Command Palette
Search for a command to run...
Online Tutorial: Deploy Large Models Without Any Pressure! Run Llama 3.1 405B and Mistral Large 2 With One Click

On July 23rd local time, Meta officially released Llama 3.1. The oversized 405B parameter version strongly opened the highlight moment of the open source model. In multiple benchmark tests, its performance caught up with or even surpassed the existing SOTA models GPT-4o and Claude 3.5 Sonnet.
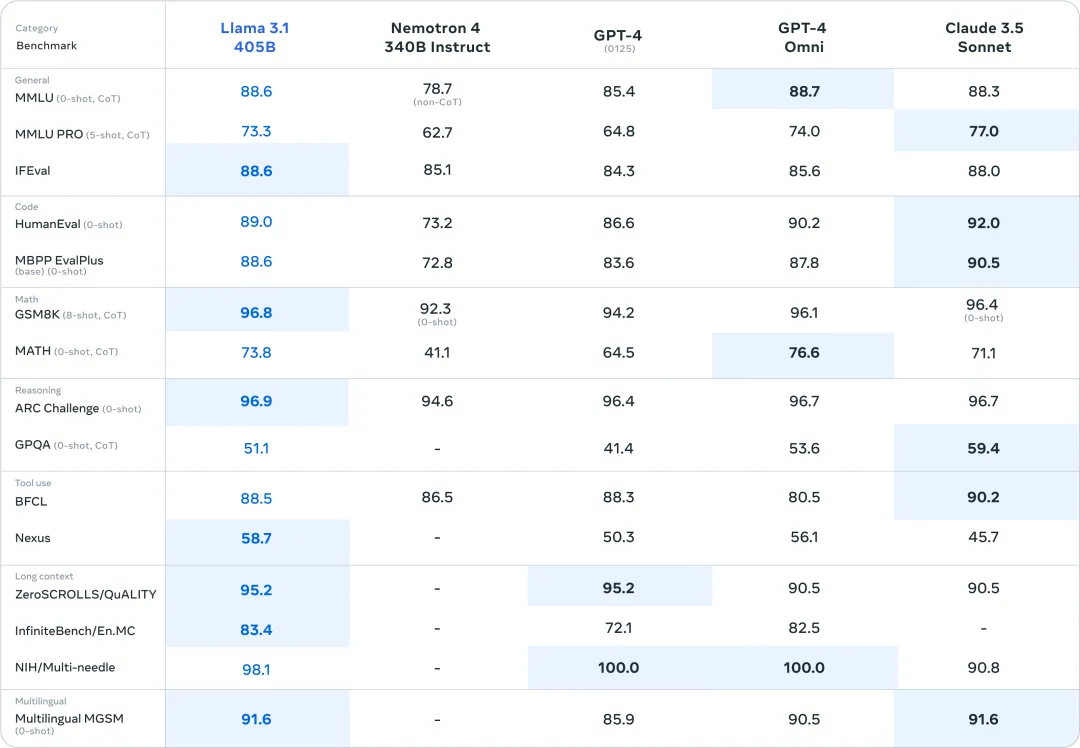
Zuckerberg also wrote a long article titled "Open Source AI is the Way Forward" on the day of Llama 3.1's release, saying that Llama 3.1 will be a turning point for the industry. At the same time, the industry is eager to try out the powerful capabilities of Llama 3.1, and is also looking forward to how closed-source big models will respond.
Interestingly, just as Llama 3.1 was vying for the throne, Mistral AI launched Mistral Large 2 to directly confront the 405B model, which is difficult to deploy.
Undoubtedly, the hardware capabilities required for the 405B parameter scale are not a threshold that individual developers can easily cross, and most enthusiasts can only look on with daunting eyes. The Mistral Large 2 model has only 123B parameters, less than one-third of the Llama 3.1 405B, and the deployment threshold is also lowered, but the performance can "compete" with Llama 3.1.
For example, in the MultiPL-E multiple programming language benchmark, Mistral Large 2's average score surpassed Llama 3.1 405B, and was 1% behind GPT-4o, and surpassed Llama 3.1 405B in Python, C++, Java, etc. As its official statement, Mistral Large 2 has opened up a new frontier in performance/service cost of evaluation indicators.
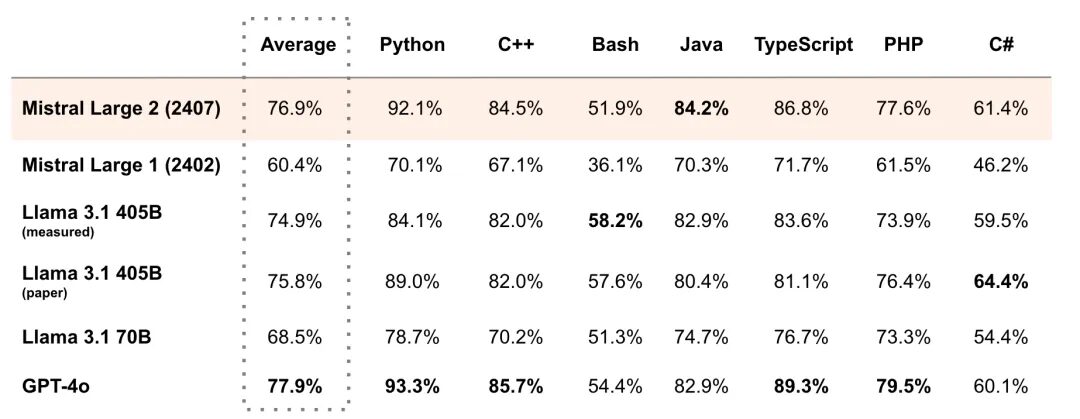
On one hand, there is the current "ceiling" of the open source model parameter scale, and on the other hand, there is the leader of the new era of open source with super high "cost-effectiveness". I believe that everyone does not want to miss it! Don't worry, HyperAI Super Neural has launched a one-click deployment tutorial for Llama 3.1 405B and Mistral Large 2407. You don't need to enter any commands, just click "Clone" to experience it.
* Use Open WebUI to deploy the Llama 3.1 405B model in one click:
* Use Open WebUI to deploy Mistral Large 2407 123B in one click:
At the same time, we have also prepared advanced tutorials, you can choose as needed:
* One-click deployment of Llama 3.1 405B model OpenAI compatible API service:
* One-click deployment of Mistral Large 2407 123B model OpenAI compatible API service:
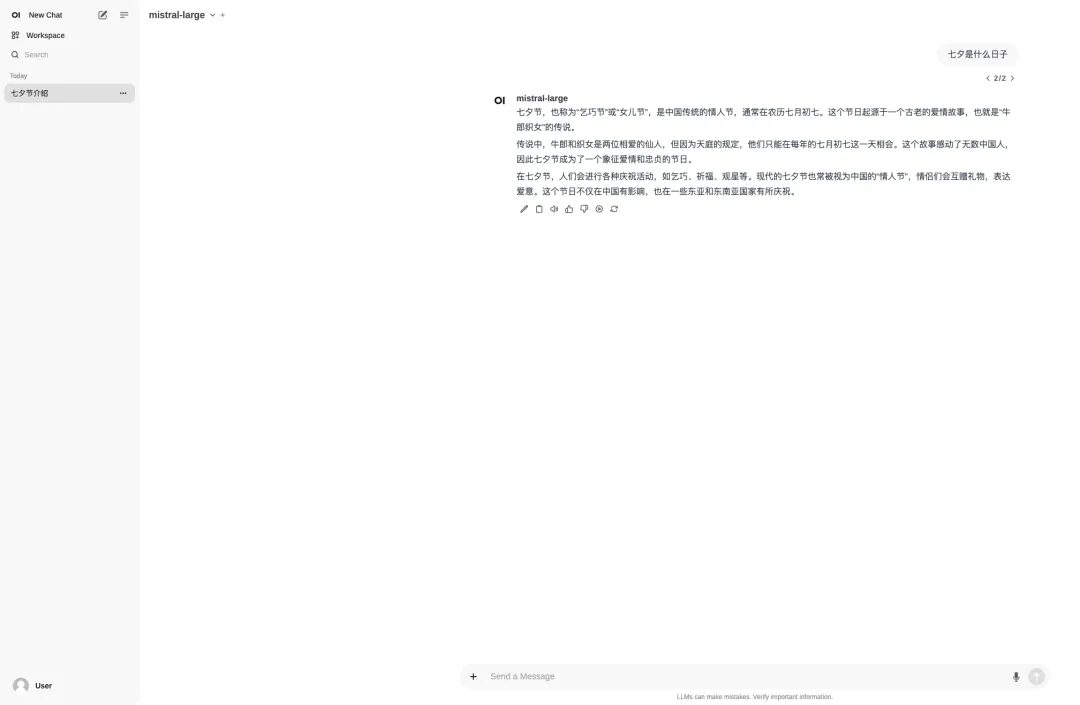
I used Open WebUI to deploy Mistral Large 2407 123B with one click and conducted a test. The large models frequently failed to meet the "9.9 or 9.11 which is bigger" problem, and Mistral Large 2 was not immune to this problem:

Interested friends, come and experience it, the detailed tutorial is as follows⬇️
Demo Run
This text tutorial will take "Use Open WebUI to deploy Mistral Large 2407 123B in one click" and "Deploy Llama 3.1 405B model OpenAI compatible API service in one click" as examples to break down the operation steps for you.
Use Open WebUI to deploy Mistral Large 2407 123B in one click
1. Log in to hyper.ai, on the Tutorial page, select Deploy Mistral Large 2407 123B with Open WebUI, and click Run this tutorial online.
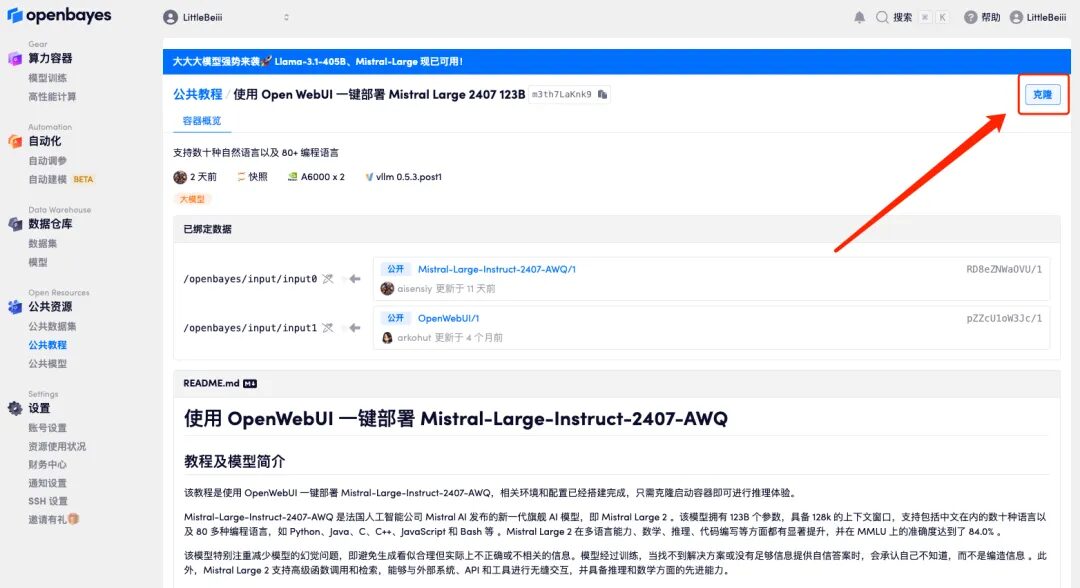
2. After the page jumps, click "Clone" in the upper right corner to clone the tutorial into your own container.
3. Click "Next: Select Hashrate" in the lower right corner.
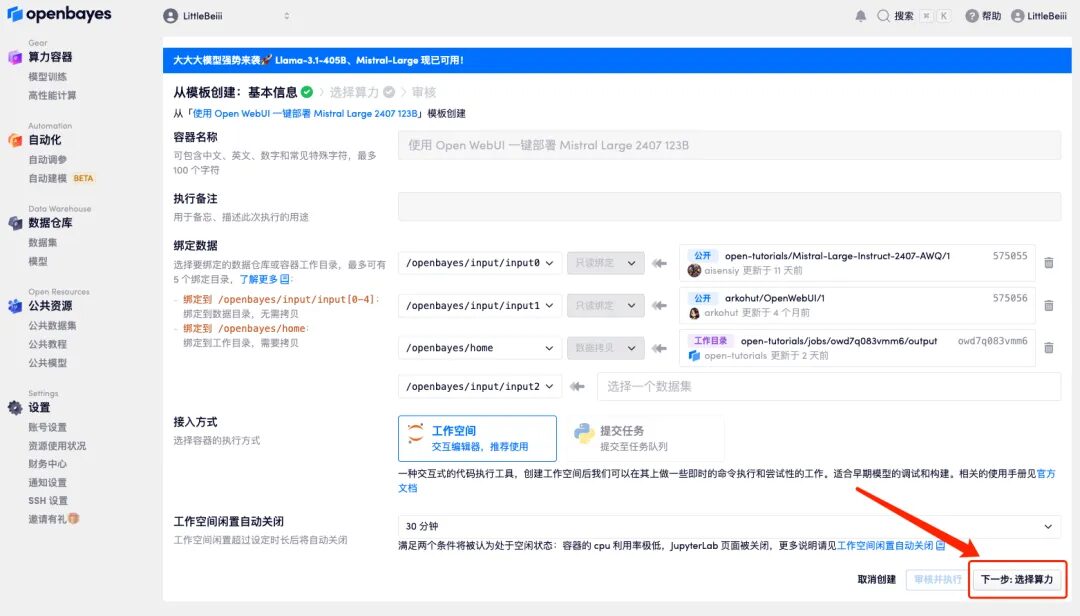
4. After the page jumps, select "NVIDIA RTX A6000-2" and "vllm" image, and click "Next: Review".New users can register using the invitation link below to get 4 hours of RTX 4090 + 5 hours of CPU free time!
HyperAI exclusive invitation link (copy and open in browser):
https://openbayes.com/console/signup?r=6bJ0ljLFsFh_Vvej
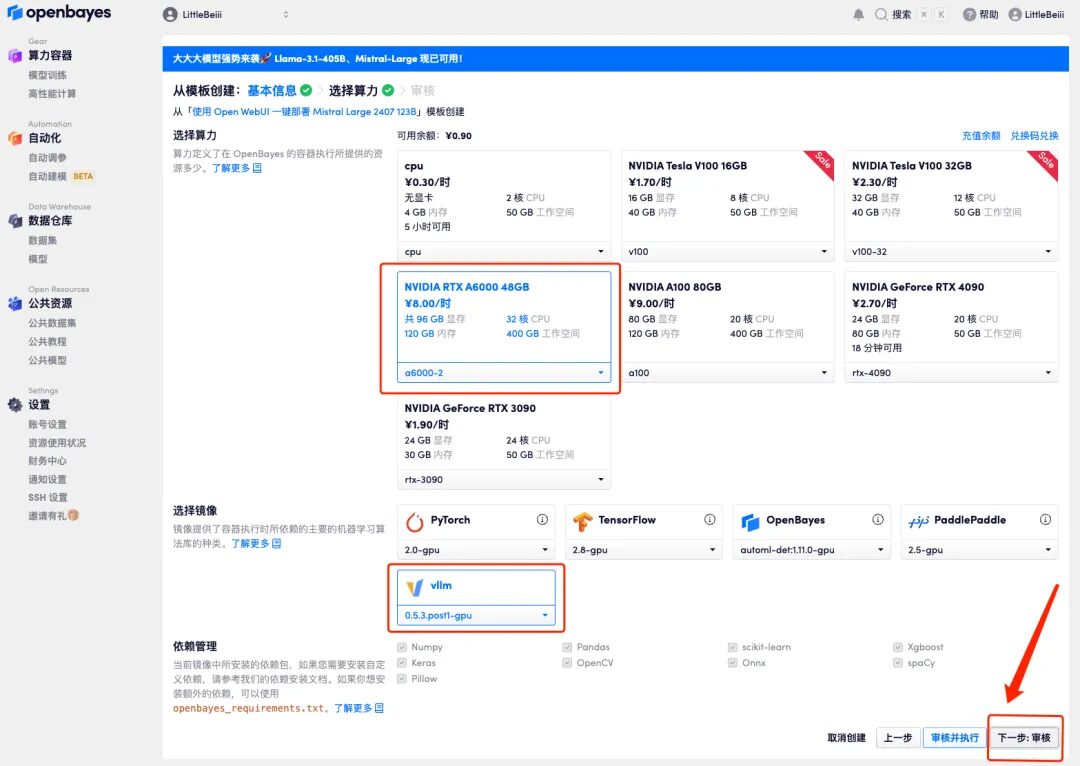
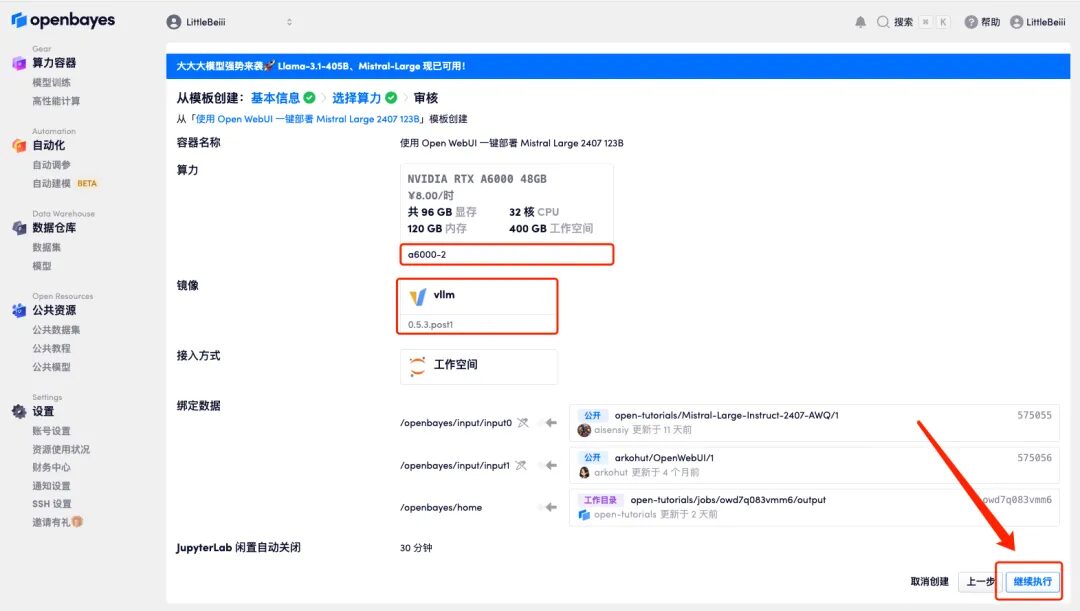
5. After confirmation, click "Continue" and wait for resources to be allocated. The first cloning takes about 2 minutes. When the status changes to "Running", click the jump arrow next to "API Address" to jump to the Demo page.Please note that users must complete real-name authentication before using the API address access function.
If the issue persists for more than 10 minutes and remains in the "Allocating resources" state, try stopping and restarting the container. If restarting still does not resolve the issue, please contact the platform customer service on the official website.
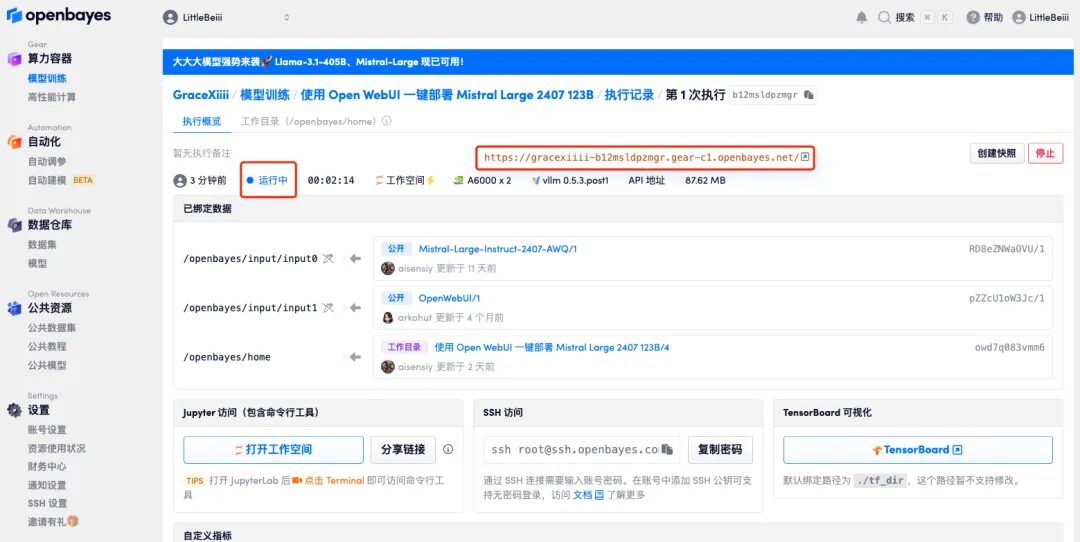
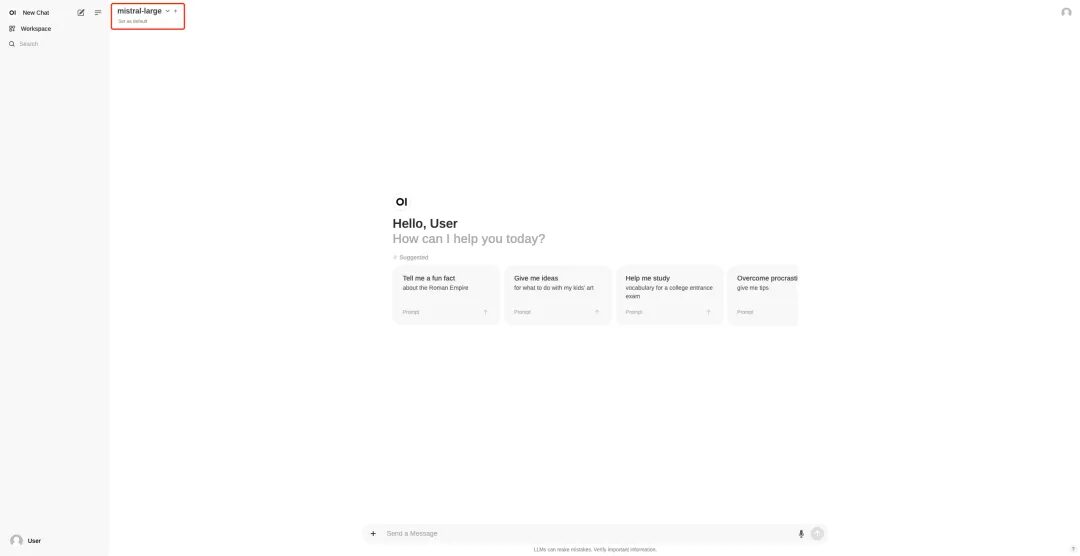
6. After opening the Demo, you can start the conversation immediately.
One-click deployment of Llama 3.1 405B model OpenAI compatible API service
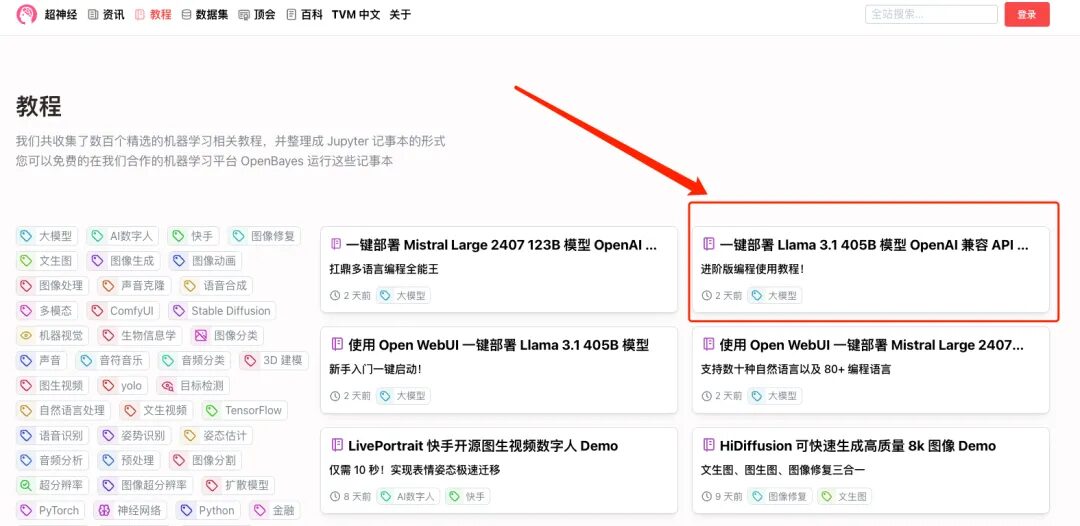
1. If you want to deploy OpenAI compatible API service, select "One-click deployment of Llama 3.1 405B model OpenAI compatible API service" on the tutorial interface. Similarly, click "Run tutorial online"
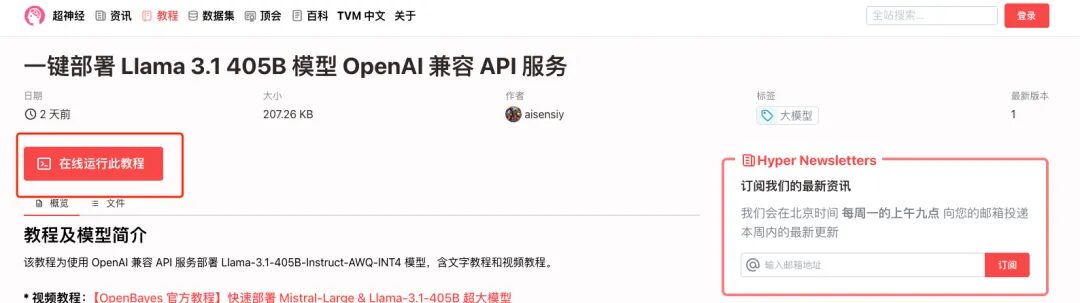
2. After the page jumps, click "Clone" in the upper right corner to clone the tutorial into your own container.
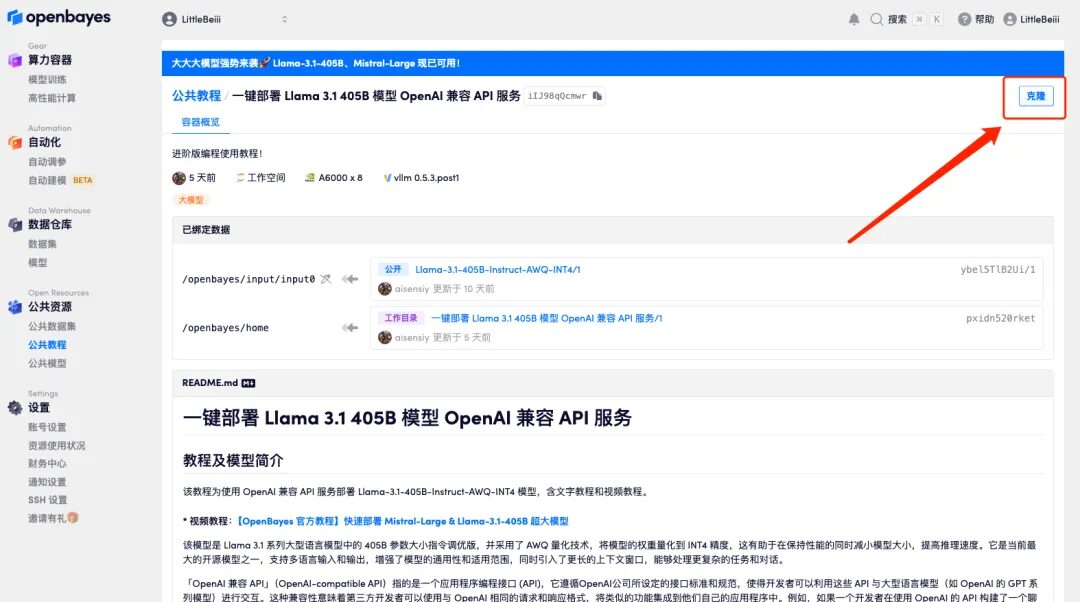
3. Click "Next: Select Hashrate" in the lower right corner.
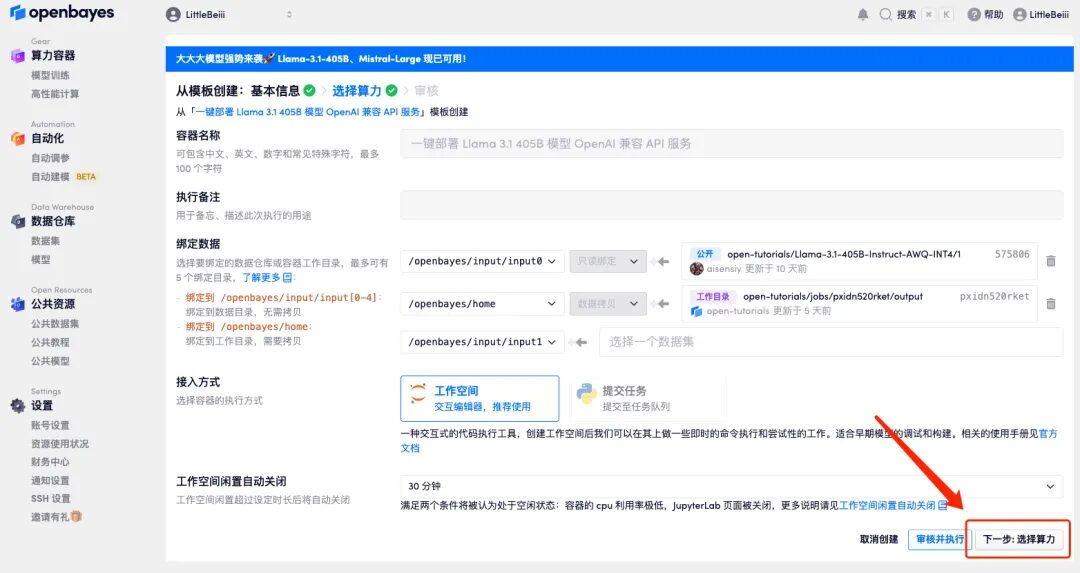
4. After the page jumps, because the model is large, the computing resource needs to select "NVIDIA RTX A6000-8", and the image still selects "vllm". Click "Next: Review".
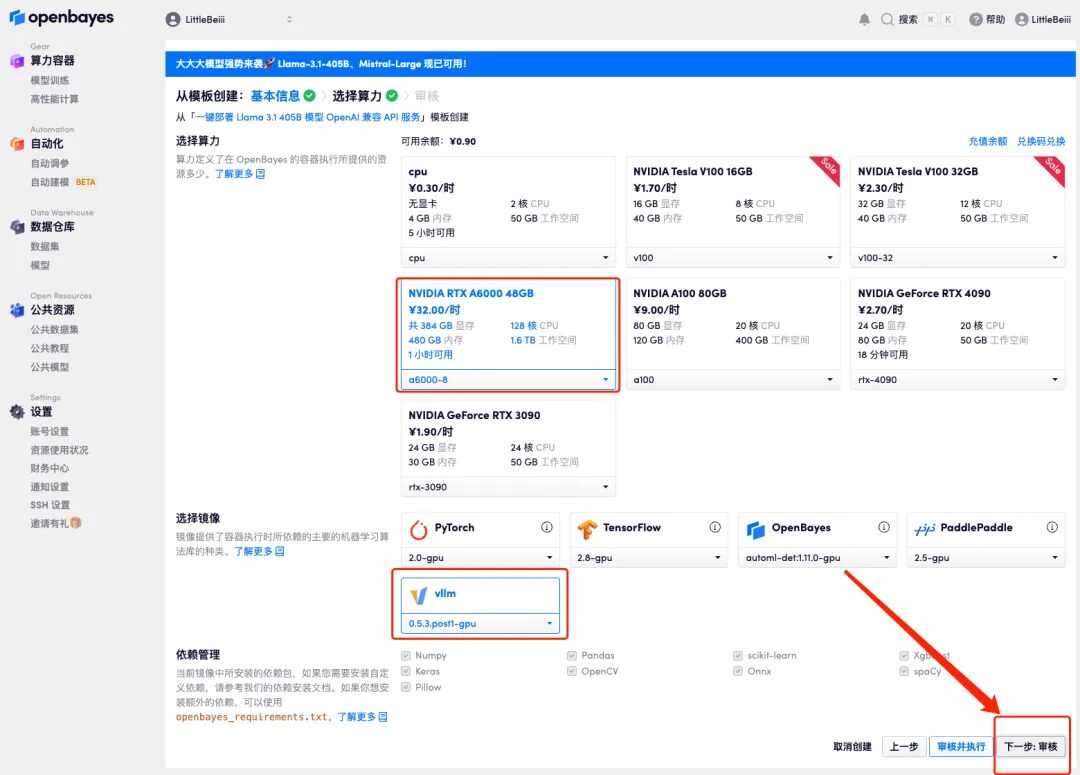
5. After confirmation, click "Continue" and wait for resources to be allocated. The first cloning takes about 6 minutes. When the status shows "Running", the model will automatically start loading.
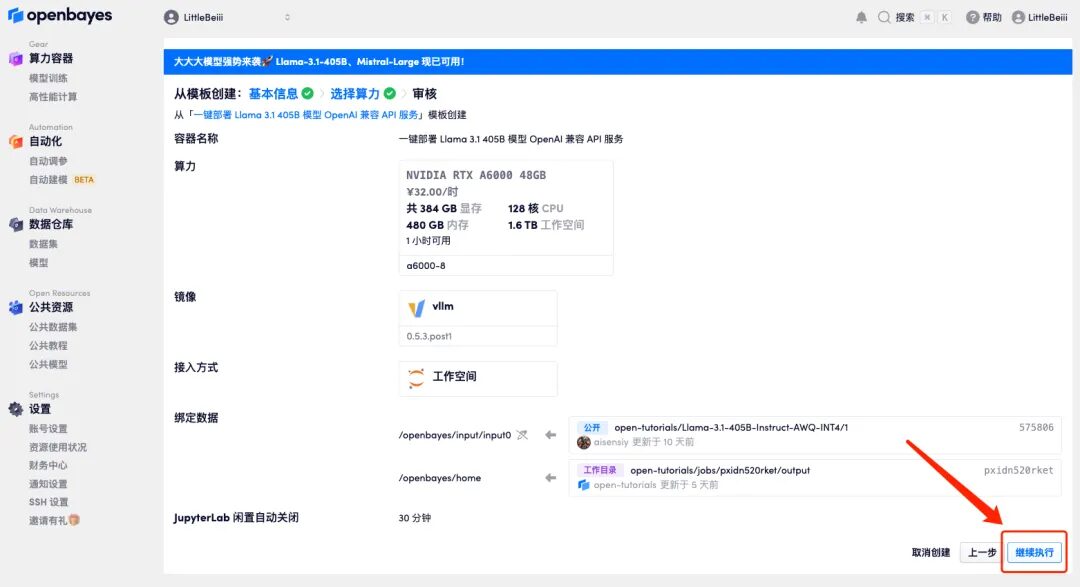
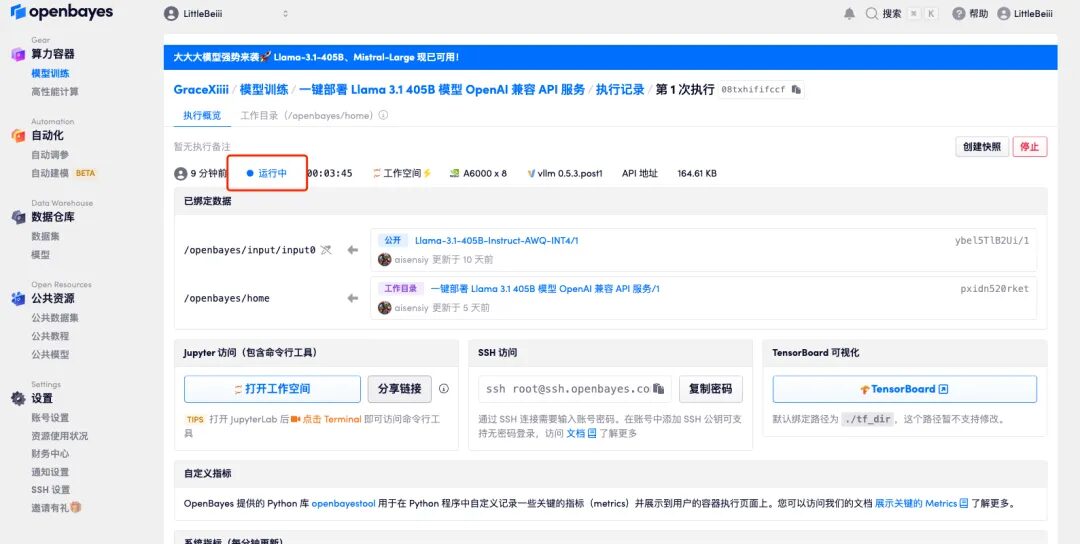
6. Scroll to the bottom of the page. When the log shows the following routing information, it means the service has been started successfully. Open the API address.
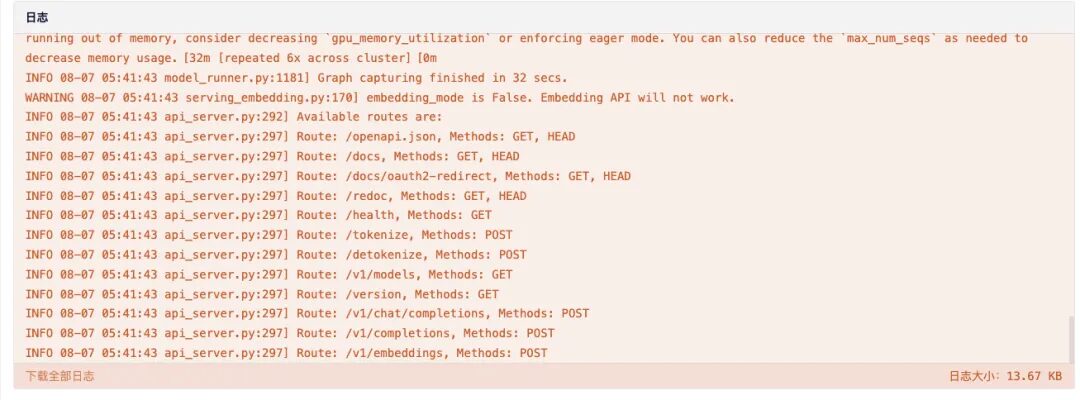
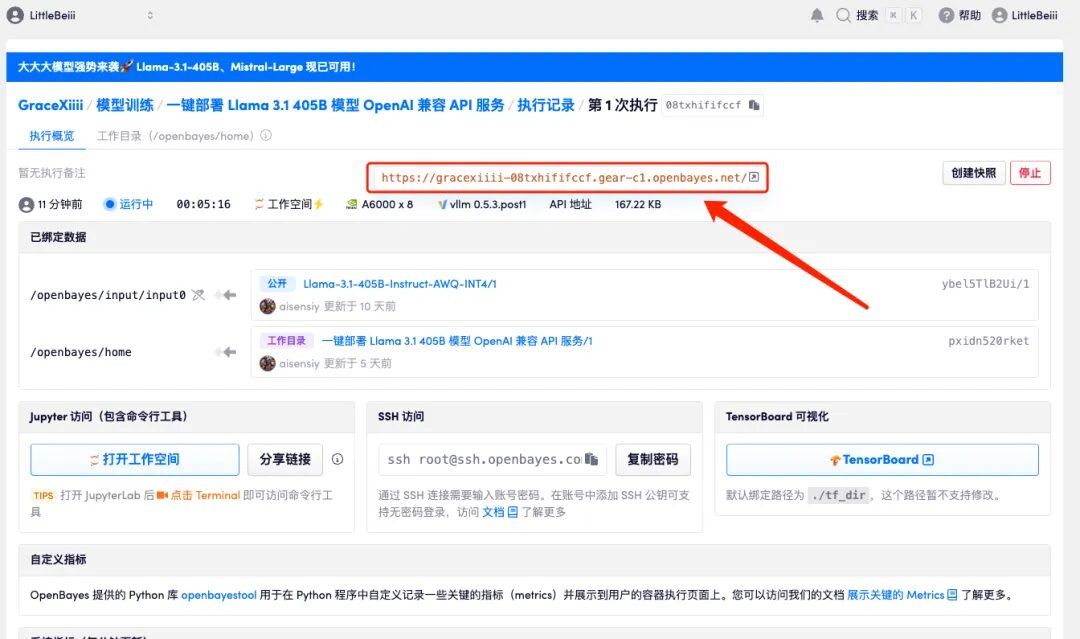
7. After opening, the 404 information will be displayed by default. Adding an additional parameter "/v1/models" in the red box will display the deployment information of the current model.




8. Start an Open WebUI service locally, start an additional connection in "External Connections", fill in the previous API address in "OpenAPI" and ➕ "/v1", and there is no "API key" set here. Click Save in the lower right corner.
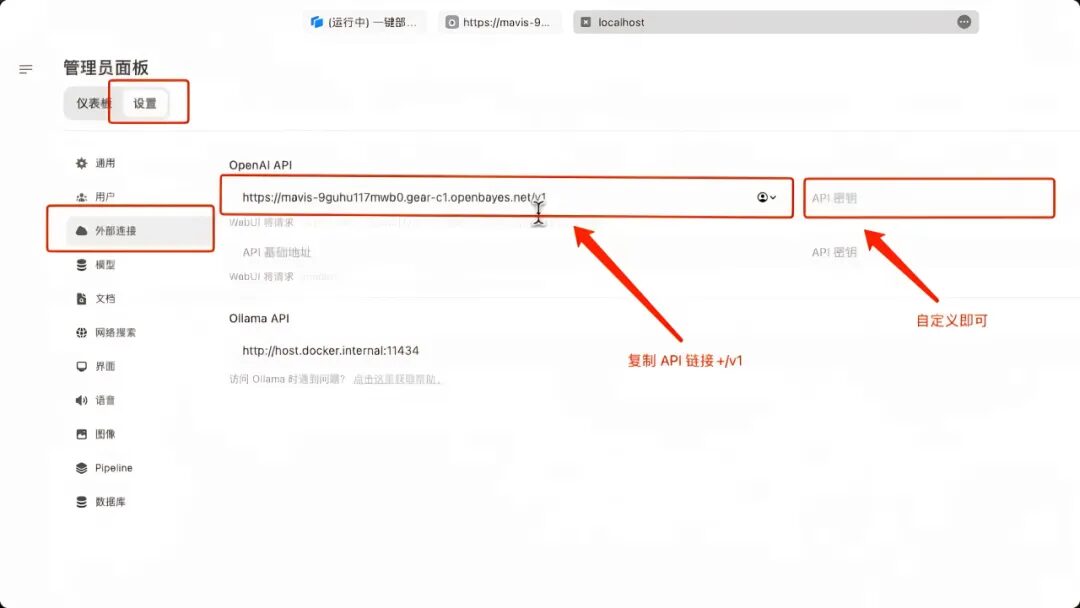
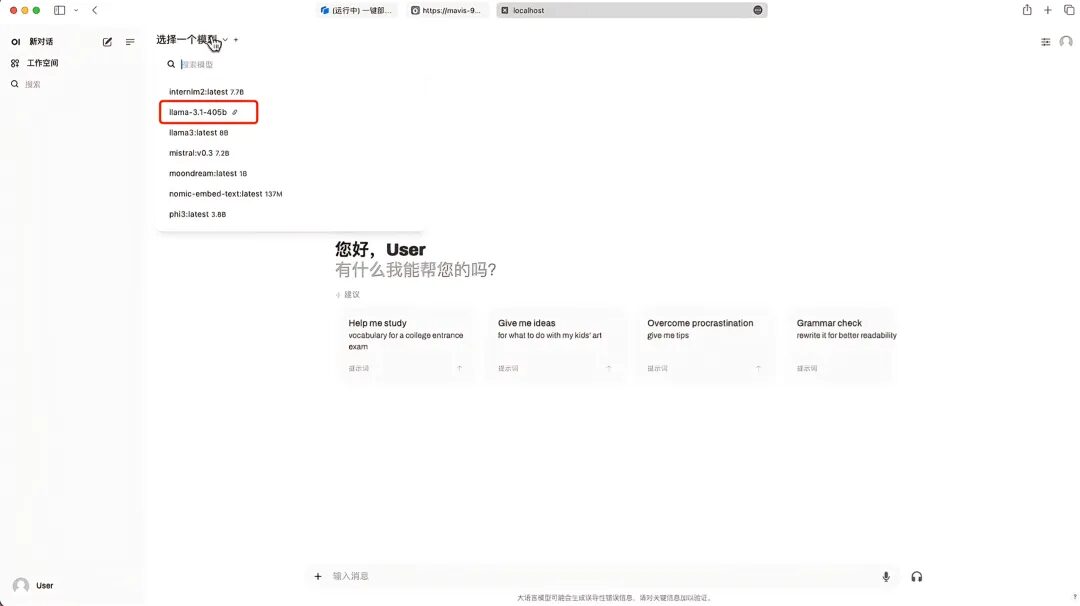
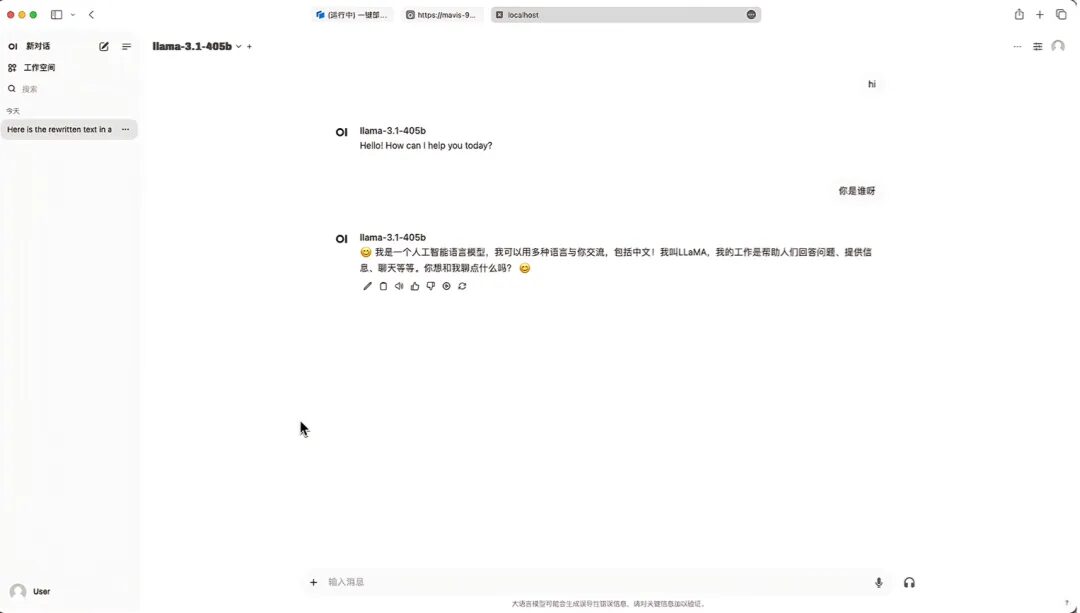
9. After saving, you can see Llama-3.1-405B appearing in "Select Model". After selecting the model, you can start the conversation!
Finally, I recommend an online academic sharing activity. Interested friends can scan the QR code to participate!









