Command Palette
Search for a command to run...
Universal Robots Milestone! MIT Proposes a Strategy Combination Framework PoCo to Solve the Problem of Heterogeneous Data Sources and Enable Flexible multi-task Execution of Robots

18 humanoid robots acted as "greeters" and waved to the guests in unison. This was a shocking scene at the 2024 World Artificial Intelligence Conference, allowing people to intuitively feel the rapid development of robots this year.

In 1954, the world's first programmable robot "Unimate" was officially put into operation on the General Motors assembly line. After more than half a century, robots have gradually grown from bulky industrial giants to smarter and more flexible human assistants. Among them, artificial intelligence technology, especially the breakthrough progress of natural language processing and computer vision, has paved a high-speed track for the development of robots. Using huge computing power and massive data,Training general robotics strategies through simple algorithms such as behavioral cloning,The unlimited potential of future robots is gradually being unlocked.

However, most current robot learning pipelines are trained for a specific task.This makes them unable to cope with new situations or perform different tasks.In addition, robot training data mainly comes from simulation, human demonstration and robot teleoperation scenarios.There is huge heterogeneity between different data sources.It is also difficult for a machine learning model to integrate data from so many sources, and training robots with general strategies has always been a major challenge.
In response to this,MIT researchers proposed a robot policy composition framework PoCo (Policy Composition).This framework uses the probability synthesis of diffusion models to combine data from different fields and modalities, and develops task-level, behavior-level, and field-level policy synthesis methods for building complex robot policy combinations, which can solve the data heterogeneity and task diversity problems in robot tool use tasks. Related research has been published on arXiv under the title "PoCo: Policy Composition from and for Heterogeneous Robot Learning".
Research highlights:
* No need to retrain, the PoCo framework can flexibly combine strategies for training data from different fields
* PoCo excels in tool use tasks in both simulation and the real world, and is highly generalizable to tasks in different environments compared to methods trained on a single domain

Paper address:
https://arxiv.org/abs/2402.02511
The open source project "awesome-ai4s" brings together more than 100 AI4S paper interpretations and provides massive data sets and tools:
https://github.com/hyperai/awesome-ai4s
Three major data sets, covering human & machine data, real & simulated data, etc.
The data sets involved in this study mainly come from human demonstration video data, real robot data, and simulation data.
Human Demonstration Video Dataset
Human demonstration videos can be collected from uncalibrated cameras in the wild, with up to 200 tracks collected in total.

Real Robot Dataset
The local and global views of the scene are obtained through the installed wrist camera and overhead camera, and the tool posture, tool shape, and tactile information when the tool contacts the object are collected using GelSight Svelte Hand. 50-100 trajectory demonstrations are collected for each task.
Simulation Dataset
The simulated data set follows Fleet-Tools, where expert demonstrations are generated through key point trajectory optimization, and a total of about 50,000 simulated data points are collected. In the subsequent training process, the researchers performed data augmentation on both point cloud data and motion data, and saved fixed simulation scenes for testing.
In addition, the researchers added point-wise noises and random dropping to 512 tools and 512 object point clouds from depth images and masks to improve the robustness of the model.
Combining strategies through probability distribution product
In the strategy combination, the researchers gave trajectory information encoded by two probability distributions pDM(⋅|c,T) and pD′M′(⋅|c′,T′), and directly combined the information of these two probability distributions by sampling in the product distribution during inference.
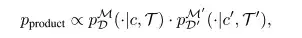
in,pproduct It shows high likelihood on all trajectories that satisfy both probability distributions.It can effectively encode information of both distributions.
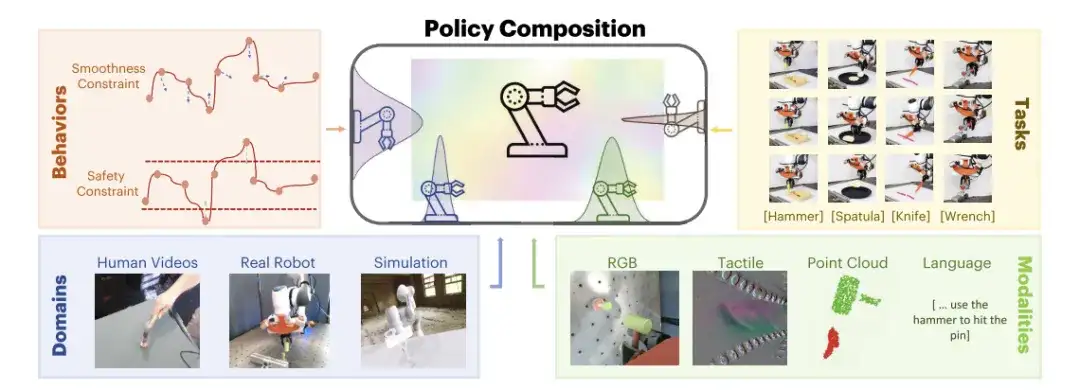
PoCo proposed by researchers,Bringing together information across behaviors, tasks, channels, and domains,No retraining is required; information is combined in a modular manner during prediction, and generalization of tool usage tasks can be achieved by leveraging information from multiple fields.
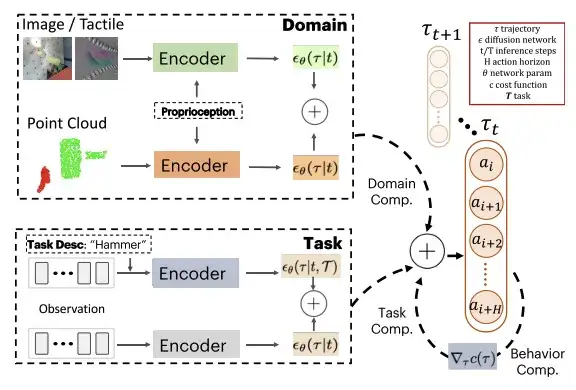
It is assumed that the diffusion output of each model is in the same space, that is, the action dimension and action time domain are the same. At test time, PoCo is combined with gradient predictions. This method can be applied to the combination of strategies in different fields, such as combining strategies trained with different modal data such as images, point clouds, and tactile images. It can also be used for the combination of strategies for different tasks, as well as providing additional cost functions for the desired behavior through the combination of behaviors.
In this regard, the researchers provided three examples: Task-level Composition, Behavior-level Composition, and Domain-level Composition to illustrate how PoCo can improve policy performance.
Task-level Composition
Task-level composition adds extra weights to trajectories that can potentially complete task T, which can improve the final quality of the synthesized trajectory without the need for separate training for each task.Instead, a general policy is trained that can achieve multi-task goals.
Behavior-level Composition
This combination can combine information about task distribution and cost objective.Ensure that the synthesized trajectory both completes the task and optimizes the specified cost target.
Domain-level Composition
This combination can leverage information captured from different sensor modalities and domains.Very useful to complement data collected in separate fields.For example, when real robot data is expensive to collect but more accurate, and simulation demonstration data is cheaper to collect but less accurate, feature concatenation can be performed on data from different modes in the same field to simplify processing.
Visualization tool usage task, evaluate 3 major strategy combinations

During training, the researchers used a temporal U-Net structure with a denoising diffusion probabilistic model (DDPM) and performed 100 steps of training; during testing, they used a denoising diffusion implicit model (DDIM) and performed 32 steps of testing. In order to combine different diffusion models between different domains D and tasks T, the researchers used the same action space for all models and performed fixed normalization on the robot's action boundaries.
The researchers evaluated the proposed PoCo through robot usage tasks for common tools (wrench, hammer, shovel, and spanner). The task was determined to be successful when a certain threshold was reached, for example, the hammering task was considered successful when a pin was driven in.
Behavior-level combinations can improve desired behavioral goals
The researchers used test-time inference to combine behaviors such as smoothness and workspace constraints, with the synthesis weight fixed to γc=0.1.
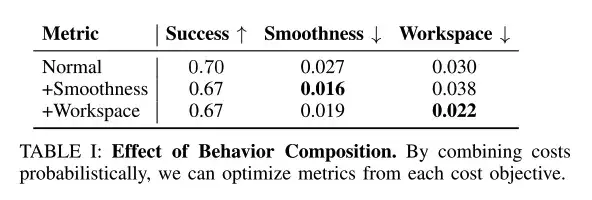
As shown in the table above, test-time behavior-level combinations can improve desired behavioral goals such as smoothness and workspace constraints.
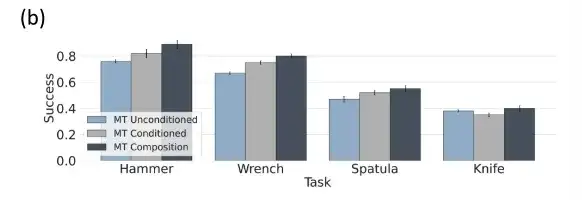
Task-level combinations are optimal in multi-task policy evaluation
When the task weight α=0, the task-level combination policy is mapped to the unconditioned multitask policy, when α=1, it is mapped to the standard task-conditioned policy, when 0 < α < 1, the researchers interpolate between the task conditional and task unconditional policies. When α > 1, a trajectory that is more relevant to the task condition can be obtained.
The above figure shows that compared with the unconditional and task-specific conditional multi-task tool use diffusion strategy, the conditional and unconditional multi-task tool use strategy has a better task combination.
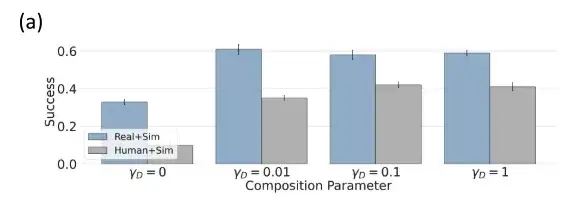
Human + simulated data, domain-level combination has better performance
The researchers trained separate policy models using a simulated dataset θsim, a human dataset θhuman, and a robot dataset θrobot, and evaluated domain-level combinations in a simulated setting.
Since θsim has no training/test domain gap, it performs well and can achieve a 92% success rate. In domains such as human data, the researchers combined it with a better performing policy θsim, significantly improving performance.
The performance of the strategy combination exceeds that of its individual components and is more versatile
The researchers used PoCo in robot tool use tasks to combine data from different fields and tasks to improve its generalization ability. The four tasks were: tightening a screw with a wrench, hammering a nail with a hammer, scooping a pancake out of a pan with a shovel, and cutting plasticine with a knife.

By combining policies trained in simulation, humans, and real data, we can generalize across multiple distractors (row 1), different object and tool poses (row 2), and new object and tool instances (row 3).
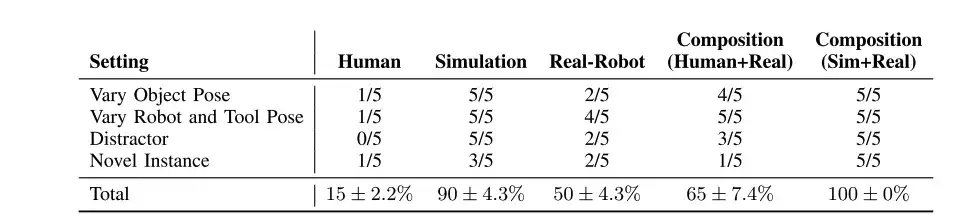
As shown in the table above, although the strategies trained with human data and the strategies trained with real-robot data perform poorly in different scenarios (compared with simulation),But their combination (Human+Real) can exceed each individual component.
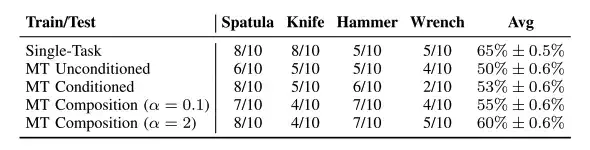
Through the real world, researchers evaluated the robot's strategic performance on four different tool-using tasks and found that in tool-using tasks,The performance of task combination strategy is improved better.As shown in the table above, the multi-task strategy has almost the same performance as the specific tasks conditioned by Tspatula and Thammer, and they all show a certain stability in fine actions. In addition, the combined hyperparameters need to be kept within a range to be effective and stable.
The best conditions for universality, the rise of humanoid robots
General-purpose robots have flourished in the past two years, but an interesting phenomenon is that the industry currently seems to be more in favor of promoting the development of general-purpose robots in a humanoid way.Why must general-purpose robots be humanoid?Chen Zhe, managing director of 5Y Capital, said, "Because only humanoid robots can adapt to different interaction scenarios in the human living environment!" Since robots are going to help humans work, it is obviously best for them to imitate humans and learn in a human form.
As a benchmark for the industry, as early as September 2022, Tesla released the general-purpose humanoid robot Optimus. Although it could not even walk steadily at first, it has a complete humanoid robot prototype and meets the basic dexterous work that humans can do. With the continuous iteration of Tesla's software and hardware technology, Optimus will have more exciting functions, and this has been proved to be the case.

At the 2024 World Artificial Intelligence Conference, Tesla showed everyone the latest research progress of its humanoid robot Optimus: the upright walking speed increased by 30%, and the ten fingers also evolved perception and touch, which can gently hold fragile eggs and steadily carry heavy boxes. It is understood that Optimus has tried practical applications in Tesla factories, such as using visual neural networks and FSD chips to imitate human operations to train battery sorting. It is expected that next year there will be more than 1,000 humanoid robots in Tesla factories to help humans complete production tasks.
Similarly, Shanghai Fourier Intelligent Technology Co., Ltd., an industry-leading general robotics company founded in 2015, also brought its humanoid robot GR-1 to the conference. Since its launch in 2023, GR-1 has taken the lead in mass production and delivery, achieving advanced upgrades in environmental perception, simulation models, motion control optimization, and other aspects.
In addition, in March of this year, NVIDIA also launched a humanoid robot project called GR00T at its annual GTC developer conference. By observing human behavior to understand natural language and imitate actions, the robot can quickly learn coordination, flexibility and other skills to navigate, adapt and interact with the real world.
With the continuous advancement of science and technology, we have reason to believe that humanoid robots may become a bridge connecting humans and machines, reality and the future, leading us into a smarter and better society.
References:
https://m.163.com/dy/article/J69LAFDR0512MLBG.html
https://36kr.com/p/1987021834257154
https://hub.baai.ac.cn/view/211








