Command Palette
Search for a command to run...
NVIDIA Huang Renxun Released GB200, Which Has 30 Times Higher Reasoning Capability Than H100 and 25 Times Lower Energy Consumption, Turning AI4S Capabilities Into Microservices

"AI's iPhone moment has arrived." Huang Renxun's golden words at NVIDIA GTC 2023 are still fresh in our minds. This year, the development of AI has also proved that what he said is true.
Over the years, with the acceleration of AI development and Nvidia's technology and ecological moat being difficult to shake, GTC has gradually upgraded from an initial technical conference to an AI industry event that the entire industry chain pays attention to. The "muscle" flexed by Nvidia may be an important catalyst for industry innovation.
This year's 2024 GTC AI conference is here as scheduled. From March 18 to March 21, there will be more than 900 meetings and more than 20 technical lectures. Of course, the most watched is still the speech of "Leather Jacket Huang". In the previously announced schedule, Huang Renxun's speech will start at 4:00 am on March 19th, Beijing time, and last until 6:00 am. Just now, Huang threw "AI nuclear bombs" in a 2-hour sharing:
* Blackwell, the new generation GPU platform
* The first chip based on Blackwell, GB200 Grace Blackwell
* Next-generation AI supercomputer DGX SuperPOD
* AI supercomputing platform DGX B200
* New generation network switch X800 series
* Quantum computing cloud service
* Earth-2, a climate digital twin cloud platform
* Generative AI Microservices
* 5 new Omniverse Cloud APIs
* DRIVE Thor, an in-vehicle computing platform designed for generative AI applications
* BioNeMo base model
Live replay link:
https://www.bilibili.com/video/BV1Z6421c7V6/?spm_id_from=333.337.search-card.all.click
cuLitho in action
At last year's GTC conference, NVIDIA launched a computational lithography library, cuLitho, which it claims can accelerate computational lithography by more than 40 times. Today, Huang Renxun introduced that TSMC and Synopsys have integrated NVIDIA cuLipo with their software, manufacturing processes and systems to speed up chip manufacturing.When testing cuLitho on a shared workflow, the two companies jointly achieved a 45x speedup for curvilinear flows and nearly 60x efficiency improvement for more traditional Manhattan-style flows.
In addition, NVIDIA has developed algorithms that apply generative AI to further enhance the value of the cuLitho platform. Specifically, based on the efficiency improvement of production processes based on cuLitho,This generative AI algorithm is also 2 times faster.
It is reported that by applying generative AI, a nearly perfect reverse mask solution can be created, taking the diffraction of light into account, and then deriving the final mask through traditional physical methods, ultimately increasing the speed of the entire optical proximity correction (OPC) process by 2 times.
Blackwell Platform for Generative AI at Trillion Parameter Scale

The above introduction to the application of cuLitho is more like an "appetizer", demonstrating the development prospects of computational lithography technology, and to a certain extent, providing a basic guarantee for the generational upgrade of NVIDIA's AI chips.
Next, the main course began. Following Nvidia's tradition of updating its GPU architecture every two years, Huang's first blockbuster product was the new bigger GPU, the Blackwell platform. He said,Hopper is great, but we need more powerful GPUs.
The Blackwell Architecture is named in honor of David Harold Blackwell, the first African American elected to the National Academy of Sciences.

In terms of performance, Blackwell has 6 revolutionary technologies:
* The world's most powerful chip:The Blackwell architecture GPU is manufactured using a custom 4NP TSMC process and contains 208 billion transistors. It connects two extreme GPU chips into a unified GPU through a 10 TB/sec chip-to-chip link. The second-generation Transformer engine: Blackwell will support double the computing and model scale based on the new 4-bit floating-point AI reasoning capability.
* Fifth-generation NVLink:The latest iteration of NVIDIA NVLink delivers a breakthrough 1.8TB/s bidirectional throughput per GPU, ensuring seamless high-speed communication between up to 576 GPUs to implement the most complex LLMs.
* RAS Engine:Blackwell-powered GPUs include a dedicated engine for reliability, availability, and maintainability. In addition, the Blackwell architecture adds chip-level capabilities to run diagnostics and predict reliability issues using AI-based preventive maintenance. This maximizes system uptime, improves the resilience of large-scale AI deployments, enables them to run continuously for weeks or even months, and reduces operating costs.
* Secure AI:It protects AI models and customer data without compromising performance and supports new native interface encryption protocols, which is critical for privacy-sensitive industries such as healthcare and financial services.
* Decompression engine:A dedicated decompression engine supports the latest formats and accelerates database queries, providing the highest performance for data analytics and data science.
At present, AWS, Google, Meta, Microsoft, OpenAI, Tesla and other companies have taken the lead in "reserving" the Blackwell platform.
GB200 Grace Blackwell

The first chip based on Blackwell was named GB200 Grace Blackwell Superchip.It connects two NVIDIA B200 Tensor Core GPUs to the NVIDIA Grace CPU via an ultra-low-power 900GB/s NVLink chip-to-chip interconnect.
The B200 GPU has more than twice the number of transistors as the existing H100, with 208 billion transistors. It can also provide 20 petaflops of high computing performance through a single GPU, while a single H100 can only provide up to 4 petaflops of AI computing power. In addition, the B200 GPU is also equipped with 192 GB of HBM3e memory, providing up to 8 TB/s of bandwidth.

GB200 is a key component of NVIDIA GB200 NVL72.The NVL72 is a multi-node, liquid-cooled, rack-mount system.Ideal for the most compute-intensive workloads, it combines 36 Grace Blackwell superchips, including 72 Blackwell GPUs and 36 Grace CPUs, interconnected by fifth-generation NVLink.
In addition, the GB200 NVL72 includes the NVIDIA BlueField®-3 data processing unit, which enables cloud network acceleration, composable storage, zero-trust security, and GPU computing elasticity in hyperscale AI clouds. Compared with the same number of NVIDIA H100 Tensor Core GPUs, the GB200 NVL72 can achieve up to 30 times the performance of LLM inference workloads and up to 25 times lower cost and energy consumption.
Next-generation AI supercomputer DGX SuperPOD
NVIDIA DGX SuperPOD uses a new liquid-cooled rack-mounted architecture and is built from NVIDIA DGX GB200 systems.It provides 11.5 exaflops of AI supercomputing power at FP4 precision and 240 TB of fast memory.And it can be expanded to higher performance with additional racks. DGX SuperPOD has intelligent predictive management capabilities that continuously monitor thousands of data points on hardware and software to predict and intercept sources of downtime and inefficiency, saving time, energy, and computing costs.
The DGX GB200 system is equipped with 36 NVIDIA GB200 super chips, including 36 NVIDIA Grace CPUs and 72 NVIDIA Blackwell GPUs, connected into a supercomputer via the fifth-generation NVLink.
Each DGX SuperPOD can carry 8 or more DGX GB200s, which can be expanded to tens of thousands of GB200 super chips connected via NVIDIA Quantum InfiniBand. For example, users can connect 576 Blackwell GPUs to 8 DGX GB200s based on NVLink interconnect.
AI Supercomputing Platform DGX B200
DGX B200 is a computing platform for AI model training, fine-tuning, and inference, using an air-cooled, traditional rack-mounted DGX design. The DGX B200 system achieves FP4 precision in the new Blackwell architecture, providing up to 144 petaflops of AI computing performance, 1.4TB of massive GPU memory, and 64TB/s of memory bandwidth.Real-time inference speed for trillion-parameter models is increased by 15 times compared to the previous generation.
The DGX B200, based on the new Blackwell architecture, is equipped with 8 Blackwell GPUs and 2 fifth-generation Intel Xeon processors. Users can also use the DGX B200 system to build a DGX SuperPOD. In terms of network connectivity, the DGX B200 is equipped with 8 NVIDIA ConnectX™-7 network cards and 2 BlueField-3 DPUs, which can provide up to 400 gigabits per second of bandwidth.
New generation network switch series - X800
It is reported that the new generation of network switches X800 series is designed for large-scale artificial intelligence, breaking the network performance limits of computing and AI workloads.
The platform includes NVIDIA Quantum Q3400 switches and NVIDIA ConnectX@-8 super network cards, achieving industry-leading 800Gb/s end-to-end throughput.The bandwidth capacity is increased by 5 times compared with the previous generation of products.At the same time, by adopting NVIDIA's Scalable Hierarchical Aggregation and Reduction Protocol (SHARPv4), it has achieved up to 14.4 Tflops of in-network computing power.The performance increase is up to 9 times compared to the previous generation.
Quantum computing cloud services accelerate scientific research
NVIDIA's quantum computing cloud service is based on the company's open source CUDA-Q quantum computing platform.Currently, three-quarters of companies deploying quantum processing units (QPUs) in the industry are using this platform. NVIDIA's quantum computing cloud service allows users to build and test new quantum algorithms and applications in the cloud for the first time, including powerful simulators and quantum hybrid programming tools.
The Quantum Computing Cloud has powerful capabilities and third-party software integrations to accelerate scientific discovery, including:
* A generative quantum eigensolver developed in collaboration with the University of Toronto that uses large language models to enable quantum computers to find the ground-state energy of molecules more quickly.
* Classiq's integration with CUDA-Q enables quantum researchers to generate large, complex quantum programs and deeply analyze and execute quantum circuits.
* QC Ware Promethium can solve complex quantum chemistry problems such as molecular simulations.
Release of Earth-2, a climate digital twin cloud platform
Earth-2 aims to simulate and visualize weather and climate at scale, thereby enabling prediction of extreme weather. Earth-2 API provides AI models and uses the CorrDiff model.
CorrDiff is a new generative AI model launched by NVIDIA. It uses the SOTA Diffusion model.The resulting images have 12.5 times higher resolution than existing numerical models, are 1,000 times faster, and are 3,000 times more energy efficient.It overcomes the inaccuracy of coarse-resolution predictions and integrates metrics that are critical for decision making.

CorrDiff is a first-of-its-kind generative AI model that provides super-resolution, synthesizes new important metrics, and learns the physics of local fine-grained weather from high-resolution datasets.
Release of generative AI microservices to promote drug development, medical technology iteration and digital health
The new suite of NVIDIA healthcare microservices includes optimized NVIDIA NIM™ AI models and industry-standard API workflows as building blocks for creating and deploying cloud-native applications. These microservices include capabilities such as advanced imaging, natural language and speech recognition, generation of digital biology, prediction and simulation.
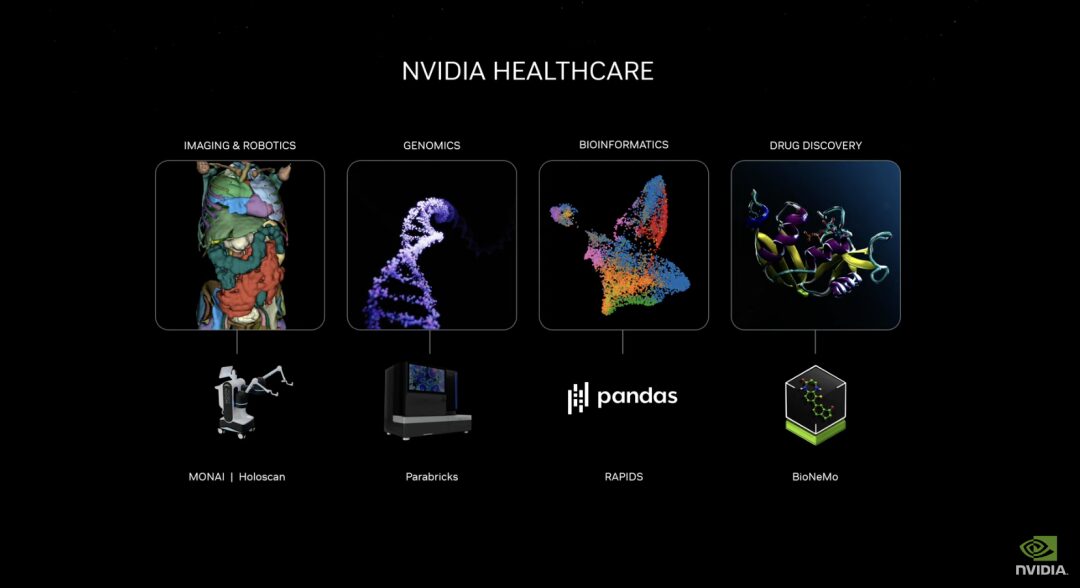
In addition, NVIDIA accelerated software development kits and related tools, including Parabricks®, MONAI, NeMo™, Riva and Metropolis, are now accessible through NVIDIA CUDA-X™ microservices.
Inference microservice
Release dozens of enterprise-grade generative AI microservices that companies can use to create and deploy custom applications on their own platforms while retaining their intellectual property.
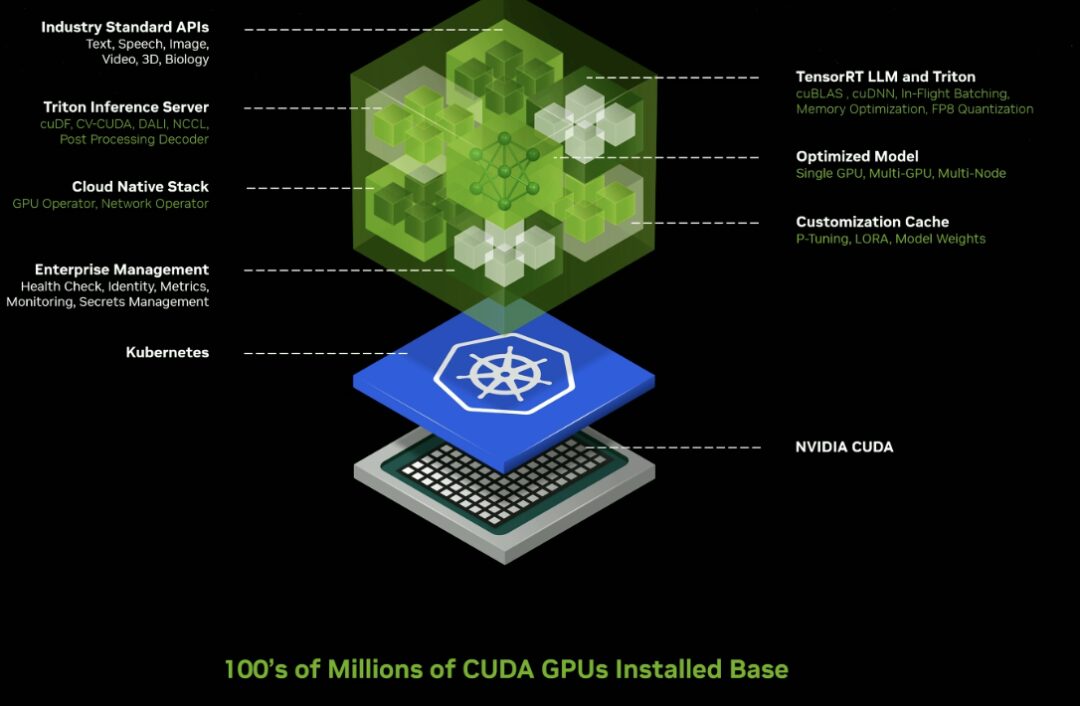
New GPU-accelerated NVIDIA NIM Microservices and Cloud Endpoints for pre-trained AI models optimized to run on hundreds of millions of CUDA-enabled GPUs across clouds, data centers, workstations, and PCs.
Enterprises can use microservices to accelerate data processing, LLM customization, reasoning, retrieval enhancement generation, and protection;
Adopted by a broad AI ecosystem, including leading application platform providers Cadence, CrowdStrike, SAP, ServiceNow, and more.
NIM Microservices provides pre-built containers powered by NVIDIA inference software, including Triton Inference Server™ and TensorRT™-LLM, which can reduce deployment time from weeks to minutes.
Release of Omniverse Cloud API to empower industrial digital twin software tools
Using five new Omniverse Cloud APIs, developers can integrate Omniverse core technologies directly into existing digital twin design and automation software applications, as well as into simulation workflows for testing and validating robots or self-driving cars, such as streaming interactive industrial digital twins to Apple Vision Pro.
These APIs include:
* USD Render:Generating NVIDIA RTX™ Rendering of Global Ray Traced OpenUSD Data
* USD Write:Allows users to modify and interact with OpenUSD data.
* USD Query:Support scene query and scene interaction.
* USD Notify:Track USD changes and provide updates.
* Omniverse Channel:Linking users, tools and reality to achieve cross-scenario collaboration
Huang Renxun believes that in the future, everything manufactured will have a digital twin. Omniverse is the operating system for building and running digital twins of physical reality. Omniverse and generative artificial intelligence are the foundational technologies for the digitization of the $50 trillion heavy industry market.
DRIVE Thor: Generative AI with Blackwell Architecture to Power Autonomous Driving
DRIVE Thor is an in-vehicle computing platform designed for generative AI applications, providing feature-rich simulated driving and highly automated driving capabilities on a centralized platform. As the next generation of autonomous vehicle central computer, it is safe and reliable, unifying intelligent functions into one system, which can improve efficiency and reduce the cost of the entire system.
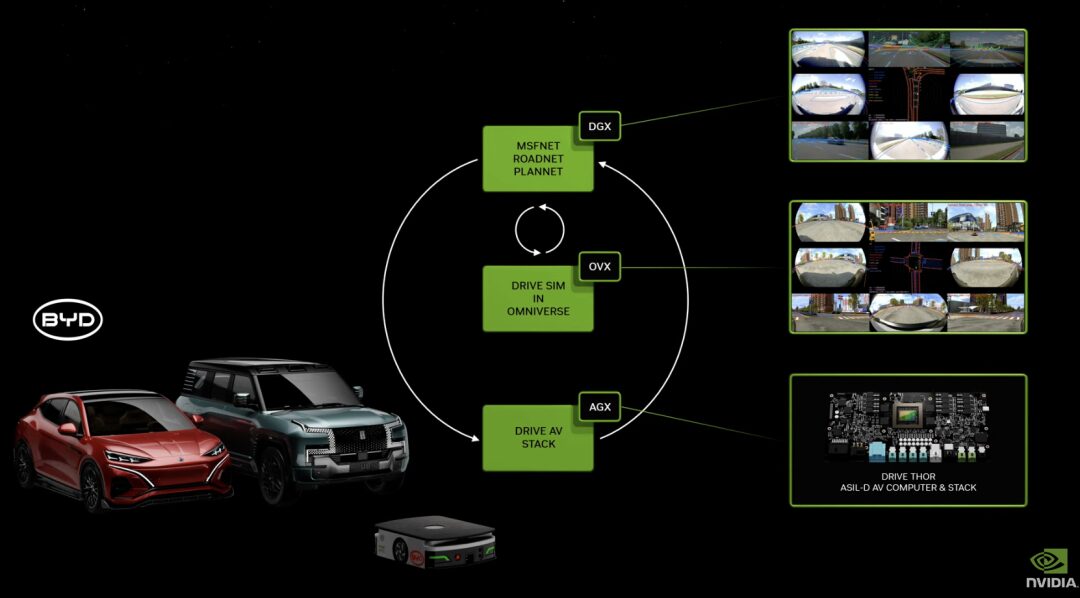
DRIVE Thor will also integrate the new NVIDIA Blackwell architecture.The architecture is designed for Transformer, LLM, and generative AI workloads.
BioNeMo: Assisting Drug Discovery
BioNeMo's basic model can analyze DNA sequences, predict the shape changes of proteins under the action of drug molecules, and determine the function of cells based on RNA.
Currently, the first genomic model provided by BioNeMo, DNABERT, is based on DNA sequences and can be used to predict the functions of specific regions of the genome, analyze the effects of gene mutations and variations, etc. Its second model, scBERT, which is about to be launched, is trained based on single-cell RNA sequencing data, and users can apply it to downstream tasks, such as predicting the effects of gene knockout (i.e. deleting or deactivating specific genes), and identifying cell types such as neurons, blood cells or muscle cells.
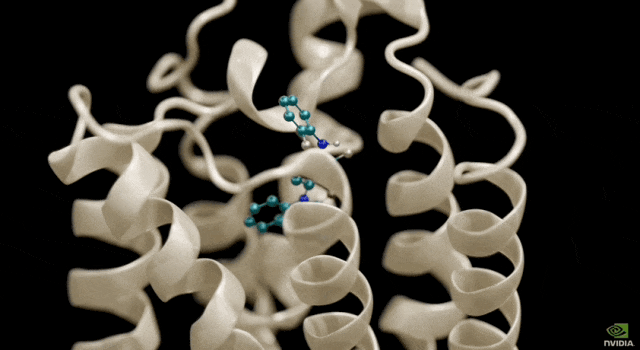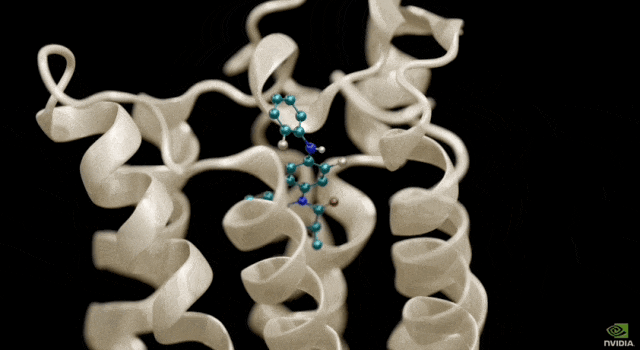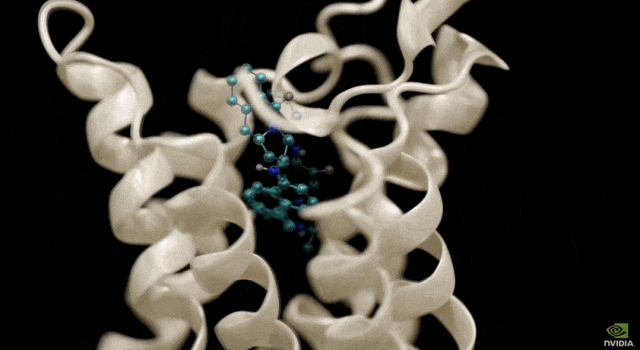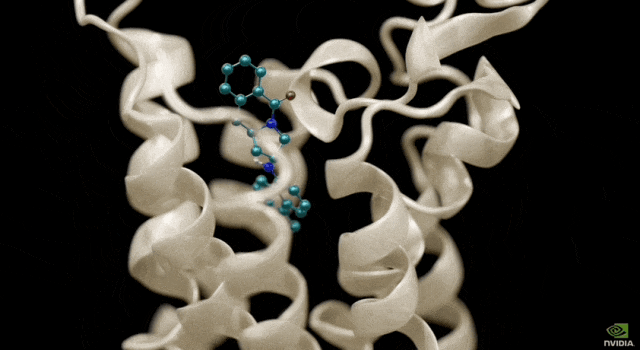
It is reported that there are currently more than 100 companies around the world that are advancing their research and development process based on BioNeMo, including Tokyo-based Astellas Pharma, computational software developer Cadence, drug development company Iambic, and so on.
Final Thoughts
In addition to the many new products mentioned above, Huang Renxun also introduced NVIDIA's layout in the field of robotics. Huang said that all moving things are robots, and the automotive industry will be an important part of it. Currently, NVIDIA computers have been used in cars, trucks, delivery robots and robot taxis. Subsequently, the Isaac Perceptor software development kit, the universal basic model of humanoid robots GR00T, and the new humanoid robot computer Jetson Thor based on the NVIDIA Thor system-on-chip were launched, and the NVIDIA Isaac robot platform was significantly upgraded.
In summary, the 2-hour sharing session was filled with high-performance products and model introductions. Such a fast-paced and content-rich press conference is exactly like the current development status of the AI industry - fast and prosperous.
As the foundation of the AI era, the computing power represented by high-performance chips is the key to determining the industry's development cycle and direction. There is no doubt that Nvidia currently has an unshakable moat. Although many companies have begun to attack Huang, and OpenAI, Microsoft, Google, etc. are also cultivating their own "army", this may be a greater impetus for Nvidia, which is still moving forward at a high speed.
Now, the online live broadcast has ended. After each new product release, Huang Renxun will introduce which partners have "pre-ordered" new services, and all the giants are on the list. In the future, we also expect that the companies currently at the forefront of the industry can use the industry's advanced productivity to bring more innovative products and applications.








