Command Palette
Search for a command to run...
Online Tutorial | Similar to Sora's Technical Route! The world's First Open Source Vincent Video DiT Model Latte one-click Deployment

Since OpenAI launched Sora, the concept of "Virtual Video" and its related applications have attracted much attention.The key technology behind it, DiT (Diffusion Transformers), was also "archaeologically excavated".

In fact, DiT is a text graph model that was open sourced two years ago. Its developers are Peebles and Xie Saining, among whom Peebles is also one of the project leaders of Sora.
Before the DiT model was proposed, Transformer almost dominated the field of natural language processing with its powerful feature extraction and context understanding capabilities, while U-Net dominated the field of image generation and diffusion models with its unique architecture and superior performance. The biggest feature of DiT is that it replaces the U-Net architecture in the diffusion model with the Transformer architecture.Interestingly, this work was rejected by CVPR in 2023 due to lack of innovation.
Compared with U-Net, Transformer has better scalability. It can learn global dependencies and handle long-distance dependencies in sequence data through the self-attention mechanism. It has great advantages in processing global image features. In addition, DiT based on the Transformer architecture has also significantly improved computational efficiency and generation effects, further promoting the large-scale application of image generation.
However, due to the high structure and complexity of video data, it is a challenge to extend DiT to the field of video generation.The research team from the Shanghai Artificial Intelligence Laboratory open-sourced the world's first Wensheng video DiT: Latte at the end of 2023. As a self-developed model similar to Sora technology, Latte can be freely deployed.For those who want to explore Vincent video technology, the open source Latte undoubtedly provides an opportunity for practice.
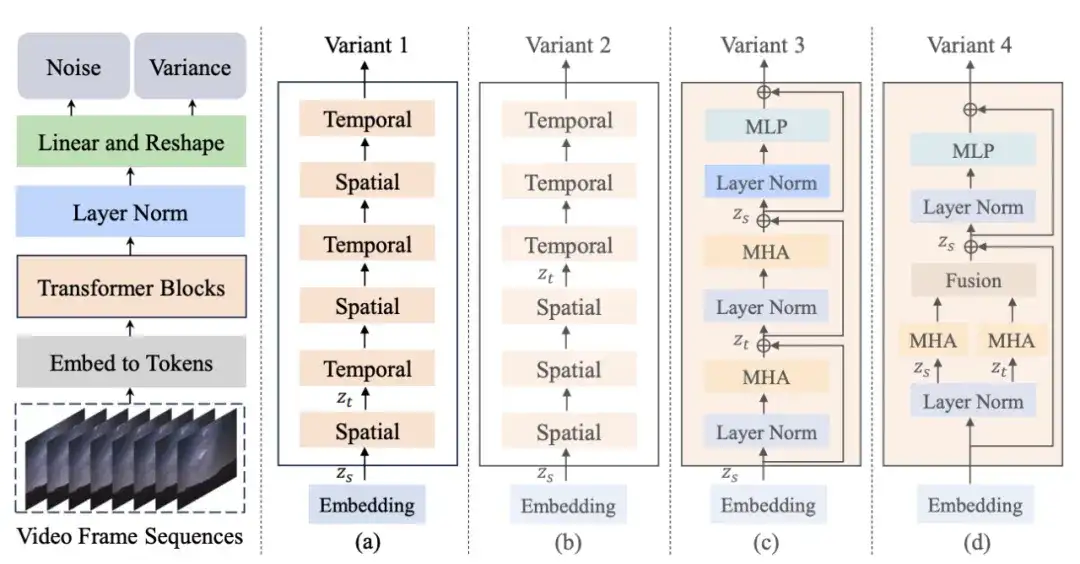
First, Latte encodes the input video into features in the latent space through a pre-trained variational autoencoder (VAE) and extracts tokens from it. Then, these tokens are encoded and decoded using the corresponding Transformer structure in one of the above variants. During the generation process, the model will gradually restore the low-noise video frame representation in the latent space based on the learned back-diffusion process, and finally reconstruct it into continuous and realistic video content.
It is worth noting that the Shanghai Artificial Intelligence Laboratory, the research and development team behind Latte, has worked with China Central Radio and Television Station toTogether, they launched the first Chinese original Wensheng video AI animation series "Poetry of the Thousand Years", which was broadcast on CCTV-1 Comprehensive Channel.Industry insiders analyzed that with the launch of the first AI animation in China, the implementation of cultural video applications in my country is expected to accelerate, which may reshape the production process of the film and television industry in the future and promote the revolutionary development of film and television animation production, game development and advertising design.
In this context, in order to help more creative workers and video enthusiasts keep up with the technology trend,HyperAI launched the "Latte World's First Open Source Vincent Video DiT" tutorial.This tutorial has built an environment for you. You no longer need to wait for the model to be downloaded and trained. Just click Clone to start it with one click, and enter text to generate a video instantly!
Tutorial address:https://hyper.ai/tutorials/32065
The editor used the text "a dog with sunglasses" to generate a video of a puppy wearing sunglasses. It looks pretty handsome!

Demo Run
1. Log in to hyper.ai, on the "Tutorials" page, select "Latte World's First Open Source Vinyl Video DiT", and click "Run this tutorial online".

2. After the page jumps, click "Clone" in the upper right corner to clone the tutorial into your own container.
3. Click "Next: Select Hashrate" in the lower right corner.
4. After the jump, select "NVIDIA GeForce RTX 4090" and click "Next: Review".New users can register using the invitation link below to get 4 hours of RTX 4090 + 5 hours of CPU free time!
HyperAI exclusive invitation link (copy and open in browser):https://openbayes.com/console/signup?r=6bJ0ljLFsFh_Vvej
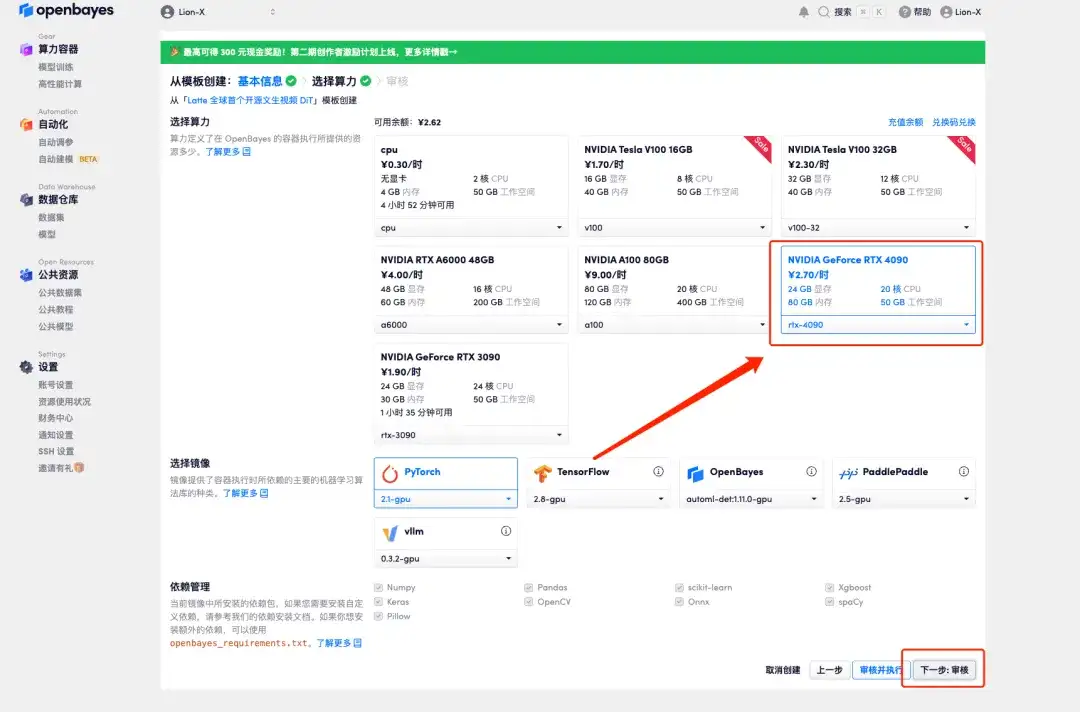
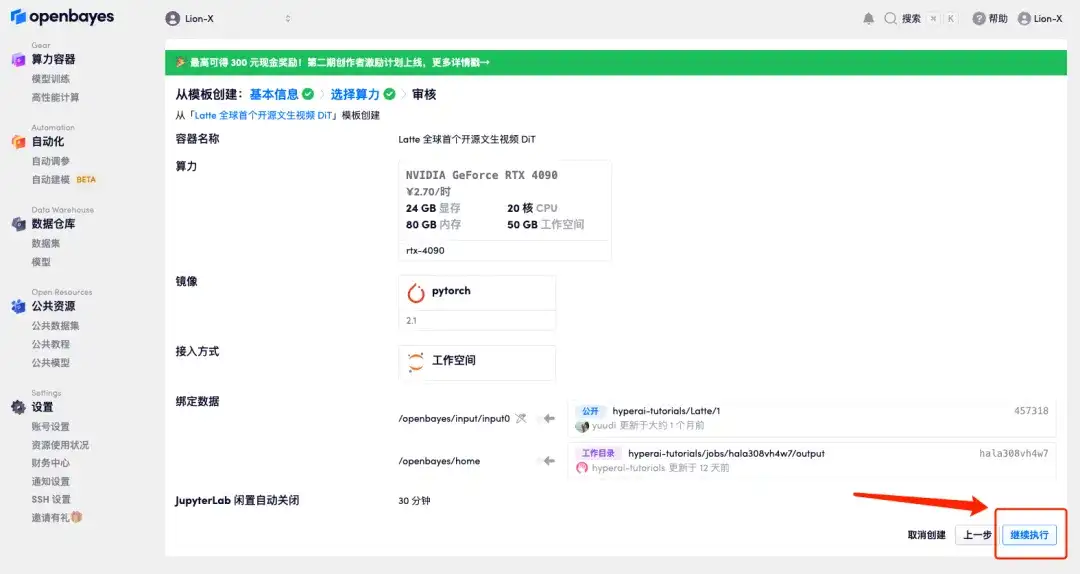
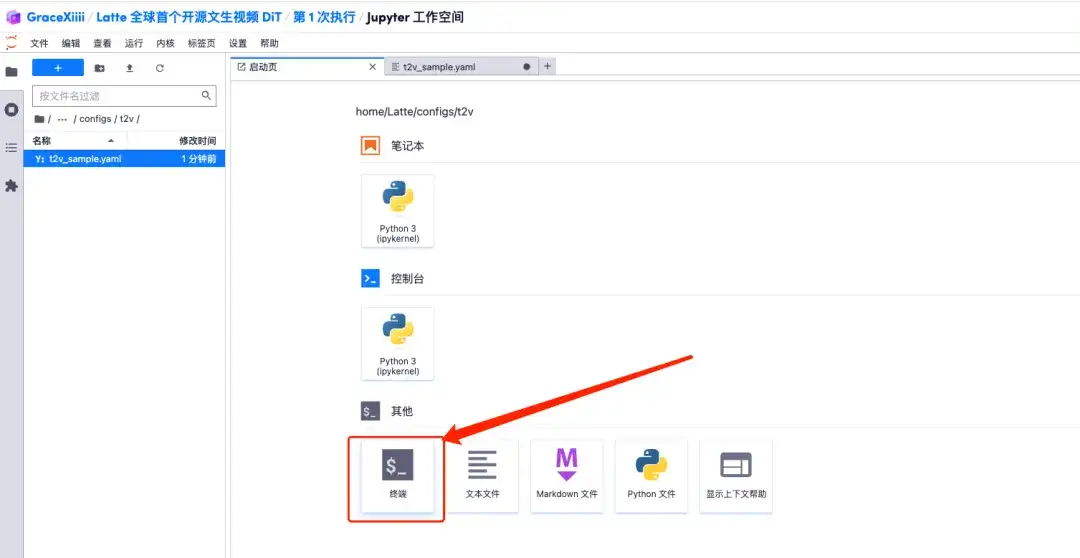
5. Click "Continue" and wait for resources to be allocated. The first cloning process takes about 3-5 minutes. When the status changes to "Running", click "Open Workspace".
If the issue persists for more than 10 minutes and remains in the "Allocating resources" state, try stopping and restarting the container. If restarting still does not resolve the issue, please contact the platform customer service on the official website.
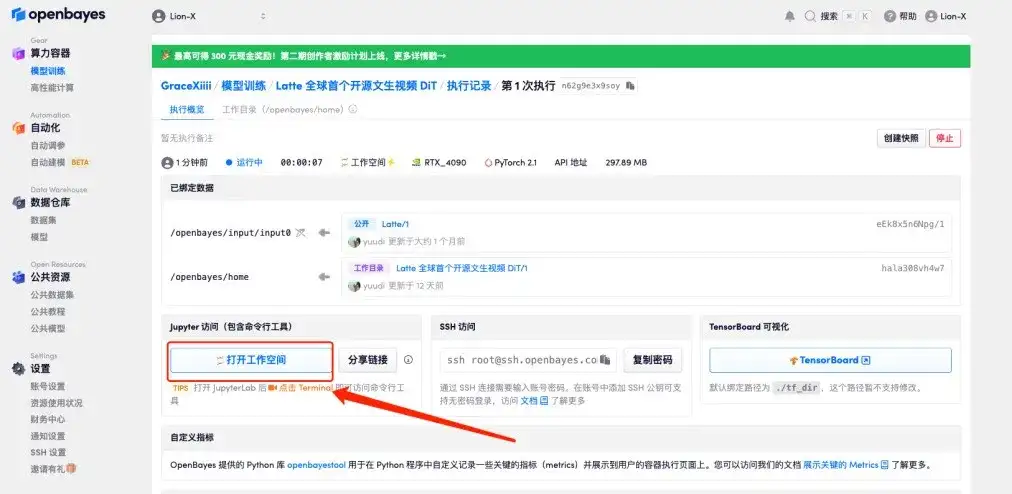
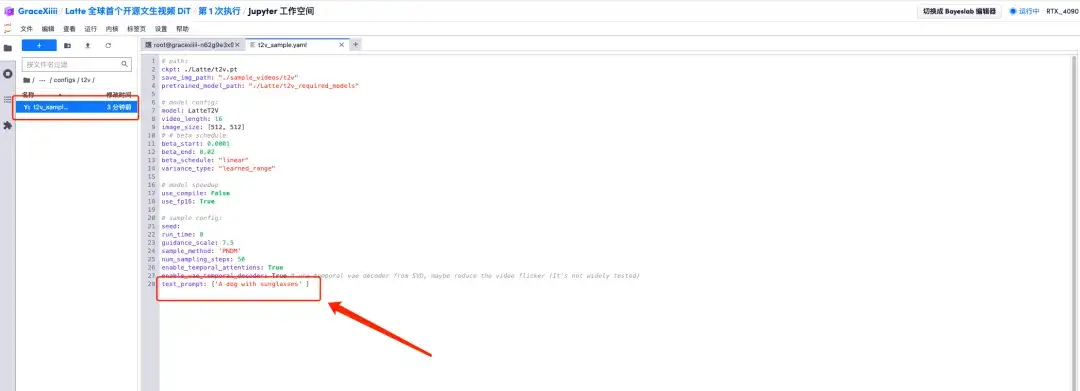
6. After opening the workspace, open the configuration file home/Latte/configs/t2v/t2v_sample.yaml according to the path in the left menu, enter prompt "For example: a dog with sunglasses" under text_prompt, and save it with Ctrl+S.
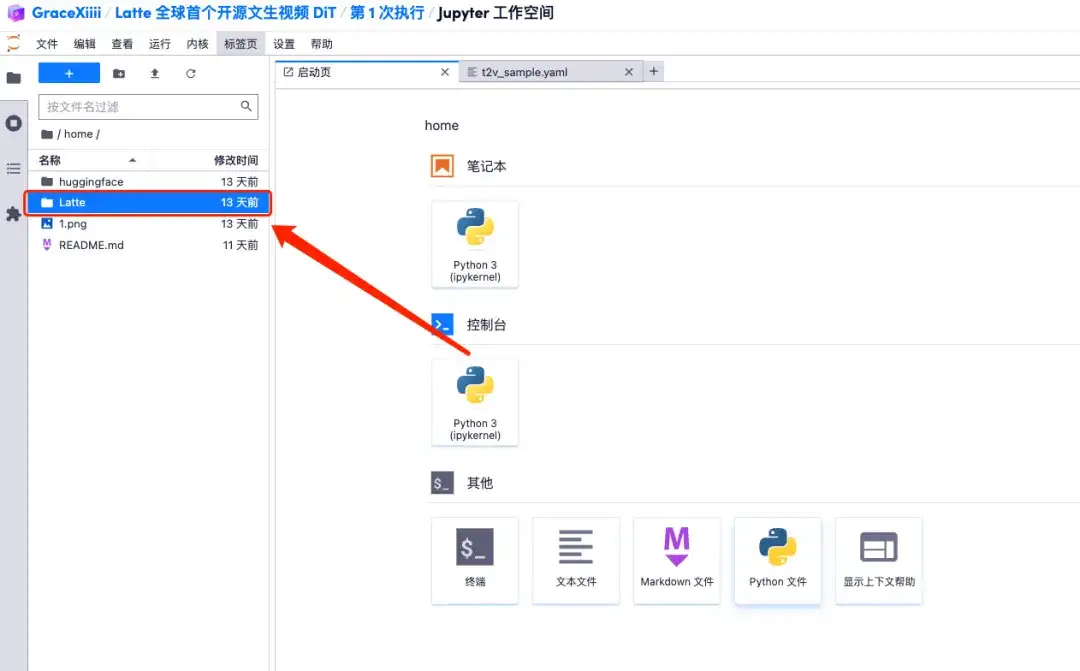
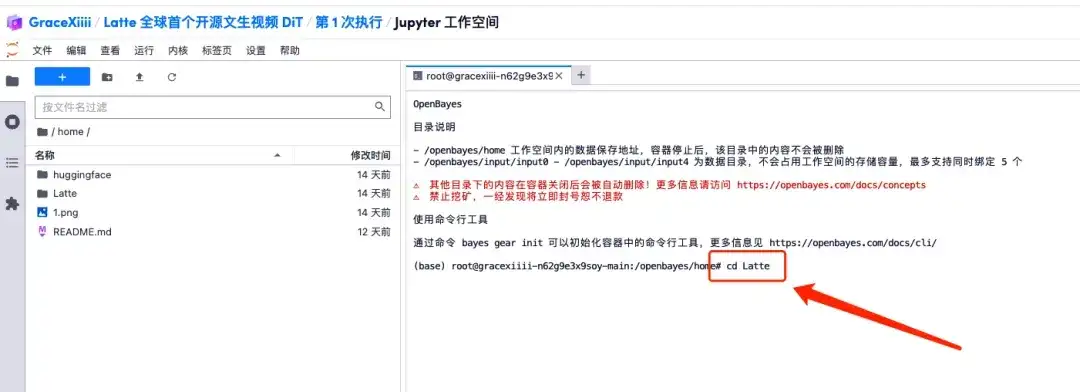
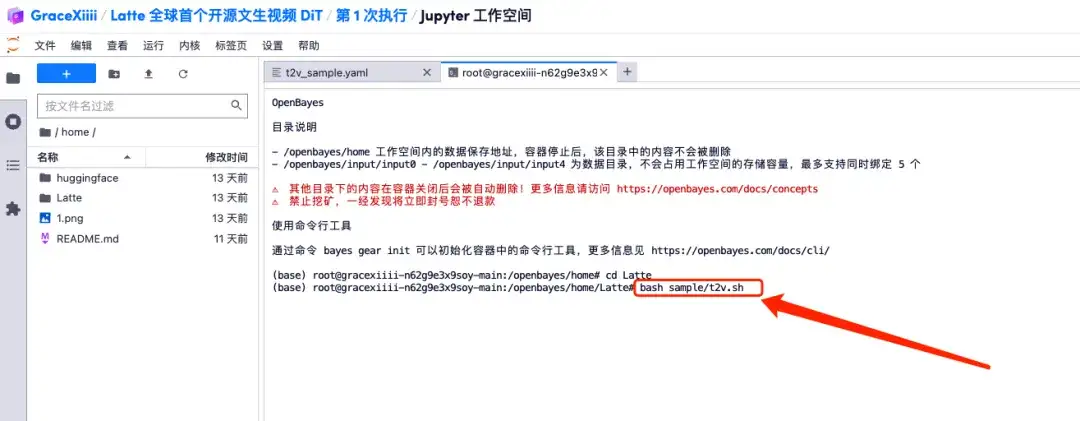
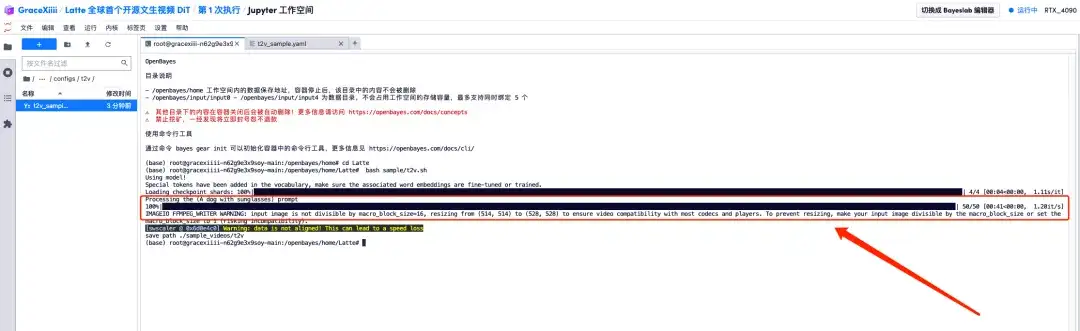
7. After saving, create a new terminal page, enter "cd Latte" and press Enter to enter the "Latte" directory. Enter "bash sample/t2v.sh" to generate high-definition video.
Effect display
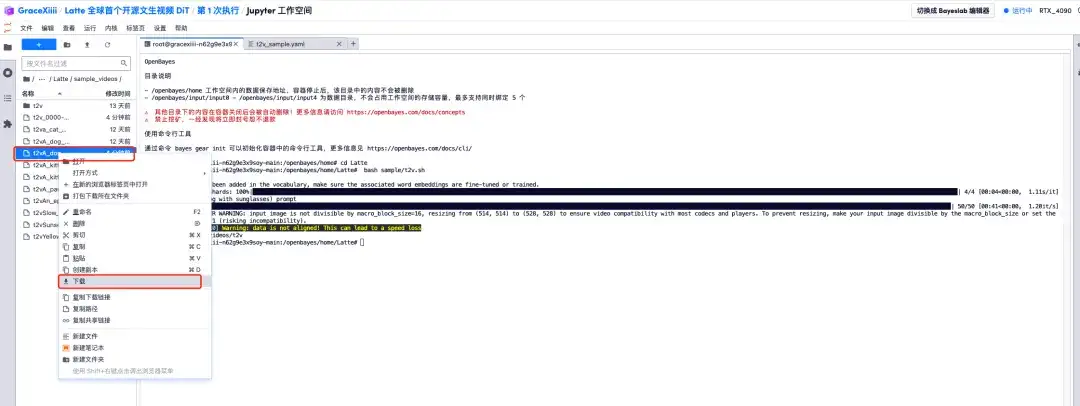
1. When the progress bar shows 100%, open the left menu bar "Latte/sample_videos", find the video we generated, and right-click to download.Please note that MP4 videos cannot be viewed directly and must be downloaded before viewing.
2. A video of a puppy wearing sunglasses is generated!

At present, HyperAI's official website has launched hundreds of selected machine learning related tutorials, which are organized into the form of Jupyter Notebook.
Click the link to search for related tutorials and datasets:https://hyper.ai/tutorials
The above is all the content of HyperAI Super Neural Network’s sharing this time. If you see a high-quality project, please leave a message in the background to recommend it to us! In addition, we have also established a "Stable Diffusion Tutorial Exchange Group", welcome friends to join the group to discuss various technical issues and share application results~








