Command Palette
Search for a command to run...
Download Meta's Largest Video Segmentation Dataset in One Click! Contains 50.9K real-world Videos, Covering 47 Countries

In April 2023, Meta released Segment Anything Model (SAM), claiming to be able to "segment everything". This innovative achievement that subverts traditional computer vision (CV) tasks has aroused widespread discussion in the industry and has been quickly applied to research in vertical fields such as medical image segmentation. Recently, SAM has been upgraded again.Meta open-sourced Segment Anything Model 2 (SAM 2), marking another epoch-making milestone in the field of computer vision.
From image segmentation to video segmentation,SAM 2 demonstrates superior performance in real-time cue segmentation.The model introduces the segmentation and tracking functions of images and videos into a unified model. It can accurately identify and segment any object in an image or video by simply inputting a prompt (click, box or mask) on the video frame. This unique zero-sample learning capability gives SAM 2 extremely high versatility.It shows great application potential in the fields of medicine, remote sensing, autonomous driving, robotics, camouflaged object detection, etc. Meta is confident: "We believe that our data, models, and insights will become an important milestone in video segmentation and related perception tasks!"
It is true. As soon as SAM 2 was launched, everyone couldn’t wait to use it, and the effect was unbelievable!

Less than two weeks after SAM 2 was open sourced, researchers from the University of Toronto used it on medical images and videos and published a paper!

Original paper:
https://arxiv.org/abs/2408.03322
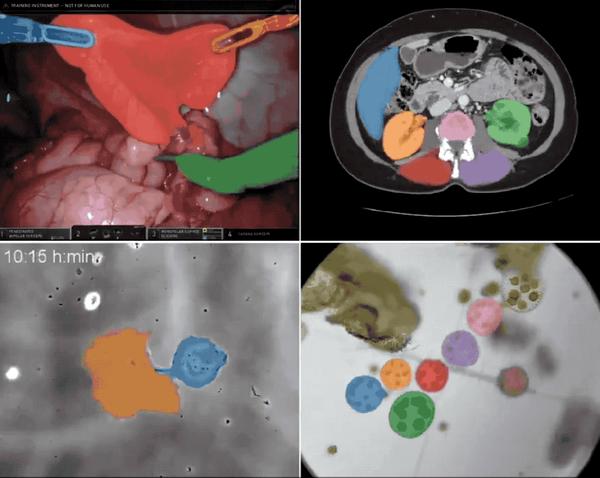
Models need data to train, and SAM 2 is no exception. At the same time, Meta also open-sourced the large-scale dataset SA-V used to train SAM 2.It is reported that this dataset can be used to train, test and evaluate generic object segmentation models.HyperAI has launched "SA-V: Meta Building the Largest Video Segmentation Dataset" on its official website, which can be downloaded with one click!
SA-V video segmentation dataset direct download:
https://go.hyper.ai/e1Tth
More high-quality datasets to download:
https://go.hyper.ai/P5Mtc
Beyond existing video segmentation datasets! SA-V covers multiple topics and multiple scenes
Meta researchers collected a large and diverse video segmentation dataset SA-V using Data Engine, as shown in the following table,The dataset contains 50.9K videos, 642.6K masklets (191K manually annotated with the assistance of SAM 2, 452K automatically generated by SAM 2),Compared with other common video object segmentation (VOS) datasets, SA-V has significantly improved the number of videos, masklets, and masks.The number of annotated masks is 53 times that of any existing VOS dataset.It provides a rich data resource for future computer vision work.
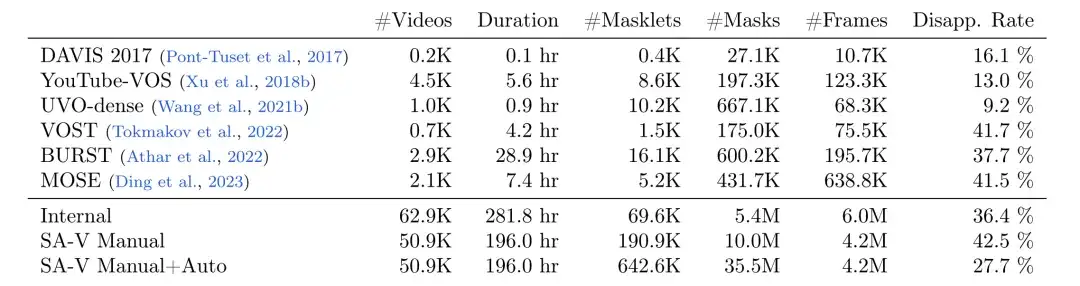
Comparison of the number of mask fragments, number of masks, number of frames, and disappearance rate
* SA-V Manual contains only manually annotated labels
* SA-V Manual+Auto combines manually annotated labels with automatically generated mask segments
It is understood that the number of videos contained in SA-V exceeds the existing VOS dataset, and the average video resolution is 1401×1037 pixels.The collected videos cover various daily scenes.Including 54% of indoor scene videos and 46% of outdoor scene videos, with an average duration of 14 seconds. In addition,The topics of these videos are also varied.Including locations, objects, scenes, etc., Masks range from large objects (such as buildings) to fine-grained details (such as interior decoration).
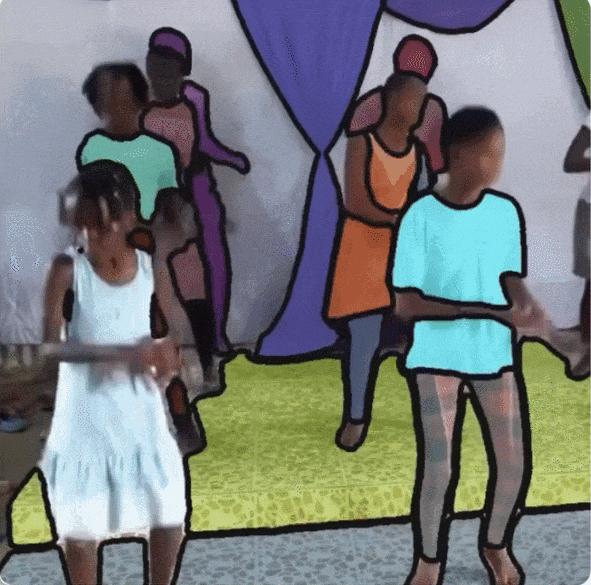
As shown in the figure below,The videos in SA-V cover 47 countries.And taken by different participants, Figure a shows that compared with the mask size distribution of DAVIS, MOSE and YouTubeVOS, the normalized mask area (normalized mask area) of SA-V less than 0.1 exceeds 88%.
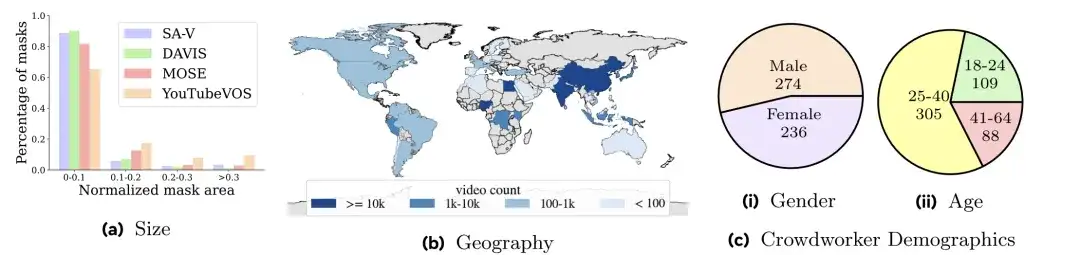
The researchers divided the SA-V dataset based on the video authors and their geographic locations.Ensure that similar objects in the data have minimal overlap.To create the SA-V validation set and SA-V test set, the researchers focused on challenging scenes when selecting videos, requiring annotators to identify targets that move quickly, are occluded by other objects, and have disappearance/reappearance patterns. In the end, there were 293 masklets and 155 videos in the SA-V validation set, and 278 masklets and 150 videos in the SA-V test set. In addition, the researchers used internally available licensed video data to further expand the training set.
SA-V video segmentation dataset direct download:
https://go.hyper.ai/e1Tth
The above are the datasets recommended by HyperAI in this issue. If you see high-quality dataset resources, you are welcome to leave a message or submit an article to tell us!
More high-quality datasets to download:
https://go.hyper.ai/P5Mtc








