Command Palette
Search for a command to run...
Selected for ACL 2024! Introducing zero-shot Learning, Huazhong University of Science and Technology Released a Conditional Diffusion Model Optimized for Oracle Bone Inscriptions Deciphering

Writing is a symbol of civilization and the most significant mark of a nation. Oracle bone script (OBS), as the earliest known and systematic writing system in my country, carries the culture and civilization of the Chinese nation. Since 1899, when a scholar accidentally discovered a tortoise shell with oracle bone script in a Chinese medicine shop, the study of oracle bone script has become a hot topic in the academic community.
In all the research on oracle bone inscriptions, identification and interpretation are the most core issues. However, among the more than 4,500 oracle bone inscriptions discovered so far, there are still about 3,000 characters that have not been identified, and oracle bone inscription research has entered a bottleneck period that is difficult to break through.
With the rise of AI technology, using modern technology to understand this ancient language provides researchers with a new way of thinking. However, previous research methods were mainly based on the knowledge and understanding of the deciphered oracle bone inscriptions.How to use AI to assist in deciphering unknown words with multiple problems such as non-digital text, severely damaged samples, missing corpus, etc.It is still a new area to be explored.
In response to this, the research team of Bai Xiang and Liu Yuliang from Huazhong University of Science and Technology, together with the University of Adelaide, Anyang Normal University, and South China University of Technology, used an image-based generative model toA conditional diffusion model Oracle Bone Script Decipher (OBSD) optimized for oracle bone script deciphering was trained.The model uses unseen categories of oracle bone inscriptions as conditional input to generate corresponding modern Chinese character images, providing a novel approach to the ancient character recognition task that is difficult to solve in natural language processing.
The related research, titled "Deciphering Oracle Bone Language with Diffusion Models", has been accepted by the ACL 2024 main conference.
Research highlights:
* Providing a novel approach to ancient text recognition tasks by using image generation technology
* OBSD uses local analysis sampling technology to enhance the model's ability to distinguish and interpret complex character patterns
* Demonstrate the effectiveness of OSBD in decoding through comprehensive ablation studies and benchmark tests

Paper address:
https://doi.org/10.48550/arXiv.2406.00684
The open source project "awesome-ai4s" brings together more than 100 AI4S paper interpretations and provides massive data sets and tools:
https://github.com/hyperai/awesome-ai4s
Dataset: Using Oracle's largest repository, using OCR technology as the benchmark
To train and evaluate the proposed OSBD model,This study selected the HUST-OBS dataset and the EVOBC dataset.They are one of the largest repositories of oracle bone inscriptions, containing 1,590 different characters depicted in 71,698 images.
Considering that deciphering unknown oracle bone inscriptions usually requires more comprehensive professional verification, this study only uses the deciphered texts as the test set, thus simplifying the entire evaluation process. More importantly, the study also specifically excludes the character categories selected in the test set from the training set to ensure that the model is used to decipher characters that have never been processed. The dataset is divided into training and test sets in a ratio of 9:1, providing a reliable framework for evaluation.
In addition, although the OSBD model deciphers oracle bone inscriptions from the perspective of image generation, traditional image generation metrics such as SSIM are not suitable for this task. Therefore, this study uses OCR technology as a more objective measure of the success of deciphering results. Specifically, the researchers customized the OBS-OCR tool by using a simple classifier with the ResNet-101 backbone network, and trained it specifically on a large dataset containing 88,899 modern Chinese character categories to evaluate the output of the model.
The results show that The customized OCR tool achieved a recognition accuracy of 99.87%.The reliability of the deciphering results was proved. At the same time, the study also widely introduced the open source Chinese OCR tool PaddleOCR 1 for further evaluation. This dual OCR method provides a strong guarantee for the effectiveness of the model in deciphering oracle bone inscriptions.
Reconstruct the OBSD model based on the conditional diffusion model
This study represents the training set as S = {(si, ci) | si is an oracle instance, ci∈C}, that is, the oracle instances are matched with a set of modern Chinese characters in a known category C, and new character forms are proposed where existing matches are missing. To achieve this,This study converts the oracle bone character image X into its modern Chinese equivalent based on the diffusion model.
As shown in the figure below, the model is divided into two stages:
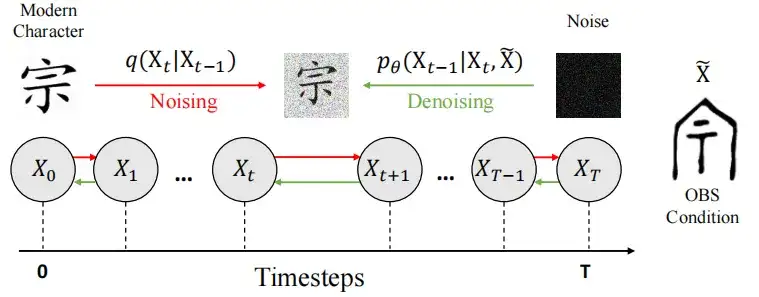
In the early stage (Noising),The researchers introduced noise into the modern Chinese character image X0 and used a controllable Markov chain process to transition it to a state similar to pure noise, ultimately forming a Gaussian distribution N (0, I).
In the denoising stage,The researchers used the U-Net architecture to train the model fθ to predict noise e and restore the image, and used et ∼ N(0, I) to introduce randomness to enhance the diversity of the model's generation results. The final decoding result is the generated denoised image X0.
On this basis, the OBSD model integrates the initial decipherment stage and the zero-shot refinement stage to improve the decryption accuracy, as shown in the figure below.
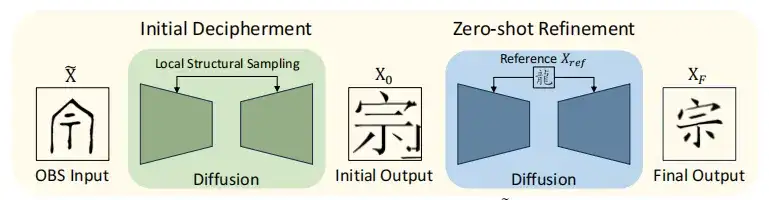
First, the oracle bone image X is conditionally diffused to approximate the initial image X0, and then it is improved by zero-shot learning method, and Xref is used as a reference to correct and enhance the structure. Benefiting from the insight into the text structure during the improvement process, the text result XF corresponding to modern Chinese characters is finally generated.
Introducing the LSS concept to enhance the model's ability to connect ancient Chinese characters with modern Chinese characters
However, in actual application cases, the model trained in this way cannot accurately generate the corresponding modern Chinese characters, but instead forms some nonsense based on a large number of random fragments, as shown in the figure below.

The researchers speculated that the reason for this result is that the diffusion model is mainly designed to generate natural images, but in the process of deciphering oracle bone inscriptions, there are great differences in the structure between oracle bone inscriptions and modern Chinese characters.This makes it impossible for the standard conditional diffusion model to accurately reconstruct the target modern Chinese characters.
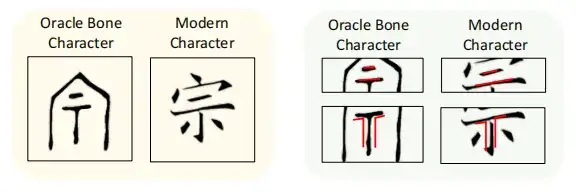
To address this challenge,This study introduced the concept of Local Structure Sampling (LSS).The help diffusion model learns how to map the local radical structure of oracle bone script to the corresponding modern Chinese characters, thereby enhancing the model's ability to connect ancient characters with modern Chinese characters. The study also found that although there is considerable structural evolution from ancient Chinese characters to modern Chinese characters, some local structures have been preserved.
In order to enable the diffusion model to learn the characteristics of local structure, the LSS module uses a sliding window method to split the target modern Chinese character image X0∈RHxWx3 and the corresponding oracle bone image X∈RHxWx3 into D small blocks of size p×p, denoted as X(d) and Xt(D)∈Rp×p×3, D=1,2…D, p=64. Here, Xt represents a modern text image with Gaussian noise ϵt added at time step t.
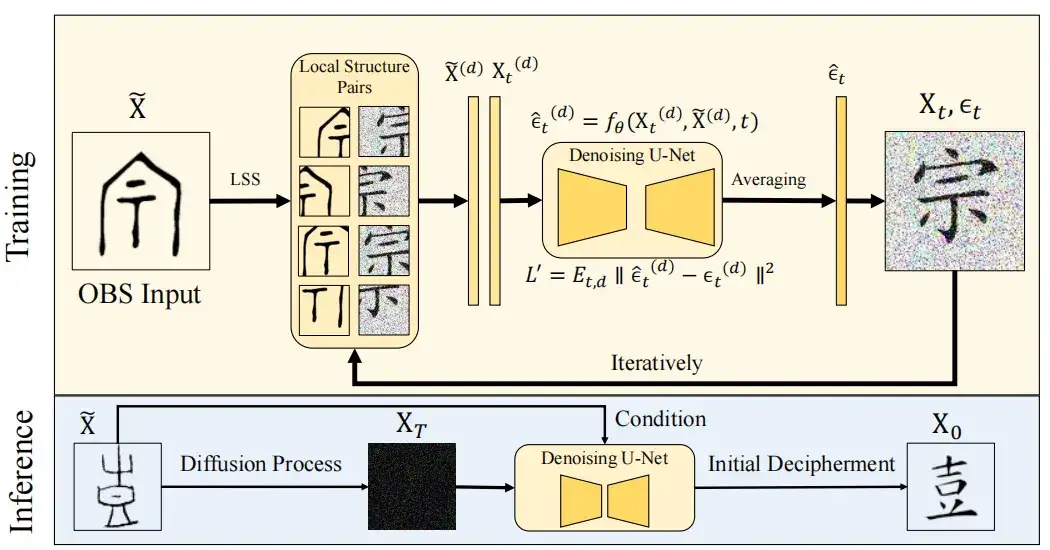
Based on this method,The model can iterate and optimize patches by learning the local structure of oracle bone inscriptions and subtle differences in the structure of Chinese characters.The uniqueness of this research method is that it averages the overlap between adjacent regions at each time step t without completing denoising to ensure a uniform effect in the shared area. At the same time, this research avoids edge differences and maintains the visual consistency of the reconstructed image by smoothing the regional transitions during sampling.
Introducing zero-shot learning methods to enhance the model’s ability to understand character structure
Although some progress has been made in generating modern Chinese characters using local structure sampling, initial deciphering efforts still encounter obvious obstacles such as structural deformation and artifacts.

This is due to the many-to-one training method used, which maps multiple oracle bone inscriptions to one modern Chinese character image.This leads to confusion and inaccuracies in capturing the evolution of characters.And due to the limited samples of modern Chinese characters, an incomplete structure appears.
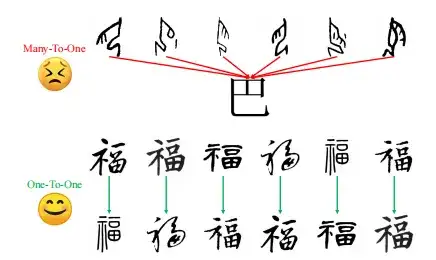
To overcome these challenges,This study proposed a zero-shot learning strategy to improve the model's understanding of structure by using different modern Chinese character writing styles.In actual operation, the study trained the module in a one-to-one manner on 20 different modern Chinese fonts, thereby learning the structural transformations between different modern Chinese writing styles and enhancing the model's ability to understand character structure.
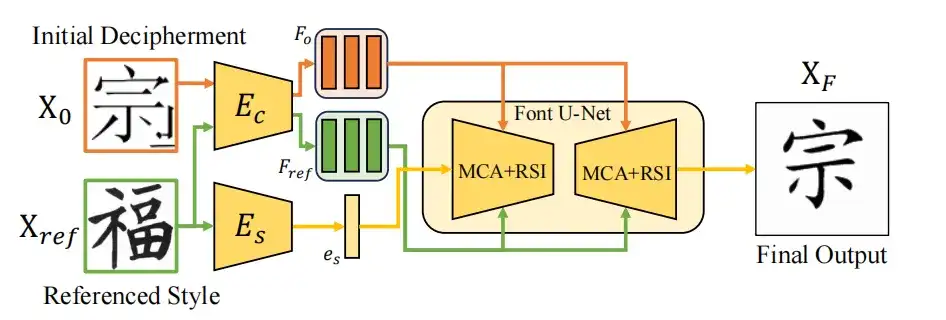
As shown in the figure below, the zero-shot learning method is based on a universal font style transfer framework, which adapts the style of the source font image X0 to the target style Xref through a dual encoder system while preserving the content integrity. The style encoder Es extracts the style feature es from Xref, while the content encoder Ec processes Xo and Xref to obtain the multi-scale content feature Fo, which is refined by the Font U-Net with multi-scale content aggregation (MCA) and reference structure. After training, the zero-shot learning module can be directly used to optimize the results generated by the diffusion model.
OSBD performance evaluation: The recognition accuracy rate is the highest under multiple evaluation criteria
To quantitatively evaluate the performance of OSBD, the study used two different evaluation criteria: single-round decryption and multi-round decryption. Since there are no tools dedicated to oracle decryption, the study adopted a comparative framework to adapt the leading image-to-image translation methods to this task.
Specifically, these methods include GAN-based methods such as Pix2Pix, CycleGAN, DRIT++, and diffusion models such as CDE, Palette, BBDM, etc. This setting ensures that the OBSD method can be evaluated in the context of the latest image conversion and ensures fair and consistent training and testing conditions.
In a single round of decryption evaluation,OBSD has significant advantages over modified image-to-image conversion methods in cracking oracle bones.As shown in the figure below.
The top-1 accuracy achieved by OSBD through OBS-OCR and PaddleOCR is 41.0% and 30.0% respectively, which is better than other methods. As the ranking increases, the accuracy has a clear improvement trend. Under the top-500 accuracy, OSBD has achieved an OBS-OCR recognition accuracy of 64.5%.
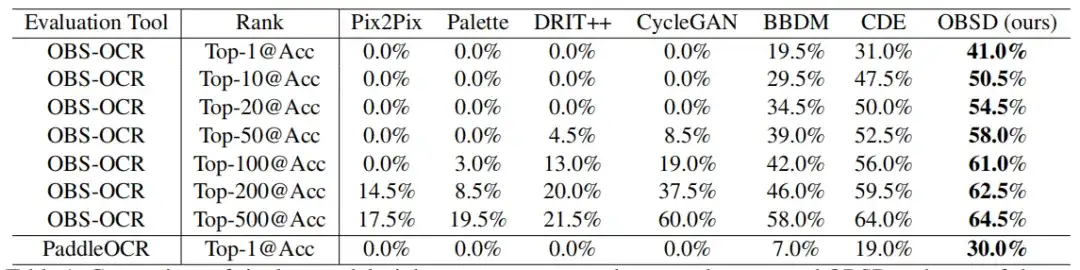
It is worth noting that all GAN-based methods (such as Pix2Pix, Palette, DRIT++, and CycleGAN) show the worst effectiveness in this case, with a top-1 accuracy of 0.%. This may be due to the difficulty of GAN itself in capturing the complex and subtle mapping relationships required to decipher oracle bones.
In multiple rounds of decryption evaluation,The success rate of OBS-OCR gradually improved over multiple attempts.The indicator has continuously improved from a success rate of 41.0% to 80.0%, as shown in the figure below.
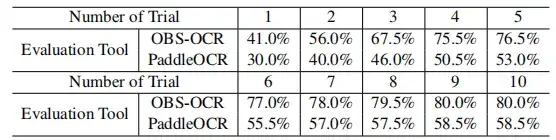
The growth trend of the PaddleOCR metric also shows an upward trend, starting from 30.0% and finally reaching 58.5%. These results all verify that incremental improvements can be achieved through continuous attempts.
To further examine the impact of individual components, the study also conducted an ablation study, focusing on the LSS module and zero-shot learning. The results show that decoding oracle using only the basic conditional diffusion model has limitations and has significantly lower accuracy. Specifically, training the diffusion model without any enhancement results in outputs that are essentially meaningless.
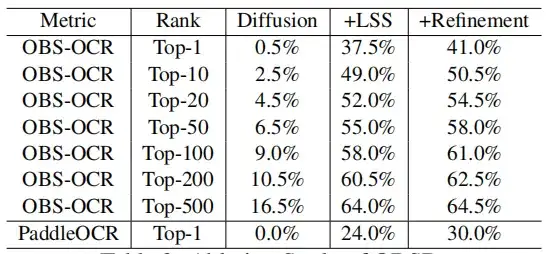
By introducing the LSS module,The recognition accuracy of OBS-OCR has been improved to 37.5%.PaddleOCR improves to 24%. By using the zero-shot learning module with LSS, the Top-1 accuracy of OBS-OCR and PaddleOCR can be further improved, with an additional 3.5% and 6% respectively.
Finally, this study also conducts a qualitative study on various image-to-image translation models.
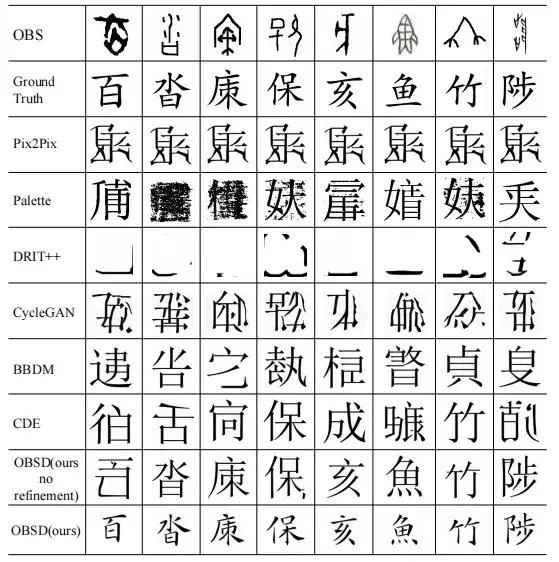
The results show that oracle bone inscriptions input through the OBSD method can produce the most accurate modern Chinese character decipherment and can discern the complex details of oracle bone inscriptions. These results not only highlight the effectiveness of OSBD, but also its potential as an expert tool for oracle language decipherment.
When oracle bone inscriptions meet artificial intelligence, the ancient writing system finally gets a new lease of life
In the field of ancient writing research, especially oracle bone writing research, Huazhong University of Science and Technology has always been at the forefront of the times and is one of the earliest universities in China to build its own oracle bone writing database. With the rapid development of artificial intelligence technology, intelligent processing of text and images has become one of the hot spots in the field of artificial intelligence research. Huazhong University of Science and Technology, represented by the research team of Bai Xiang and Liu Yuliang, has once again become a pioneer and leader in text and image intelligence.
Professor Bai Xiang is a National Outstanding Young Scholar and IAPR Fellow. He is currently the Dean of the School of Software at Huazhong University of Science and Technology and the Director of the Hubei Engineering Research Center for Machine Vision and Intelligent Systems.Monkey, developed by Professor Bai Xiang The multimodal big model has won the first place in the OpenCompass open source version of the authoritative big model list.The results have been applied to the innovative products of Wuhan's leading software companies.
As a core member of Bai Xiang's team, Liu Yuliang was selected for the 9th China Association for Science and Technology Young Talent Support Project. He focused on text and image intelligence and achieved a series of work results in document intelligent analysis, visual and natural language understanding, and multimodal large models.
As technology matures, in order to achieve greater breakthroughs in oracle bone inscription research, Bai Xiang and Professor Liu Yuliang resolutely chose to cooperate with Anyang Normal University, one of the top institutions in China for oracle bone inscription research. In 2018, the Ministry of Education Key Laboratory of Oracle Bone Inscription Information Processing of Anyang Normal University was approved for construction; in 2019, the oracle bone inscription big data platform "Yin Qi Wen Yuan" carefully built by the laboratory, which integrates the oracle bone inscription document library, catalog library, and character library, was opened to the world.This is the most complete, standardized and authoritative oracle data platform in the world.Its opening marks the entry of oracle bone research into the intelligent era.
It is worth noting that Liu Yongge, one of the corresponding authors of this article, is the director of the Key Laboratory of Oracle Information Processing of the Ministry of Education at Anyang Normal University.
In order to better record and disseminate oracle bone research, the laboratory focused on two major things in 2023: On the one hand, it launched the "Oracle Bone Global Digital Return Plan" in cooperation with Tencent SSV, the Anyang Workstation of the Institute of Archaeology of the Chinese Academy of Social Sciences, and the Anyang Cultural Relics Bureau, using cameras with hundreds of millions of pixels to achieve high-fidelity restoration and protection of oracle bones in digital space. On the other hand, the "Amazing Oracle Bone Script" applet jointly launched by the laboratory and Tencent has brought oracle bones closer to the public.
Coincidentally, in order to facilitate scholars to find information on oracle bone splicing more conveniently and shorten the time for data collection in the early stage of research,In early 2023, Yang Yi, Huang Bo, and Cheng Minghui, doctoral students from the Center for Excavated Documents and Ancient Characters Research at Fudan University, jointly created the "Jade and Pearl" oracle bone splicing information database.It brings together more than 6,700 sets of oracle bone splicing results from many scholars since the publication of the "Oracle Bone Collection". It has not only become an online tool for the academic community to search for major oracle bone splicing results, but also allows many oracle bone enthusiasts outside the "ivory tower" to have the opportunity to participate in the work of solving oracle bone fragments and provide corrections and new oracle bone splicing information.
It can be seen that with the help of digital technologies such as big data, cloud computing, and artificial intelligence, oracle bone inscription research has entered a new era. As research continues to deepen, I believe that this "unpopular and unique" technique will eventually be cracked to reveal more codes in the near future, and will play a very important role in deciphering other ancient characters.








