Command Palette
Search for a command to run...
Online Tutorial丨liu Qiangdong's Digital Human Debut Sales Exceeded 50 Million! Generate real-time Speaking Digital Human With GeneFace++
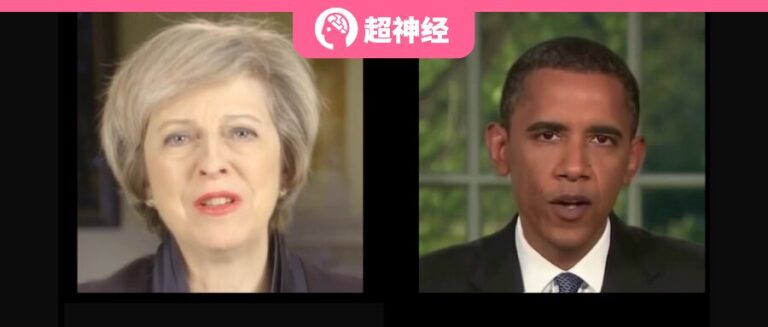
Recently, JD.com founder Liu Qiangdong transformed himself into the "Purchasing and Sales Dongge AI Digital Human" and started his first live broadcast in the purchasing and sales live broadcast room of JD.com's home appliances and supermarkets. The live broadcast event attracted more than 20 million viewers and the total transaction amount exceeded 50 million.It fully demonstrates the huge potential of AI digital people in the field of e-commerce live streaming.
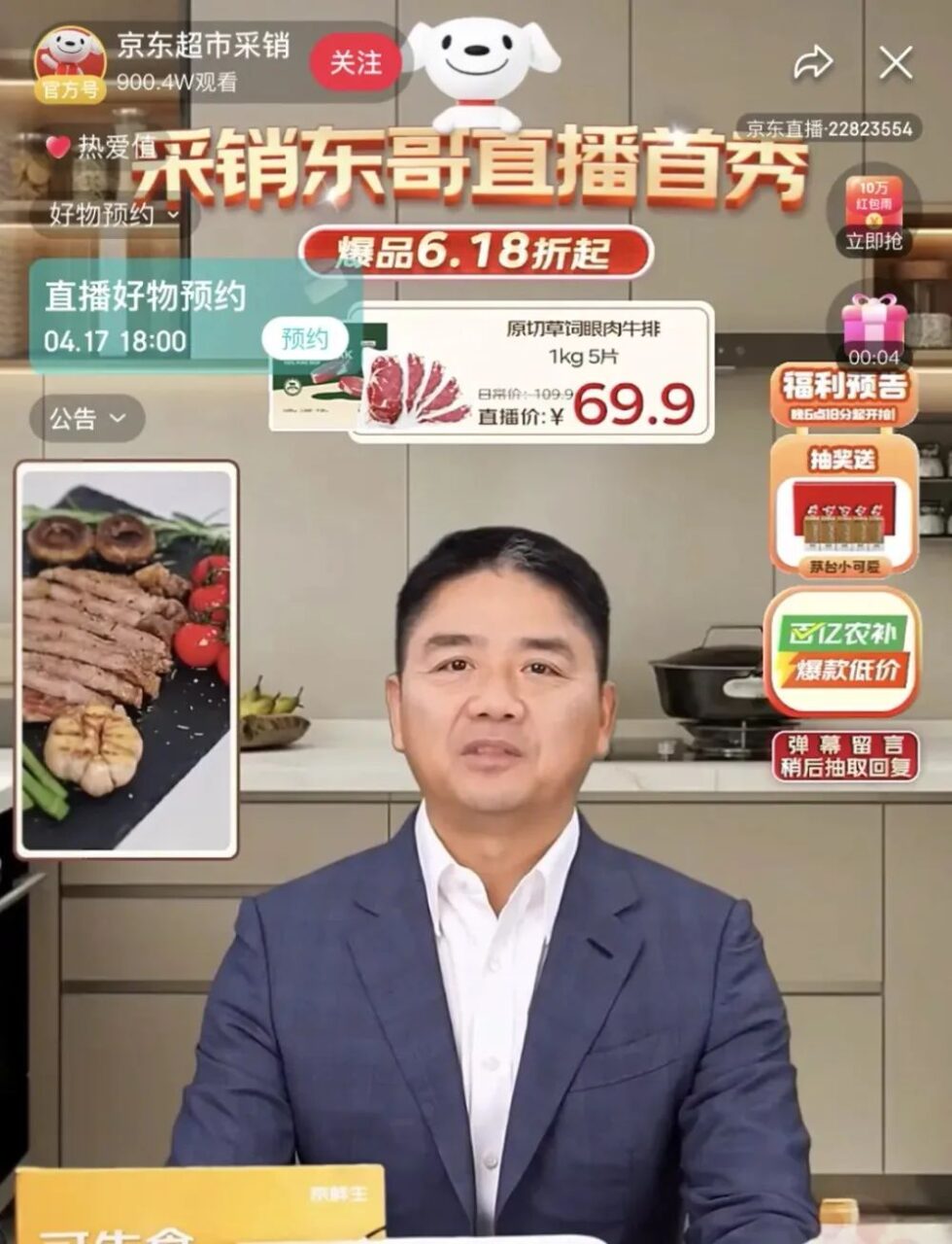
Image source: Guanchazhe.com
It is understood that the "Purchasing and Sales Dongge AI Digital Human" can accurately display Liu Qiangdong's personalized expressions, postures, gestures, and timbre characteristics by learning and training his image and voice. It is difficult to distinguish the difference between the digital human and the real person with the naked eye within 120 seconds.

IDC once stated in "China AI Digital Human Market Status and Opportunity Analysis 2022" that the scale of China's AI digital human market is expected to reach 10.24 billion yuan by 2026. It has to be said that AI digital humans are replicable, low-cost, and can work 24 hours a day. Applying them in scenarios such as self-media operations, short video sales, and digital human broadcasting to assist humans in completing various tasks may become a major trend in the future.
In this field, audio-driven talking face generation is a hot topic. Based on this technology, a speaking video of the target person can be constructed by simply inputting a voice clip, thereby helping the target person to attend some scenes where it is inconvenient or impossible for a real person to appear.GeneFace++ is a general and stable real-time audio-driven 3D talking face generation technology that is the first to achieve real-time talking face generation by improving lip synchronization, video quality and system efficiency.
Specifically, GeneFace++ trains the audio-to-motion module and the real-time motion-to-video module independently. During the training process, it involves mapping learning between audio and facial motion, domain-adaptive transfer learning, and landmark-driven 3D portrait real-time rendering technology learning, which ultimately enables the model to generate high-quality, real-time, lip-synced 3D talking face videos based on any audio.
However, creating a realistic lip-synced digital human is not an easy task. In order to help beginners get started quickly and avoid common environment construction and technical difficulties,HyperAIHyperAIThe "GeneFace++ Digital Human Demo" tutorial was launched.This tutorial has built an environment for everyone and simplified the process of making digital humans. You don’t need to worry about issues such as environment configuration, hardware requirements, and version compatibility. Just click Clone to start it with one click, and the effect is very realistic!
HyperAI Hyperneural Public Tutorial Address:
https://hyper.ai/tutorials/31157
Preliminary preparation
Prepare a 3-5 minute video:
* The picture should be clear and square in size (preferably 512*512);
* In order for the model to better extract the background, the video background should be a solid color without other interference factors;
* The faces of the people in the video should be clear and relatively large, and should be frontal. The captured images should preferably be above the shoulders, and the movements of the people should not be too large or too small;
* The audio in the video is free of noise;
* It is best to name the video in English.
Note: This video will be used for model training. The better the video quality, the better the effect. Therefore, it is necessary to spend more time and effort on data preparation.
The following is an example of a video screen:

Demo Run
1. Log in to hyper.ai, and on the Tutorial page, select GeneFace++ Digital Human Demo. Click Run this tutorial online.

2. After the page jumps, click "Clone" in the upper right corner to clone the tutorial into your own container.

3. Click "Next: Select Hashrate" in the lower right corner.

4. After the jump, select "NVIDIA GeForce RTX 4090" and click "Next: Review".New users can register using the invitation link below to get 4 hours of RTX 4090 + 5 hours of CPU free computing time!
HyperAI exclusive invitation link (copy and open in browser to register):
https://openbayes.com/console/signup?r=6bJ0ljLFsFh_Vvej

5. Click "Continue" and wait for resources to be allocated. The first clone will take about 3-5 minutes. When the status changes to "Running", click "Open Workspace". If it is still in the "Allocating Resources" state for more than 10 minutes, try to stop and restart the container; if restarting still does not solve the problem, please contact the platform customer service on the official website.



6. After opening the workspace, create a new terminal session on the startup page, then enter the following code in the command line to start the environment. Just copy and paste it.
conda env export -p /output/geneface
conda activate /output/geneface


7. Wait for a moment and run the following command in the terminal to configure the environment variables.
source bashrc

8. Wait for a while, enter the following code in the command line to start the WebUI, and wait for about 1 minute.
/openbayes/home/start_web.sh
9. When the command line displays "Running on local URL: https://0.0.0.0:8080", copy the API address on the right to the browser address bar to access the GeneFace++ interface.Please note that users must complete real-name authentication before using the API address access function.

Effect display
1. After opening the GeneFace++ interface, import the video prepared in advance, select the number of training steps "50000", and click "Train" to start training.
Note: This step requires waiting for more than 2 hours. During this period, you can check 1-2 times whether the training is running normally to avoid time loss caused by interrupting the process but still waiting.
The number of training steps "50000" here is by default. If the results of 50000 steps of training are poor, please change the training data and retrain.

2. When "Train Success" appears, refresh the GeneFace++ interface.

3. In the GeneFace++ interface, upload the audio on the left and do not modify the parameters of the middle module.
Select the audio driver model "model_ckpt_steps_400000.ckpt" from the model on the right.
Select the torso model "model_ckpt_steps_50000.ckpt" corresponding to the training under 50,000 steps.
Select the head model "model_ckpt_steps_50000.ckpt" corresponding to the training under 50,000 steps.
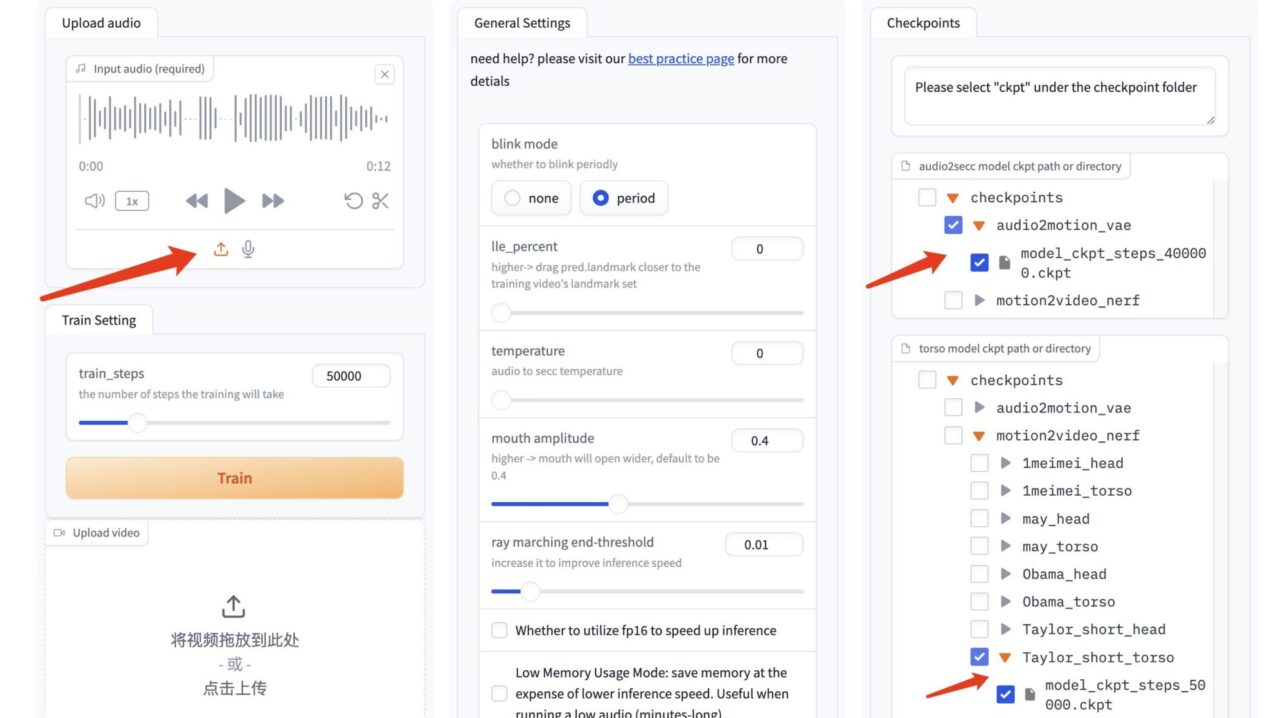
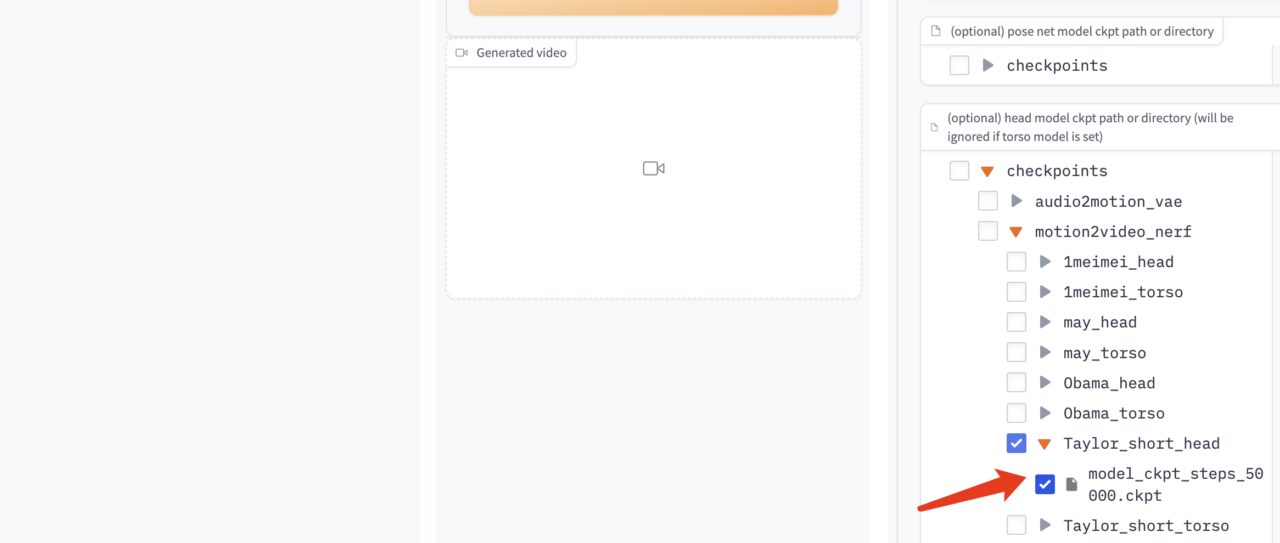
4. Click "Gnerate" to generate the effect.

5. If you want to train further, delete the head_done folder and torso_done folder under the corresponding model.
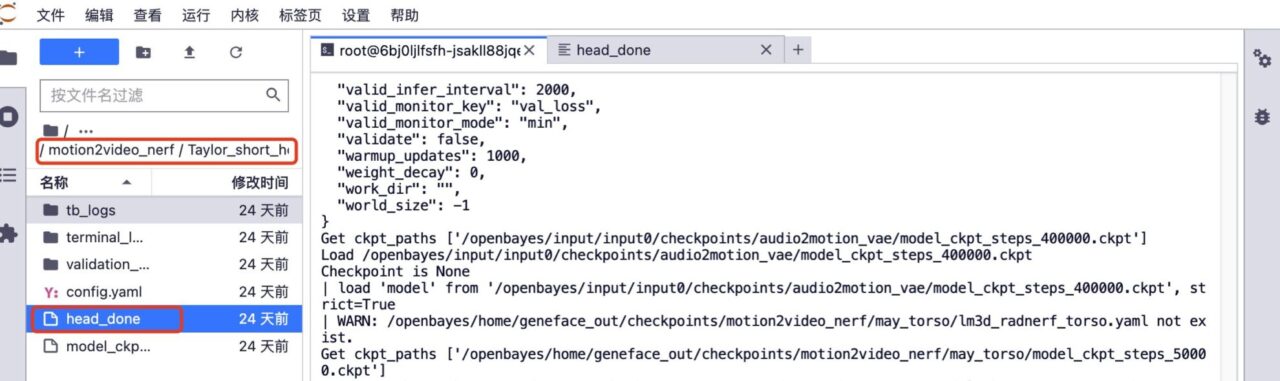
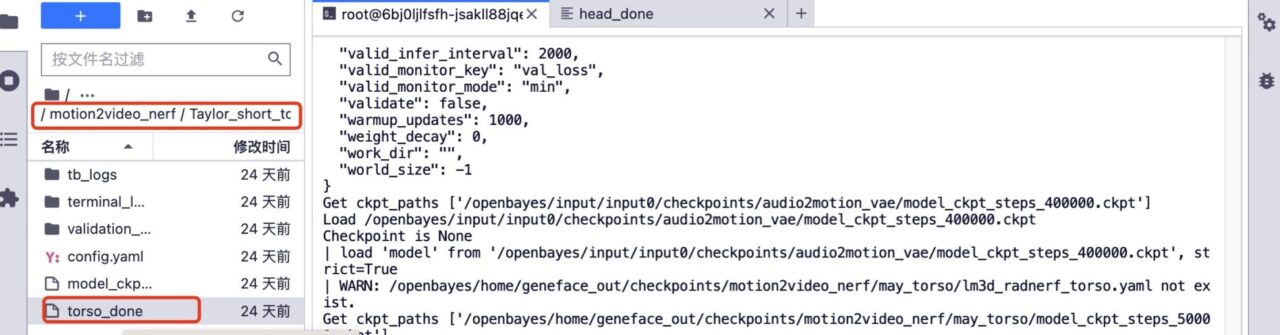
6. Upload the previous training video, keep the video file name unchanged, increase the number of training steps, and click "Train" to start training.


7. After the training is completed, in the GeneFace++ interface, select the default audio driver model, the torso model corresponding to the 150,000 steps training, and the head model corresponding to the 150,000 steps training. Click "Gnerate" to generate the final effect.
At present, the HyperAI official website has launched hundreds of selected machine learning related tutorials, which are organized into the form of Jupyter Notebook.
Click the link to search for related tutorials and datasets:
The above is all the content that I have shared this time. I hope this content is helpful to you. If you want to learn other interesting tutorials, please leave a message or send us a private message to tell us the project address. I will tailor a course for you and teach you how to play AI.
References:
https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/128895215








