Command Palette
Search for a command to run...
Llama 3.1 Chinese fine-tuning Dataset Is Now Online, and Large Models Can Be Deployed With One Click

The AI circle in July was really exciting, with small models followed by large models. Most students were able to experience small models such as GPT-4o and Mistral-Nemo, but large models such as Llama-3.1-405B and Mistral-Large-2 made many students feel troubled.
don’t worry!The hyper.ai official website provides tutorials in the tutorial section for starting these two super large models using "Open WebUI" and "OpenAI compatible API service"!In addition, the Chinese fine-tuning dataset DPO-zh-en-emoji is also online. Scroll down to get the link~
From August 5 to August 9, hyper.ai official website updates:
* High-quality tutorial selection: 5
* High-quality public datasets: 10
* Community article selection: 3 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in August: 2
Visit the official website:hyper.ai
Selected Public Tutorials
1. Use Open WebUI to deploy Mistral Large 2 / Llama 3.1 405B in one click
This tutorial uses OpenWebUI to deploy Mistral Large 2 / Llama 3.1 405B in one click. The relevant environment and configuration have been set up. You only need to clone and start the container to experience inference.
* Run Mistral Large 2 model deployment online:
* Run Llama 3.1 405B model deployment online:
2. One-click deployment of Mistral Large 2 / Llama 3.1 405B model OpenAI compatible API service
This tutorial is to deploy Mistral-Large-Instruct-2407-AWQ using the OpenAI compatible API. "OpenAI compatible API" means that third-party developers can use the same request and response format as OpenAI to integrate similar functions into their own applications. After starting this tutorial, you can connect to the model in any OpenAI compatible SDK. Compared with the previous tutorial, it is more complicated and suitable for those who have a programming foundation.
* Run Mistral Large 2 model deployment online:
* Run Llama 3.1 405B model deployment online:
3. Use Gibbs-Diffusion for blind image denoising
GDiff stands for Gibbs-Diffusion, which is a Bayesian blind denoising method that solves the problem of posterior sampling of signal and noise parameters. This tutorial is a test method built based on the paper "Listening to the Noise: Blind Denoising with Gibbs Diffusion". You can experience the research results by following the tutorial steps.
Run online:https://go.hyper.ai/y2wIU
Selected public datasets
1. DPO-zh-en-emoji Emoji Question Answering Dataset
This dataset is designed for fine-tuning large language models. It contains a large amount of question-answer pairs. Each question has two versions of the answer, Chinese and English. The answers also incorporate fun and humorous elements, including the use of emojis. The shareAI team has used it to fine-tune the Llama 3.1 8B model.
Direct use:https://go.hyper.ai/Y90pZ
2. UrbanSARFloods v1 Flood Mapping Benchmark Dataset
UrbanSARFloods is a dataset dedicated to urban and open area flood mapping, containing 8,879 512×512 image patches, covering 807,500 square kilometers, and covering 18 flood events. It solves the problem of insufficient attention paid to urban floods in existing large-scale SAR-derived flood mapping studies.
Direct use:https://go.hyper.ai/yOXx7
3. VRSBench Large-scale High-quality Remote Sensing Visual Language Benchmark Dataset
The dataset is a multi-purpose visual-language benchmark dataset designed for remote sensing image understanding. It contains 29,614 manually verified detailed captioned images, 52,472 object references, and 123,221 question-answer pairs. It aims to advance the development of general, large-scale remote sensing image visual-language models.
Direct use:https://go.hyper.ai/O7DtC
4. ATLAS High-resolution 3D Character Texture Dataset
The full name of this dataset is ArTicuLated humAn textureS (ATLAS for short). It is the largest high-resolution (1,024 × 1,024) 3D human texture dataset, containing 50,000 high-fidelity textures with text descriptions. The related paper results have been selected for ECCV 2024.
Direct use:https://go.hyper.ai/Zx1nj
5. MIND Microsoft News Dataset
MIND contains about 160,000 English news articles and more than 15 million impression logs generated by 1 million users, collected from anonymous behavior logs of the Microsoft News website. It is intended to serve as a benchmark dataset for news recommendation and to promote research in the field of news recommendation and recommendation systems.
Direct use:https://go.hyper.ai/lVOyX
6. BoWFire fire detection segmentation dataset
The BoWFire dataset is an image dataset specifically for flame detection, which aims to improve the accuracy of fire detection and reduce false alarms. The dataset includes fire images in various emergency situations, such as building fires, industrial fires, car accidents, and riots.
Direct use:https://go.hyper.ai/73AYY
7. CNN/DailyMail News Article Dataset
The dataset contains more than 300,000 news articles written by CNN and Daily Mail journalists, and is designed to help develop models that can summarize long paragraphs of text in one or two sentences.
Direct use:https://go.hyper.ai/AbidL
8. Doodle Dataset Doodle Image Dataset
The dataset contains more than 1 million images covering 340 graffiti categories, which can be processed for machine learning tasks.
Direct use:https://go.hyper.ai/Ns4M4
9. Yoga-16 Human Yoga Action Image Dataset
The Yoga-16 dataset is designed to improve the classification accuracy of yoga pose recognition models. It is divided into three main directories: training, testing, and validation, each of which contains 16 sub-directories corresponding to 16 different yoga poses.
Direct use:https://go.hyper.ai/iMe0Z
10. Human Images Dataset Male and female human image dataset
This dataset contains two person category image folders: male and female. The images include face, upper body and full body. It can be used for various projects such as gender recognition, human identity recognition and image classification.
Direct use:https://go.hyper.ai/6UJb7
For more public datasets, please visit:
https://hyper.ai/datasets
Community Articles
The second episode of the "Meet AI4S" series of live broadcasts invited Li Yuzhe, a postdoctoral fellow in Zhang Qiangfeng's laboratory at Tsinghua University. On August 21, Dr. Li Yuzhe will further share with everyone the AI methods in spatial transcriptomics and single-cell omics research in the form of an online live broadcast.
View event details:https://go.hyper.ai/GIzpo
Google Research and MIT jointly won the IJCAI 2024 Best Paper Award! Reply IJCAI 2024 to get the collection of IJCAI 2024 Best Paper Award, Outstanding Paper Award, AIJ Classic Paper Award and Outstanding Paper Award.
View the full report:https://go.hyper.ai/ZGzI2
Professor Huang Tianyin, Vice Provost and Director of the School of Medicine at Tsinghua University, Professor Sheng Bin, Department of Computer Science, School of Electrical Engineering, Shanghai Jiao Tong University/Key Laboratory of Artificial Intelligence, Ministry of Education, Professor Jia Weiping and Professor Li Huating, the Sixth People's Hospital Affiliated to Shanghai Jiao Tong University School of Medicine, and Professor Qin Yuzong, National University of Singapore and Singapore National Eye Center, worked together to successfully build the world's first integrated vision-large language model system DeepDR-LLM for diabetes diagnosis and treatment. This article is a detailed interpretation and sharing of the research.
View the full report:https://go.hyper.ai/qnzSp
Popular Encyclopedia Articles
1. Intersection over Union (IoU)
2. Reciprocal sorting fusion RRF
3. Contrastive Learning
4. Large-scale Multi-task Language Understanding (MMLU)
5. Long and short-term memory Long Short-Term Memory
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
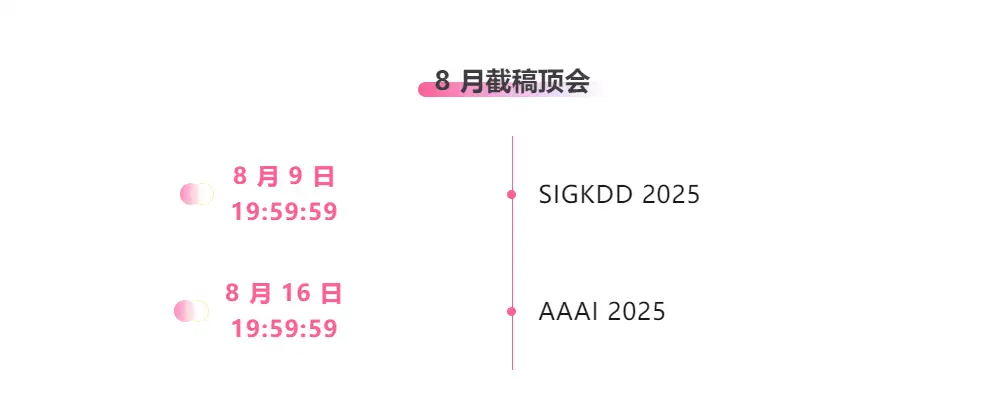
One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provide domestic accelerated download nodes for 1300+ public data sets
* Includes 400+ classic and popular online tutorials
* Interpretation of 100+ AI4Science paper cases
* Support 500+ related terms search
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey:








