Command Palette
Search for a command to run...
Online Tutorial | One-click Launch of Sora Open Source Alternative, Capturing 450,000 AI Developers

In 1888, Edison submitted a patent for a "moving picture projector," a device that for the first time played static photos continuously, creating a dynamic picture effect, thus opening the prelude to the development of video.
Looking back at history, video has gone through an iteration from nothing to something, from black and white to color, and from analog signals to digital signals. In the past, video production included multiple steps such as script/screenplay creation, shooting, editing, dubbing, and proofreading. Today, from the popular videos on short video platforms to the big-budget movies showing in theaters, they still follow this long chain of production.
In recent years, with the emergence of generative AI, video production has also ushered in innovation.Since the emergence of ChatGPT, generative AI's ability in text understanding has repeatedly brought surprises.
On February 26, OpenAI released the Sora model, which can generate up to one minute of video by receiving text instructions. It not only has a good ability to understand long texts, but also can understand and simulate real-world physics, generate complex scenes containing multiple characters and specific types of movements, and have both logic and realism.However, OpenAI has only released a demonstration video of the Sora model, and access to it has only been granted to a small number of researchers and creative people.
At the same time, there are now multiple open source AI-generated video models available for free use. Jack-Cui, a popular up-master on Bilibili, introduced in his video tutorial that the currently best open source AI video generation solution is the combination of Stable Diffusion + Prompt Travel + AnimateDiff.
Among them, Stable Diffusion is a "latent diffusion model" that first maps the original high-dimensional data (such as images) to the latent space through the encoder, diffuses and denoises in this space, and then reconstructs the cleaned data in the latent space back to the high-dimensional space through the decoder.The final result is to generate a corresponding static image according to the text instructions.
Compared to the current mainstream diffusion model in the field of AI video generation, Stable Diffusion introduces an additional encoding-decoding stage, which allows it to be applied to high-dimensional data (such as images) in a low-dimensional latent space that contains important features of the original data.Improved the efficiency and generation quality of the model.
Prompt Travel is an adjustmentText instructionsIn this way, users can provide different keywords and descriptions in different timelines of the video according to their creative intentions, guiding the AI model to generate a series of coherent and changing images.
Finally, AnimateDiff appends a newly initializedMotion Modeling Module, and use the video clip dataset to train reasonable motion prior knowledge. Once the motion module is trained, it is inserted into the text-based graph model, so that the model has the ability to generate diverse and personalized text-driven video clips.
Currently, the model deployment tutorial has been launched on the HyperAI official website, and you can clone it with one click.
https://hyper.ai/tutorials/30038
The "Stable-Diffusion Online Tutorial" produced by Jack-Cui, a popular up master on Bilibili, is as follows. This tutorial will teach you step by step how to master AI painting & AI generated videos with just one click!
According to the tutorial, the editor has successfully generated various beautiful pictures and videos, and the effect is simply amazing!

Demo Run
1. Click "Run this tutorial online" to jump to OpenBayes to get RTX 4090 for free.
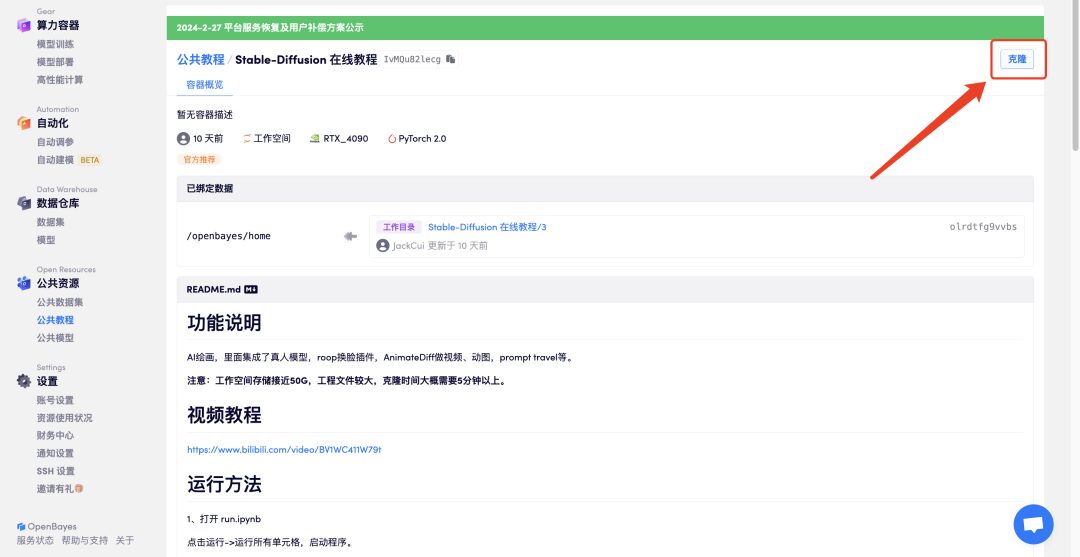
2. Click "Clone" in the upper right corner to clone the tutorial into your own container.
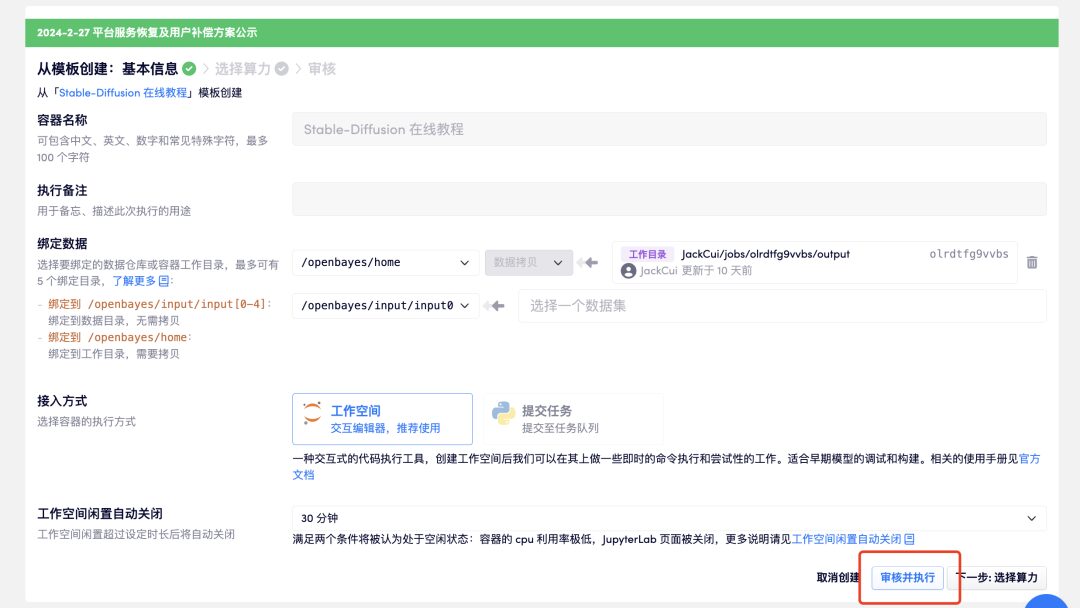
3. Click "Review and Execute" - "Continue to Execute". RTX 4090 is recommended. New users can register using the invitation link below to get 4 hours of RTX 4090 + 5 hours of free CPU computing time!
Invite link:
https://openbayes.com/console/signup?r=GraceXiii_W8qO
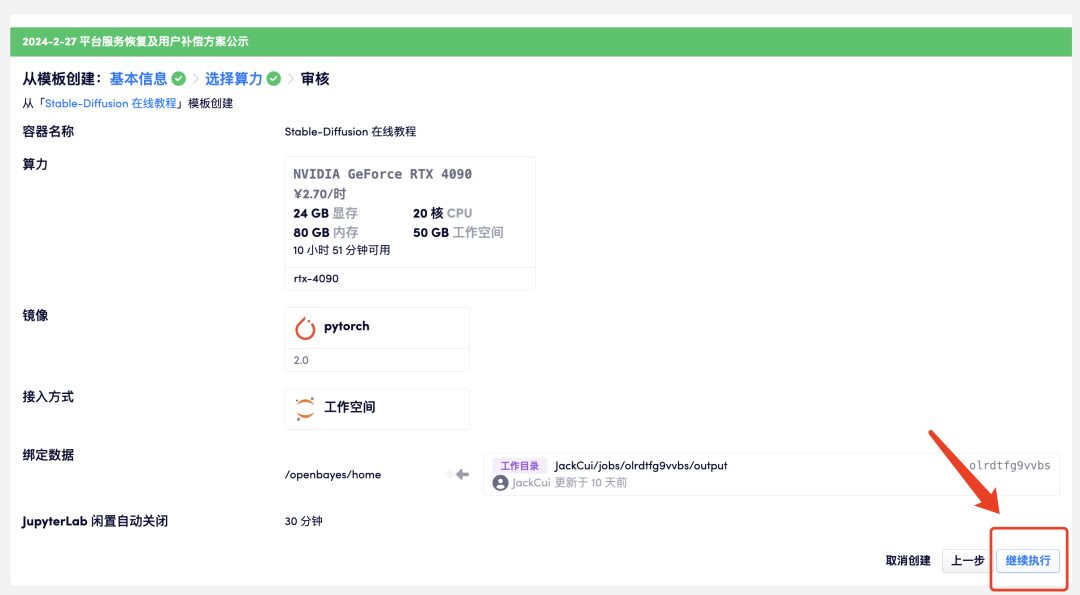
4. Wait for a while, and when the status changes to "Running", click "Open Workspace". This container has a large amount of data, and it takes about 8-10 minutes to start the container for the first time. Please wait patiently.
If the container is still in the "allocating resources" state for more than 15 minutes, you can try to stop and restart the container; if the problem still cannot be solved after restarting, please contact the platform customer service on the official website.
5. After opening the workspace, click "run.ipynb" on the left, and then click "Run All Cells" through the "Run" button on the menu bar.
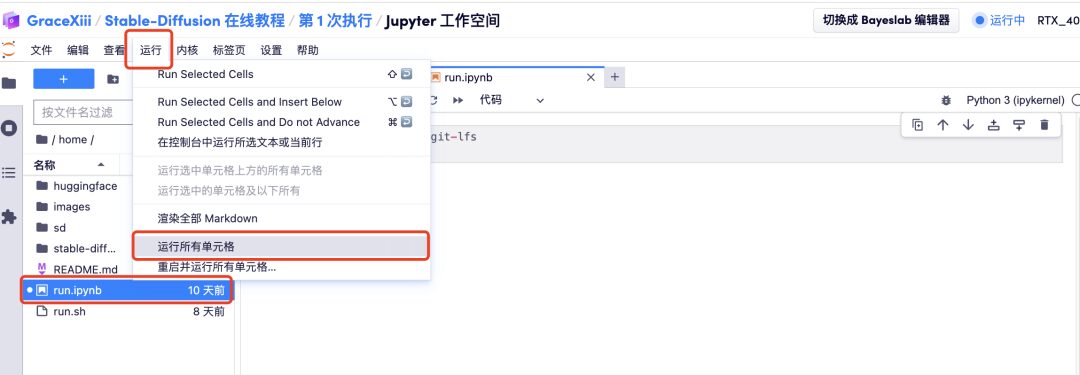
6. Wait for a while, and after the Local URL is generated, open the "API Address" on the right. Please note that users must complete real-name authentication before using the API address access function.
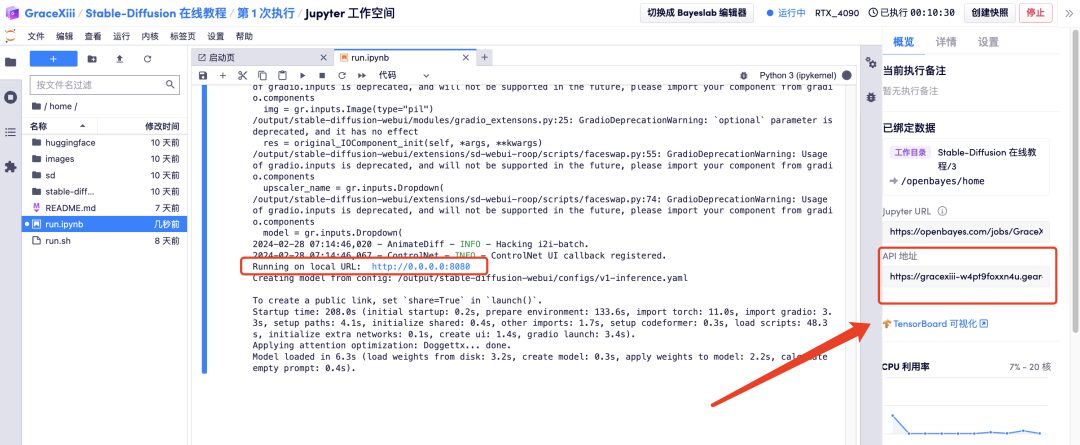
Effect display
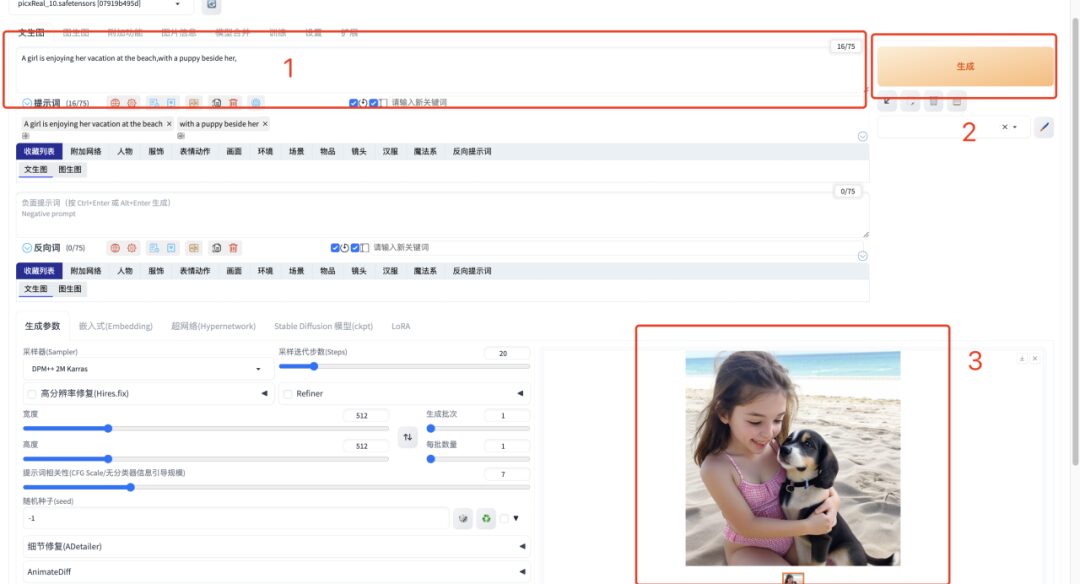
1. After opening the "API address", enter the English prompt word in the text box and click "Generate". It only takes 1 second to quickly generate the image.
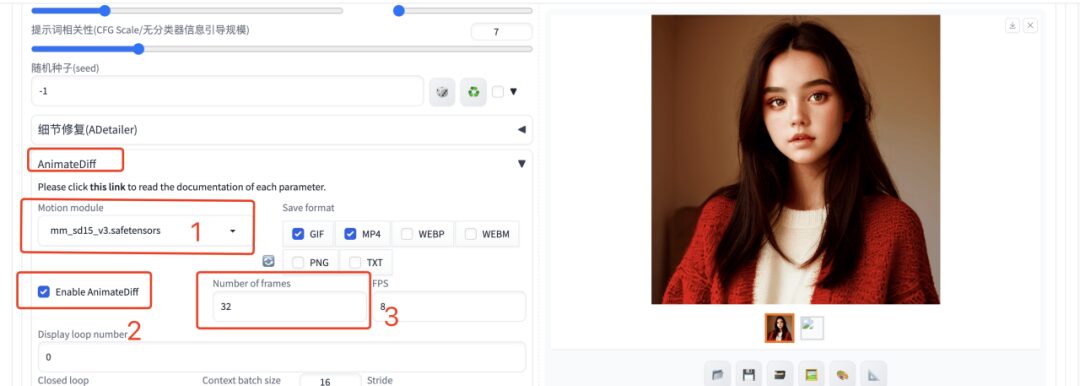
2. If you want to generate a video, you need to enter the English prompt word, select the AnimateDiff plug-in, fill in the number of generated frames as 32 frames, and leave the other parameters as default. Wait a moment, and you can generate the animated image or video.
At present, HyperAI's official website has launched hundreds of selected machine learning related tutorials, which are organized into the form of Jupyter Notebook.
Click the link to search for related tutorials and datasets:
The above is all the content shared by the editor this time. I hope this content is helpful to you. If you want to learn other interesting tutorials, please leave a message to tell us the project address. The editor will tailor a course for you to teach you how to play AI.
References:
1.https://zhuanlan.zhihu.com/p/627133524
2.https://fuxi.163.com/database/739
3.https://zhuanlan.zhihu.com/p/669814884








