Command Palette
Search for a command to run...
Candidate for CVPR 2024 Best Paper! Shenzhen University and Hong Kong Polytechnic University Jointly Released MemSAM: Applying the "Segment Everything" Model to Medical Video Segmentation

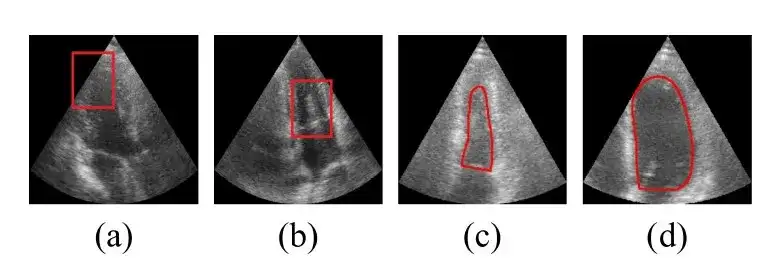
According to statistics from the World Health Organization (WHO), cardiovascular disease is the leading cause of death worldwide, claiming approximately 17.9 million lives each year, accounting for 32% of global deaths. Echocardiography is an ultrasound diagnostic technique for cardiovascular disease, which is widely used in clinical practice due to its portability, low cost, and real-time nature. However,Echocardiography requires manual evaluation by experienced doctors, and the quality of the evaluation depends largely on the doctor's professional knowledge and clinical experience.This often leads to large inter- and intra-observer differences in the evaluation results. Therefore, automated evaluation methods are urgently needed in clinical practice.
In recent years, many deep learning methods have been proposed for echocardiography video segmentation. However, due to the low quality and limited annotations of ultrasound videos, these methods still cannot achieve satisfactory results. Recently, a large-scale visual model, Segment Anything Model (SAM), has received great attention and achieved remarkable success in many natural image segmentation tasks.However, how to apply SAM to medical video segmentation remains a challenging task.
Based on this, a team jointly formed by the School of Computer Science and Software of Shenzhen University and the Intelligent Health Research Center of Hong Kong Polytechnic University published a paper titled "MemSAM: Taming Segment Anything Model for Echocardiography Video Segmentation" at the top computer vision conference CVPR 2024. In the paper,The researchers proposed a novel echocardiography video segmentation model, MemSAM, which applies SAM to medical videos.

The model uses memory containing spatiotemporal information as a hint for the segmentation of the current frame, and uses a memory reinforcement mechanism to improve the quality of the memory before storing it. Experiments on public datasets show that the model achieves state-of-the-art performance with a small number of point hints and achieves comparable performance to fully supervised methods with limited annotations, greatly reducing the hint and annotation requirements required for video segmentation tasks.
Research highlights:
- This study uses memory containing spatiotemporal information as a cue for the segmentation of the current frame to improve the consistency of representation and segmentation accuracy.
- The researchers further proposed a memory enhancement module to enhance memories before storing them, thereby mitigating the adverse effects of speckle noise and motion artifacts during memory cueing.
- The new model demonstrates state-of-the-art performance compared to existing models, in particular it achieves comparable performance to fully supervised methods with limited annotations.

Paper address:
https://github.com/dengxl0520/MemSAM
Datasets: 2 publicly available echocardiography datasets
The researchers used two widely used, publicly available echocardiography datasets to CAMUS The method is evaluated on EchoNet-Dynamic:
- The CAMUS dataset contains 500 cases, including 2D apical two-chamber and apical four-chamber view videos, and also provides annotations for all frames.
- The EchoNet-Dynamic dataset contains 10,030 2D apical two-chamber view videos. Each video provides the area of the left ventricle in the form of an integral, with only the end-diastolic (ED) and end-systolic (ES) phases annotated.
To fully evaluate the effectiveness of the new method in semi-supervised video segmentation, the researchers adapted the CAMUS dataset into two variants: CAMUS-Full and CAMUS-Semi. CAMUS-Full uses annotations of all frames during training, while CAMUS-Semi only uses annotations of end-diastolic (ED) and end-systolic (ES) frames. During testing, both datasets are evaluated using complete annotations.
The researchers uniformly sampled videos from the dataset and cropped them to 10 frames each. Cropping ensured that the ED frame was the first frame and the ES frame was the last frame, and the resolution was adjusted to 256×256. The CAMUS dataset was divided into training, validation, and test sets in a ratio of 7:1:2.
Model architecture: SAM components and memory components build the overall framework of MemSAM
The overall framework of the MemSAM model is shown in the figure below.It consists of two parts: SAM component and Memory component.
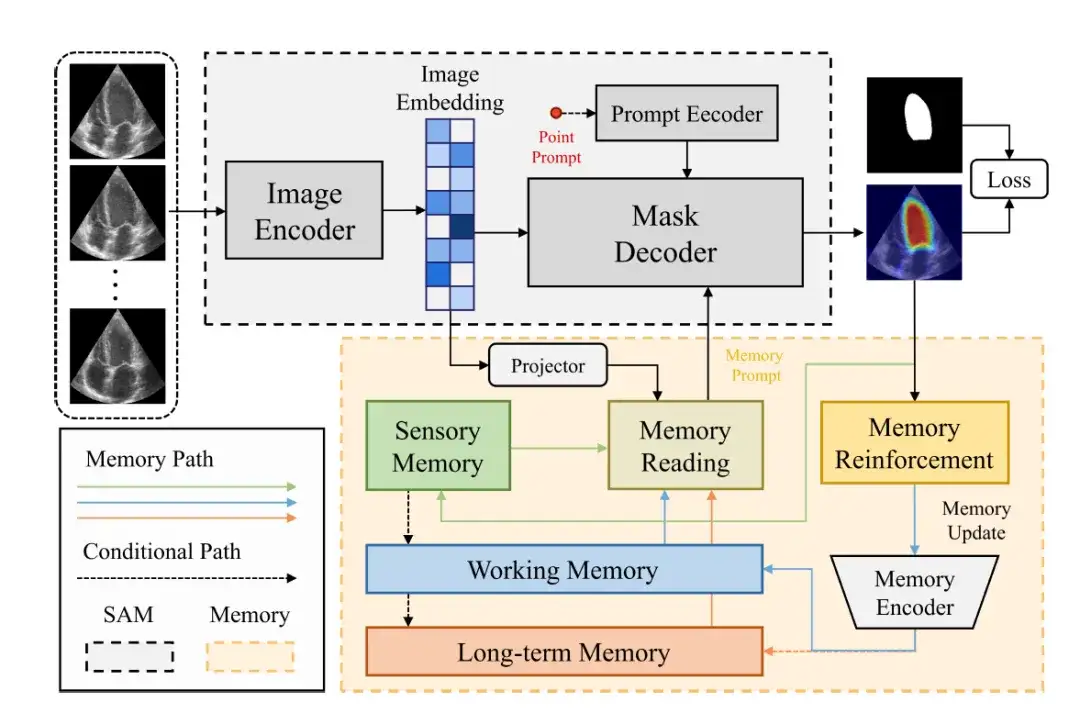
The SAM component uses the same architecture as the original SAM.It consists of an image encoder (Image Encoder), a prompt encoder (Prompt Encoder) and a mask decoder (Mask Decoder).
The image encoder uses Vision Transformer (ViT) as the backbone to encode the input image into an image vector (Image Embedding).
The hint encoder receives external hints, such as point prompts, and encodes them into a c-dimensional embedding. Subsequently, the mask decoder combines the image and the hint vector to predict the segmentation mask.
In these components, the image vector is mapped to the memory feature space through the projection layer, and then the researchers perform memory reading, obtain memory prompts from multiple feature memories (such as sensory memory, working memory, and long-term memory), and provide them to the mask decoder. Finally, after passing through memory reinforcement and memory encoder, the memory will be updated.
The following figure further shows more details of the memory read, memory enhancement and memory update process:
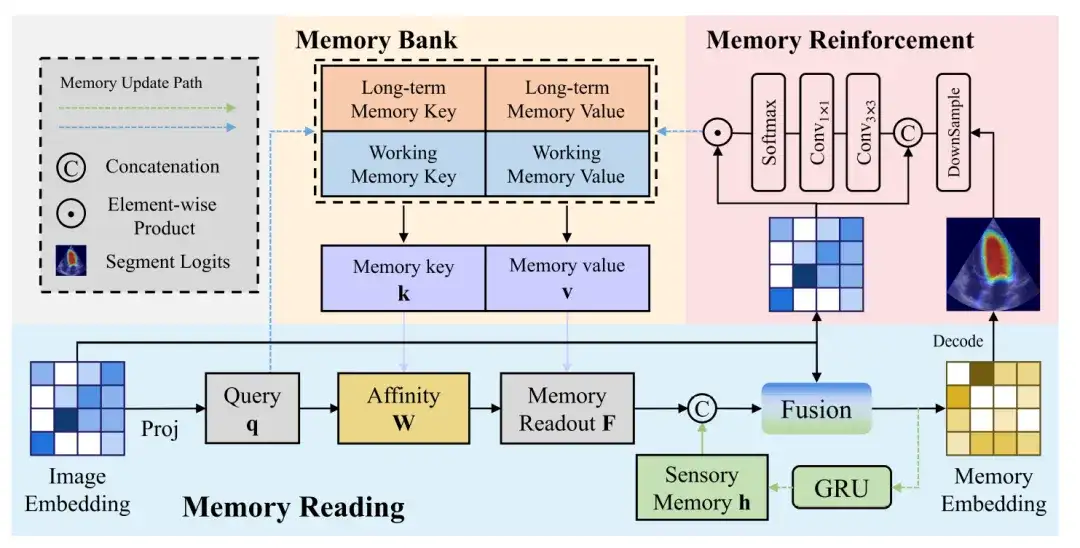
Memory Reading
The memory readout block shows the process of generating a memory vector from an image vector. The image vector is projected to generate a query, which is then queried against the memory value affinity to get a memory readout, which is then fused with the sensory memory and the image vector to get a memory vector.
Memory Enhancement
Compared with natural images, ultrasound images contain more complex noise, which means that the image vectors generated by the image encoder inevitably carry noise. If these noise features are updated to the memory without any processing, it may lead to the accumulation and propagation of errors.
In order to reduce the impact of noise on memory updating, a memory enhancement module is needed to enhance the recognizability of feature representations in memory. The memory enhancement block first concatenates the image vector and the predicted probability map, and then limits the receptive field of each pixel through a 3×3 convolution to generate a local attention weight feature.
Memory Update
Finally, the output features to be updated to the memory bank are obtained through the dot product of the Softmax function and the image vector.
Research results: MemSAM achieves state-of-the-art performance with limited annotations
To verify the performance of MemSAM, the researchers widely selected different types of comparison methods, including traditional image segmentation models and medical basic models. The three traditional image segmentation models are CNN-based UNet, Transformer-based SwinUNet, and CNN-Transformer hybrid H2Former. SAM models suitable for the medical field include MedSAM, MSA, SAMed, SonoSAM, and SAMUS. Among them, SonoSAM and SAMUS focus on ultrasound images.
First, the quantitative comparison results are shown in the following table:
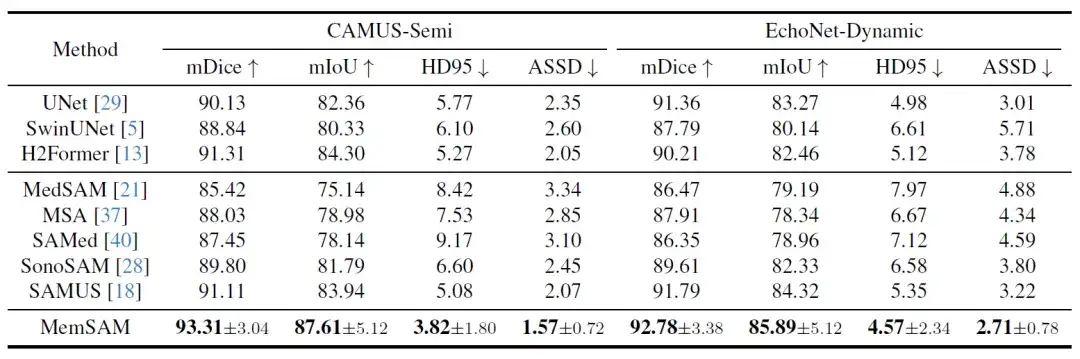
Among these state-of-the-art methods, H2Former and SAMUS perform relatively well on both datasets, thanks to their CNN-Transformer architecture and ultrasound image optimization. However, in the case of scarce annotations and without exploiting the temporal properties of videos, the above models lag behind the proposed method.Experiments verify that MemSAM achieves the best performance with limited annotations.
To further evaluate MemSAM, the researchers also compared the CAMUS-Semi and CAMUS-Full datasets under the same settings. The results are shown in the figure below:
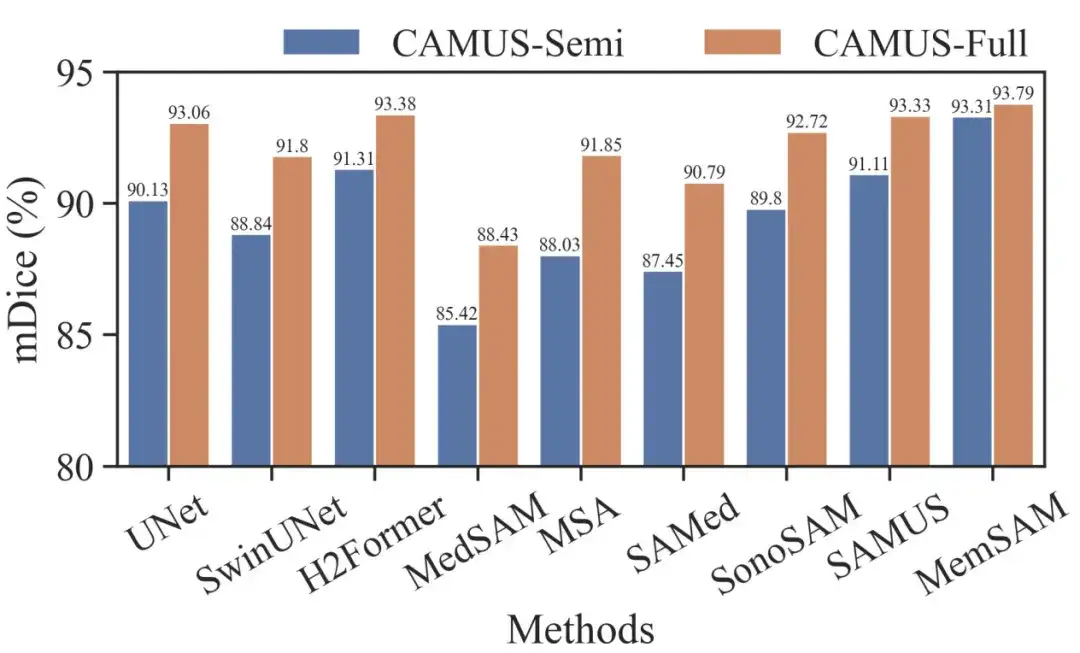
It can be seen that traditional methods like UNet and H2Former, as well as ultrasound-specialized methods like SonoSAM and SAMUS, can recover decent segmentation results when given full annotations. Although our method achieves a smaller gain from semi-supervised to fully supervised settings, it still outperforms other competitors in both cases.
It is worth noting that the Medical Baseline Model requires per-frame cues under full supervision, while MemSAM only requires a single point cue.Experiments verify that the proposed method achieves comparable performance to full annotations with sparse labels and far fewer external hints.
Next is the qualitative comparison result. The researchers provide visualization results for some challenging cases, as shown in the figure below:

The images in rows 1-2 of the above figure contain speckle noise around the left ventricle, misleading some traditional and medical-based models to mistakenly identify it as the edge of the ventricle. Rows 3-4 contain instances where the boundaries are severely blurred, and almost all the results given by the comparison models exceed the true ventricle boundary, while the method proposed in this study accurately outlines the boundary.These visualization results demonstrate that the proposed method is robust in dealing with poor image quality.
AI brings new ideas to the prevention and treatment of cardiovascular diseases
Cardiovascular disease is a category of heart and blood vessel diseases, including coronary heart disease, cerebrovascular disease, rheumatic heart disease and other diseases. In modern society, people's unhealthy diet, lack of physical activity, smoking and drinking have further increased the risk of cardiovascular disease.
In recent years, with the development of technologies such as artificial intelligence and big data, "AI+medical care" has entered the fast lane of development. AI has made extensive progress in the diagnosis and prediction of cardiovascular diseases. For example, AI combined with electrocardiogram and cardiovascular imaging data can achieve accurate diagnosis. AI combined with cardiovascular imaging data and other clinical data can achieve early screening and risk prediction of cardiovascular diseases such as coronary artery disease, congenital heart disease, and heart failure.
For example: Accurate classification of heart sounds is key to early diagnosis and intervention of cardiovascular diseases. The effectiveness of artificial heart sound auscultation still depends on the doctor's professional knowledge, but this situation is quietly changing. In November 2023, Pan Xiangbin's team from the Fuwai Hospital of the Chinese Academy of Medical Sciences (Fuwai Hospital) published a research paper titled "Heart sound classification based on bispectrum features and Vision Transformer mode" online in the Alexandria Engineering Journal.This study achieved binary classification of heart sounds based on bispectrum-inspired feature extraction and visual transformer model.
The model demonstrated excellent classification results in the entire population (including pregnant and non-pregnant patients), with diagnostic performance superior to that of human experts, demonstrating great application potential.
In October 2023, new research data published in the journal Clinical Medicine showed that by identifying signs of coronary artery disease, such as calcification and blockages, as well as evidence of previous heart attacks, ECG-AI can flag some risks years earlier than current risk calculator equations.
Just recently, a British company called Caristo Diagnostics published a landmark clinical study result in The Lancet.Their CaRi-Heart AI technology quantifies the severity of coronary artery inflammation and accurately predicts heart disease.
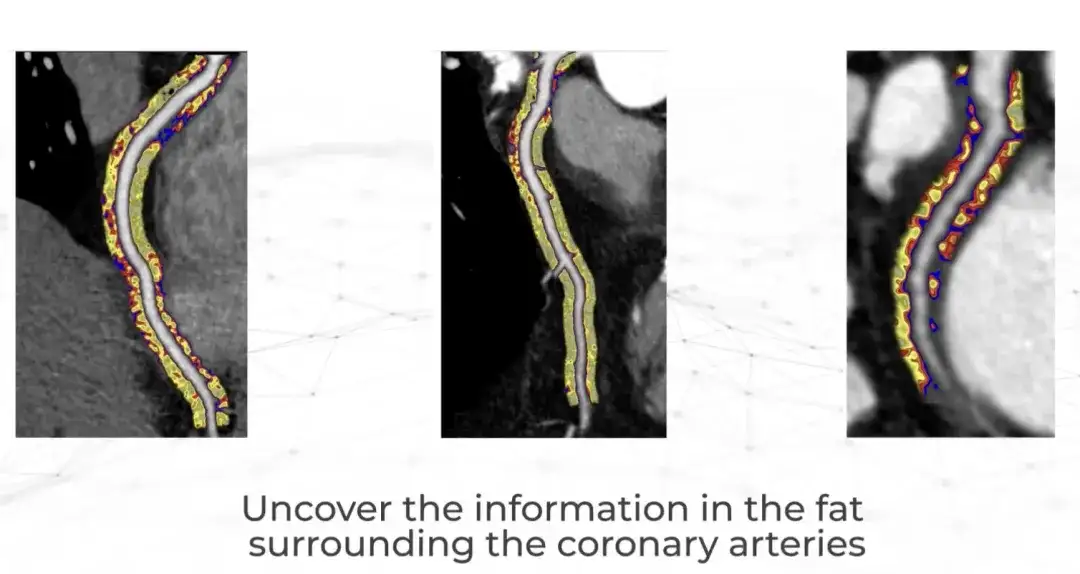
Caristo was founded in 2018 by cardiologists from the University of Oxford. The company made a major research discovery more than 50 years ago - heart attacks are caused by inflammation of the coronary arteries, but clinicians have been unable to observe and measure inflammation through routine heart examinations.Now, the CaRi-Heart technology can be used to CTTA Extract this information from the scan.This marks a scientific breakthrough that fundamentally changes the traditional approach to predicting, preventing and managing heart disease. It is reported that CaRi-Heart has been put into clinical use in the UK, Europe and Australia.
Looking into the future, artificial intelligence has great development potential in clinical diagnosis and treatment, especially in the prevention and treatment of cardiovascular diseases. It will help doctors provide patients with accurate diagnosis and advice more efficiently and reliably.
References:
1.https://m.chinacdc.cn/jkzt/mxfcrjbhsh/jcysj/201909/t20190906_205347.html
2.https://mp.weixin.qq.com/s/daqoXwnxeZxw7xC6iw1h3A
3.https://www.drvoice.cn/v2/article/12166
4.https://36kr.com/p/280080595174








