Command Palette
Search for a command to run...
My Lord, the Era of Vincent Van Gogh Has Changed Again! SD Core Members Set up Their Own Studio, and the First Model FLUX.1 Is a Tough Rival to SD 3 and Midjourney

For a long time, from the Midjourney with diverse artistic styles, to DALL-E backed by OpenAI, to the open source Stable Diffusion (SD for short), the generation quality and speed of the text-based graph model have been continuously upgraded, and prompt understanding and detail processing have also become new directions for the internal circulation of major models.
After entering 2024, Midjourney and Stable Diffusion, which are in the "two-horse race" stage, have made efforts one after another. SD 3 was released first, and then Midjourney V6.1 was also updated. However, when people are still immersed in the comparison between SD 3 and Midjourney,A new generation of "devil" was born quietly - FLUX came out of nowhere.
When FLUX generates characters, especially scenes of real people, the effect is very close to real-life shots. The details such as the character's expression, skin sheen, hairstyle and color are very realistic.It was once hailed as the successor of Stable Diffusion.Interestingly, the two do have a close relationship.
Robin Rombach, the founder of Black Forest Labs, the team behind FLUX, is one of the co-developers of Stable Diffusion. After leaving Stability AI, Robin founded Black Forest Labs.And launched the FLUX.1 model.
Currently, FLUX.1 provides 3 versions: Pro, Dev and Schnell. The Pro version is a closed-source version provided through an API, which can be used commercially and is also the most powerful version; the Dev version is an open-source version "distilled" directly from the Pro version, with a non-commercial license; the Schnell version is the fastest streamlined version, which is said to run up to 10 times faster. It is open source and uses the Apache 2 license, suitable for local development and personal use.
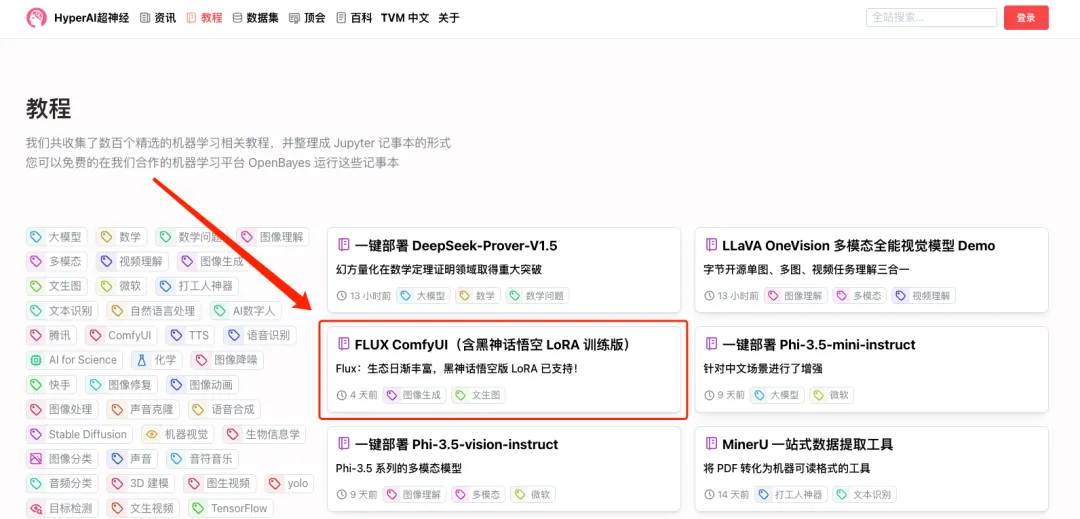
I believe that many of you want to actually experience this new generation of top-notch literary pictures!The tutorial section of HyperAI's official website (hyper.ai) has now launched "FLUX ComfyUI (including Black Myth Wukong LoRA training version)", which is the ComfyUI version of FLUX [dev] and also supports LoRA training.
If you are interested, come and try it! I have tried it for you and the effect is just as good as SD 3 and Midjourney↓

The same prompt, generated by 3 models
* prompt: a girl is holding a sign that says "I am an AI"
In addition, Jack-Cui, a popular Up Master on Bilibili, also created a detailed operation tutorial to teach everyone step by step!
Tutorial address:
Operation video:
https://www.bilibili.com/video/BV1xSpKeVEeM
Demo Run
FLUX ComfyUI Run
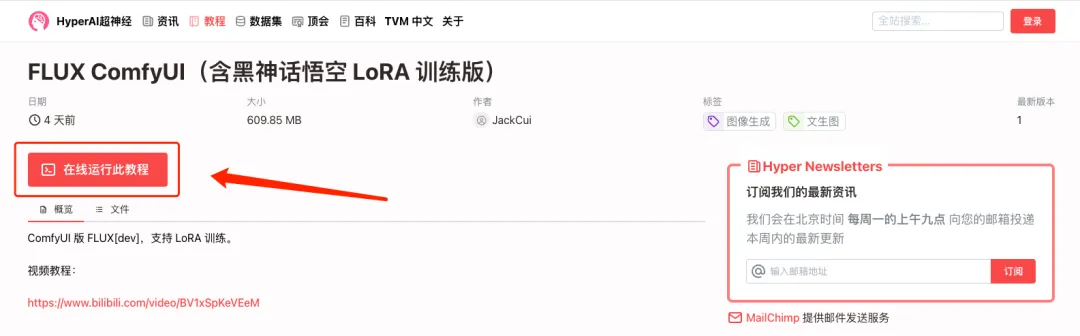
1. Log in to hyper.ai, and on the Tutorial page, click Run this tutorial online. In FLUX ComfyUI (including Black Myth Wukong LoRA training version), click Run this tutorial online.
2. After the page jumps, click "Clone" in the upper right corner to clone the tutorial into your own container.
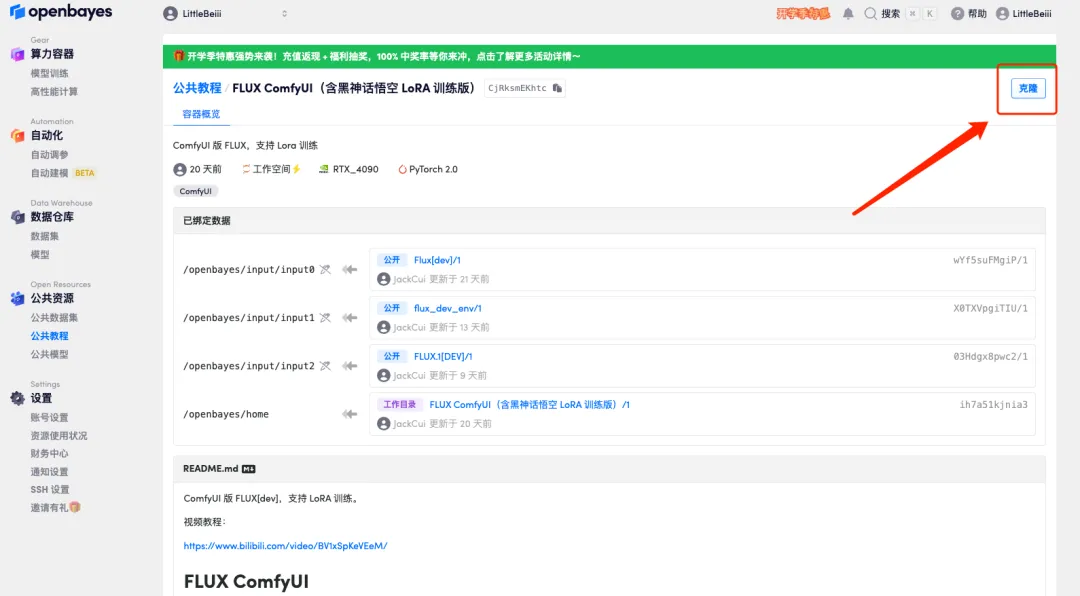
3. Click "Next: Select Hashrate" in the lower right corner.
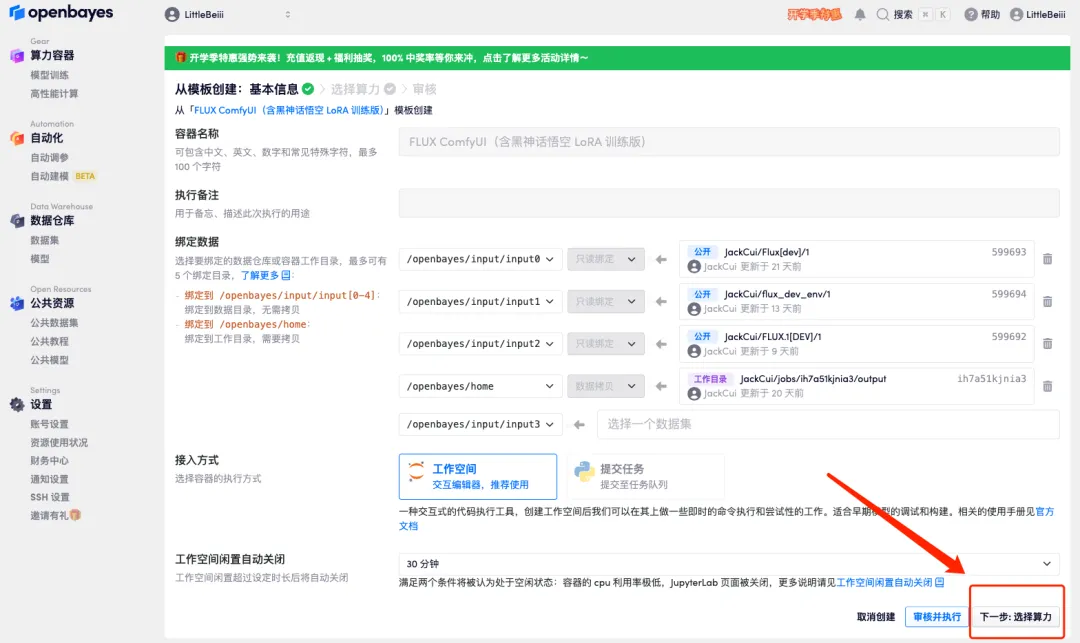
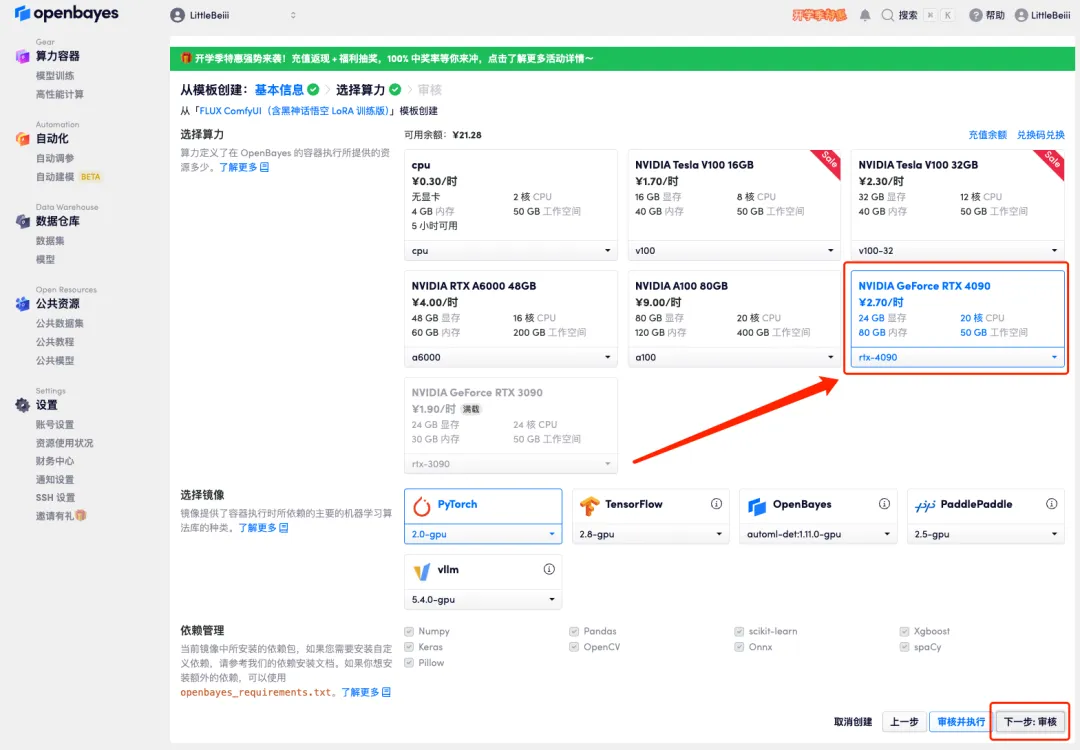
4. After the page jumps, select "NVIDIA RTX 4090" and "PyTorch" image, and click "Next: Review".New users can register using the invitation link below to get 4 hours of RTX 4090 + 5 hours of CPU free time!
HyperAI exclusive invitation link (copy and open in browser):
https://openbayes.com/console/signup?r=6bJ0ljLFsFh_Vvej
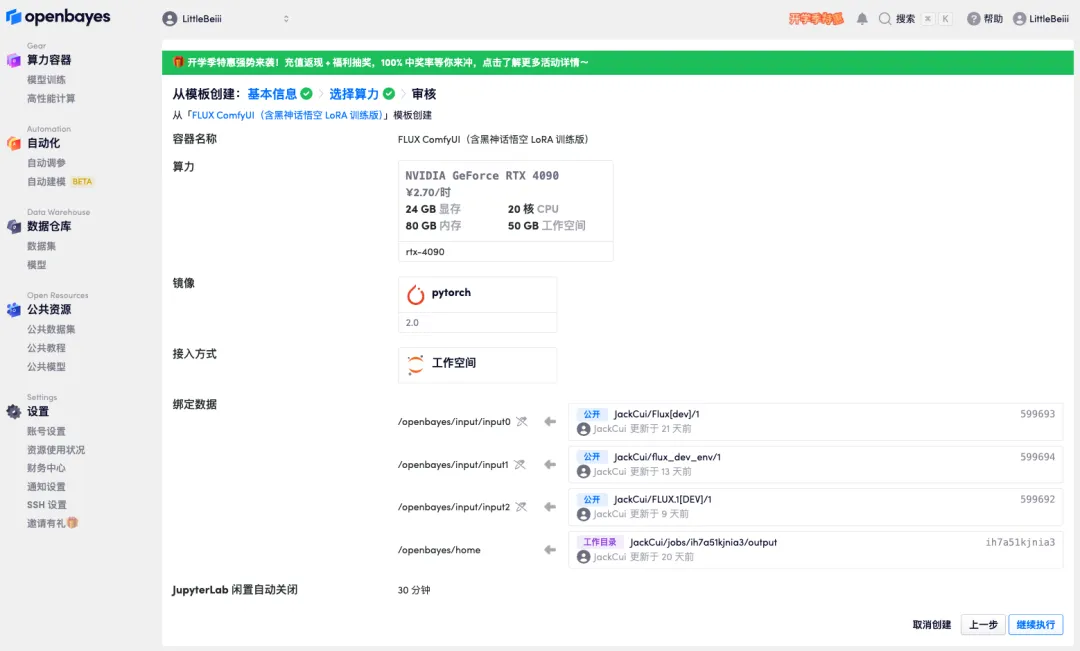
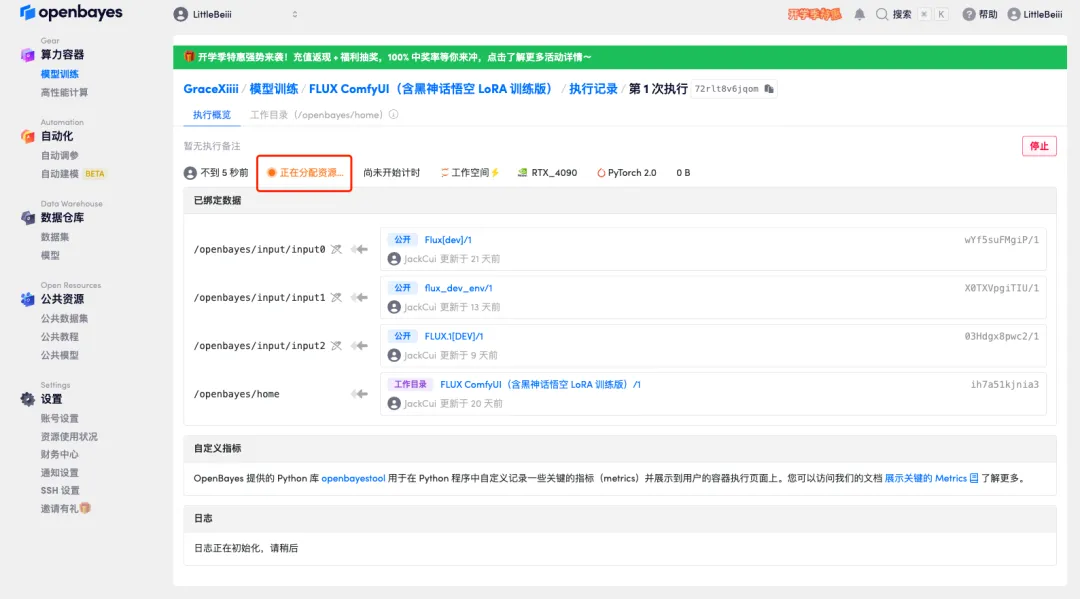
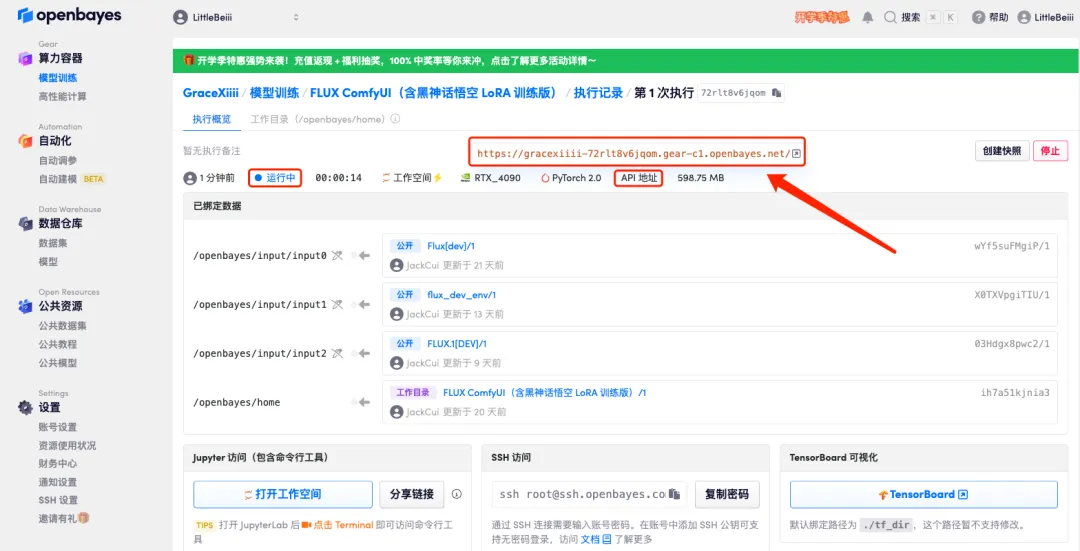
5. After confirmation, click "Continue" and wait for resources to be allocated. The first cloning takes about 1-2 minutes. When the status changes to "Running", click the jump arrow next to "API Address" to jump to the Demo page.Please note that users must complete real-name authentication before using the API address access function.
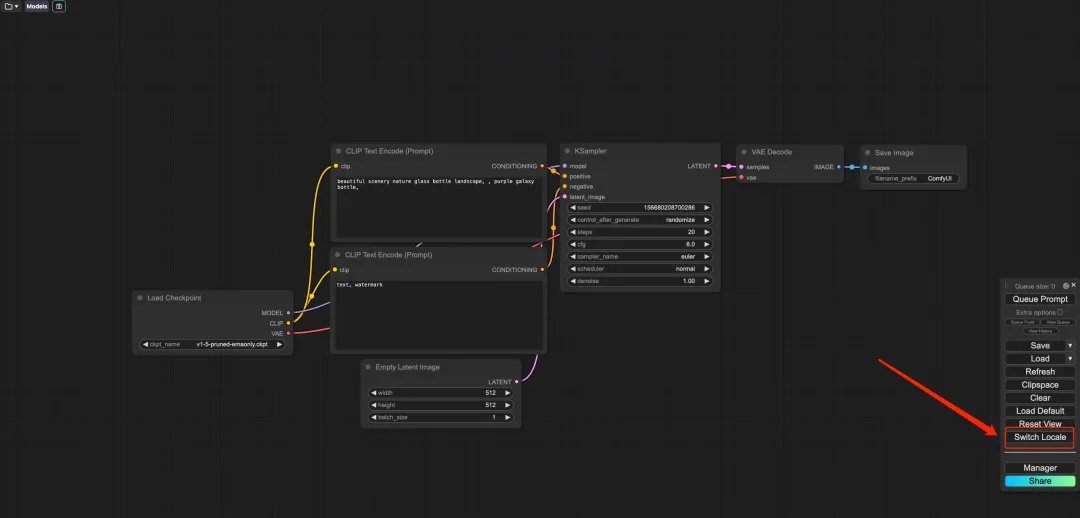
6. After opening the Demo, click "Switch Locale" to switch the language to Chinese.
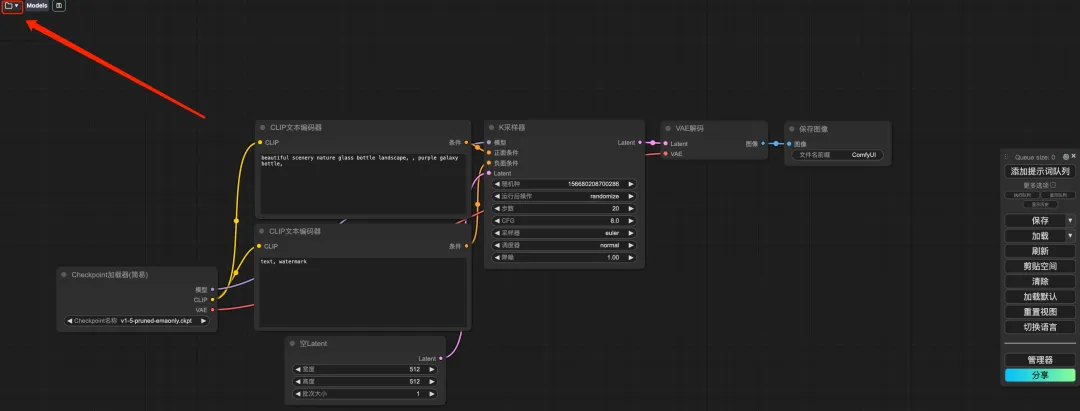
7. After switching the language, click the folder icon in the upper left corner to select the required workflow.
* Wukong: Black Myth Wukong Image Demo
* TED: TED live speech demo
* 3mm4w: Demo of writing text on pictures
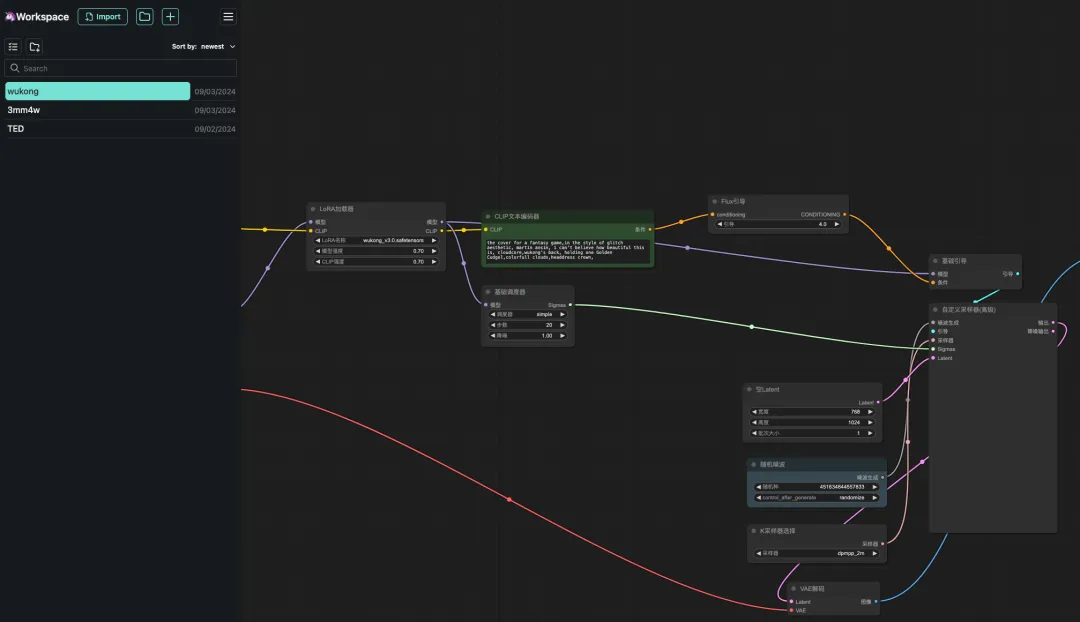
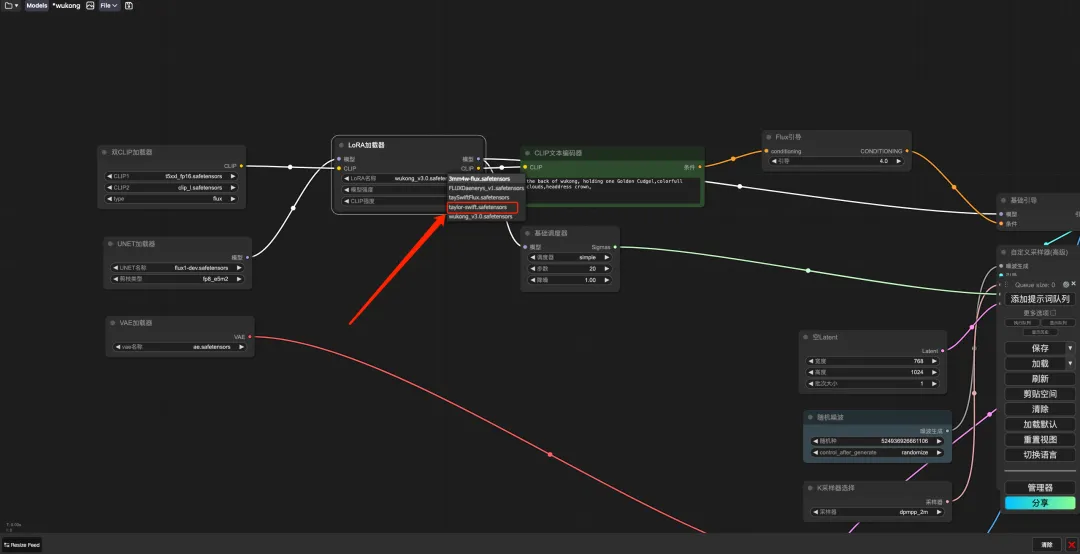
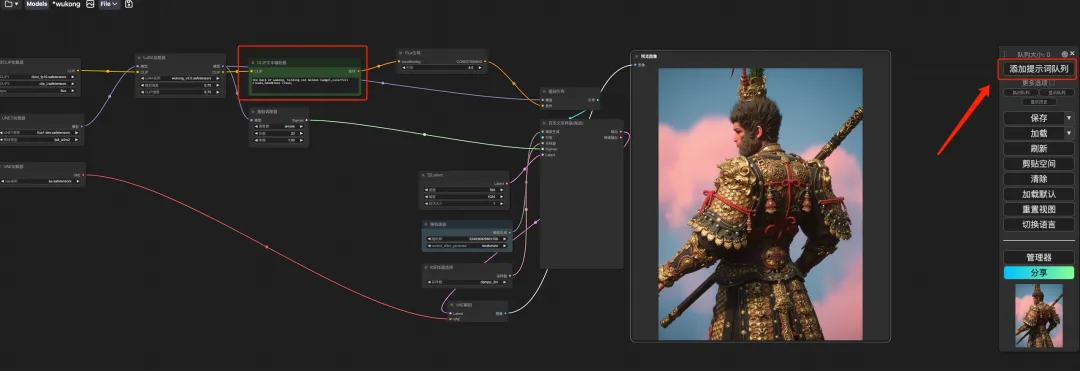
8. Select the "wukong" workflow, enter Prompt in the CLIP text generator (for example: the back of wukong, holding one golden cudgel, colorful clouds, headdress crown), click "Add prompt word queue to generate image", and you can see that the generated image is very beautiful.

FLUX LoRA Training
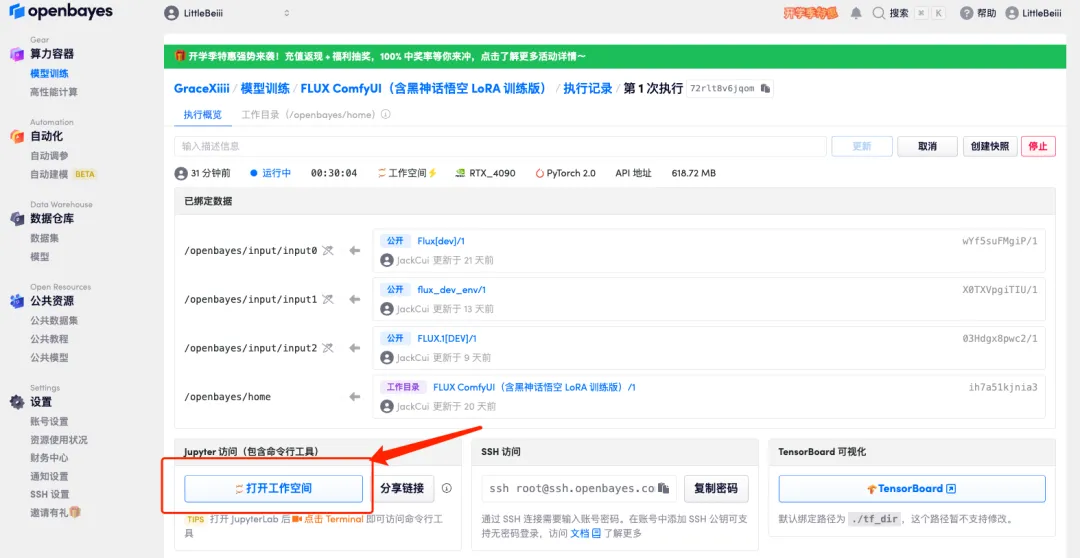
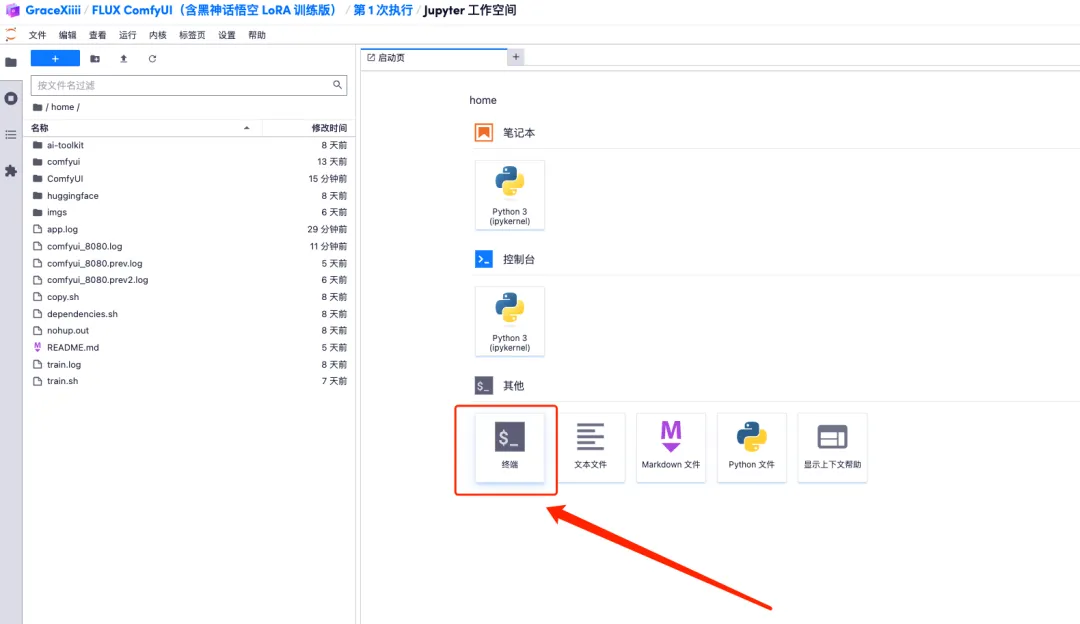
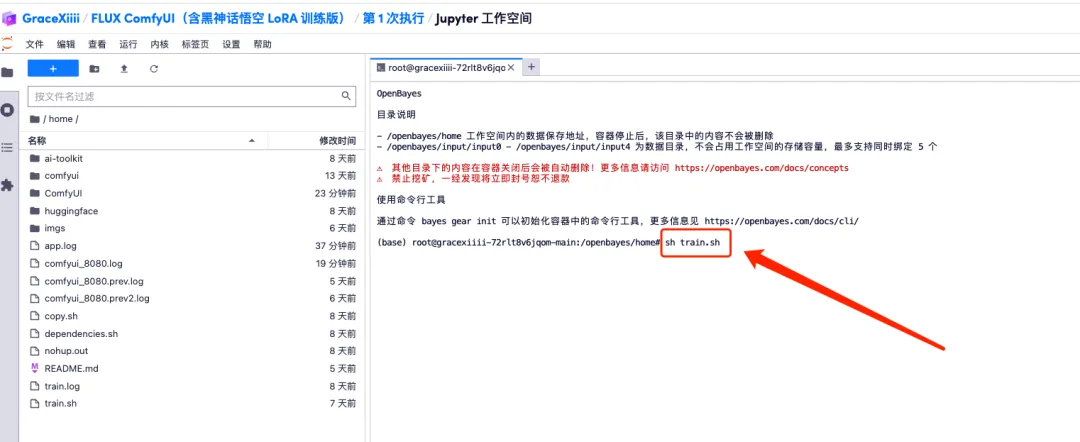
1. To customize the workflow, we need to train the LoRA model first. Return to the container interface just now, click "Open Workspace" and create a new terminal.
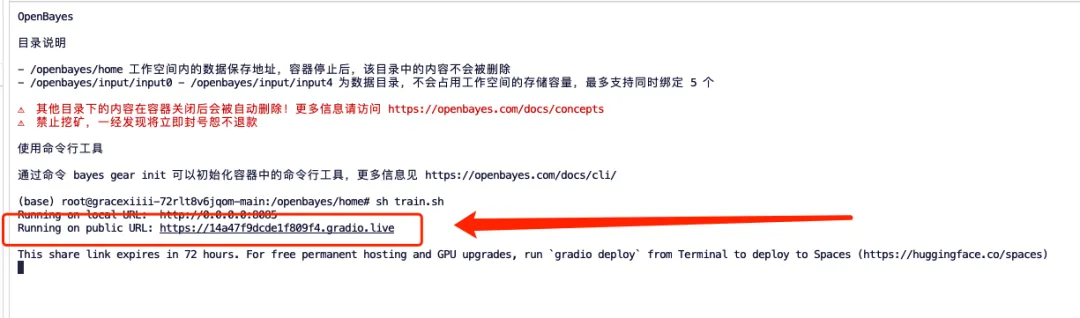
2. Enter "sh train.sh" in the terminal and press Enter to run. When "Running on public URL" appears, click the link.
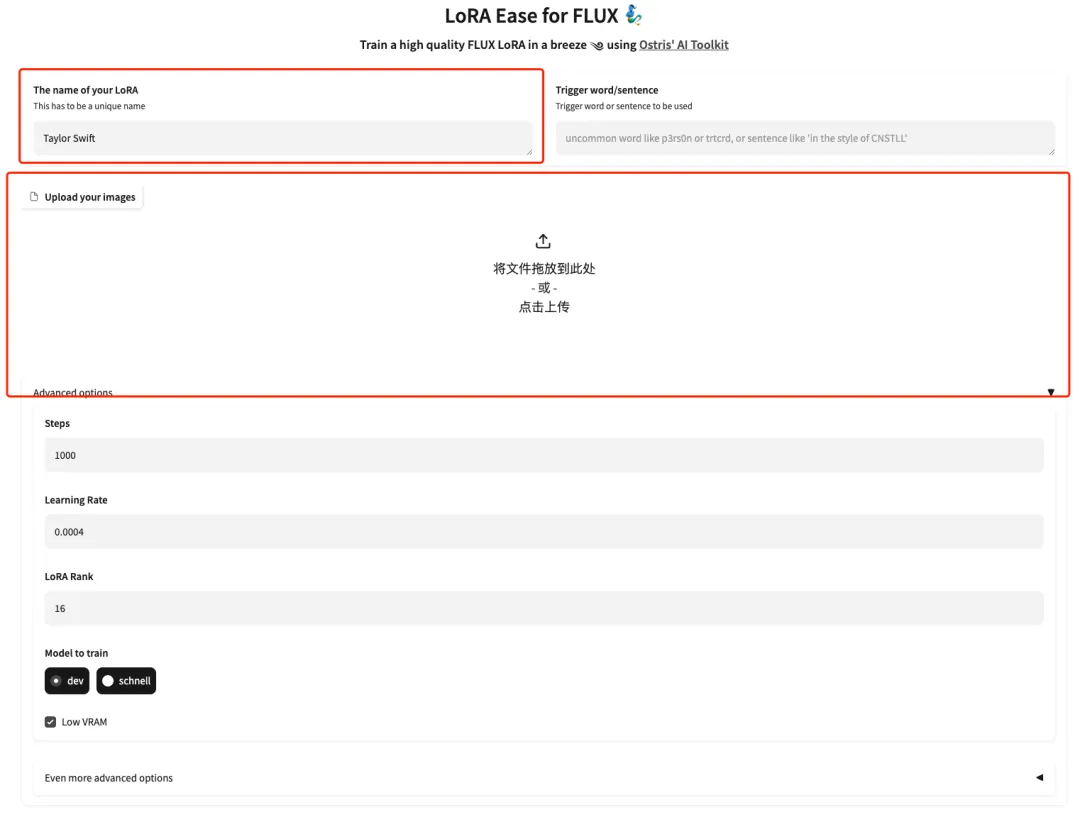
3. After the page jumps, enter the model of the model and upload the pictures. Upload 5 photos of Taylor Swift here.Please note that the image needs to be a high-resolution frontal photo with a larger face ratio. The better the image quality, the better the training effect.
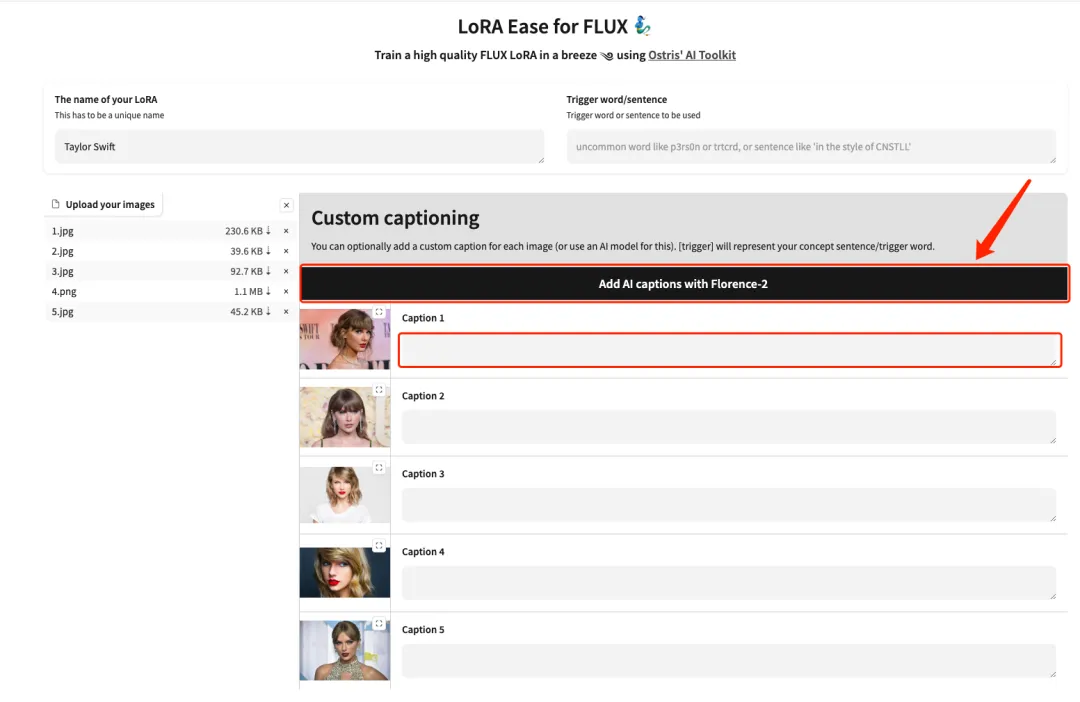
4. After uploading successfully, manually add English text descriptions after each image, or click "Add AI captions with Florence-2" to automatically generate text descriptions.
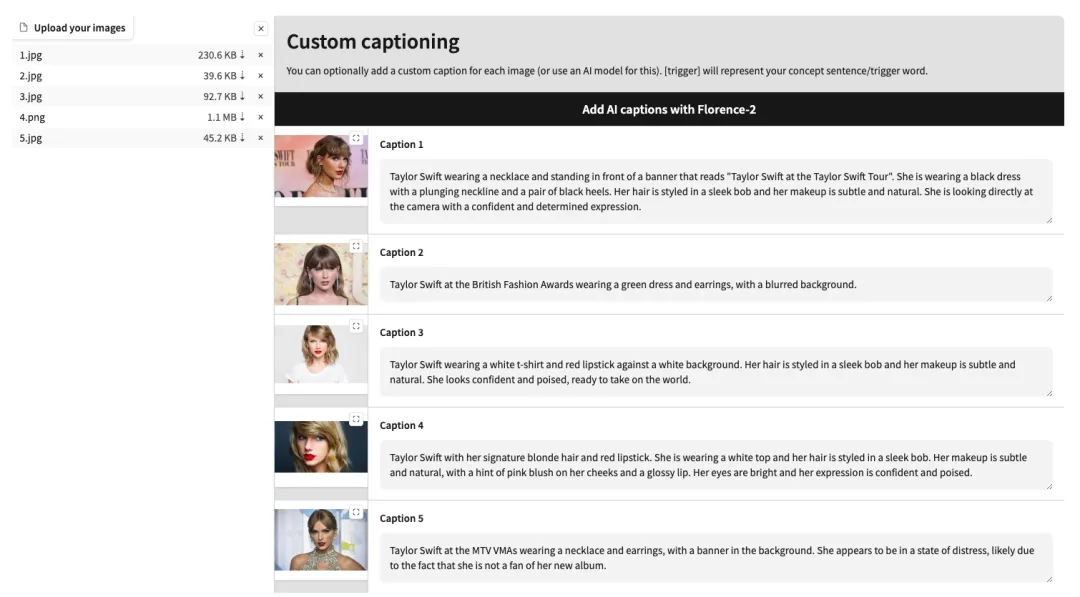
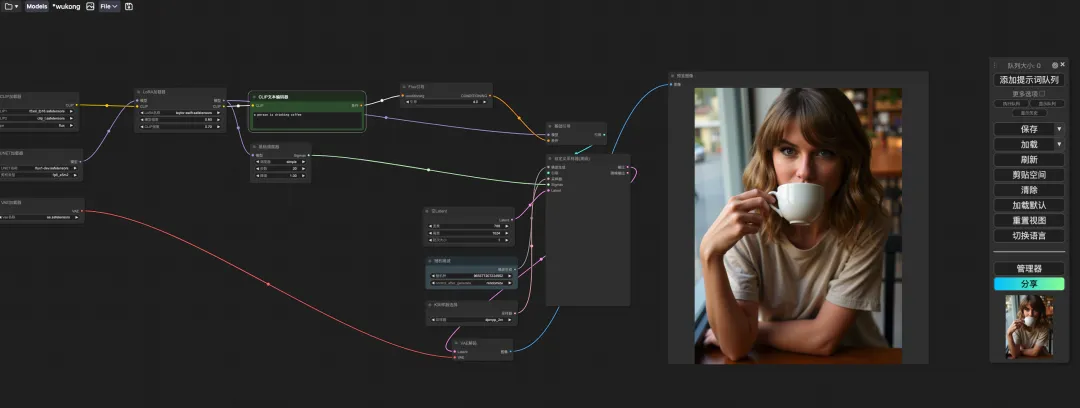
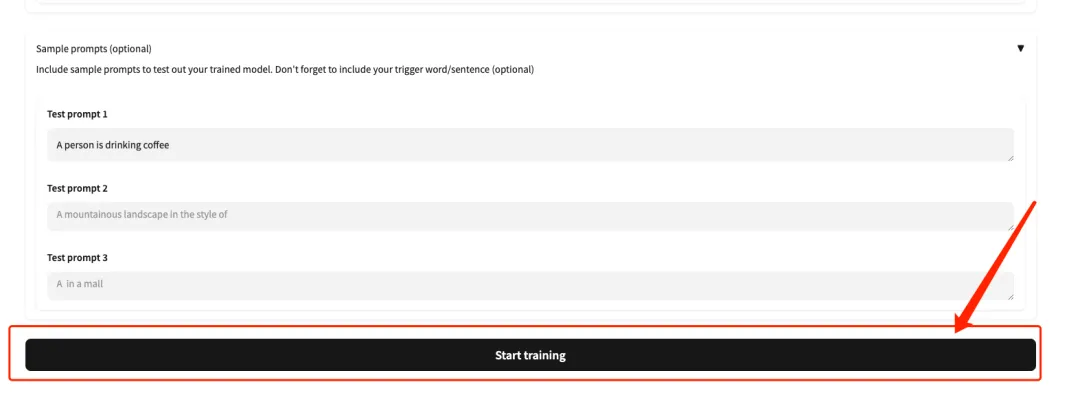
5. Scroll down to the bottom of the page, enter a Test prompt (for example: A person is drinking coffee), and click “Start training”.
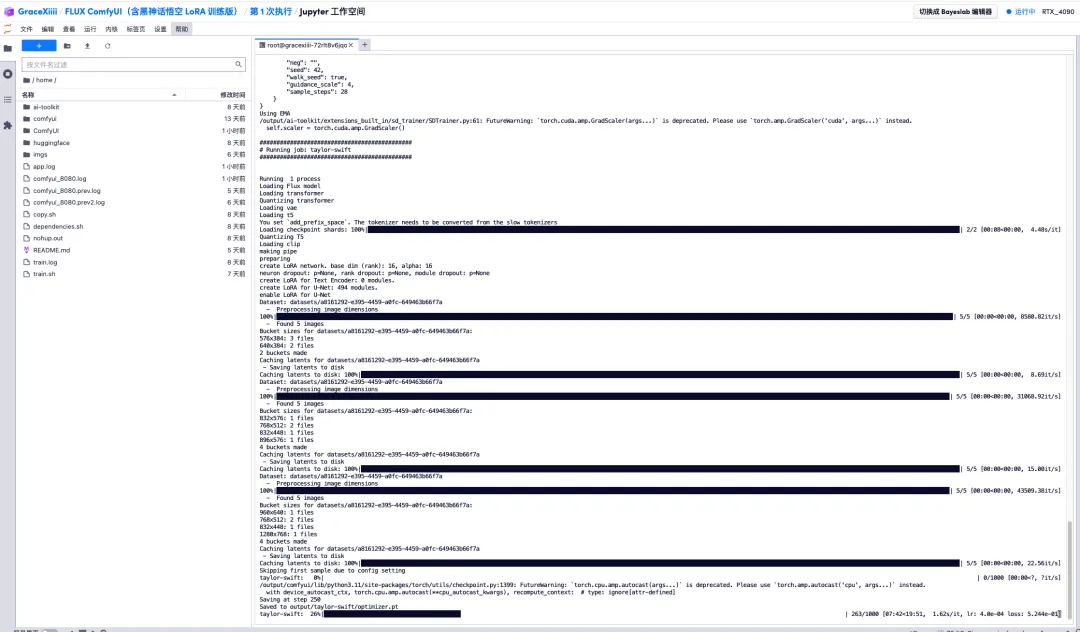
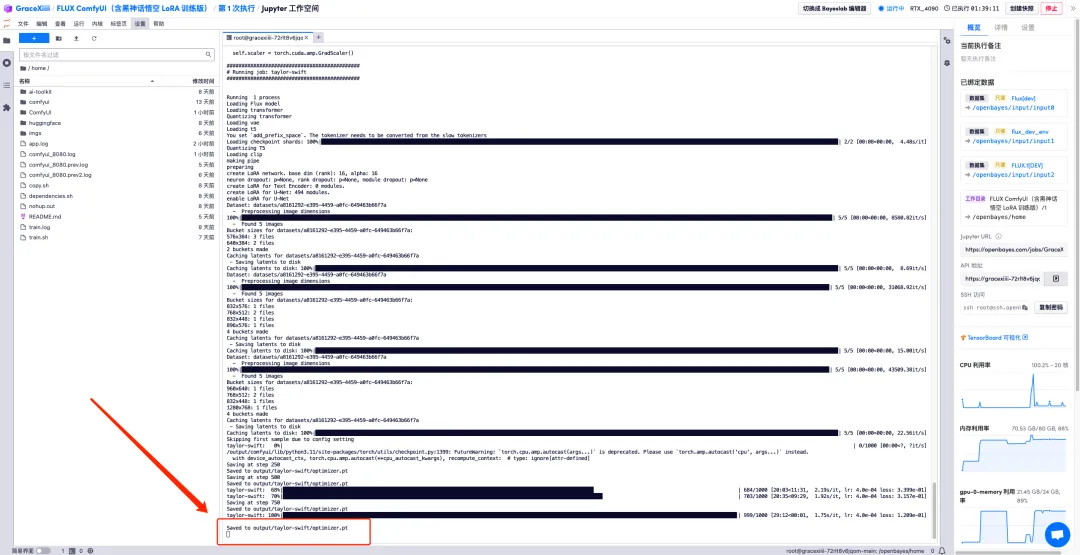
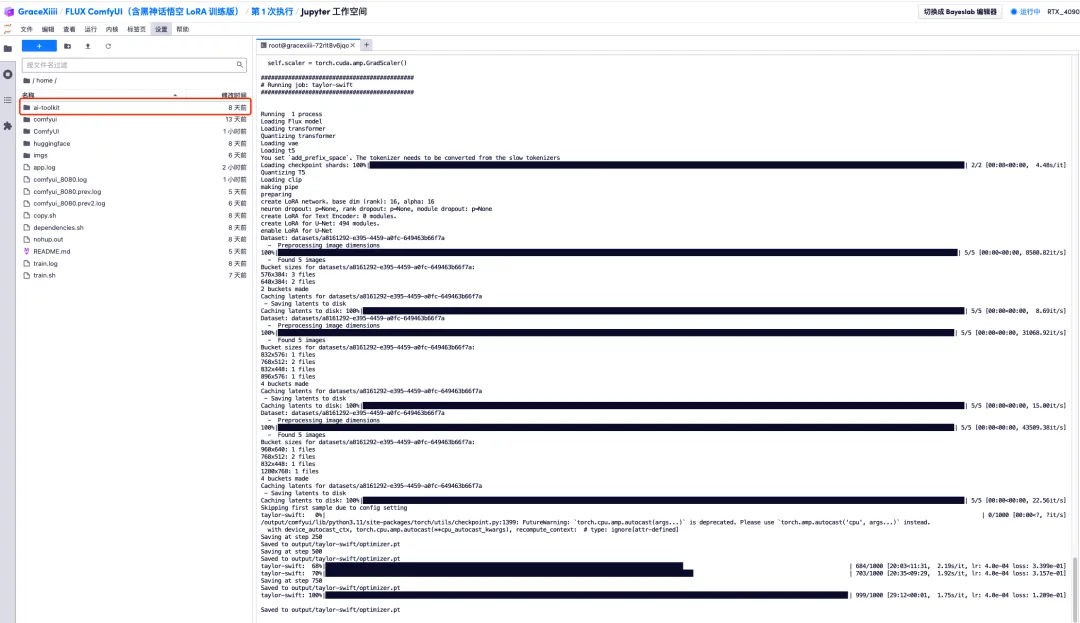
6. After waiting for a few minutes, we return to the terminal interface and can see the training progress bar. The training will be completed in about 40 minutes. When "Saved to output/taylor-swift/optimizer.pt" appears, it means that the training is complete.
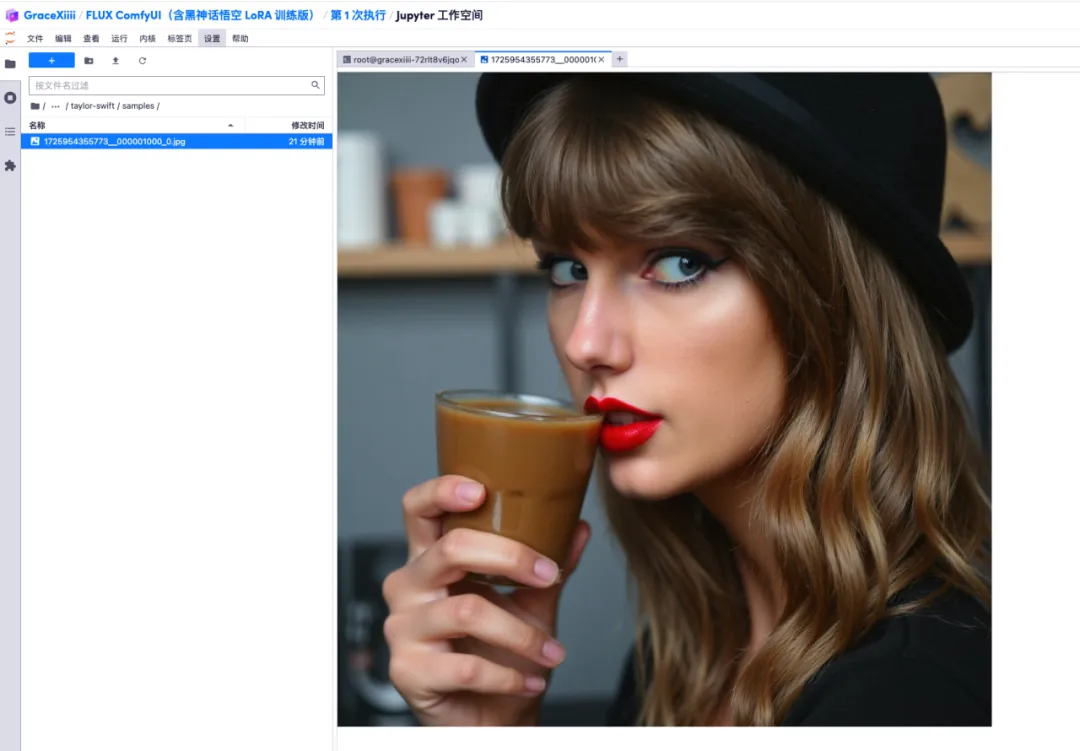
7. In the "ai-toolkit" - "output" - "taylor swift" - "sample" file on the left, you can see the effect of our Test Prompt. If the effect is good, it proves that our model has been trained successfully.
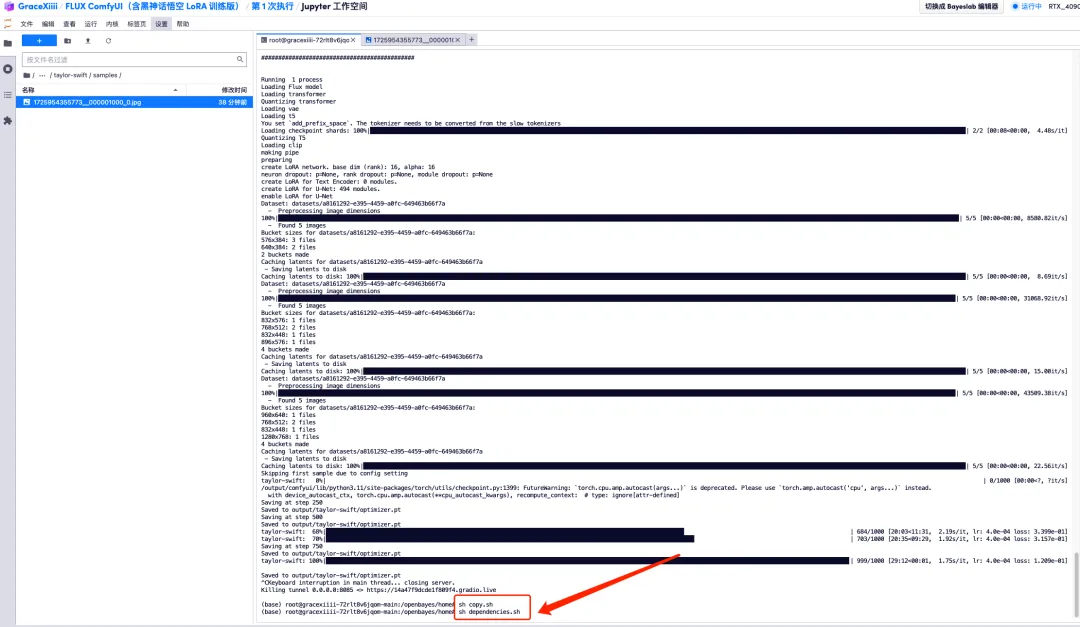
8. After the model is trained, we need to shut down the training service to release GPU resources, return to the key interface just now, and press "Ctrl+C" to terminate the training.
9. Run "sh copy.sh", then run "sh dependencies.sh" to start ComfyUI, wait for 2 minutes, and open the API address on the right.
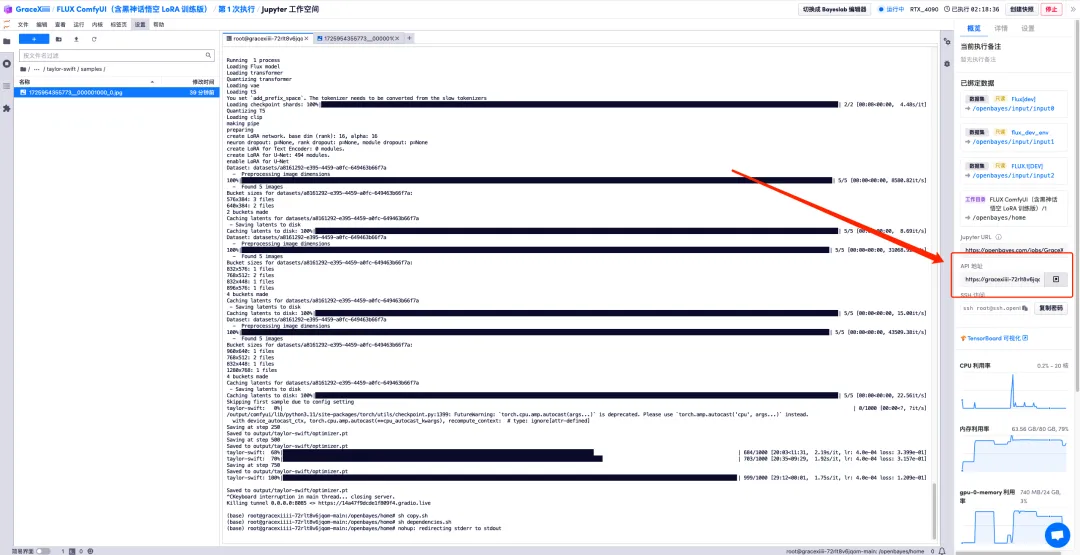
10. After the page jumps, select the trained model in "LoRA Loader", enter Prompt (for example: a person is drinking coffee) in "CLIP", and click "Add prompt word queue" to generate the image.