Command Palette
Search for a command to run...
Selected for ECCV 2024! Covering 54,000+ Images, MIT Proposed a General Model for Medical Image Segmentation, ScribblePrompt, Which Performs Better Than SAM

Laymen watch the excitement, experts watch the doorway, this saying is absolutely true in the field of medical imaging. Not only that, even as an expert, it is not easy to accurately see the "doorway" in complex medical images such as X-rays, CT scans or MRIs. Medical image segmentation is to segment certain parts with special meanings from complex medical images and extract relevant features, so as to assist doctors in providing patients with more accurate diagnosis and treatment plans, and also provide more reliable basis for scientific researchers to conduct pathological research.
In recent years, thanks to the development of computer and deep learning technology,The method of medical image segmentation is gradually accelerating from manual segmentation to automated segmentation, and trained AI systems have become an important aid for doctors and researchers.However, due to the complexity and professionalism of medical images, a lot of work in system training still relies on experienced experts to manually segment and create training data, which is a time-consuming and labor-intensive process. At the same time, existing deep learning-based segmentation methods have also encountered many challenges in practice, such as applicability issues and flexible interaction requirements.
In order to address the limitations of existing interactive segmentation systems in practical applications, a team from the Massachusetts Institute of Technology's Computer Science and Artificial Intelligence Laboratory (MIT CSAIL) teamed up with researchers from Massachusetts General Hospital and Harvard Medical School to develop a new interactive segmentation system that can be used to identify and segment faces.We propose a general model for interactive biomedical image segmentation, ScribblePrompt, a neural network-based segmentation tool that supports annotators using different annotation methods such as scribbles, clicks, and bounding boxes to flexibly perform biomedical image segmentation tasks, even for untrained labels and image types.
The research, titled "ScribblePrompt: Fast and Flexible Interactive Segmentation for Any Biomedical Image", has been included in the internationally renowned academic platform arXiv and accepted by the top international academic conference ECCV 2024.
Research highlights:
* Quickly and accurately perform any biomedical image segmentation task, outperforming existing state-of-the-art models, especially for untrained labels and image types
* Provides flexible annotation styles, including scribble, click, and bounding box
* Higher computational efficiency, enabling fast inference even on a single CPU
* In a user study with domain experts, the tool reduced annotation time by 28% compared to SAM

Paper address:
https://arxiv.org/pdf/2312.07381
MedScribble dataset download address:
The "ScribblePrompt Medical Image Segmentation Tool" has been launched in the HyperAI Super Neural Tutorial section. You can start it by cloning it with one click. The tutorial address is:
Large datasets, comprehensive coverage of model training and performance evaluation
The study builds on large dataset collection efforts such as MegaMedical, which compiles 77 open-access biomedical imaging datasets for training and evaluation, covering 54,000 scans, 16 image types, and 711 labels.
These dataset images cover various biomedical fields, including scans of eyes, chest, spine, cells, skin, abdominal muscles, neck, brain, bones, teeth, and lesions; image types include microscopes, CT, X-rays, MRI, ultrasound, and photographs.
In terms of the division between training and evaluation,The research team divided the 77 datasets into 65 training datasets and 12 evaluation datasets.Among the 12 evaluation datasets, the data of 9 evaluation datasets were used for model development, model selection and final evaluation, and the data of the other 3 evaluation datasets were only used for the final evaluation.
Each dataset is divided into training set, validation set, and test set in a ratio of 6:2:2, as shown in the figure below.

The following two pictures are "validation and test data sets" and "training data sets".Among them, the "validation and test datasets" are invisible during the ScribblePrompt model training.
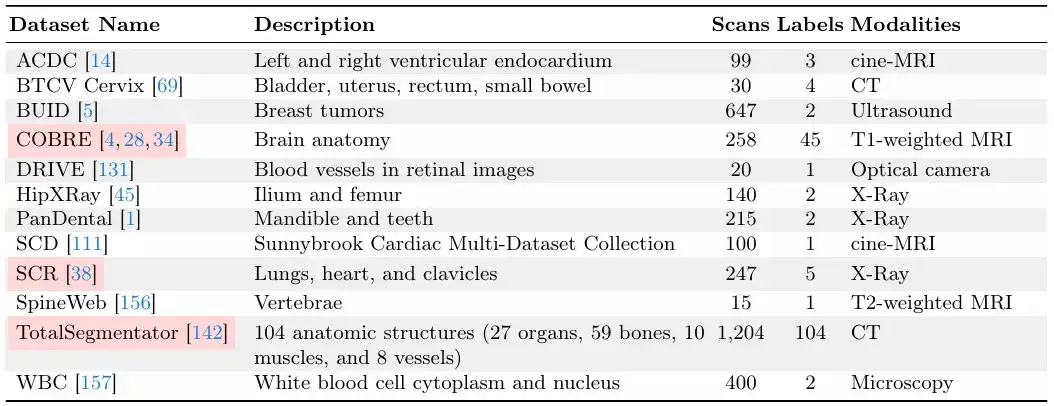
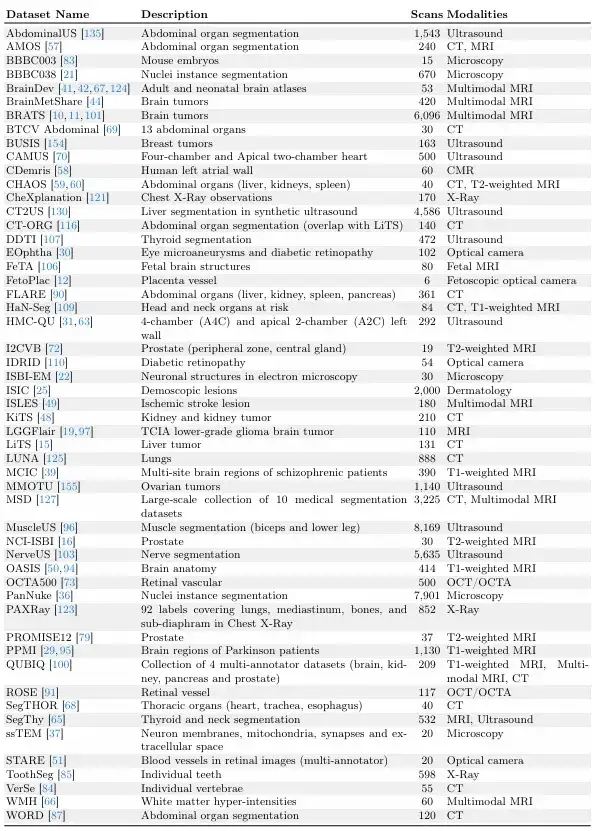
Given the relative sizes of the datasets, the research team ensured that each dataset had a unique number of scans.
Efficient architecture for fast reasoning, building practical segmentation tools
The research team proposed a flexible and interactive segmentation method with strong practical applicability that can be extended to new biomedical imaging areas and regions of interest.
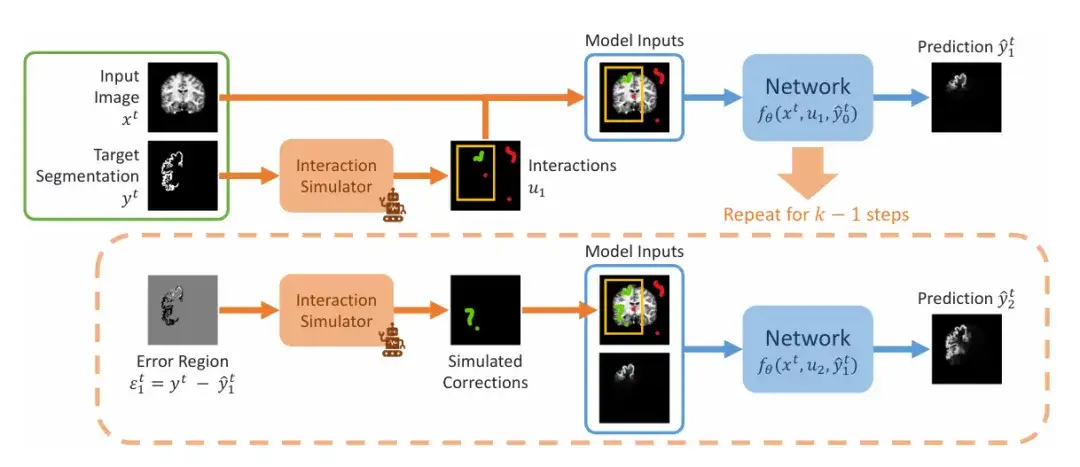
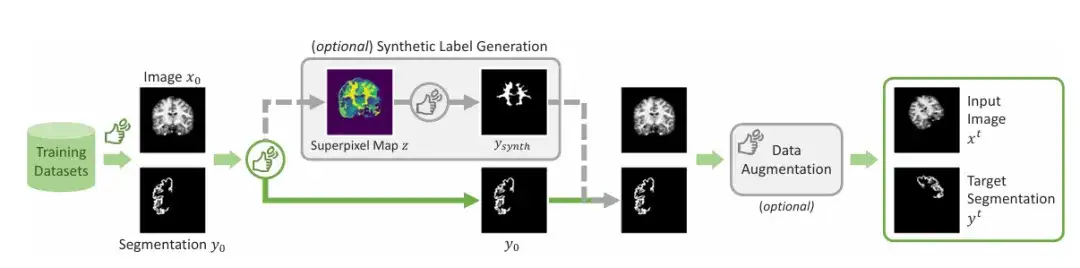
The research team demonstrated the sequential steps of simulating interaction segmentation during training, as shown in the figure below. The input is a given image segmentation pair (xᵗ, yᵗ). The team first simulates a set of initial interactions u₁, which may include bounding boxes, clicks, or scribbles, and then enters the first step of prediction, setting the initial value to 0. In the second step, the team simulates the previous prediction in the wrong area and adds it to the initial interaction set after simulation correction to obtain u₂. This is repeated to generate a series of predictions.
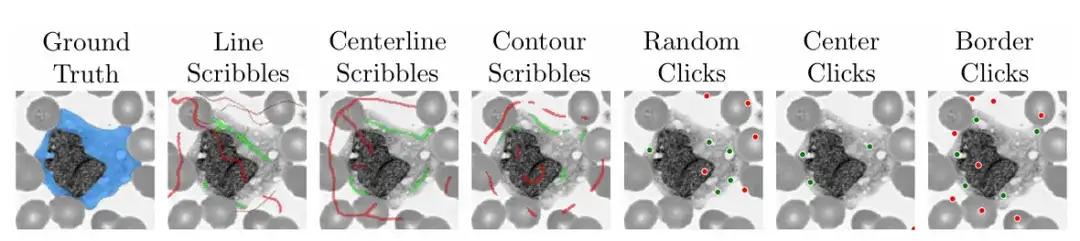
In order to ensure the practicality and ease of use of the model,The research team also used the algorithm during training to simulate practical scenarios of how to doodle, click, and input bounding boxes on different areas of medical images.
In addition to the commonly marked areas,The team introduced a mechanism to generate synthetic labels.By applying a superpixel algorithm to generate a map of potential synthetic labels, then sampling a label to generate the "Ysynth" shown in the figure, and finally applying random data augmentation to obtain the final result. This method finds parts of the image with similar values and then identifies new areas that may be of interest to medical researchers, and trains ScribblePromt to segment them. As shown in the figure below.
This research presentation mainly uses two network architectures for demonstration. One is to demonstrate ScribblePrompt using an efficient fully convolutional architecture similar to UNet, and the other is to demonstrate ScribblePrompt using a visual converter architecture.
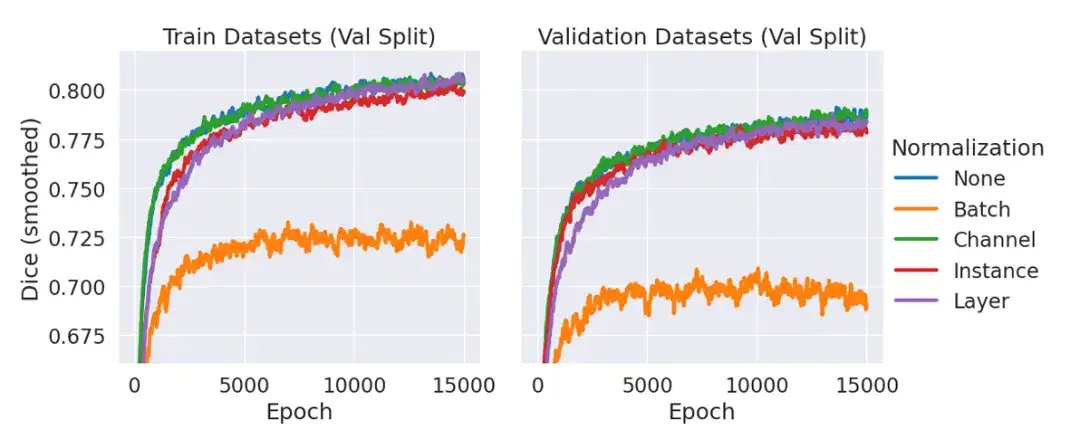
Among them, ScribblePrompt-UNet uses an 8-layer CNN, following a decoder structure similar to the popular UNet architecture, without batch norm. Each convolutional layer has 192 features and uses PReLu activation. It should be explained that there is no normalization layer because in preliminary experiments, the team found that including normalization did not improve the average dice of the validation data compared to not using a normalization layer, as shown in the figure below.
ScribblePrompt-SAM takes the smallest SAM model, ViT-b, and fine-tunes its decoder. The SAM architecture can make predictions in either single-mask mode or multi-mask mode, where the decoder outputs a single predicted segmentation given an input image and user interactions. In multi-mask mode, the decoder predicts 3 possible segmentations, and then outputs the predicted segmentation with the highest IoU through the MLP. To maximize the expressiveness of the architecture, ScribblePrompt-SAM is trained and evaluated in multi-mask mode.
ScribblePrompt demonstrates superiority over existing methods
In this study, the research team compared ScribblePrompt-UNet and ScribblePrompt-SAM with existing state-of-the-art methods, including SAM, SAM-Med2D, MedSAM, and MIDeepSeg, through manual scribble experiments, simulated interactions, and user studies with experienced annotations.
In the manual graffiti experiment,The results show that ScribblePrompt-UNet and ScribblePrompt-SAM produce the most accurate segmentation in the experimental manual scribble dataset and the single-step manual scribble of the ACDC scribble dataset, as shown in the following table.
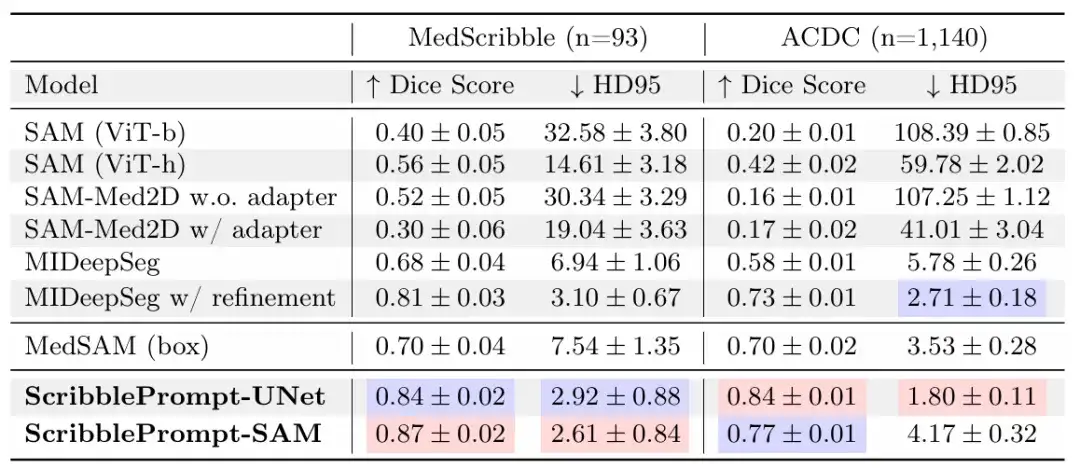
SAM and SAM-Med 2D do not generalize well to scribble inputs because they are not trained on them. MedSAM has better predictions than other SAM baselines using the SAM architecture, but it cannot exploit negative scribbles and thus often misses segmentations with holes, as shown in the figure below. Also, the initial predictions from the MIDeepSeg network are poor but improve after applying the refinement process.
In the simulated interaction experiment,The results show that for all simulated interactions at all interaction times, both versions of ScribblePrompt outperform the baseline method, as shown in the figure below.
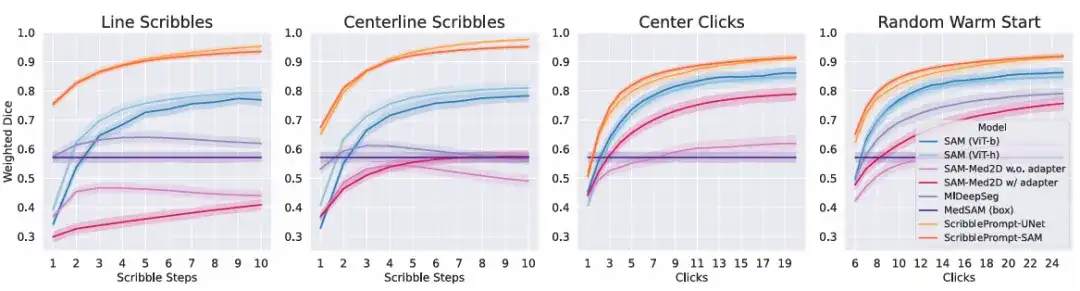
To further evaluate the practical utility of ScribblePrompt,The team conducted a user study with experienced annotators.This round of comparison is between ScribblePrompt-UNet and SAM (Vit-b), which achieved the highest dice score in the above click experiment. The results show that participants produced more accurate segmentations when using ScribblePrompt-UNet, as shown in the table below. At the same time, the average segmentation time using ScribblePrompt-UNet was about 1.5 minutes, while each segmentation time using SAM was more than 2 minutes.

16 participants reported that it was easier to achieve target segmentation using ScribblePrompt compared to SAM, 15 of whom said they preferred using ScribblePrompt, and one participant had no preference. In addition, 93.81% of participants preferred ScribblePrompt over the SAM baseline because it improved the corresponding segments for scribble corrections, and 87.51% of participants preferred using ScribblePrompt for click-based editing.
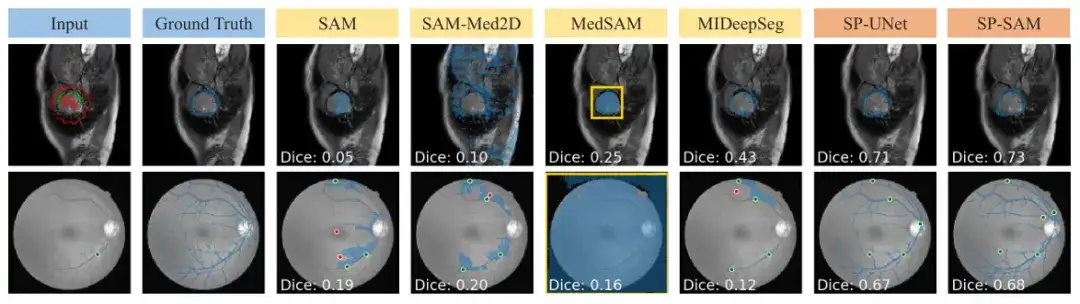
The above results once again prove the most common reason why participants prefer ScribblePrompt - self-correction and rich interactive functions. This is not possible with other methods. For example, in retinal vein segmentation, SAM has difficulty making accurate predictions even after multiple corrections.
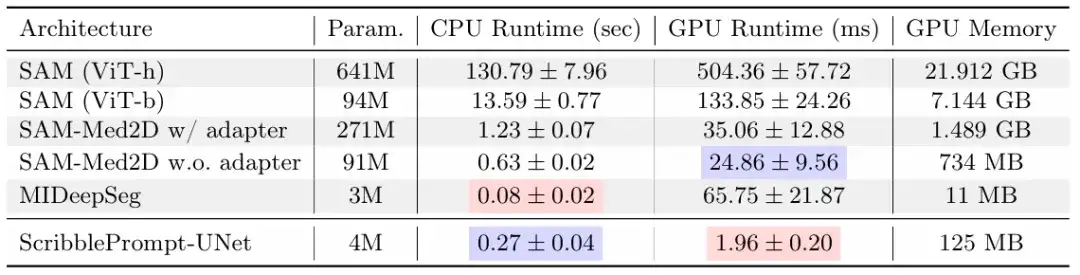
In addition, ScribblePrompt also demonstrates its low cost and easy deployment. The study found that on a single CPU, ScribblePrompt-UNet only takes 0.27 seconds for each prediction, with an error of less than 0.04 seconds. As shown in the figure above, the GPU is an Nvidia Quatro RTX8000 GPU. SAM (Vit-h) takes more than 2 minutes for each prediction on the CPU, and SAM (Vit-b) takes about 14 seconds for each prediction. This undoubtedly demonstrates the applicability of the model in extremely low-resource environments.
Free medical staff and researchers from time-consuming and laborious work
Artificial intelligence has long shown great potential in image analysis and processing other high-dimensional data. Medical image segmentation, as the most common task in biomedical image analysis and processing, has naturally become one of the important test fields for artificial intelligence empowerment.
In addition to this study,As mentioned in the article, SAM is also one of the main tools that has attracted the most attention from relevant scientific research teams in recent years.HyperAI has previously conducted follow-up research on related issues, such as "The latest application of SAM 2 has been launched! The Oxford University team released Medical SAM 2, refreshing the SOTA list of medical image segmentation"In the paper, the Oxford University team shared their discovery of the potential of SAM in medical image segmentation.
The study showcased a medical image segmentation model called Medical SAM 2 developed by the Oxford University team. Designed based on the SAM 2 framework, it not only performs well in 3D medical image segmentation tasks by treating medical images as videos, but also unlocks a new single-prompt segmentation capability. Users only need to provide a prompt for a new specific object, and the segmentation of similar objects in subsequent images can be automatically completed by the model without further input.
certainly,In addition to SAM, there are many other studies on medical image segmentation methods based on deep learning.For example, a study titled “Scribformer: Transformer Makes CNN Work Better for Scribble-based Medical Image Segmentation” was included in the internationally renowned journal and magazine IEEE Transactions on Medical Imaging.
The study was published by a team of researchers from multiple institutions including Xiamen University, Peking University, the Chinese University of Hong Kong, ShanghaiTech University and the University of Hull in the UK.The study proposed a new CNN-Transformer hybrid solution for graffiti supervised medical image segmentation, called ScribFormer.
In short, whether it is the results of MIT's research, innovations based on SAM, or other new methods, the purpose is the same. As the saying goes, all roads lead to Rome, and the application of artificial intelligence in the medical field is to benefit medicine and society.
As Hallee E Wong, the lead author of the ScribblePrompt paper and a PhD student at MIT, said,“We want to augment, not replace, the efforts of medical workers through an interactive system.”
References:
1.https://news.mit.edu/2024/scribbleprompt-helping-doctors-annotate-medical-scans-0909
2.https://arxiv.org/pdf/2312.0738








