Command Palette
Search for a command to run...
A Stroke Left Her Speechless for 18 Years, AI + brain-computer Interface Helps Her “speak With Thoughts”

Zweig once said:The greatest luck in a person's life is to discover his mission in the middle of his life, when he is young and strong.
And what is man’s greatest misfortune?
In my opinion, the greatest misfortune in a person's life isNothing is worse than suddenly losing all ability to speak and move at the prime of life.——Overnight, dreams, careers, and wishes all turned into nothing, and life was turned upside down.
Ann is an unfortunate example.
30 years old, aphasia due to stroke
One day in 2005, Ann, who had always been in good health, suddenly developed symptoms such as dizziness, slurred speech, quadriplegia and muscle weakness. She was diagnosed withBrainstem infarction(What we call "stroke" in daily life),Accompanied by left vertebral artery dissection and basilar artery occlusion.
This unexpected stroke brought Ann aLocked-in syndromeA byproduct of this disease - people with this disease have all their senses and awareness, but cannot mobilize any muscle in the body. Patients can neither move nor speak independently, and some cannot even breathe.
As the word "locked" literally reflects, the body that takes ordinary people through thousands of mountains and rivers has become a cage that seals the patient's soul.
At that time, Ann was only 30 years old, had been married for 2 years and 2 months, her daughter was just 13 months old, and she was a math teacher in a high school in Canada. "Everything was taken away from me overnight." Ann later used the device to slowly type this sentence on the computer.

After years of physical therapy, Ann could breathe, move her head slightly, blink her eyes and speak a few words, but that was it.
You should know that in normal life, the average person's speaking speed is 160-200 words/minuteIn 2007, a study from the Department of Psychology at the University of Arizona showed that men say an average of 15,669 words, women say on average 16,215 words (on average one word corresponds to 1.5-2 Chinese characters).
In a world where language is the primary means of interpersonal communication, one can imagine how many of Ann’s needs, due to her limited expression, have been silenced.What is lost with aphasia is not only the quality of life, but also personality and identity.And how many paralyzed and aphasic people around the world are in the same situation as Ann?
Paralyzed for 18 years, he speaks again
Restoring the ability to communicate fully and naturally is the greatest desire of every person who has lost his or her speech due to paralysis.In today's highly developed technological world, is there any way to use the power of technology to restore the ability of interpersonal communication to patients?
have!
Recently, a research team from the University of California, San Francisco and the University of California, BerkeleyUsing AI to develop a new brain-computer technologyAnn, who had been speechless for 18 years, regained her "Speak", and generate vividFacial expressions, helping patients communicate with others in real time at a speed and quality consistent with normal social interaction.

This is the first time in human history that speech and facial expressions have been synthesized from brain signals!
Previous research by the UC team has shown that it is possible to decode language from the brain activity of paralyzed people, but only in the form of text output, with limited speed and vocabulary.
This time they want to go a step further:It enables faster large-vocabulary text communication while recovering the speech and facial movements associated with speaking.
Based on machine learning and brain-computer interface technology, the research team achieved the following results, published in Nature on August 23, 2023:
► Fortext, decoding the subjects' brain signals into text at a rate of 78 words per minute, with an average word error rate of 25%, which is more than 4 times faster than the communication device currently used by the subjects (14 words/minute);
►ForVoice Audio, rapidly synthesizing brain signals into understandable and personalized sounds that are consistent with the subject’s pre-injury voice;
►ForDigital facial avatar, achieving virtual facial motion control for speech and non-speech communication gestures.

Paper link:
https://www.nature.com/articles/s41586-023-06443-4
You must be curious.How was this epoch-making miracle achieved?Next, let’s break down this paper in detail and see how the researchers brought the virus back to life.
1. Underlying Logic Brain signals → speech + facial expressions
The human brain outputs information through peripheral nerves and muscle tissue, while language ability is generated by the cerebral cortex. "Language Center"controlled.
The reason why stroke patients suffer from aphasia is that blood circulation is obstructed and the language area of the brain is damaged due to lack of oxygen and important nutrients, resulting in one or more language communication mechanisms not being able to function properly, resulting in language dysfunction.
In response, a research team from the University of California, San Francisco and Berkeley designed a "Multimodal speech neural prosthesis", using a large-scale, high-density cortical electroencephalogram (ECoG) to decode the text and audio-visual speech output represented by the vocal tract distributed throughout the sensory cortex (SMC), that is, capturing brain signals at the source and "translating" them into corresponding text, speech and even facial expressions through technical means.
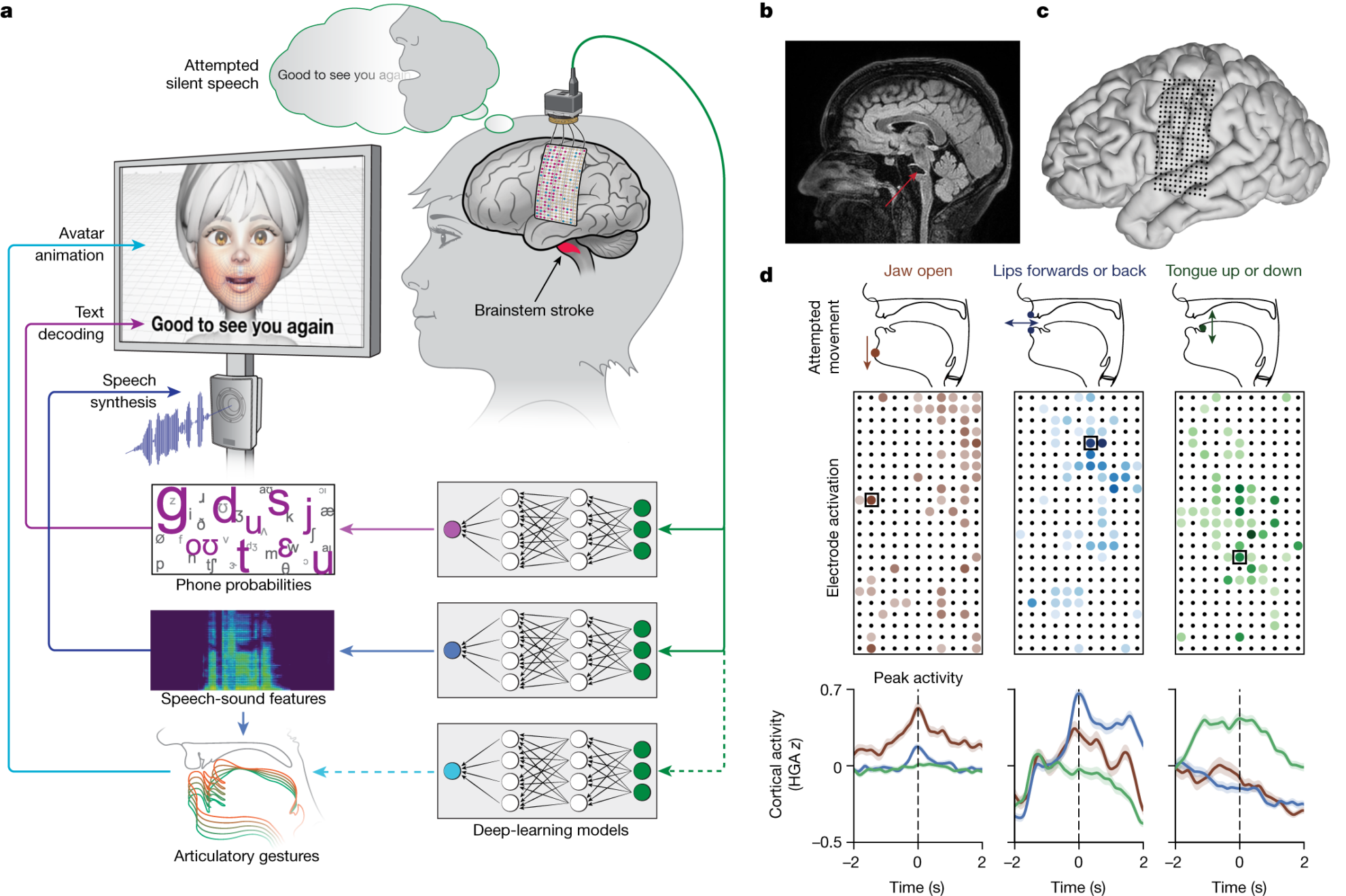
2. Process and Implementation Brain-computer interface + AI algorithm
The first is physical means.
The researchers implanted aHigh-density EEG arrayandTranscutaneous docking connector, covering areas related to speech production and speech perception.
The array consists of 253The disc-shaped electrodes intercept brain signals that would otherwise go to Ann's tongue, jaw, throat and facial muscles. A cable plugs into a port on Ann's head, connecting the electrodes to a set of computers.

The second is algorithm construction.
To identify Ann's unique brain speech signals,The research team spent several weeks working with her to train and evaluate the deep learning model.
The researchers created a set of 1,024-word common sentences based on the nltk Twitter corpus and the Cornell Film Corpus, and instructed Ann to speak silently at a natural pace. She silently recited different phrases from the 1,024-word conversational vocabulary over and over again.Until the computer recognizes the patterns of brain activity associated with those sounds.
It is worth noting that this model does not train AI to recognize entire words.Instead, a system was createdDecoding words from phonemesFor example, "Hello" contains four phonemes: "HH", "AH", "L" and "OW".
Based on this method, a computer only needs to learn 39 phonemes to decode any English word.It not only improves accuracy, but also increases speed by 3 times.
Note: Phoneme is the smallest sound unit of a language, which can describe the pronunciation characteristics of speech, including the place of articulation, pronunciation method and vocal cord vibration. For example, the phonemes of an are composed of /ə/ and /n/.
This process of phoneme decoding is similar to the process of babies learning to speak. According to the generally accepted view in the field of developmental linguistics, newborn babies can distinguish the phonemes in languages around the world. 800 indivualPhonemes. Preschool children may not understand the writing and meaning of words and sentences, but they can gradually learn to pronounce and understand language through the perception, distinction and imitation of phonemes.
Finally, there is speech and facial expression synthesis.
The foundation has been laid, and the next step is to show the voice and facial expressions.The researchersSpeech SynthesisandDigital Avatarto solve this problem.
Voice, the researchers developed a synthetic speech algorithm using recordings of Ann’s voice before her stroke to make the digital avatar sound as much like her as possible.
Facial expressions, Ann's digital avatar was created using software developed by Speech Graphics and appears as an animation of a female face on the screen.
The researchers customized the machine learning process.To tune the software to the signals Ann's brain sends when she tries to speak, thereby showing the jaw opening and closing, lips protruding and retracting, tongue moving up and down, and facial movements and gestures that express happiness, sadness, and surprise.

Future Outlook
"Our goal is to restore a complete, concrete form of communication," said Edward Chang, MD, chief of neurosurgery at UCSF., which is the most natural way for us to talk to others… The goal of combining audible speech with real-life avatars allows for the full manifestation of human language communication, which is far more than just language.
The next step for the research team isCreate a wireless version,Getting rid of the physical connection of brain-computer interface, enabling paralyzed people to use this technology to freely control their personal mobile phones and computers, which will have a profound impact on their independence and social interaction.
From voice assistants on mobile phones, electronic face-scanning payment to robotic arms in factories and sorting robots on production lines,AI is extending human limbs and senses, and gradually penetrating into every aspect of our production and life.
Researchers focus on the special group of paralyzed and aphasic people, using the power of AI to help them restore their natural communication ability, which is expected to promote contact between patients and their relatives and friends and expand their opportunities to regain interpersonal interaction.And finallyHigh patient quality of life.
We are excited about this achievement and look forward to hearing more good news about how AI benefits humanity.
Reference Links:
[1] https://www.sciencedaily.com/releases/2023/08/230823122530.htm
[2] http://mrw.so/6nWwSB








