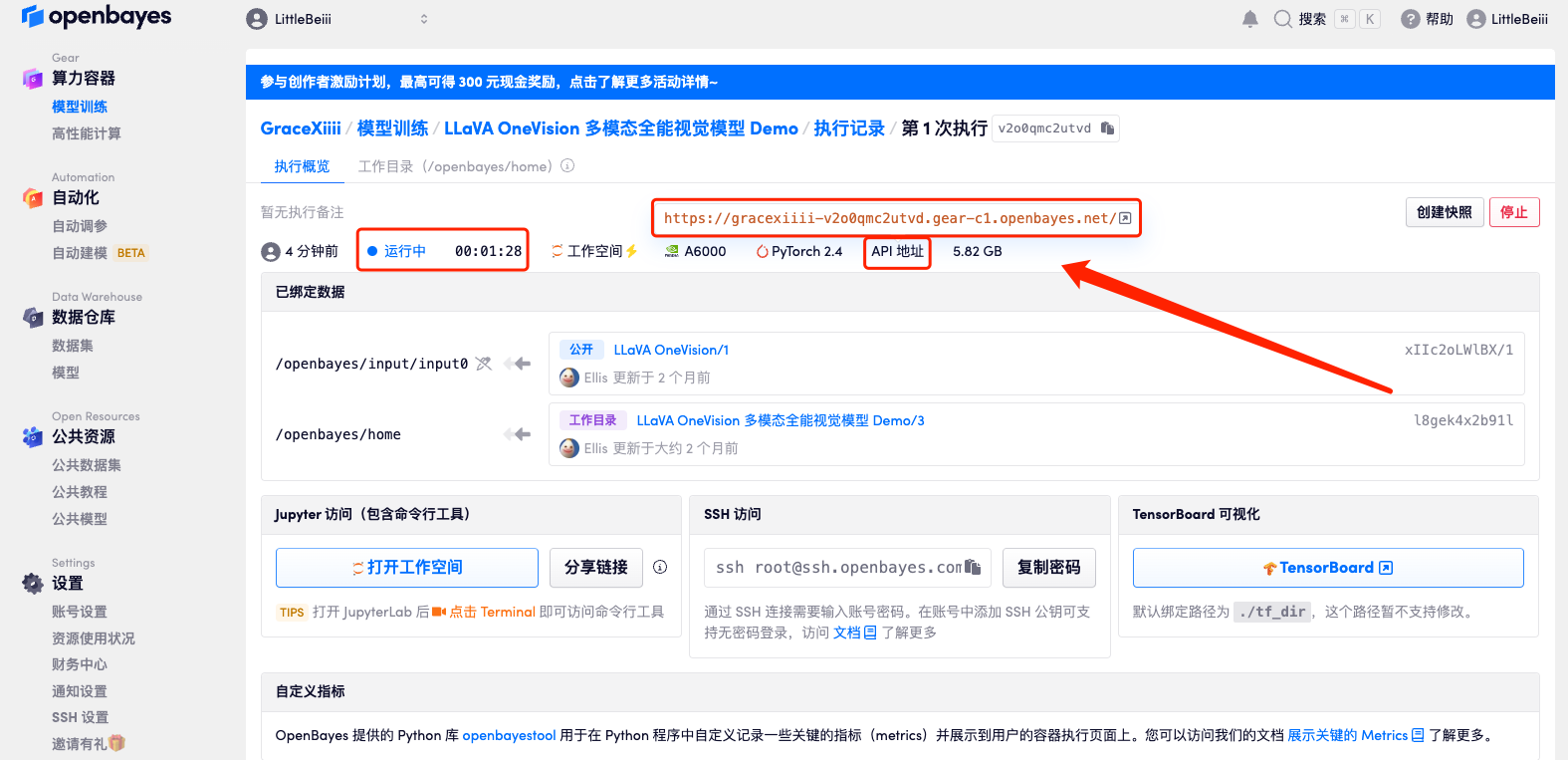
5. After confirmation, click "Continue" and wait for resources to be allocated. The first cloning takes about 3 minutes. When the status changes to "Running", click the jump arrow next to "API Address" to jump to the Demo page.Please note that users must complete real-name authentication before using the API address access function.Because the model is too large, after the container shows that it is running, you need to wait for about 1 minute before opening the API address, otherwise BadGateway will be displayed.
Effect Demonstration
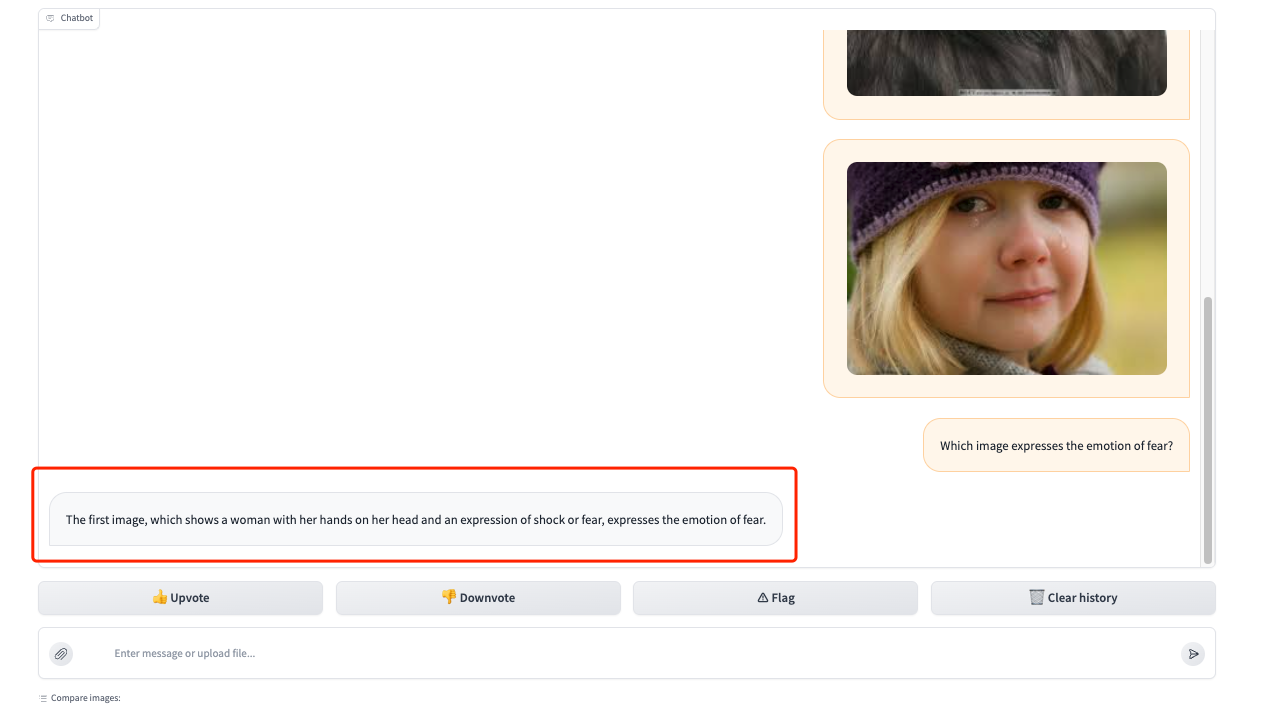
1. After opening the Demo interface, let's first test its ability to understand pictures. Upload 3 photos of different emotions in the red frame area and enter our question "Which image expresses the emotion of fear?" You can see that it accurately answers our question and provides a description of the picture (The first image, which shows a woman with her hands on her head and an expression of shock or fear, expresses the emotion of fear).


2. It also has excellent video comprehension capabilities. Upload a video collection of highlights from an Olympic running competition and ask “What is this video about?” You can see that it can accurately answer the events of the competition and describe the video scenes and details, such as the athletes’ skin color, emotions, and sponsor logos around the stadium.

Answer translation:
The video appears to be a clip of track and field events, primarily the 100-meter sprint. It shows athletes on the starting blocks preparing to compete, with one athlete wearing a yellow and green outfit, suggesting he may be representing Jamaica, as these are the colors of the Jamaican flag. The video captures the athletes' nervousness and focus as they prepare to start, their push-off from the starting blocks, and their subsequent sprint down the track. The athletes wear uniforms that indicate their national team or sponsors, with logos of various sponsors, such as TOYOTA and TDK, visible around the stadium. The video also includes close-ups of the athletes' faces, showing their focus and determination. The final frame shows the athletes sprinting at full speed, with one athlete leading the rest of the pack, suggesting a competitive race is underway.
We have established a "Stable Diffusion Tutorial Exchange Group". Welcome friends to join the group to discuss various technical issues and share application results~
Scan the QR code below to add HyperaiXingXing on WeChat (WeChat ID: Hyperai01), and note "SD Tutorial Exchange Group" to join the group chat.









