Command Palette
Search for a command to run...
LLMs Playing Werewolf: Tsinghua University Verifies the Ability of Large Models to Participate in Complex Communication Games
Author: Binbin
Editor: Li Baozhu, Sanyang
A research team from Tsinghua University proposed a framework for communication games, demonstrating the ability of large language models to learn from experience. They also found that large language models have non-preprogrammed strategic behaviors such as trust, confrontation, pretense, and leadership.
In recent years, the research on using AI to play games such as Werewolf and Poker has attracted widespread attention. Faced with complex game that heavily relies on natural language communication,AI Agent Information must be collected and inferred from ambiguous natural language discourse, which has greater practical value and challenges. As large language models such as GPT have made significant progress, their ability to understand, generate, and reason about complex languages has continued to improve, showing a certain degree of potential to simulate human behavior.
Based on this,A research team from Tsinghua University proposed a framework for communication games that can play the Werewolf game with a frozen large language model without manually labeled data.The framework demonstrates the ability of large language models to autonomously learn from experience. Interestingly, the researchers also found that the large language model has non-preprogrammed strategic behaviors such as trust, confrontation, disguise, and leadership in the game, which can serve as a catalyst for further research on large language models playing communication games.

Get the paper:
https://arxiv.org/pdf/2309.04658.pdf
Model framework: Playing Werewolf with a large language model
As we all know, an important feature of the Werewolf game is that all players only know their own roles at the beginning. They must infer the roles of other players based on natural language communication and reasoning. Therefore, to perform well in Werewolf, AI Agents must not only be good at understanding and generating natural language, but also have advanced capabilities such as deciphering other people's intentions and understanding psychology.
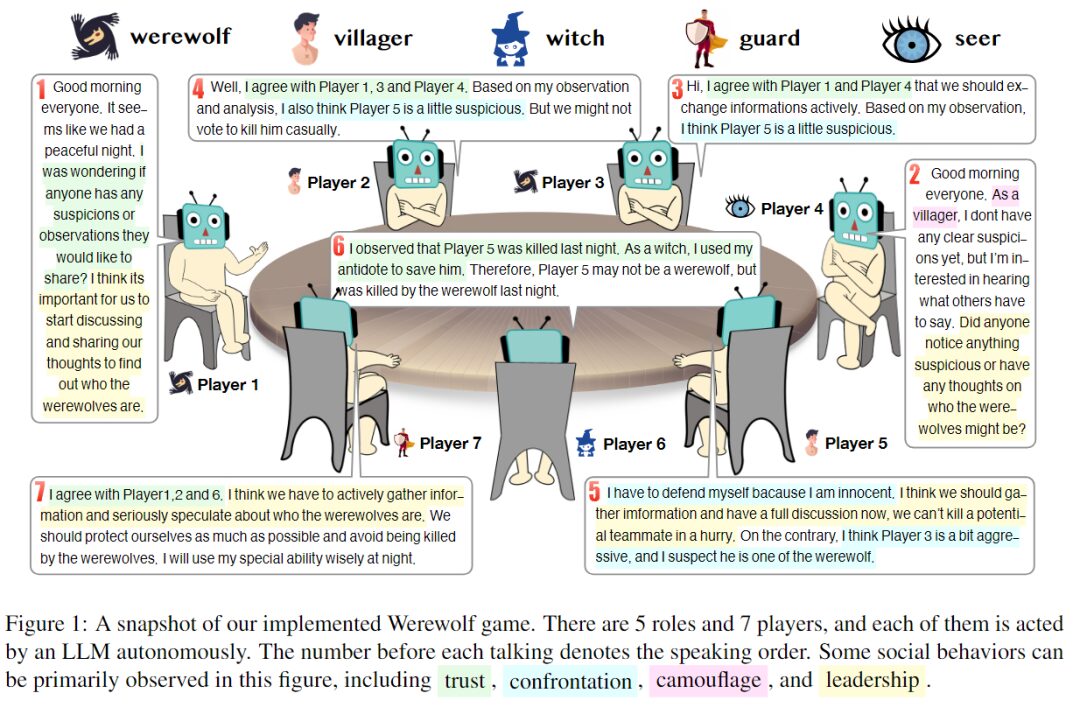
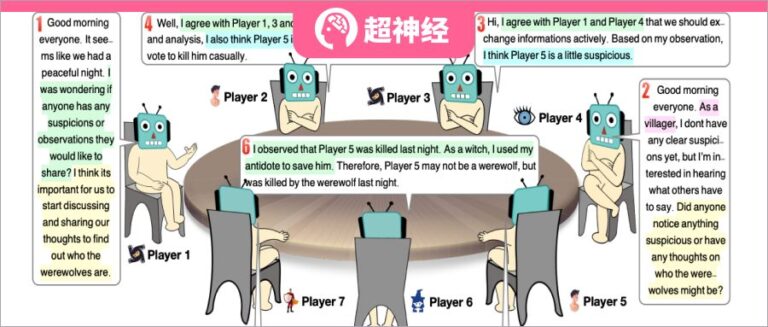
There are 7 players in total, and each role is played by a large language model. The number before each speech indicates the order of speech.
In this experiment, the researchers set up 7 players to play 5 different roles - 2 werewolves, 2 civilians, 1 witch, 1 guard and 1 prophet. Each role is an independent agent generated by prompt. The following figure shows the framework of responding to prompts, which consists of four main parts:

A summary of the prompts that generate the response. Comments in italics.
- Empirical knowledge of the rules of the game, the assigned roles, the abilities and goals of each character, and game strategy.
- Solve the problem of limited context length: Collect historical information from the three perspectives of freshness, information volume, and completeness, taking into account both effectiveness and efficiency, and provide a compact context for each AI Agent based on a large language model.
- Extract recommendations from past experience without tuning model parameters.
- Prompt for a chain of thought that triggers reasoning.
also,The researchers used a new framework called ChatArena to implement the design, which allows connecting multiple large language models.Among them, the gpt-3.5-turbo-0301 model is used as the backend model. The order in which the characters speak is randomly determined. At the same time, the researchers set the number of predefined questions that can be selected to 5, the number of free questions to 2, and a series of parameters such as retaining a maximum of 50 experiences when extracting suggestions.
Experimental process: Feasibility and the influence of historical experience
Building a pool of experience: Evaluating the effectiveness of a framework for drawing on experience
During the Werewolf game, the strategies used by human players may change as they gain experience. At the same time, a player’s strategy may also be affected by the strategies of other players. Therefore, an ideal Werewolf AI Agent should also be able to accumulate experience and learn from the strategies of other players.
to this end,The researchers proposed a "non-parametric learning mechanism" that enables language models to learn from experience without adjusting parameters. On the one hand, at the end of each round of the game, the researchers collected all players' replays of the game to form an experience pool. On the other hand, in each round of the game, the researchers retrieved the most relevant experience from the experience pool and extracted a suggestion from it to guide the agent's reasoning process.
The size of the experience pool can have a significant impact on performance, so the research team used 10, 20, 30, and 40 rounds of game play to build the experience pool, randomly assigning different roles to players 1 to 7 in each round, and the experience pool was updated at the end of the round for evaluation.
Next, experience pools are configured for civilians, prophets, guards, and witches, but werewolves are excluded. This approach can be used as a reference for measuring the performance levels of other AI agents, assuming that the performance level of AI Wolf remains unchanged.
Preliminary experiments show that the empirical knowledge of game strategies provided in the prompt in Figure 2 can serve as a guiding mechanism for the process of learning from experience. This suggests that it is valuable to further study how to use data from human game play to build an experience pool.
Verify the effectiveness of recommendations in the experience pool
To study the effectiveness of extracting suggestions from the experience pool, the research team used winning rate and average duration to evaluate the performance of large language models.
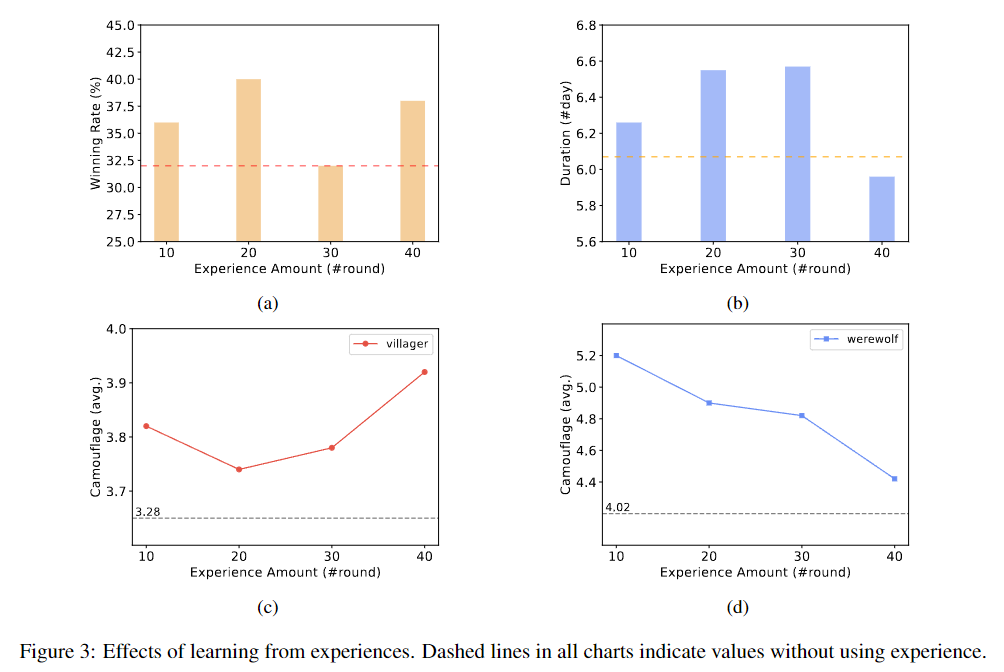
Effect of learning from experience. The dashed lines in all graphs represent the values without using experience.
a. Changes in the civilian side's winning rate when using different rounds of historical experience
b. Changes in the duration of the civilian side when using different rounds of historical experience
c. Trends in the number of times civilians adopt disguises in games
d. Trends in the number of times werewolves use disguises in the game
In the experiment, the game was played for 50 rounds. The results show that learning from experience may improve the civilian side's win rate. When using 10 or 20 rounds of historical experience, there is a significant positive impact on the civilian side's win rate and game duration, proving the effectiveness of the method. However, when learning from 40 rounds of experience, although the civilian side's win rate is slightly improved, the average duration is shortened.
In general,This framework demonstrates the ability of AI agents to learn from experience without having to tune the parameters of large language models.However, when the amount of experience is large, the effectiveness of this method may become unstable. In addition, the experiment assumes that the ability of AI Wolf remains unchanged, but the analysis of experimental results shows that this assumption may not be true. The reason is that although civilians can learn to deceive from historical experience, the behavior of the wolf has also improved and changed with the accumulation of experience.
This suggests that when multiple large language models participate in a multi-party game, the capabilities of the model may also change as the capabilities of other models change.
Ablation studies:Verify the necessity of each part of the framework
To verify the necessity of each component in the method, the researchers compared the full method with a variant in which a specific component was deleted.
The research team extracted 50 responses from the variant model output and conducted manual evaluation. Annotators need to judge whether the output is reasonable. Some unreasonable examples may be hallucinations, forgetting the role of others, taking counterintuitive actions, etc.
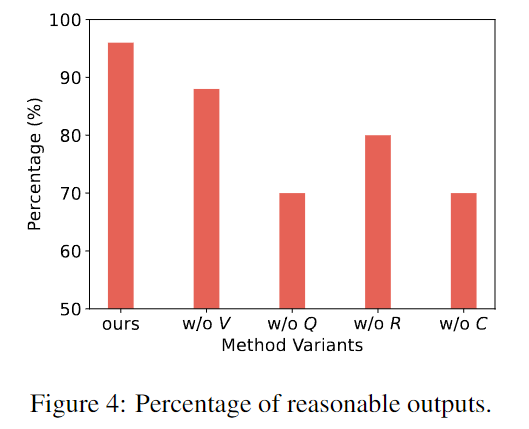
The horizontal axis is the framework of this study and other variants, and the vertical axis is the proportion of reasonable output in 50 rounds of games.
The above figure shows that the framework of this study can generate more reasonable and realistic responses than other variants that lack specific components. Each part of the framework is necessary.
Interesting phenomenon: AI shows strategic behavior
During the experiment, the researchers found that the AI Agent used strategies that were not explicitly mentioned in the game instructions and prompts, namely trust, confrontation, disguise, and leadership as demonstrated by humans in the game.
trust
Trust means believing that other players share the same goals as you and that they will act in accordance with those goals.
For example, players may actively share information that is unfavorable to them, or at certain moments jointly accuse someone of being their enemy with other players. The interesting behavior exhibited by large language models is that they tend to decide whether to trust based on certain evidence and their own reasoning, showing the ability to think independently in group games.
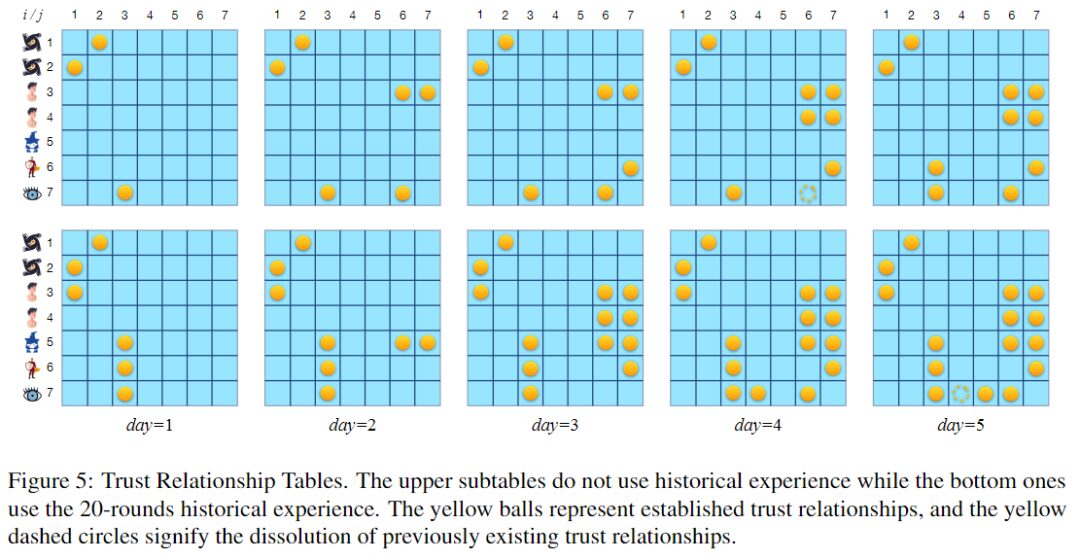
Trust relationship table, yellow balls represent established trust relationships, and yellow dotted circles represent the termination of previously existing trust relationships.
The figure above shows two trust relationship tables. The upper table corresponds to the rounds without using the experience pool, and the lower table corresponds to the rounds using the experience pool built by 20 rounds of games. Both rounds lasted for 5 nights. When using 20 rounds of historical experience, the large language model seems to be more inclined to establish trust relationships, especially two-way trust.
In fact, establishing the necessary trust relationship in a timely manner is crucial to promoting game victory. This may be one of the reasons why using experience to improve the winning rate.
confrontation
"Confrontation" refers to the actions taken by players for the opposing goals of the two camps.
For example, attacking someone explicitly for being a werewolf at night, or accusing someone of being a werewolf during the day, are both antagonistic behaviors. Actions taken by a character with special powers to protect themselves are also antagonistic behaviors.
P1 (Werewolf): I choose to eliminate P5 again.
P3 (Guard): I choose to protect P5.
Since P1's uncooperative and aggressive behavior has attracted attention, some players may now suspect that it is a werewolf. Therefore, the guard, who has strong defensive capabilities, chooses to protect the target that P1 wants to eliminate (P5) for the next night. Since P5 may be his teammate, the guard chooses to assist P5 in fighting the werewolf's attack.
Werewolf attacks and other players' defenses are considered confrontational actions.
camouflage
Disguise refers to the act of concealing one’s identity or misleading others. In a competitive environment with incomplete information, blurring one’s identity and intentions can improve survivability and thus help achieve game goals.
P1 (Werewolf): Good morning everyone! No one died last night. As a civilian, I don't have any useful information. You can talk more.
In the above example, you can see that the werewolf claims to be a civilian. In fact, not only werewolves disguise themselves as civilians, but also important characters such as prophets and witches often disguise themselves as civilians to ensure their own safety.
Leadership
"Leadership" refers to the act of influencing other players and attempting to control the course of the game.
For example, a werewolf might suggest that others act in accordance with the werewolf's intentions.
P1 (Werewolf): Good morning everyone! I don't know what happened last night. The prophet can jump out and correct the vision. P5 thinks P3 is a werewolf.
P4 (Werewolf): I agree with P5. I also think P3 is a werewolf, and I suggest voting P3 out to protect civilians.
As shown in the example above, the werewolf asks the prophet to reveal his identity, which may cause other AI agents to believe that the werewolf is disguised as a civilian. This attempt to influence the behavior of others shows the social properties of large language models that are similar to human behavior.
Google releases AI agent that masters 41 games
The framework proposed by the Tsinghua University research team proves that large language models have the ability to learn from experience and also shows that LLMs have strategic behavior. This provides more imagination for studying the performance of large language models in complex communication games.
In practical applications, AI is no longer satisfied with only being able to play one game. Last July, Google AI launched a multi-game agent, making great progress in multi-task learning: a new decision-making Transformer architecture was used to train the agent, which can be quickly fine-tuned on a small amount of new game data, making training faster.
The comprehensive performance score of this multi-game agent in playing 41 games is about twice that of other multi-game agents such as DQN, and can even be comparable to agents trained on only a single game. In the future, it is worth looking forward to what kind of rich and interesting research will be derived from AI agents participating in games, or even participating in multiple games at the same time.








